交叉熵损失函数公式_交叉熵损失函数 与 相对熵,交叉熵的前世今生
0. 总结 (本文目的是讨论理解一下相对熵(KL)与交叉熵(cross-entropy)的关系,以及相应的损失函数)

熵的本质: 信息量 log(1/p)的期望 的期望。
交叉熵:
物理意义: 用模拟分布Q去编码真实分布P所需要的平均编码长度(比特个数底数为2时
交叉熵损失函数:

(这里的连加sigma 是把一个样本分布的所有概率下的信息量进行的连加,例如我们就求一句话分类的损失, 假设类别有3个, 那么就会连加3次,属于第一个类别的概率。。+输入第二个类别的概率+。。)
相对熵:
物理意义: 用模拟分布Q去编码真实分布P所需要的额外比特个数。
熵的重要性质: (摘录)
**单调性**,即发生概率越高的事件,其所携带的信息熵越低。极端案例就是“太阳从东方升起”,因为为确定事件,所以不携带任何信息量。从信息论的角度,认为这句话没有消除任何不确定性。**非负性**,即信息熵不能为负。这个很好理解,因为负的信息,即你得知了某个信息后,却增加了不确定性是不合逻辑的。**累加性**,即多随机事件同时发生存在的总不确定性的量度是可以表示为各事件不确定性的量度的和。1.重点
1. 信息熵2. 交叉熵3. 相对熵 4. 交叉熵与相对熵关系5. 相对熵与交叉熵的损失函数2. 自信息与信息熵:
信息熵:
(E表示期望)
物理意义: 编码一个变量分布的最少比特数(期望比特数)。实际意义: 事件发生的概率越高, 信息熵越小。例如 p(xi) 的概率是1,对于X的取值只能是xi ,则H(x)=0.为什么是log?log的底应该是多少?
底为2, 因为计算机中是0,1编码,但是底设置为多少都可以根据需求而定
例子:
投掷一次, 要确定是不是A需要询问1次, 确定是不是B需要问2次(先问是不是A再问是不是B) 询问C问3次,询问D也是3次 所以编码有 1*1/2+2*1/4+3/8+3/8 = 7/4 (该例子原理引用自知乎某文因为是之前看过记忆下来的没有找到reference地址抱歉)3.交叉熵
物理意义:
用模拟分布Q去编码真实分布P所需要的平均编码长度比特个数例子:
假设 X~(A,B,C,D) 数据集,真实分布(1/2,1/2,0,0) 那么 H(X)=1/2*log(1/0.5)+1/2*log(1/0.5)=1如果我们模型预测的分布Q满足 (1/4,1/4,1/4,1/4) ,用这个分布去模拟真实分布:这里是2其实我们自然希望我们的模型的分布去编码真实分布时可以最小,但是最小并不一定是0,在这个例子里我们就希望最小为1(当然也不可能比1小).那么在很多时候交叉熵损失函数为什么都要逼近0呢?那是因为在这时候我们的H(p)=0例如P满足分布(1,0,0)是一个3分类问题,这时候H(P)=(1*log(1/1)+0+0)=0。可以看到上例中根据非真实分布q得到的平均编码长度H(p,q)大于根据真实分布p得到的平均编码长度H(p)。 那么H(p,q)-H(p)的物理意义就是当用模拟分布预测的编码长度减去真实编码长度就是 相对熵。(相对熵: 用错误分布去编码真实分布所消耗的额外比特数)3.1 交叉熵损失函数:
假如样本用来描述积极与消极,p真实样本符合(1,0)也就是p(积极)=1,p(消极=0) 模型预测分布时(0.6,0.4) q(积极)=0.6 q(消极)=0.4则有损失函数如下

其中 M:表示类别的数量。 p:表示真实样本分布, q:表示模型预测分布。上式中 p(x1) 表示当前样本输入第一个类目的概率, (例如判断一句话是 积极,消极还是中性,那么M就是3 表示每个样本有3种分布)(注意发现有些同学误以为这里的sigma是把很多句话的损失连加起来,不是哈,这里连加是把一句话所属的不同分布的信息熵连加得到了一句话的损失,如果有很多句话,进来是一个矩阵,每一行代表一句话,出去应该是一个列向量,每一个元素代表每一句话的损失,然后再求个平均损失即可。)当然上面二分类问题的损失函数等同于下面多分类的损失函数,只不过是把下面的$Sigma$进行了展开。 例如判断一句话:真实分布P X~{1,0} 而我们 预测分布Q X~{1/2,1/2}
当然了我们也可以 设置真实分布时P X~{1/2,1/2} 预测分布Q 是(1,0)带入公式会得到 -log(0) 趋于无线大。
4.相对熵: Kullback-Leibler divergence,KLD KL散度
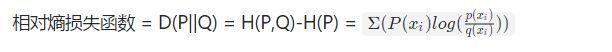
相对熵: 用错误分布(或者是模型分布)去编码真实分布所消耗的额外比特数。根据Gibbs' inequality可知,H(p,q)>=H(p)恒成立,当q为真实分布p时取等号。我们将由q得到的平均编码长度比由p得到的平均编码长度多出的bit数称为 相对熵。意义:它表示2个函数或概率分布的差异性:差异越大则相对熵越大,差异越小则相对熵越小,特别地,若2者相同则熵为0相对熵的性质:
4.1. 相对熵损失函数:
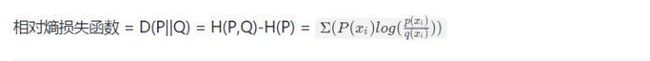
为啥不常用呢?其实主要是因为很多时候我们的真实分布都是分类问题例如:p样本符合分布(1,0,0,0) 4分类问题, 此时H(P)=0 所以相对熵损失函数在很多问题上 相对熵就是交叉熵损失函数。(大家可以想一想H(p)=0的场景)5. 损失函数的应用例子:
为了方便理解机器学习中损失函数输入,输出以及计算过程,这里给出一个自己假设的案例。 场景: 我们要对句子进行情感分类, 一个句子可以分成3个不同类目:{积极,中性,消极} 一个batch有2个句子,matrix(batch,embedding)经过一系列网络(例如lstm )再经过一个softmax之后得到如下矩阵:Q=
交叉熵损失函数:

相对熵损失函数:

结论:
其实我们用的是相对熵损失函数,只不过在很多情况下,H(P)=0 简化成了交叉熵。 但是理论上来看,我们更关注的是 模型分布编码真实分布 与 真实分布编码真实分布 的差距,这个差距是相对熵也就是KL div
由于匆忙尚有几个问题没有整理放出来:
- 为什么选用log?
- 如何证明 相对熵>=0 恒成立,关于jenson不等式的探讨.
- 交叉熵与极大似然
欢迎讨论,指正,引用(请注明出处)。

