Pytorch 深度学习笔记
Pytorch 深度学习笔记
- 1. 环境及相关依赖
- 2. 前导
- 3. 部分概念
-
- 3.1 深度学习
- 3.2 tensor
- 3.3 SVM
- 3.4 超参数
- 3.5 迁移学习
- 4. 基于迁移学习的实现
-
- 4.1 多分类
-
- 4.1.1 加载数据
- 4.1.2 训练
- 4.1.3 保存和加载模型
- 4.1.4 预测
- 4.2 多标签
-
- 4.2.1 加载数据集
- 4.2.2 训练
- 4.2.3 保存加载模型
- 4.2.4 预测
- 5. 问题
-
- 5.1 超参数有哪些?如何调整?
- 5.2 如何选择神经网络模型?
- 5.3 怎么进行数据集标注?
- 5.4 数据增强是什么?
- 5.5 transforms.Normalize参数是怎么确定的?
- 5.6 LR学习率下降有什么作用?
- 5.7 model.train() 和 model.eval() 的区别?
- 5.8 神经网络层数越多越好吗?
- 6. 参考
1. 环境及相关依赖
python==3.8.9
torch==1.9.0
torchvision==0.10.0
numpy==1.21.1
tensorboard==2.5.0
jupyter==1.0.0
Flask==2.0.1
sklearn==0.0
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
- 一个强大的N维数组对象 ndarray
- 广播功能函数
- 整合 C/C++/Fortran 代码的工具
- 线性代数、傅里叶变换、随机数生成等功能
(摘自 菜鸟教程–Numpy教程)
sklearn (scikit-learn) 是基于 Python 语言的机器学习工具
- 简单高效的数据挖掘和数据分析工具
- 可供大家在各种环境中重复使用
- 建立在 NumPy ,SciPy 和 matplotlib 上
- 开源,可商业使用 - BSD许可证
(摘自 scikit-learn (sklearn) 官方文档中文版)
Jupyter Notebook是基于网页的用于交互计算的应用程序。
其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。
2. 前导
深度学习框架有很多,下面列举一部分
- TensorFlow (2.0 已整合 Keras)
- Pytorch
- Caffe2
- 百度的PaddlePaddle
- 旷世的 MegEngine(天元)
- 清华大学的 Jittor(计图)
- 华为的 MindSpore
人力有时而穷,这么多的框架我们不能一一尝试,只能选择在目前应用比较广泛、业内口碑较高的框架进行学习测试。
成果: 在到目前为止的学习中,我们实现了图像分类、图像多标签分类任务的模型训练,准确率最高达到99%以上,后续还会进行目标检测等系列工作。
在到目前为止的学习中,我们主要是使用Pytorch迁移学习来进行模型训练,接触了 ResNet、DenseNet、GoogleNet等CNN模型,对各模型的超参数进行调整之后,进行对比,找到准确率最高的模型。
3. 部分概念
3.1 深度学习
机器学习(Machine Learning,ML) 是指从有限的观测数据中学习(或“猜 测”)出具有一般性的规律,并利用这些规律对未知数据进行预测的方法.
深度学习(Deep Learning,DL) 是机器学习的一个子问题,其主要目的是从数据中自动学习到有效的特征表示
(摘自 神经网络与深度学习)
3.2 tensor
tensor,中文译为张量,可以看一下Tensorflow的解释
A tensor is a generalization of vectors and matrices to potentially higher dimensions.
张量是多维数组,目的是把向量、矩阵推向更高的维度。
我们平时说到张量时,通常都说的是N≥ 3维度的矩阵概念的泛指。那么为了避免混淆,一般地我们只将维度大于等于3的张量称为张量。
3.3 SVM
支持向量机(Support Vector Machine,SVM) 是一个经典的二分类算法,其找到的分割超平面具有更好的鲁棒性,因此广泛使用在很多任务上,并表现出了很强优势.
(超平面就是三维空间中的平面在更高维空间的推广. 维空间中的 超 平 面 是 − 1 维 的.在二维空间中,决策边界为一个直线;在三维空间中,决策边界为一个平面;在高维空间中,决策边界为一个超平面.)
(摘自 神经网络与深度学习)
3.4 超参数
在机器学习中,优化又可以分为参数优化和超参数优化.
模型(; )中的 称为模型的参数,可以通过优化算法进行学习.
