【论文简述】Long-range Attention Network for Multi-View Stereo(WACV 2021)
一、论文简述
1. 第一作者:Xudong Zhang
2. 发表年份:2021
3. 发表期刊:WACV
4. 关键词:MVS、注意力、级联、监督回归
5. 探索动机:先前的方法忽略了像素之间的依赖关系,并且期望回归的方式效率不高。
- However, this pixel-wise operation ignores the interdependence among pixels, since its calculation of matching degree for each pixel pair is produced independently from the other pixel pairs. As a result, the constructed cost volume computed from image features could be noise-contaminated and inconsistent, which is often not conducive to the dense matching on occluded or texture-less regions.
- previous methods predict depth maps from the expectation of probability volume distributions which express the possibility of different depth hypotheses. However, existing volume learning methods are driven by the depth regression, which are implicit and not very efficient, considering that different probability distributions might share the same expectation. Also, the optimal distribution should be a Gaussian distribution, which has the highest probability at the true depth. As illustrated in Fig. 1, for those falsely matched pixels, their probability distributions are far from optimal, since they might be not effectively supervised by the intermediate layer. Therefore, it becomes essential to explicitly supervise the probability volume distribution.
6. 工作目标:解决上述问题
7. 核心思想:注意力机制,ASPP正则化,高斯中间监督
- We introduce a long-range attention network for MVS to selectively aggregate reference features to each position to capture the interdependence among pixels. Our method instinctively facilitates propagating more guiding information to measure the similarity between reference and other source images.
- We introduce a new loss to supervise the distribution of probability volumes reasonably centered at the true depth, which can enhance robustness of the network to reconstruct new objects.
8. 实验结果:SOTA
We achieve the best overall performance on the DTU and Tanks & Temples benchmarks, largely surpassing the state-of-the-art methods by up to 3.7% for the overall scores.
9.论文下载:
https://openaccess.thecvf.com/content/WACV2021/papers/Zhang_Long-Range_Attention_Network_for_Multi-View_Stereo_WACV_2021_paper.pdf
二、实现方法
1. LANet概述
LANet采用从粗到细的结构,逐步预测更精细的深度图。假设有一个参考图像I1和N−1个源图像{In}。
- 利用特征金字塔网络(FPN)提取3个分辨率的多尺度深度图像特征{fln};
- 将每对深度特征{fln}输入到所提出的远程注意模块(LAM)中,得到注意力金字塔特征;
- 基于前一阶段预测的自适应深度假设,构建3D代价体;
- 利用3D卷积网络和ASPP对代价体进行正则化,预测深度概率分布,回归得到深度图;
- 此外,还利用一种新的概率体损失作为中间监督,将中间概率体约束为高斯分布,并结合深度回归损失来监督网络训练;

2. 长距离的注意力
注意力金字塔特征提取器如下。首先利用特征金字塔网络(FPN)来提取多尺度特征,然后将它们输入到长距离注意力模块(LAM)中。LAM主要分为两个步骤。第一步通过基于注意力的二阶池化将参考f1的关键特征收集到全局描述符Gl中,将整个特征空间嵌入到一个信息紧凑包中。第二步通过自适应选择这些具有信息的参考描述符Gl到输入特征的每个位置{fn} 来聚合相互依赖性,得到注意力输出{Zn}。

