论文解读《Co-Correcting:Noise-tolerant Medical Image Classification via mutual Label Correction》
论文解读《Co-Correcting:Noise-tolerant Medical Image Classification via mutual Label Correction》
论文解读:协同校正:通过相互标签校正的抗噪声医学图像分类
期刊名: IEEE TRANSACTIONS ON MEDICAL IMAGING (医学影像学报)
期刊名缩写: IEEE T MED IMAGING
国际刊号 : 0278-0062
2021年影响因子/JCR分区: 10.048/Q1
CCF: B区
代码: 代码地址
论文地址: 论文地址
一、摘要:
深度学习需要大量带有标签的数据。在深度学习中处理标签噪声的方向没有被医学图像所注意到。
1)双网络互学习、2)标签概率估计、3)课程标签“校正”。
两个医学图像数据集,测试了6种最新的带噪声标签学习方法,并进行了比较研究。
实验表明,在不同的任务条件下,在不同的噪声比下,Co-Correcting 都能获得最佳的精度和泛化效果。
二、介绍:
2.1医学图像分类在临床治疗和教学任务中起着至关重要的作用。医学图像的自动分类是一个研究热点。由于病变外观的细粒度变化,这是一个挑战。最近,从早期筛选到确定子类别,使用深度学习的方法已经取得了令人印象深刻的效果,而且往往是前所未有的表现。
2.2 深度学习的成功归功于越来越多的大型和不断增长的数据集,以及更强大的计算硬件。大数据和可靠的标签有利于深度神经网络对参数的训练。医学图像采集困难,面临数据隐私问题,又需要专家耗时间去分析。
1) 收集更多的数据,现有的临床报告。
2) 少量标签来提高性能,半监督学习和伪标签。伪标签的数据受到标签噪音的影响。
伪标签学习:在标签数据上训练模型,然后使用经过训练的模型来预测无标签数据的标签,从而创建伪标签。此外,将标签数据和新生成的伪标签数据结合起来作为新的训练数据。不需要手动标记不加标签的数据,而是根据标签的数据给出近似的标签。
2.3 嘈杂的标签破坏了ground-truth(标准)标签,降低了分类器的准确性。深度神经网络先记忆清晰简单的实例,随着训练时间延长逐渐适应困难实例
2.4 医学图像数据集小,获取成本高。带噪声标签包含学习信息。其次,即使标签完美,也很难对医学图像分类。
专门为医学应用设计的抗噪声方法不足,在医学应用中,标签需要领域专业知识,错误的预测可能直接影响医生决策。
2.5 提出了一种用于医学图像分类的端到端且噪声容忍深度学习框架。该框架受Co-teaching+的启发,采用了同时训练两个网络的思想。它由三个核心组件组成:
1) 双网络架构
2) 一种新的概率模型
3) 一个课程式学习框架