除了可学习的参数 之外,还有一类参数是用来定义模型结构或优化策略的,这类参数叫作超参数 (Hyper-Parameter).
在贝叶斯方法中,超参数可以理解为参数的参数,即控制模型参数分布的参数.
常见的超参数包括:聚类算法中的类别个数、梯度下降法中的步长、正则化
项的系数、神经网络的层数、支持向量机中的核函数等.超参数的选取一般都是
组合优化问题,很难通过优化算法来自动学习.
因此,超参数优化是机器学习的一个经验性很强的技术,通常是按照人的经验设定,或者通过搜索的方法对一组超参数组合进行不断试错调整.
(摘自 神经网络与深度学习)
3.5 迁移学习
众所周知,深度学习需要相当庞大的数据集,在我们自己的业务场景中,很难找到足够的数据集,这个时候就引入了迁移学习的概念。
简单的理解就是使用一些已经训练好的模型迁移到类似的新的问题进行使用,而不必对新问题重新建模,从头训练和优化参数。这些训练好的模型同时包含了优化好的参数,在使用的时候只需要做一些简单的调整就可以应用到新问题中了。
要注意的是,预训练模型解决的问题需要与我们需要解决的问题类似,比如同样都是图像分类任务。
在实践中,我们就是使用的基于ImageNet数据集预训练好的模型进行迁移学习,效果还是不错的。
4. 基于迁移学习的实现
分类问题又分为 二分类、多分类、多标签问题。
其中,二分类和多分类都是只输出一个标签,而多标签则可能输出0个或者多个标签。
其实大体步骤还是比较简单的,加载数据集 --> 训练 --> 保存模型,主要是里面的细节,代码应该如何编写。
4.1 多分类
4.1.1 加载数据
我们只需要简单的把图像分类到文件夹中即可。比如ant文件夹存放蚂蚁的图片,bee存放蜜蜂的图片,蚂蚁蜜蜂的识别也是Pytorch迁移学习的示例。
可以直接参考 迁移学习教程
可以参考下图,又分为train和val两个文件夹,一个是训练集,一个是验证集,或者可以再加一个test测试集。
比例一般是
训练:验证=7:3,
或者
训练:验证:测试=6:2:2 (数据集 万级别及以下)
如果数据集数量很大,比如百万条数据,也可以98:1:1

代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
# 选择设备 CPU/GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 图像处理, 需要把图片缩放至统一尺寸,进行标准化操作,这是为了提高准确率的一种手段
# 只有训练集需要图像增强操作,比如仿射变换(旋转、平移等操作)
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
# 数据集所在文件夹
data_dir = '../data/hymenoptera_data'
# 从文件夹加载数据集
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
# batch_size 每个批次几条数据,超参数,需要优化
# shuffle 是否打乱
# num_workers 进程数量
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
# 训练集和验证集的数量
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
# 类别名称,可以把这个数组保存为 json 文件,在预测的时候使用
class_names = image_datasets['train'].classes
4.1.2 训练
这里又分为两个场景:
- Finetuning the convnet(微调神经网络):使用预训练网络初始化网络,而不是随机初始化,其余训练看起来像往常一样
- ConvNet as fixed feature extractor(作为固定特征提取器):冻结除最终完全连接层之外的所有网络的权重。最后一个全连接层被替换为具有随机权重的新层,并且仅训练该层。
两个场景不同的地方在于 是否冻结除全连接层之外网络的权重,其他地方都是一样的。
根据官方数据,作为固定特征提取器,也就是第二个场景,训练速度会更快,并且效果更好。(在我们应用场景中,也验证了这个说法,不过受限于设备性能,只训练了四轮,结论参考价值不大。)
下面是部分代码:
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
"""
模型训练方法
:param model: 初始模型
:param criterion: 损失函数
:param optimizer: 优化器
:param scheduler: 学习率调度器
:param num_epochs: 训练轮数
:return: 训练获取到的最佳模型
"""
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# 每轮有 训练 和 验证 两个阶段
for phase in ['train', 'val']:
if phase == 'train':
model.train() # 训练模式
else:
model.eval() # 评估模式
running_loss = 0.0
running_corrects = 0
# 遍历数据,加载数据的时候我们设置了 batch_size
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# 只有训练的时候需要损失函数和优化器
if phase == 'train':
loss.backward()
optimizer.step()
# 统计损失和准确率
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
# 学习率调度器,训练时才去进行学习率的衰减
scheduler.step()
# 这一轮训练完成后,获取本轮的损失和准确率
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# 加载训练过程中的最佳模型权重
model.load_state_dict(best_model_wts)
