ICCV2019 Best Paper: 仅用一张训练图像来进行图像生成
ICCV2019 Best Paper: 仅用一张训练图像来进行图像生成
这篇文章我们来了解一下ICCV2019 best paper: SinGAN: Learning a Generative Model from a Single Natural Image. 文章链接
前言
通常的深度学习模型都需要大量的数据进行训练,随着研究的逐步开展,研究人员已经意识到当前成果对数据的严重依赖,所以出现了各种在可获取数据受限的情况下进行的研究。例如,few-shot处理当某些类的在训练数据中出现较少甚至没有出现时,如何正确分类的问题;半监督是在部分标注的数据下学习;弱监督是在笼统标注或者存在错误标注的情况下学习。可见如何在数据受限的情况下达到理想的效果是现阶段热点问题,所以sinGAN中提出的,仅通过一张训练图像来进行图像生成具有较大的创新意义。
背景知识介绍
自从2014年 Goodfellow 提出GAN以来,在该框架下的探索层出不穷,现在GAN已经成为了CV领域极具魅力的研究方向。其中用于训练模型的min-max game也在各种其他类型的研究工作中被广泛运用。所以下面我们简要回顾一下GAN的基本原理。
本质上,GAN是从一个分布出发,将其转化为另一个目标分布。 初始的输入分布一般是高斯分布,目标分布是训练集中的图像等。那么,用一般的监督学习的思路来看,只需要合理的衡量当前输出的分布和目标分布的距离(例如,KL散度来衡量分布的差异程度),并构造损失,然后使用优化算法即可学出模型的分布。然而,这里有个关键问题,就是我们无法确定生成数据和某训练样本的对应关系。回想有监督学习,对于每个输入x,我们都有一个标签y表示类别等属性,这使得我们可以合理构建损失函数,如交叉熵等来学习。但对于一组生成的分布数据和一组训练数据分布,我们无法确定其中每个样本的对应关系,也就无法算KL散度,如何衡量分布的差异就成了问题。
Goodfellow 从另一个角度来解决了这个问题:如果生成分布和真实样本分布完全相同,我们就无法构造判别器来区分两个分布的数据。所以,我们在生成数据的同时,训练一个判别器D,来利用生成分布和真实分布的差距进行分类,那么当生成数据足够逼真,D就无法分辨,目标分布也就得到拟合了。所以min-max game的流程是:用当前生成数据和真实数据训练D,使D尽可能区分两类样本,然后固定D,训练G,G的优化目标是使D尽可能无法区分两类样本,重复这个过程,最终即可达到目的。
随后,为了提高该框架训练时的稳定性,结合先前MMD (Maximum Mean Discrepancy)的思想,提出了WGAN,加上梯度惩罚又提出了WGAN-GP。最终的对抗损失函数为:
L = E x − r e a l [ D ( x ) ] − E x − g e n e r a t e d [ D ( x ) ] + λ E [ ( ∣ ∣ ▽ x D ( x ) ∣ ∣ 2 − 1 ) 2 ] L = E_{x-real}[D(x)] - E_{x-generated}[D(x)] + \lambda E[(||\bigtriangledown_xD(x)||_2-1)^2] L=Ex−real[D(x)]−Ex−generated[D(x)]+λE[(∣∣▽xD(x)∣∣2−1)2]
训练中循环下式:
m i n G m a x D L min_Gmax_DL minGmaxDL
WGAN-GP的导出过程涉及较多数学推导,本文暂不介绍,大多GAN的应用中,只要清楚GAN的基本原理即可。
SinGAN
从GAN的实现过程可以看出,我们目标是拟合一个分布,通常使用GAN做图像生成,是将整个图片训练集作为一个目标分布来进行拟合,但现在我们只有一个图像,何来的分布呢?