2.6 提出的Co-Correcting框架可以利用噪声标签,并处理严重的噪声情况。在ISIC-Archive和PatchCamelyon,两个公共医学图像数据集上进行了实验。与目前最先进的方法相比,在噪声比为5% ~ 40%的情况下,Co-Correcting的精度模型最高。贡献如下:
(1) 基于互学习和标注校正的抗噪深度学习医学图像分类框架
(2) 双网络结构的基础上,新的标签概率模型
(3) 基于深度特征的无监督聚类学习的标签校正课程
(4)两个医学图像数据集ISIC-Archive和PatchCamelyon上,实现了最新的噪声标签学习方法。与最先进的方法相比,Co-Correcting在嘈杂的医疗数据集上获得了最高的精度。
三、相关工作
A:基于cnn的医学图像分类:
基于cnn的方法有各种策略来提高小数据集上的图像分类性能,研究了数据增强在图像分类中的有效性。一种具有前景的研究方向是通过自动化系统,在很少或没有人工监督的情况下,对大量数据集进行标记。然而,使用这些方法收集的实例通常存在较高的标签噪声,因此它们在医学成像中的适用性有限。因此,需要进一步努力研究处理嘈杂医疗数据集的方法。
B.带噪声标签的深度学习:
深度卷积神经网络过拟合损坏标签的能力会导致非常差的泛化性能。为了处理损坏的标签,一些基于深度学习的方法在损失函数中添加了正则化。利用正则化偏差来克服标签噪声问题。然而,它们永久地引入偏差,使得学习后的分类器几乎不能达到最优性能。其他方法估计的转移矩阵不引入正则化偏差,从而提高了分类器的精度。
表一在两个维度上比较了最新的LNL( learning with noisy labels噪声标签学习)方法:有没有累积错误和标签是否正确。
1)MentorNet为StudentNet提供了一个课程集中在标签的样本可能是正确的。它采用自定进度的方式来学习课程,并具有样本选择偏差造成的累积误差的负面属性。
2)Co-teaching同时对两个深度神经网络进行训练,并让它们在每个小批量(Mini-batch)下相互进行教学。在这个交换过程中,可以通过对等网络相互减少错误流。
3)Co-teaching+通过使用“不一致更新(Update by disagreement)”策略来改进Co-teaching,通过两个模型没有达成一致的数据来更新模型参数。几乎没有利用损坏标签中的信息。
4)PENCIL以一种端到端的方式完成同样的工作。该算法通过大量的训练以避免拟合噪声标签。但容易引入样本选择偏差,积累误差。
5)DivideMix利用半监督学习技术来学习带有噪声的标签。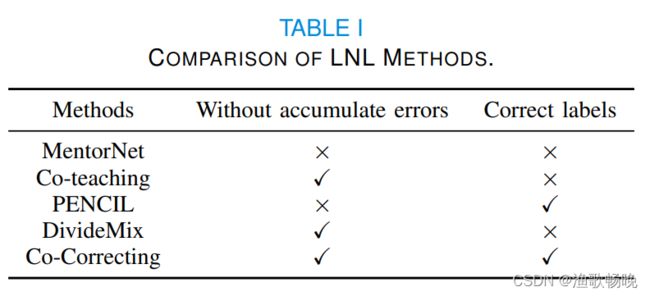
C 带有噪声标签的医学图像分类:
尽管已经考虑了一些方法来解决噪声标签问题。事实上,关于医学图像噪声标签问题的研究并不多。其中一个是将一般的LNL(噪声标签学习)方法应用于乳房x线分类任务,但它严重依赖于噪声标签分布假设。