return model
# 获取预训练模型 , 注意添加 pretrained=True, 会自动下载预训练模型
model_conv = torchvision.models.resnet18(pretrained=True)
# 使用 requires_grad = False 冻结除了全连接层外的其他网络,默认为 True
# 微调神经网络 和 作为固定特征提取器 的差异之处就在这里
for param in model_conv.parameters():
param.requires_grad = False
# 获取默认全连接层的输入通道数
num_ftrs = model_conv.fc.in_features
# 替换为新的全连接层, 输入通道数一致, 输出通道数为 我们的类别数量
model_conv.fc = nn.Linear(num_ftrs, 2)
model_conv = model_conv.to(device)
# 交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 优化函数,选用SGD,目前好像效果比较好的是 Adam,学习率也是一个超参数,需要我们调整
optimizer_conv = optim.SGD(model_conv.fc.parameters(), lr=0.001, momentum=0.9)
# lr_scheduler 学习率调度器
# 每七轮 将学习率衰减0.1,这也是为了让损失更好的收敛
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_conv, step_size=7, gamma=0.1)
# 训练模型,返回最好的模型
model_conv = train_model(model_conv, criterion, optimizer_conv,
exp_lr_scheduler, num_epochs=5)
4.1.3 保存和加载模型
模型训练完成之后,当然要找地方储存起来,否则每次使用都要重新训练那不是相对耗费时间。
模型的后缀一般是 .pt .pth .pkl,都是可以的。
模型的保存分为两种方式,各有优劣
| 类型 | 优点 | 缺点 |
|---|---|---|
| 保存完整网络 | 方便后续加载模型 | 占用空间大,保存慢 |
| 仅保存模型参数 state_dict | 占用空间小,字典格式,保存内容灵活 | 后面加载模型,需要先定义网络结构 |
举例:
# 保存完整模型
# 保存模型
torch.save(model, 'model.pth')
# 加载模型
model= torch.load('./model.pth')
model.eval()
# 仅保存参数
# 保存模型
torch.save(model.state_dict(), 'model.pth')
# 加载模型, 这里需要与训练的时候保持一致
model= models.resnet18(pretrained=True)
for param in net.parameters():
param.requires_grad = False
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 2)
state_dict = torch.load('./model.pth')
model.load_state_dict(state_dict)
model.eval()
那么这两种方式应该如何选择呢?
我的建议是如果模型结构是固定的,比如都是使用的resnet18,只是训练集有所不同,那么可以使用仅保存模型参数的方式;
如果模型结构并不固定,比如说一样的数据集,想用多种网络训练,那么可以保存完整模型,这种方式通用性更强一些。
在网上,还看到了保存字典格式数据的方式,这种方式就需要固定字典的结构。
比如:
# 保存模型
torch.save({'classes': classes, 'state_dict': model.state_dict()},
'./model.pth')
# 加载模型
net = models.resnet18(pretrained=True)
for param in net.parameters():
param.requires_grad = False
num_ftrs = net.fc.in_features
net.fc = nn.Linear(num_ftrs, 2)
# 获取到保存的字典
param = torch.load('./model.pth')
# 从字典获取类别名称
classes = param['classes']
# 从字典获取模型参数
state_dict = param['state_dict']
net.load_state_dict(state_dict)
net.eval()
4.1.4 预测
加载完模型之后,就需要进行预测工作来对我们的模型进行实战测试。
代码如下:
# net就是我们加载完的模型,放在device中
net = net.to(device)
torch.no_grad()
# 打开图片,并且进行图像标准化,放在device中
img = Image.open(img_path)
img = transform(img).unsqueeze(0)
img_ = img.to(device)
# 预测,返回结果,img_可以是DataLoader加载多张图片
outputs = net(img_)
# 返回值是个二维数组,我们传了一张图片,所以返回数组内只有一个元素
# 计算每个元素(数组)几个类别中概率最大的一个,返回
_, predicted = torch.max(outputs, 1)
# print(predicted)
# classes是类别字典,可以在训练的时候保存为json文件,然后在这里读取,或者保存在模型文件中,或者其他持久化方案
# predicted[0]获取第一张图片的结果
print('this picture maybe :', classes[predicted[0]])
4.2 多标签
这里我们主要参考 参考4(可能会被墙).
