手动以及使用torch.nn实现前馈神经网络实验
其他文章
文章目录
- 一、任务1-手动实现前馈神经网络
-
- 1.1 任务内容
- 1.2 任务思路及代码
-
- 1.2.0数据集定义
- 1.2.1 手动实现前馈网络-回归任务
- 1.2.2 手动前馈网络-二分类任务
- 1.2.3 手动实现前馈神经网络-多分类
- 1.3 实验结果分析
- 二、任务2-利用torch.nn实现前馈神经网络
-
- 2.1 任务内容
- 2.2 任务思路及代码
-
- 2.2.1 torch.nn实现前馈神经网络-回归任务
- 2.2.2 torch.nn实现前馈神经网络-二分类
- 2.2.3 torch.nn实现前馈神经网络-多分类任务
- 2.3 实验结果分析
- 三、任务3-在多分类任务中使用至少三种不同的激活函数
-
- 3.1 任务内容
- 3.2 任务思路及代码
-
- 3.2.1画图函数
- 3.2.1 使用Tanh激活函数
- 3.2.2 使用Sigmoid激活函数
- 3.2.3 使用ELU激活函数
- 3.3实验结果分析
- 三、任务4-对多分类任务中的模型评估隐藏层层数和隐藏单元个数对实验结果的影响
-
- 4.1 任务内容
- 4.2 任务思路及代码
-
- 4.2.1一个隐藏层,神经元个数为[128]
- 4.2.2 两个隐藏层,神经元个数分别为[512,256]
- 4.2.3 四个隐藏层,神经元个数分别为[512,256,128,64]
- 4.3 实验结果分析
- A1 实验心得
一、任务1-手动实现前馈神经网络
1.1 任务内容
- 任务具体要求
手动实现前馈神经网络解决上述回归、二分类、多分类任务 - 任务目的
学习前馈神经网络在回归、二分类和多分类任务上的应用 - 任务算法或原理介绍
前馈神经网络组成

- 任务所用数据集
- 回归任务数据集:
- 数据集的大小为10000且训练集大小为7000,测试集大小为3000,数据集的样本特征维度p为500,且服从如下的高维线性函数: y = 0.028 + ∑ i = 1 p 0.0056 x i + ϵ y = 0.028 + \sum_{i=1}^{p}0.0056x_i + \epsilon y=0.028+i=1∑p0.0056xi+ϵ - 二分类数据集:
- 两个数据集的大小均为10000且训练集大小为7000,测试集大小为3000。
- 两个数据集的样本特征x的维度均为200,且分别服从均值互为相反数且方差相同的正态分布。
- 两个数据集的样本标签分别为0和1。 - MNIST手写体数据集:
- 该数据集包含60,000个用于训练的图像样本和10,000个用于测试的图像样本。
- 图像是固定大小(28x28像素),其值为0到1。为每个图像都被平展并转换为784
1.2 任务思路及代码
- 构建数据集
- 构建前馈神经网络,损失函数,优化函数
- 使用网络预测结果,得到损失值
- 进行反向传播,和梯度更新
- 对loss、acc等指标进行分析
1.2.0数据集定义
import time
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torchvision
from torch.nn.functional import cross_entropy, binary_cross_entropy
from torch.nn import CrossEntropyLoss
from torchvision import transforms
from sklearn import metrics
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 如果有gpu则在gpu上计算 加快计算速度
print(f'当前使用的device为{device}')
# 数据集定义
# 构建回归数据集合 - traindataloader1, testdataloader1
data_num, train_num, test_num = 10000, 7000, 3000 # 分别为样本总数量,训练集样本数量和测试集样本数量
true_w, true_b = 0.0056 * torch.ones(500,1), 0.028
features = torch.randn(10000, 500)
labels = torch.matmul(features,true_w) + true_b # 按高斯分布
labels += torch.tensor(np.random.normal(0,0.01,size=labels.size()),dtype=torch.float32)
# 划分训练集和测试集
train_features, test_features = features[:train_num,:], features[train_num:,:]
train_labels, test_labels = labels[:train_num], labels[train_num:]
batch_size = 128
traindataset1 = torch.utils.data.TensorDataset(train_features,train_labels)
testdataset1 = torch.utils.data.TensorDataset(test_features, test_labels)
traindataloader1 = torch.utils.data.DataLoader(dataset=traindataset1,batch_size=batch_size,shuffle=True)
testdataloader1 = torch.utils.data.DataLoader(dataset=testdataset1,batch_size=batch_size,shuffle=True)
# 构二分类数据集合
data_num, train_num, test_num = 10000, 7000, 3000 # 分别为样本总数量,训练集样本数量和测试集样本数量
# 第一个数据集 符合均值为 0.5 标准差为1 得分布
features1 = torch.normal(mean=0.2, std=2, size=(data_num, 200), dtype=torch.float32)
labels1 = torch.ones(data_num)
# 第二个数据集 符合均值为 -0.5 标准差为1的分布
features2 = torch.normal(mean=-0.2, std=2, size=(data_num, 200), dtype=torch.float32)
labels2 = torch.zeros(data_num)
# 构建训练数据集
train_features2 = torch.cat((features1[:train_num], features2[:train_num]), dim=0) # size torch.Size([14000, 200])