四、Co-Correcting:医学图像分类框架
4.1 本文提出的Co-Correcting最初是为医学图像分类任务而设计的。
A:双网络架构、B:课程学习模块、C:标注纠错模块
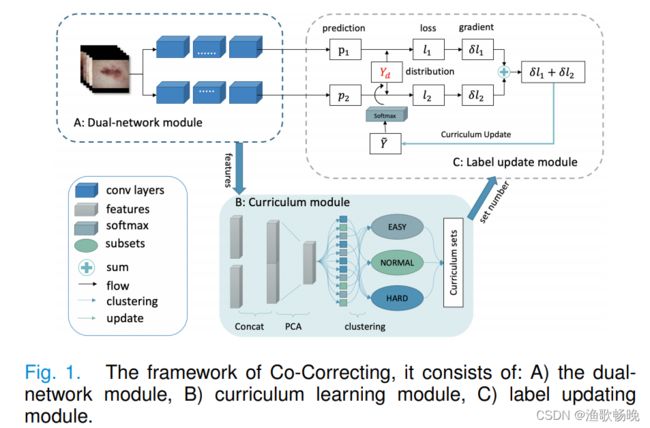
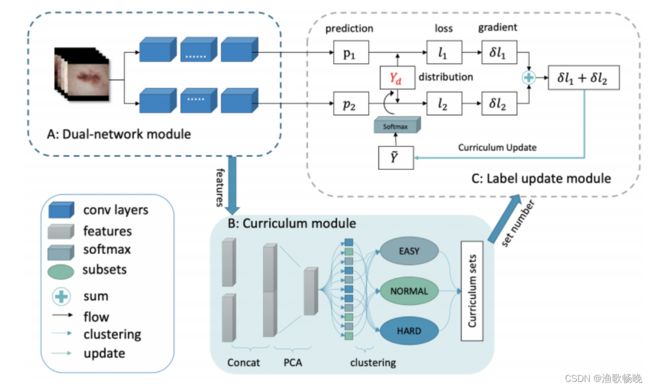
图1所示。Co-Correcting包括:双网络模块、课程学习模块、标签更新模块。PCA(Principal Component Analysis) 是一种常见的数据分析方式,常用于高维数据的降维,可用于提取数据的主要特征分量。
4.2 在Co-Correcting中,使用标签分布y^d来处理标签的不确定性。根据观察,在两个网络上的相互训练保持较好的对标签预测。可以更新标签分布y ^d后,从而可以对噪声进行概率校正。在更新网络参数的同时,网络会学习 概率标签分布。
4.3 引入了课程学习的概念。将样本投影到嵌入空间中,并根据所连接的特征进行聚类,之后这些类别按密度降序排列。随着步数的增加,逐渐添加要更新的标签组。
第一阶段:热身阶段,在模块A上进行相互学习。
第二阶段:计算模块B的课程。
第三阶段:在模块A和C上,学习参数并更新标签分布。
第四阶段:在模块A上使用修正后的标签对网络进行微调。
warm-up stage(热身阶段):刚开始的学习率应当设置得很低很低,这样可以保证网络能够具有良好的收敛性。较低的学习率会使得训练过程变得非常缓慢,因此这里会采用以较低学习率逐渐增大至较高学习率的方式实现网络训练的“热身”阶段,称为 warm-up stage。
4.4 A 双重网络体系结构:
在带噪声标签的学习研究中,一个具有挑战性的问题是设计可靠的标准来选择干净的样本。
Co-Correcting训练两个结构相同的网络。ResNet(残差网络)或DenseNet。
1)在正向传播中,两个网络分别对同一图像数据进行训练。2) 在反向传播中,根据一致更新原理,利用预测结果相同的样本所产生的梯度来更新参数。
算法倾向于先学习简单数据,然后再拟合标签噪声。因此,将损失较小的实例视为干净的实例,并在出现一致时收集它们的梯度。预测一致的样本具有更大的可信度,有利于噪声数据的筛选和校正。
与Co-teaching或Co-teaching+不同的是,Co-Correcting将计算潜在噪声样本的损失值(loss),在更新分类模型时,它们的梯度设置为零,这些损失值(loss)用于更新标签分布。
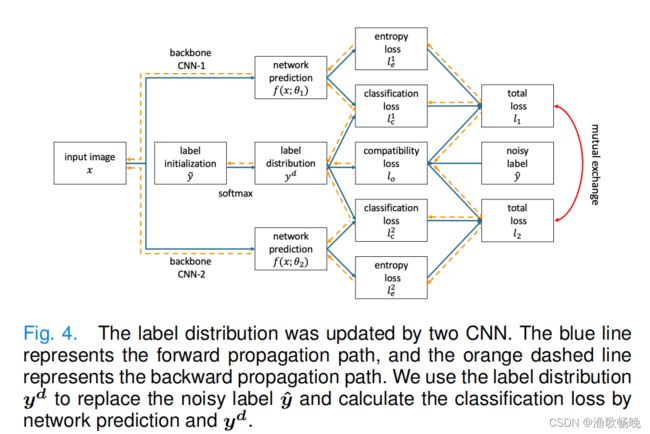
图4所示。两个CNN更新了标签分布。蓝线表示向前传播路径,橙色虚线表示向后传播路径。使用标签分布y^d 来代替有噪声的标签,并通过网络预测和y^d 计算分类损失。
B.标签概率建模与更新:
提出了深度标签分布学习算法来处理标签的不确定性。更新标签分布,噪声可以概率纠正。灵感来自PENCIL算法,用于一个包含n个图像样本的数据集。对于每个图像xi, Co-Correcting保持一个标签分布:
![]()
其中i为样本序号, i ∈[0, n)。它是对标签是否无噪声的概率估计。Yid被当作一个伪标签,用于计算损失值。
在图4中, Co-Correcting算法 同时训练两个网络来估计和更新y^d (标签分布)。两个网络之间的相互学习不会累积误差,从而最大限度地避免了噪声标签的干扰。辅助变量y~来辅助标签更新,有噪声的标签y^乘以一个常数K进行热编码。
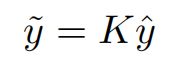
将标签校正与双网络结构相结合,有利于在两种网络损耗较大的医学图像中学习无噪声的困难样本。
C.标签矫正课程
4.5 困难样本与有噪声样本参杂在一起一直是有噪声标签学习中的一个难题。影响有:不准确的标签修改容易出错。无噪声的困难样本可能一直修正不正确,这对模型的准确性产生负面影响。
4.6 课程学习,从简单的例子开始,逐渐处理较难的例子。处理大量嘈杂的标签。
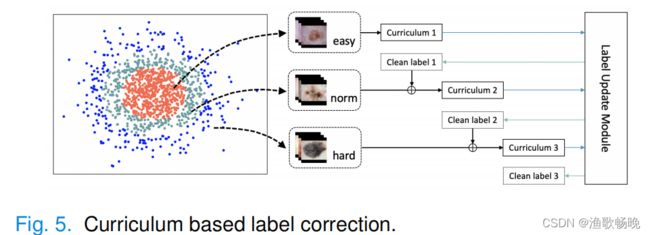
课程网络(CurriculumNet)通过测量数据的复杂性来设计学习课程。Co-Correcting提出了一种新的标签纠错课程(novel label correction curriculum),以避免标签的过早修改。它设计了一种按难度递增的标签纠错策略,纠错顺序是由易到难。
因此,目标是将整个训练集分解成多个子集,将子集从简单到复杂进行排序。
第二阶段学习课程(Curriculum module)根据课程设置,Co-Correcting纠正简单的错误。Co-Correcting将更新数据的范围扩展到比上层更困难的样本。这一程序在**第三阶段(label update module标签更新模块)**迭代,直到处理完所有课程。
五、实验与分析
5.1、实验装置
在ISIC-Archive和PatchCamelyon,两个医学图像数据集上进行了对比实验。
破坏标签来模拟真实情况。随机翻转标签来添加噪声。在训练集上加入所有的噪声模拟。测试集中都使用原标签。
我们选择了6种最新的带噪音标签学习(Learning-with-Noisy-Labels )分类方法作为基线。我们首先将基线方法应用于ISIC-Archive和PatchCamelyon上的医学图像分类任务。然后在相同的环境下,在不同的噪声比(5% ~ 40%)下,将Co-Correcting方法与之前提过方法进行比较。
5.2. ISIC档案的实验