4.2.1 加载数据集
这里就不是简单的分文件夹就可以了,因为每张图片都可能有若干个标签,简单的树状结构是不适合的。
所以我们可以使用一个 txt 或者 csv 文件记录每张图片的信息,比如路径、包含的标签等。
(csv文件:逗号分隔值文件,可以读取为表格,可以使用 pandas库的 read_csv(csv_path) 函数读取文件内容。)
示例中并没有使用到csv或者txt,而是直接使用两个json文件(一个训练集、一个测试集),json文件中内容如下,samples是所有的图片的信息,包含文件名 (其实是相对图像所在文件夹的位置,这里直接放在了图像文件夹中,所以只写了文件名,如果要放在图像文件夹的子文件夹中,则需要注意是相对路径,比如 ./abc/xyz.jpg) 和图片中的标签,labels是所有的标签:
{
"samples": [
{
"image_name": "123940_1158315062_02a15f03aa_m.jpg",
"image_labels": [
"person",
"window"
]
},
{
"image_name": "224479_258516503_adb1f839ce_m.jpg",
"image_labels": [
"person"
]
},
...
...
],
"labels": [
"house",
"birds",
"sun",
...
]
}
读取到json内容后手动拼装为只有 0 1 的矩阵。
import os
import time
import numpy as np
from PIL import Image
from torch.utils.data.dataset import Dataset
from tqdm import tqdm
from torchvision import transforms
from torchvision import models
import torch
from torch.utils.tensorboard import SummaryWriter
from sklearn.metrics import precision_score, recall_score, f1_score
from torch import nn
from torch.utils.data.dataloader import DataLoader
from matplotlib import pyplot as plt
from numpy import printoptions
import requests
import tarfile
import random
import json
from shutil import copyfile
# 固定所有种子以使实验可重复,这样每次获取的随机数都一样,方便调试
torch.manual_seed(2020)
torch.cuda.manual_seed(2020)
np.random.seed(2020)
random.seed(2020)
torch.backends.cudnn.deterministic = True
# 初始化训练参数.
num_workers = 8 # 用于数据预处理的 CPU 进程数
lr = 1e-4 # Learning rate
batch_size = 32
save_freq = 1 # 保存 checkpoint 频率 (epochs)
test_freq = 200 # 测试模型频率 (iterations)
max_epoch_number = 35 # 训练的 epoch
# Note: on the small subset of data overfitting happens after 30-35 epochs
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
device = torch.device('cuda')
# 图片所在文件夹
img_folder = 'images'
# 自定义数据集,简单的数据加载器和标签二值化,即将测试标签转换为长度为 27(类数)的二进制数组,其中适用标签的位置为 1)。
# Simple dataloader and label binarization, that is converting test labels into binary arrays of length 27 (number of classes) with 1 in places of applicable labels).
class NusDataset(Dataset):
def __init__(self, data_path, anno_path, transforms):
"""
初始化
:param data_path: 图片所在文件夹
:param anno_path: json文件位置
:param transforms: 图像转换函数
"""
self.transforms = transforms
with open(anno_path) as fp:
json_data = json.load(fp)
samples = json_data['samples']
self.classes = json_data['labels']
self.imgs = []
self.annos = []
self.data_path = data_path
print('loading', anno_path)
# 遍历json中对应的所有图片信息,把路径和标签分开放在两个数组中
for sample in samples:
self.imgs.append(sample['image_name'])
self.annos.append(sample['image_labels'])
# 遍历图像的标签,将self.annos数组中的值改为 0 1的矩阵
for item_id in range(len(self.annos)):
item = self.annos[item_id]
# 遍历所有标签,判断图像的标签数组中是否有这个标签
vector = [cls in item for cls in self.classes]
# 转换为 0 1 数组
self.annos[item_id] = np.array(vector, dtype=float)
def __getitem__(self, item):
anno = self.annos[item]
img_path = os.path.join(self.data_path, self.imgs[item])
img = Image.open(img_path)
if self.transforms is not None:
img = self.transforms(img)
else:
# 这里必须进行 ToTensor() 操作
img = val_transform (img)
return img, anno
def __len__(self):
return len(self.imgs)
# 测试集 预处理
val_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
print(tuple(np.array(np.array(mean)*255).tolist()))