sinGAN实际上是将图片分成小块,这些块构成了一组目标分布,使用GAN拟合这个分布就ok。这时候仔细想想,对比之前GAN在图像生成中的应用,这里有两个思考点:首先,原始GAN的思路中,生成的各个样本可能有相似性,如果G输入相似,则生成相似的图像,反之则可能生成完全不同的图像,但这些生成的图像实际上是没有严格的联系的,然而sinGAN生成的图像需要经过排列形成整幅图,如何排列?另外,之前真实数据的分布是多张图像,那么学习到的G生成介于两个训练样本之间的图像时,会呈现一种过渡的形态,那么sinGAN中,对于每个生成的小图块,也可能是介于两个样本之间的形态,但全局是基本不变的,所以可以预见到,这种设计将生成整体布局类似训练图片,局部细节有变化的新图像。
好,说了这么多对该模型的见解,下面来正式介绍一下模型结构。
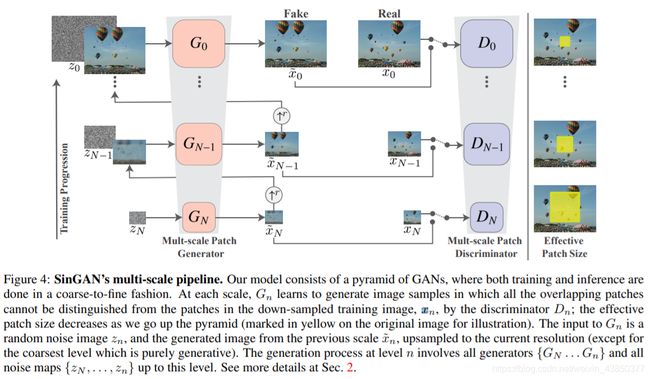
sinGAN是由多层作用于不同尺度的G和D构成的,下层尺度小,越往上层尺度越大。最底层的G输入纯噪声,上面的层将下一层G的输出上采样后加入噪声作为输入,判别器D对该层G的输出图像和真实图像下采样到同样维度的图像进行判别。其中G和D都是5层卷积核大小为3的CNN。对抗损失使用了 WGAN-GP 。另外,为了保证训练的稳定性,作者假定 存在某个固定的输入噪声完美对应到训练图像 ,所以训练过程中将一组噪声输入G,将输出与对应维度的真实图像算 MSEloss。这两个loss作为最终的优化准则。
模型可以说是简单易懂,但这是如何践行上述的原理的呢?sinGAN非常巧妙地设置了5层CNN,感受野仅为11(感受野的计算可参考这篇博客,这里只用了最简单的推算),而一般的深度神经网络中,整个网络计算下来,感受野一般都是输入图像维度的若干倍!这个11,就相当于将训练图像用滑动窗口的方式裁剪成了11*11的小块,feature map自然保证了这些生成的小块按照正确的方式排列成整个生成图像。
在最低层的维度中,11*11约占整幅图维度的1/4,低层维度主要是为了学习训练图像的整体布局,上面的层中,11*11只占图像的一小部分,所以上层主要学习了图像的细节纹理风格。
论文中给出了多种sinGAN的应用,这里简要介绍两种。最原始的一个效果,就是上面分析到的,生成指定训练图像的相似图像,整体构图相似,纹理相似,但有区别,如下图:

有必要提到的是,在这项应用中,一般不从最底层输入纯噪声开始进行图像生成,因为那样会导致图片structure产生大的变化,导致失真。较好的结果是从最小维度开始数,第二层、第三层开始进行生成。对这一点直观的理解是,最底层主要负责从纯随机噪声产生低分辨率图像,随后的层负责从低分辨率图像逐渐加入细节纹理,而图像生成的目的是生成整体相似、细节有差的图像,所以最底层不应该用纯随机噪声,那应该用什么呢?上文提到,训练过程中人为限定了一组固定的噪声完美匹配到训练图像,所以可以在底层使用这个固定的噪声(由于训练过程使得这个噪声经过G之后结果尽可能接近训练图像,所以生成的图像结构不会有大的变化),之后的层中加入随机的噪声,目的是产生不同的随机纹理细节。
另一个是图像风格融合,即在某风格的图像中插入一个外来的物体,并将该物体按照同样的绘图风格融入原图中:

实现的方式是将强行插入其他内容的图像,下采样到某一层G的输入维度,然后从该层的G开始,向上逐渐生成。
从这两个应用看出,虽然sinGAN名义上属于非条件GAN,但依然具有一定的局限性。例如,第一个应用中,必须使用训练时认为确定的初始噪声,“训练时固定的噪声”实际上是隐式的条件。第二个任务中,必须将原始图像的下采样,输入某层的G进而继续生成,显然也是以下采样图像为条件的生成。
文中给出了使用sinGAN来进行style transfer的例子,但我认为这基于两个前提:目标图片和待转图片基本构图相似,并且两个图像的基本色调相似。如果色调不同,则可能导致上层的G的输入与训练时差别较大,这有可能导致不能输出理想的纹理。所以不是完全无条件的style transfer。如果有可行的方式在中间进行bottle neck或许能够提供解决方法。
sinGAN确实能够在一些问题上取得很好的效果,并且其中利用图像的小块作为目标分布进行训练也具有一定的借鉴意义。