train_labels2 = torch.cat((labels1[:train_num], labels2[:train_num]), dim=-1) # size torch.Size([6000, 200])
# 构建测试数据集
test_features2 = torch.cat((features1[train_num:], features2[train_num:]), dim=0) # torch.Size([14000])
test_labels2 = torch.cat((labels1[train_num:], labels2[train_num:]), dim=-1) # torch.Size([6000])
batch_size = 128
# Build the training and testing dataset
traindataset2 = torch.utils.data.TensorDataset(train_features2, train_labels2)
testdataset2 = torch.utils.data.TensorDataset(test_features2, test_labels2)
traindataloader2 = torch.utils.data.DataLoader(dataset=traindataset2,batch_size=batch_size,shuffle=True)
testdataloader2 = torch.utils.data.DataLoader(dataset=testdataset2,batch_size=batch_size,shuffle=True)
# 定义多分类数据集 - train_dataloader - test_dataloader
batch_size = 128
# Build the training and testing dataset
traindataset3 = torchvision.datasets.FashionMNIST(root='E:\\DataSet\\FashionMNIST\\Train',
train=True,
download=True,
transform=transforms.ToTensor())
testdataset3 = torchvision.datasets.FashionMNIST(root='E:\\DataSet\\FashionMNIST\\Test',
train=False,
download=True,
transform=transforms.ToTensor())
traindataloader3 = torch.utils.data.DataLoader(traindataset3, batch_size=batch_size, shuffle=True)
testdataloader3 = torch.utils.data.DataLoader(testdataset3, batch_size=batch_size, shuffle=False)
# 绘制图像的代码
def picture(name, trainl, testl, type='Loss'):
plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体
plt.rcParams["axes.unicode_minus"]=False #该语句解决图像中的“-”负号的乱码问题
plt.title(name) # 命名
plt.plot(trainl, c='g', label='Train '+ type)
plt.plot(testl, c='r', label='Test '+type)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
print(f'回归数据集 样本总数量{len(traindataset1) + len(testdataset1)},训练样本数量{len(traindataset1)},测试样本数量{len(testdataset1)}')
print(f'二分类数据集 样本总数量{len(traindataset2) + len(testdataset2)},训练样本数量{len(traindataset2)},测试样本数量{len(testdataset2)}')
print(f'多分类数据集 样本总数量{len(traindataset3) + len(testdataset3)},训练样本数量{len(traindataset3)},测试样本数量{len(testdataset3)}')
当前使用的device为cuda
回归数据集 样本总数量10000,训练样本数量7000,测试样本数量3000
二分类数据集 样本总数量20000,训练样本数量14000,测试样本数量6000
多分类数据集 样本总数量70000,训练样本数量60000,测试样本数量10000
1.2.1 手动实现前馈网络-回归任务
# 定义自己的前馈神经网络
class MyNet1():
def __init__(self):
# 设置隐藏层和输出层的节点数
num_inputs, num_hiddens, num_outputs = 500, 256, 1
w_1 = torch.tensor(np.random.normal(0,0.01,(num_hiddens,num_inputs)),dtype=torch.float32,requires_grad=True)
b_1 = torch.zeros(num_hiddens, dtype=torch.float32,requires_grad=True)
w_2 = torch.tensor(np.random.normal(0, 0.01,(num_outputs, num_hiddens)),dtype=torch.float32,requires_grad=True)
b_2 = torch.zeros(num_outputs,dtype=torch.float32, requires_grad=True)
self.params = [w_1, b_1, w_2, b_2]
# 定义模型结构
self.input_layer = lambda x: x.view(x.shape[0],-1)
self.hidden_layer = lambda x: self.my_relu(torch.matmul(x,w_1.t())+b_1)
self.output_layer = lambda x: torch.matmul(x,w_2.t()) + b_2
def my_relu(self, x):
return torch.max(input=x,other=torch.tensor(0.0))
def forward(self,x):