# 训练集 预处理
train_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(),
transforms.RandomAffine(degrees=20, translate=(0.2, 0.2), scale=(0.5, 1.5),
shear=None, resample=False,
fillcolor=tuple(np.array(np.array(mean)*255).astype(int).tolist())),
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
# Initialize the dataloaders for training.
test_annotations = os.path.join(img_folder, 'small_test.json')
train_annotations = os.path.join(img_folder, 'small_train.json')
test_dataset = NusDataset(img_folder, test_annotations, val_transform)
train_dataset = NusDataset(img_folder, train_annotations, train_transform)
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, num_workers=num_workers, shuffle=True,
drop_last=True)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, num_workers=num_workers)
其实大体都是类似的。
4.2.2 训练
多标签分类需要注意的是
激活函数: softmax vs sigmoid
Softmax =多类别分类问题=只有一个正确答案=互斥输出(例如手写数字)
Sigmoid =多标签分类问题=多个正确答案=非独占输出(例如胸部X光检查)。
损失函数:CrossEntropyLoss vs BCELoss
nn.BCELoss() 二元交叉熵损失
nn.CrossEntropyLoss() 交叉熵损失
需要使用 sigmoid + BCELoss .
# 使用 torchvision 的 ResNeXt 实现, 但是添加一个不同类别数(27)的全连接层并使用 Sigmoid 替换默认的 Softmax.
class Resnext50(nn.Module):
def __init__(self, n_classes):
super().__init__()
resnet = models.resnext50_32x4d(pretrained=True)
resnet.fc = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(in_features=resnet.fc.in_features, out_features=n_classes)
)
self.base_model = resnet
self.sigm = nn.Sigmoid()
def forward(self, x):
return self.sigm(self.base_model(x))
# 使用阈值定义预测标签并使用不同的平均策略调用 sklearn 的指标
# Use threshold to define predicted labels and invoke sklearn's metrics with different averaging strategies.
# 精确度:precision,正确预测为正的,占全部预测为正的比例,TP / (TP+FP)
# 召回率:recall,正确预测为正的,占全部实际为正的比例,TP / (TP+FN)
# F1-score:精确率和召回率的调和平均数,2 * precision*recall / (precision+recall)
# 微平均(Micro-averaging) 宏平均(Macro-averaging)
# Use threshold to define predicted labels and invoke sklearn's metrics with different averaging strategies.
def calculate_metrics(pred, target, threshold=0.5):
pred = np.array(pred > threshold, dtype=float)
return {'micro/precision': precision_score(y_true=target, y_pred=pred, average='micro'),
'micro/recall': recall_score(y_true=target, y_pred=pred, average='micro'),
'micro/f1': f1_score(y_true=target, y_pred=pred, average='micro'),
'macro/precision': precision_score(y_true=target, y_pred=pred, average='macro'),
'macro/recall': recall_score(y_true=target, y_pred=pred, average='macro'),
'macro/f1': f1_score(y_true=target, y_pred=pred, average='macro'),
'samples/precision': precision_score(y_true=target, y_pred=pred, average='samples'),
'samples/recall': recall_score(y_true=target, y_pred=pred, average='samples'),
'samples/f1': f1_score(y_true=target, y_pred=pred, average='samples'),
}
# 初始化模型
model = Resnext50(len(train_dataset.classes))
# 选择 训练模式 ,放到device上
model.train()
model = model.to(device)