参考全局描述符。给定参考特征f1∈C×H×W,首先利用不同的卷积层将其分别嵌入到两个新的特征映射A, B∈C×H×W。然后重塑为C×(HW),其中HW是像素的数量。为了便于解释,重写A = [a1,…,ahw]和B= [b1,…,bc],其中ai是c维的列向量,bj是hw维的列向量。全局描述符G = [g1,…,gc]∈C×C可以通过基于注意力的二阶池化将整个特征空间嵌入到一个紧凑包中来计算,通过加权bj合并局部特征{ai}hw得到基元gj是:
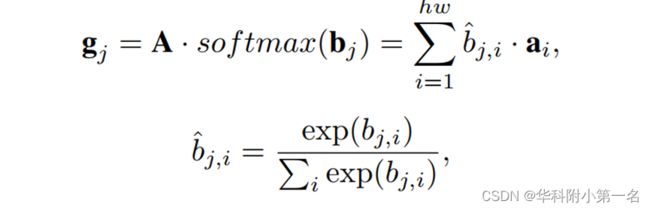
其中应用softmax函数将bj归一化为单位和的函数,接着进行二阶注意力池化过程,bj,i表示bj的第i个元素。这一步提供了一种获得参考信息特征的有效方法。例如,如果所有位置都密集的注意到bj,可以获得纹理和光照特征。相反,如果bj在特定区域上稀疏的注意到,我们可以获得语义特征,例如一个物体。
依赖聚合。聚合具有丰富信息的参考描述符和所有输入特征{fn}N N =1的每个位置之间的相互依赖关系。为了方便起见,我们详细描述了一个输入特征f的依赖聚合过程,这样的操作可以是并行应用于其他输入特征。首先应用卷积层将输入特征f嵌入到新特征映射V∈C×H×W中。重写V = [v1,…, vhw],其中vi表示局部输入特征的c维列向量。在需要局部特征vi的条件下,自适应地选择输入f的每个位置i的具有丰富信息的参考描述符{gj}c来聚合相互依赖性,得到注意力输出,表示为[z1,…, zhw]∈C×(HW)。对于每个位置i,zi可以计算为:
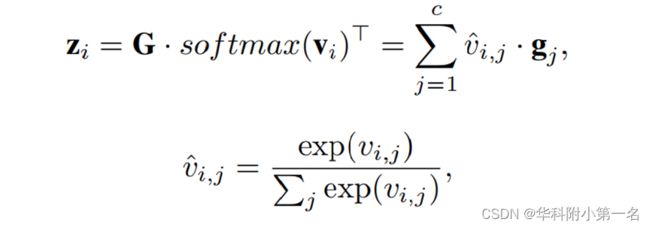
其中vi,j表示vi的第j个元素,通过softmax进行归一化得到vi,j。结果表明,这种软注意力操作具有较好的收敛性。
注意力金字塔特征。为了回归有细密纹理的深度图,采用了一个类似金字塔的结构来捕获不同尺度上的多层次相互依赖关系,以逐步构建更高分辨率的代价体。应用于不同层次的LAM模块会生成多个包含不同相互依赖程度的注意力特征{Zl}3,高层级信息有助于重建反射或遮挡区域,低层级信息有助于精确定位像素。
3. 深度预测
获得注意力的特征后,如MVSNet一样构建3D代价体。与U-Net相比,用ASPP模块取代了编码器架构的最后两层,用于正则化代价体。ASPP模块使网络能够有效地扩大感受野,以融合远距离上下文。其中ASPP在三个阶段的结构是相同的,但不共享权重,分别处理多尺度代价体。卷积网络的最后一层是深度的softmax,用于预测像素深度概率体P。对于给定的l级,假设像素x处的深度假设为dl(x),范围从d1到dK,其中K表示深度平面的数量,PK(x)表示像素x处深度为dlK的可能性。利用沿深度方向的期望值计算第l级上每个像素x的估计深度:

4. 组合损失函数
先前工作用L1深度损失来训练网络。然而,它忽略了概率体作为中间层被间接监督,这使得它的分布较少受到约束。为了解决这个问题,提出了一种新的概率体损失,结合深度损失来有效地训练网络。
概率体损失。假设像素x的深度假设的范围从d1到dK,真实深度为dˆ。概率体Pk(x)是像素x深度为dk的概率。因此,预测的概率体在深度dˆ′的概率最大,且随着离真实深度越远概率逐渐减小。这个性质要求概率分布在真实概率体中每个位置的真实深度处达到峰值,服从期望为dˆ的类高斯分布。像素x的真实概率体定义为:

其中cˆk(x)表示深度假设dk(x)与真深度之间的归一化距离,σ是控制真实深度附近峰值锐度的方差。不同的像素应有不同的锐度。例如,那些确定匹配的像素应该有一个尖锐的峰值,而那些不确定的像素则有一个相对平坦的峰值。
为了为概率体建立更合理的标签,利用置信度分数图s∈[0,1]H×W自适应地预测每个像素的σ。大分数s表示更匹配自信,小分数表示匹配不明确。因此,可以用概率分布的单峰来测量估计的置信度。那么,生成真实值的分布的σ计算为:

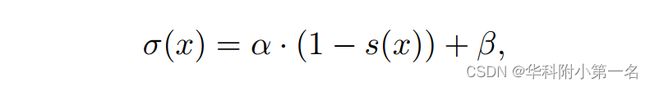
其中α是反映σ对置信度s变化敏感性的比例因子,β定义了σ的下界,避免了除0的数值问题。像素x处,得到了估计的概率体Pk(x)和真实Pˆk(x)。概率体损失可以通过交叉熵来定义:

其中Ω表示有效的真实像素集。
深度损失。与MVSNet类似,利用L1测量真实深度D与估计深度D之间的绝对差,定义损失为:
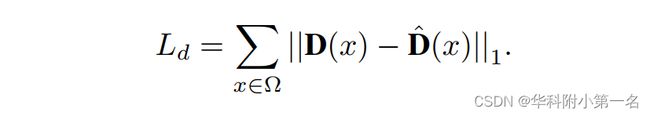
组合损失。用损失函数来监督所有三个阶段,阶段权值为{γl}3。在每阶段,综合损失是深度损失Ll d和概率体损失Ll p的加权和。总损失定义为:

其中λ为损失权重,以平衡深度损失和概率体损失。
5. 实验
5.1. 数据集
DTU Dataset、Tanks and Temples
5.2. 实现
通过PyTorch实现,使用DTU数据集训练。 对于DTU,图像分辨率为640 × 512,输入图像的数量N = 3。由Adam优化器端到端训练,批大小为16,在8个NVIDIA GTX 1080Ti GPU上训练。
5.3. 基准结果
DTU数据集基准:SOTA

Tanks & Temples:SOTA