x = self.input_layer(x)
x = self.my_relu(self.hidden_layer(x))
x = self.output_layer(x)
return x
def mySGD(params, lr, batchsize):
for param in params:
param.data -= lr*param.grad / batchsize
def mse(pred, true):
ans = torch.sum((true-pred)**2) / len(pred)
# print(ans)
return ans
# 训练
model1 = MyNet1() # logistics模型
criterion = CrossEntropyLoss() # 损失函数
lr = 0.05 # 学习率
batchsize = 128
epochs = 40 #训练轮数
train_all_loss1 = [] # 记录训练集上得loss变化
test_all_loss1 = [] #记录测试集上的loss变化
begintime1 = time.time()
for epoch in range(epochs):
train_l = 0
for data, labels in traindataloader1:
pred = model1.forward(data)
train_each_loss = mse(pred.view(-1,1), labels.view(-1,1)) #计算每次的损失值
train_each_loss.backward() # 反向传播
mySGD(model1.params, lr, batchsize) # 使用小批量随机梯度下降迭代模型参数
# 梯度清零
train_l += train_each_loss.item()
for param in model1.params:
param.grad.data.zero_()
# print(train_each_loss)
train_all_loss1.append(train_l) # 添加损失值到列表中
with torch.no_grad():
test_loss = 0
for data, labels in traindataloader1:
pred = model1.forward(data)
test_each_loss = mse(pred, labels)
test_loss += test_each_loss.item()
test_all_loss1.append(test_loss)
if epoch==0 or (epoch+1) % 4 == 0:
print('epoch: %d | train loss:%.5f | test loss:%.5f'%(epoch+1,train_all_loss1[-1],test_all_loss1[-1]))
endtime1 = time.time()
print("手动实现前馈网络-回归实验 %d轮 总用时: %.3fs"%(epochs,endtime1-begintime1))
epoch: 1 | train loss:0.93475 | test loss:0.92674
epoch: 4 | train loss:0.90341 | test loss:0.89801
epoch: 8 | train loss:0.88224 | test loss:0.88125
epoch: 12 | train loss:0.87340 | test loss:0.87269
epoch: 16 | train loss:0.86727 | test loss:0.86776
epoch: 20 | train loss:0.86387 | test loss:0.86064
epoch: 24 | train loss:0.85918 | test loss:0.85865
epoch: 28 | train loss:0.85352 | test loss:0.85443
epoch: 32 | train loss:0.85082 | test loss:0.84960
epoch: 36 | train loss:0.84841 | test loss:0.84680
epoch: 40 | train loss:0.84312 | test loss:0.84205
手动实现前馈网络-回归实验 40轮 总用时: 9.466s
1.2.2 手动前馈网络-二分类任务
# 定义自己的前馈神经网络
class MyNet2():
def __init__(self):
# 设置隐藏层和输出层的节点数
num_inputs, num_hiddens, num_outputs = 200, 256, 1
w_1 = torch.tensor(np.random.normal(0, 0.01, (num_hiddens, num_inputs)), dtype=torch.float32,
requires_grad=True)
b_1 = torch.zeros(num_hiddens, dtype=torch.float32, requires_grad=True)
w_2 = torch.tensor(np.random.normal(0, 0.01, (num_outputs, num_hiddens)), dtype=torch.float32,
requires_grad=True)
b_2 = torch.zeros(num_outputs, dtype=torch.float32, requires_grad=True)
self.params = [w_1, b_1, w_2, b_2]
# 定义模型结构
self.input_layer = lambda x: x.view(x.shape[0], -1)
self.hidden_layer = lambda x: self.my_relu(torch.matmul(x, w_1.t()) + b_1)
self.output_layer = lambda x: torch.matmul(x, w_2.t()) + b_2
self.fn_logistic = self.logistic
def my_relu(self, x):
return torch.max(input=x, other=torch.tensor(0.0))
def logistic(self, x): # 定义logistic函数
x = 1.0 / (1.0 + torch.exp(-x))
return x
# 定义前向传播
def forward(self, x):
x = self.input_layer(x)
x = self.my_relu(self.hidden_layer(x))
x = self.fn_logistic(self.output_layer(x))