# 选用 Adam 优化函数
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
# 如果gpu大于1,使用多块GPU来加速训练.
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model)
os.makedirs(save_path, exist_ok=True)
# 损失函数 选择 BCELoss()
criterion = nn.BCELoss()
# Tensoboard logger
logger = SummaryWriter(logdir)
#%%
# Run training
epoch = 0
iteration = 0
while True:
batch_losses = []
for imgs, targets in train_dataloader:
imgs, targets = imgs.to(device), targets.to(device)
# 优化函数 梯度归零
optimizer.zero_grad()
# 获取预测结果
model_result = model(imgs)
# 计算损失
loss = criterion(model_result, targets.type(torch.float))
batch_loss_value = loss.item()
loss.backward()
optimizer.step()
# tensorboard 相关
logger.add_scalar('train_loss', batch_loss_value, iteration)
batch_losses.append(batch_loss_value)
with torch.no_grad():
# 计算准确率
result = calculate_metrics(model_result.cpu().numpy(), targets.cpu().numpy())
for metric in result:
logger.add_scalar('train/' + metric, result[metric], iteration)
# 测试模型 ,每 test_freq 个 batch 测试一次
if iteration % test_freq == 0:
model.eval()
with torch.no_grad():
model_result = []
targets = []
for imgs, batch_targets in test_dataloader:
imgs = imgs.to(device)
model_batch_result = model(imgs)
model_result.extend(model_batch_result.cpu().numpy())
targets.extend(batch_targets.cpu().numpy())
result = calculate_metrics(np.array(model_result), np.array(targets))
for metric in result:
logger.add_scalar('test/' + metric, result[metric], iteration)
print("epoch:{:2d} iter:{:3d} test: "
"micro f1: {:.3f} "
"macro f1: {:.3f} "
"samples f1: {:.3f}".format(epoch, iteration,
result['micro/f1'],
result['macro/f1'],
result['samples/f1']))
model.train()
iteration += 1
loss_value = np.mean(batch_losses)
print("epoch:{:2d} iter:{:3d} train: loss:{:.3f}".format(epoch, iteration, loss_value))
# 保存模型
if epoch % save_freq == 0:
checkpoint_save(model, save_path, epoch)
epoch += 1
if max_epoch_number < epoch:
break
4.2.3 保存加载模型
保存模型的方法已经在 4.2.2 中提到了,这里是写成了一个函数,如下:
def checkpoint_save(model, save_path, epoch):
f = os.path.join(save_path, 'checkpoint-{:06d}.pth'.format(epoch))
if 'module' in dir(model):
torch.save(model.module.state_dict(), f)
else:
torch.save(model.state_dict(), f)
print('saved checkpoint:', f)
可以看到,这里选用的是 仅保存模型参数 的方式,那么加载模型的方法和多分类其实是类似的。
需要注意的是,这里我们新建了一个模型类,里面的代码和多分类也是差不多的,也是基于迁移学习的概念,替换最后的全连接层。
在加载模型的时候,我们需要引入这个类,或者说把这个类的代码复制一份在预测的python文件中。
这样还是比较麻烦的,所以我还是沿用多分类的方式,不重写类,直接加载模型,然后修改全连接层(其实就是把类 __init__ 函数的代码提出来)。
最终代码如下:
# 训练
model = models.resnext50_32x4d(pretrained=True)
model.fc = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(in_features=model.fc.in_features, out_features=len(train_dataset.classes))
)
# 下面的就一样了
# Switch model to the training mode and move it to GPU.
model.train()
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
# If more than one GPU is available we can use both to speed up the training.
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model)
os.makedirs(save_path, exist_ok=True)
# Loss function
criterion = nn.BCELoss()
# Run training
epoch = 0
iteration = 0
while True:
batch_losses = []
for imgs, targets in train_dataloader:
imgs, targets = imgs.to(device), targets.to(device)
....
# 保存模型
def checkpoint_save(model, save_path, epoch):
f = os.path.join(save_path, 'checkpoint-{:06d}.pth'.format(epoch))
if 'module' in dir(model):
torch.save(model.module.state_dict(), f)
else:
torch.save(model.state_dict(), f)
print('saved checkpoint:', f)
# 加载模型,和多分类是一样的
resnet = models.resnext50_32x4d(pretrained=True)
resnet.fc = nn.Sequential(
nn.Dropout(p=0.2),
nn.Linear(in_features=resnet.fc.in_features, out_features=len(classes))
)
param = torch.load(model_path, map_location=device)
resnet.load_state_dict(param)
resnet.eval()
resnet = resnet.to(device)
4.2.4 预测
多标签的预测返回又分为两种
- 根据概率的阈值返回,概率大于我们设置的阈值就算存在该标签
- 根据需要返回的标签数量返回,选择概率最大的几个标签返回
这是根据阈值的方式返回的代码:
# 对结果进行sigmoid处理
model_result = resnet(img_)
model_result = torch.sigmoid(model_result)
# 获取到第一张图片的所有标签的概率
raw_pred = model_result.cpu().detach().numpy()[0]
# 将大于0.5的置1,其余置0
raw_pred = np.array(raw_pred > 0.5, dtype=float)
# 只返回raw_pred 中为1的index对应的标签
predicted_labels = np.array(classes)[np.argwhere(raw_pred > 0)[:, 0]]
# print(predicted)
print('this picture maybe :', predicted_labels)
5. 问题
5.1 超参数有哪些?如何调整?