1)ISIC-Archive数据集:ISIC-Archive数据集来自国际皮肤成像合作组织发起的黑色素瘤项目。该档案共有23906张皮肤病变图像。大多数图像是通过皮肤镜获得的。在实验中,我们选取了3324个样本,这些样本的注解经过病理学家的进一步确认。所选择的样本在积极和消极方面是平衡的。这是一个挑战,因为确认的样本通常很难被人区分。我们按照6:3:1的比例将它们分成训练集、测试集和验证集,以确保测试数据足够。所有图像的大小都被调整到224x224,并通过随机采用水平翻转、垂直翻转或图像旋转来扩充。
2)实施细节:ISIC-Archive上的所有实验都选择了ResNet-50作为骨干网。我们选择SGD作为优化器,其动量为0.9,权值衰减为0.001。由于GPU内存空间的限制,我们将最大批处理大小设置为32,训练步数设置为320。
3)结果与分析: 表三 显示了ISIC-Archive上所有比较方法的分类精度。
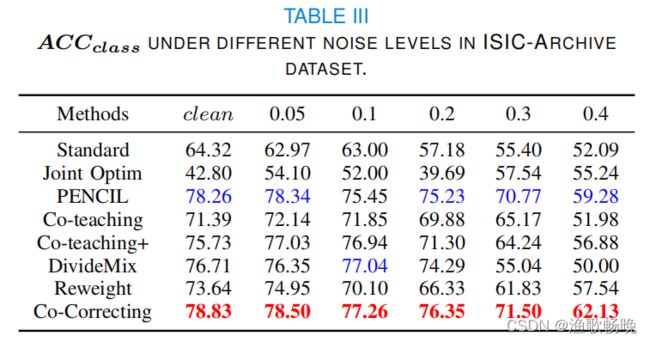
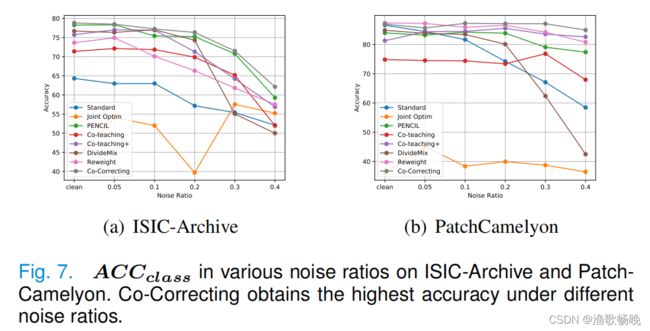
图7所示。ACCclass在ISIC-Archive和Patch-Camelyon上的各种噪声比。在不同的噪声比下,Co-Correcting的精度最高。
在LNL(噪声标签学习)方法中,在不同的噪声比下,Co-Correcting的精度最高。PENCIL位居第二。
1) 由于数据有限,Joint Optim的网络在第一阶段可能无法学习到一个好的模型。
2) Joint Optim会累积误差,导致医学图像分类准确率较低。
干净的标签上,大多数LNL(噪声标签学习)方法的准确性也超过了标准。实验中,Co-Correcting的准确率为78.83%,比标准在清洁标签上的准确率高22.6%。
1) 标准标签中可能存在模糊、不准确的标注。
2) 所提出的LNL机制抑制了网络对少量困难样本的早期过拟合,从而提高了模型的泛化程度。
3) Co-Correcting可以更准确地表示标签分布。

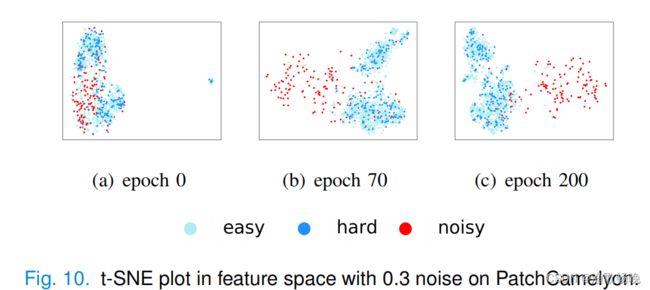
5.3 在图10中,红点代表噪声样本,蓝点代表困难样本。
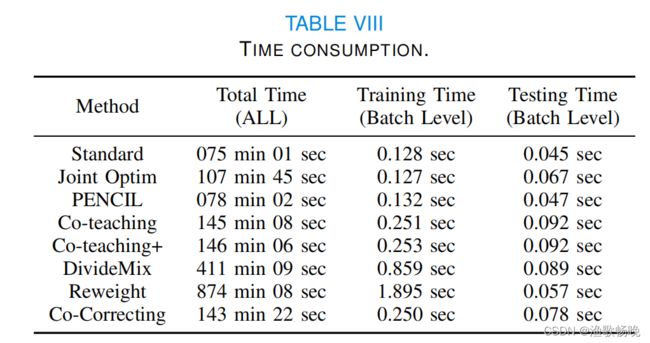
5.4 时间消耗分析: 训练时间和测试时间比Co-teaching、Co-teaching+、DivideMix更短。
六、结论
提出了一个在医学图像数据集上使用噪声标签进行学习的框架,命名为Co-Correcting。该框架由三个模块组成:
1)双网络架构,重点防止网络受到噪声标签的影响;
2)标注概率模块,对标注错误的数据进行校正;
3)标签矫正课程,提高标签矫正的稳定性。
ISIC-Archive医学图像数据集上测试和验证了所提出的方法。
在所有数据集的不同噪声比/类型下,Co-Correcting获得了最好的结果。作为未来的工作,本文提出的方法可以**调整以适应不平衡数据(即存在清晰干净样本和困难识别的样本)**的需要。