return x
def mySGD(params, lr):
for param in params:
param.data -= lr * param.grad
# 训练
model2 = MyNet2()
lr = 0.01 # 学习率
epochs = 40 # 训练轮数
train_all_loss2 = [] # 记录训练集上得loss变化
test_all_loss2 = [] # 记录测试集上的loss变化
train_Acc12, test_Acc12 = [], []
begintime2 = time.time()
for epoch in range(epochs):
train_l, train_epoch_count = 0, 0
for data, labels in traindataloader2:
pred = model2.forward(data)
train_each_loss = binary_cross_entropy(pred.view(-1), labels.view(-1)) # 计算每次的损失值
train_l += train_each_loss.item()
train_each_loss.backward() # 反向传播
mySGD(model2.params, lr) # 使用随机梯度下降迭代模型参数
# 梯度清零
for param in model2.params:
param.grad.data.zero_()
# print(train_each_loss)
train_epoch_count += (torch.tensor(np.where(pred > 0.5, 1, 0)).view(-1) == labels).sum()
train_Acc12.append((train_epoch_count/len(traindataset2)).item())
train_all_loss2.append(train_l) # 添加损失值到列表中
with torch.no_grad():
test_l, test_epoch_count = 0, 0
for data, labels in testdataloader2:
pred = model2.forward(data)
test_each_loss = binary_cross_entropy(pred.view(-1), labels.view(-1))
test_l += test_each_loss.item()
test_epoch_count += (torch.tensor(np.where(pred > 0.5, 1, 0)).view(-1) == labels.view(-1)).sum()
test_Acc12.append((test_epoch_count/len(testdataset2)).item())
test_all_loss2.append(test_l)
if epoch == 0 or (epoch + 1) % 4 == 0:
print('epoch: %d | train loss:%.5f | test loss:%.5f | train acc:%.5f | test acc:%.5f' % (epoch + 1, train_all_loss2[-1], test_all_loss2[-1], train_Acc12[-1], test_Acc12[-1]))
endtime2 = time.time()
print("手动实现前馈网络-二分类实验 %d轮 总用时: %.3f" % (epochs, endtime2 - begintime2))
epoch: 1 | train loss:74.73962 | test loss:30.99814 | train acc:0.73736 | test acc:0.87167
epoch: 4 | train loss:38.78090 | test loss:14.13814 | train acc:0.91657 | test acc:0.92167
epoch: 8 | train loss:22.69315 | test loss:9.54545 | train acc:0.92279 | test acc:0.92450
epoch: 12 | train loss:20.70577 | test loss:9.12440 | train acc:0.92700 | test acc:0.92333
epoch: 16 | train loss:19.60378 | test loss:9.08764 | train acc:0.92971 | test acc:0.92317
epoch: 20 | train loss:18.85067 | test loss:9.12393 | train acc:0.93321 | test acc:0.92167
epoch: 24 | train loss:18.14947 | test loss:9.16395 | train acc:0.93586 | test acc:0.92183
epoch: 28 | train loss:17.56800 | test loss:9.18966 | train acc:0.93864 | test acc:0.92183
epoch: 32 | train loss:16.92899 | test loss:9.21986 | train acc:0.94200 | test acc:0.92217
epoch: 36 | train loss:16.28683 | test loss:9.25284 | train acc:0.94493 | test acc:0.92267
epoch: 40 | train loss:15.61791 | test loss:9.29863 | train acc:0.94836 | test acc:0.92200
手动实现前馈网络-二分类实验 40轮 总用时: 12.668
1.2.3 手动实现前馈神经网络-多分类
# 定义自己的前馈神经网络
class MyNet3():
def __init__(self):
# 设置隐藏层和输出层的节点数
num_inputs, num_hiddens, num_outputs = 28 * 28, 256, 10 # 十分类问题
w_1 = torch.tensor(np.random.normal(0, 0.01, (num_hiddens, num_inputs)), dtype=torch.float32,
requires_grad=True)
b_1 = torch.zeros(num_hiddens, dtype=torch.float32, requires_grad=True)
w_2 = torch.tensor(np.random.normal(0, 0.01, (num_outputs, num_hiddens)), dtype=torch.float32,