前面也有提到,用来定义模型结构或优化策略的参数叫作超参数 (Hyper-Parameter),包括
- 训练轮数epoch
- 每一批处理图片数量 batch_size
- 学习率 lr
- 正则化的系数
- 梯度下降的步长
- 神经网络层数
- 等等…。
超参数调整 是一个经验性很强的工作,需要不断试错调整。
5.2 如何选择神经网络模型?
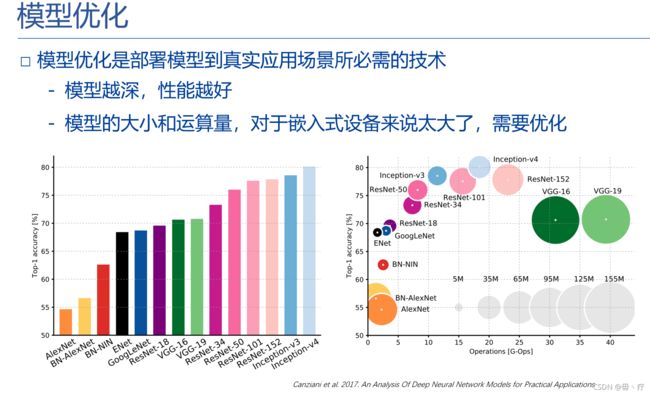
可以参考下图,不过有一点过时。
下面是我的理解,选择模型主要从以下方面考虑:
- 适用场景:是否与我们的应用场景相符(比如说识别语音的模型最好不要哪来做图像分类)
- 模型面世时间:一般来说,新出的模型比相同场景下旧的模型是要好一些的
- 模型复杂程度:根据GPU的性能,差的GPU可能无法运行过于复杂的模型
- 准确率:不同的模型可能需要不同的超参数才能达到最好的效果,那么我们可以对比他们最高的准确率,或者相同轮次所达到的最高准确率等。
其实,最重要的,也就是准确率!
5.3 怎么进行数据集标注?
其实对于现在我们简单的 多分类 和 多标签 分类,需求比较简单,可以自己写一个可视化页面来对图片分类。
市面上大部分的数据集标注产品都是针对目标检测或者语义分割的,比如 labelImg、labelme、精灵标注、VOTT、labelHub等。
多标签分类暂时是使用 VOTT,随便标一个框,在这个框里把图片所有标签标出来 (VOTT是支持一个框多个类的) ,标注完成导出,每个文件会对应一个json文件。
然后写一个简单的函数读里面的信息,变成我们想要的格式即可。
5.4 数据增强是什么?
数据增强又称为数据增广,数据扩增,它是对训练集进行变换,使训练集更丰富,从而让模型更具泛化能力。
(泛化能力(generalization ability)是指机器学习算法对新鲜样本的适应能力。可以简单理解为模型对未知数据的预测能力。)
深度神经网络一般都需要大量的训练数据才能获得比较理想的效果.在数
据量有限的情况下,可以通过数据增强(Data Augmentation)来增加数据量,提高模型鲁棒性,避免过拟合.目前,数据增强还主要应用在图像数据上,在文本等其他类型的数据上还没有太好的方法.
图像数据的增强主要是通过算法对图像进行转变,引入噪声等方法来增加
数据的多样性.增强的方法主要有几种:
- 旋转(Rotation):将图像按顺时针或逆时针方向随机旋转一定角度.
- 翻转(Flip):将图像沿水平或垂直方向随机翻转一定角度.
- 缩放(Zoom In/Out):将图像放大或缩小一定比例.
- 平移(Shift):将图像沿水平或垂直方法平移一定步长.
- 加噪声(Noise):加入随机噪声.
Pytorch的torchvision.transforms包已经实现了很多的图像转换方法,只需调用即可
5.5 transforms.Normalize参数是怎么确定的?
transforms.ToTensor()已经把值转换到了[0,1],代码中的标准化参数为
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
下面是摘自文章中的话
标准化的通常平均值和标准差不应该是[0.5、0.5、0.5]和[0.5、0.5、0.5]吗?为什么要设置这么奇怪的值?
使用Imagenet的均值和标准差是一种常见的做法。 它们是根据数百万张图像计算得出的。
如果要在自己的数据集上从头开始训练,则可以计算新的均值和标准差。
否则,建议使用Imagenet预设模型及其平均值和标准差。
是否使用ImageNet的均值和stddev取决于您的数据。 假设您的数据是“自然场景”†(人,建筑物,动物,变化的照明/角度/背景等)的普通照片,并假设您的数据集与ImageNet的偏向相同(就类平衡而言), 然后可以使用ImageNet的场景统计数据进行标准化。
如果照片以某种方式是“特殊的”(滤色,调整对比度,不常见的照明等)或“非自然的主题”(医学图像,卫星图像,手绘图等),那么我建议正确地对数据集进行规范化 在进行模型训练之前!
————————————————
版权声明:本文为CSDN博主「Hali_Botebie」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/djfjkj52/article/details/114357664
比如常见的mnist手写体识别,也有适合的参数
transforms.Normalize((0.1307,), (0.3081,))
我们可以写一个函数,来计算我们自己图片数据集的均值和方差。
5.6 LR学习率下降有什么作用?
学习率是在梯度下降的过程中更新权重时的超参数。
通常在训练一定epoch之后,都会对学习率进行衰减,从而让模型收敛得更好。学习率衰减有以下三种方式:
- 轮数衰减:每经过n个epochs后学习率减半
- 指数衰减:每经过n个epochs后学习率乘以一个衰减率
- 分数衰减:和指数衰减类似,不过公式不太一样
虽然采用学习率衰减的方法能让模型收敛的更好,但是如果遇到鞍点的时候,模型就没法继续收敛。
为解决这个问题,引入了 Cyclical Learning Rates(CRL)
5.7 model.train() 和 model.eval() 的区别?
简单来说,模型训练使用train(),验证使用eval().
model.train()
model.train()的作用是启用 Batch Normalization 和 Dropout。
如果模型中有BN层(Batch Normalization)和Dropout,需要在训练时添加model.train()。model.train()是保证BN层能够用到每一批数据的均值和方差。对于Dropout,model.train()是随机取一部分网络连接来训练更新参数。
model.eval()
model.eval()的作用是不启用 Batch Normalization 和 Dropout。
如果模型中有BN层(Batch Normalization)和Dropout,在测试时添加model.eval()。model.eval()是保证BN层能够用全部训练数据的均值和方差,即测试过程中要保证BN层的均值和方差不变。对于Dropout,model.eval()是利用到了所有网络连接,即不进行随机舍弃神经元。
训练完train样本后,生成的模型model要用来测试样本。在model(test)之前,需要加上model.eval(),否则的话,有输入数据,即使不训练,它也会改变权值。这是model中含有BN层和Dropout所带来的的性质。
在做one classification的时候,训练集和测试集的样本分布是不一样的,尤其需要注意这一点。(one classification: 应该是one class classification,一分类,只有一类的数据集)
Batch Normalization 和 Dropout 的内容可以参考 参考8
BN,Batch Normalization,就是在深度神经网络训练过程中使得每一层神经网络的输入保持相近的分布。
Dropout 是在训练过程中以一定的概率的使神经元失活,即输出为0,以提高模型的泛化能力,减少过拟合。
5.8 神经网络层数越多越好吗?
层数并非越多越好。
参考何凯明论文,这里有 原文 链接 和 译文 链接。
当更深的网络能够开始收敛时,暴露了一个退化问题:随着网络深度的增加,准确率达到饱和(这可能并不奇怪)然后迅速下降。
意外的是,这种下降不是由过拟合引起的,并且在适当的深度模型上添加更多的层会导致更高的训练误差
6. 参考
- 深度学习框架比较,我该选择哪一个?
- 迁移学习中文教程
- 使用 PyTorch 进行多标签图像分类(多输出模型)
- 使用 PyTorch 进行多标签图像分类:图像标记
- Pytorch中文文档
- pytorch 中pkl和pth的区别?
- model.train()和model.eval()用法和区别,以及model.eval()和torch.no_grad()的区别
- torchvision中Transform的normalize参数含义
- Pytorch 保存模型与加载模型
- PyTorch 实战(模型训练、模型加载、模型测试)
- 一文看懂学习率Learning Rate,从入门到CLR
- BN和Dropout在训练和测试时的差别