requires_grad=True)
b_2 = torch.zeros(num_outputs, dtype=torch.float32, requires_grad=True)
self.params = [w_1, b_1, w_2, b_2]
# 定义模型结构
self.input_layer = lambda x: x.view(x.shape[0], -1)
self.hidden_layer = lambda x: self.my_relu(torch.matmul(x, w_1.t()) + b_1)
self.output_layer = lambda x: torch.matmul(x, w_2.t()) + b_2
def my_relu(self, x):
return torch.max(input=x, other=torch.tensor(0.0))
# 定义前向传播
def forward(self, x):
x = self.input_layer(x)
x = self.hidden_layer(x)
x = self.output_layer(x)
return x
def mySGD(params, lr, batchsize):
for param in params:
param.data -= lr * param.grad / batchsize
# 训练
model3 = MyNet3() # logistics模型
criterion = cross_entropy # 损失函数
lr = 0.15 # 学习率
epochs = 40 # 训练轮数
train_all_loss3 = [] # 记录训练集上得loss变化
test_all_loss3 = [] # 记录测试集上的loss变化
train_ACC13, test_ACC13 = [], [] # 记录正确的个数
begintime3 = time.time()
for epoch in range(epochs):
train_l,train_acc_num = 0, 0
for data, labels in traindataloader3:
pred = model3.forward(data)
train_each_loss = criterion(pred, labels) # 计算每次的损失值
train_l += train_each_loss.item()
train_each_loss.backward() # 反向传播
mySGD(model3.params, lr, 128) # 使用小批量随机梯度下降迭代模型参数
# 梯度清零
train_acc_num += (pred.argmax(dim=1)==labels).sum().item()
for param in model3.params:
param.grad.data.zero_()
# print(train_each_loss)
train_all_loss3.append(train_l) # 添加损失值到列表中
train_ACC13.append(train_acc_num / len(traindataset3)) # 添加准确率到列表中
with torch.no_grad():
test_l, test_acc_num = 0, 0
for data, labels in testdataloader3:
pred = model3.forward(data)
test_each_loss = criterion(pred, labels)
test_l += test_each_loss.item()
test_acc_num += (pred.argmax(dim=1)==labels).sum().item()
test_all_loss3.append(test_l)
test_ACC13.append(test_acc_num / len(testdataset3)) # # 添加准确率到列表中
if epoch == 0 or (epoch + 1) % 4 == 0:
print('epoch: %d | train loss:%.5f | test loss:%.5f | train acc: %.2f | test acc: %.2f'
% (epoch + 1, train_l, test_l, train_ACC13[-1],test_ACC13[-1]))
endtime3 = time.time()
print("手动实现前馈网络-多分类实验 %d轮 总用时: %.3f" % (epochs, endtime3 - begintime3))
epoch: 1 | train loss:1072.38118 | test loss:178.98460 | train acc: 0.16 | test acc: 0.23
epoch: 4 | train loss:937.98462 | test loss:151.17164 | train acc: 0.45 | test acc: 0.45
epoch: 8 | train loss:642.72610 | test loss:104.61924 | train acc: 0.61 | test acc: 0.61
epoch: 12 | train loss:500.75464 | test loss:83.06618 | train acc: 0.65 | test acc: 0.64
epoch: 16 | train loss:429.94874 | test loss:72.26618 | train acc: 0.67 | test acc: 0.67
epoch: 20 | train loss:390.61571 | test loss:66.21291 | train acc: 0.69 | test acc: 0.68
epoch: 24 | train loss:365.24224 | test loss:62.19734 | train acc: 0.71 | test acc: 0.70
epoch: 28 | train loss:346.34411 | test loss:59.15829 | train acc: 0.73 | test acc: 0.72
epoch: 32 | train loss:330.86975 | test loss:56.63529 | train acc: 0.75 | test acc: 0.74
epoch: 36 | train loss:317.64237 | test loss:54.49284 | train acc: 0.76 | test acc: 0.75
epoch: 40 | train loss:306.07250 | test loss:52.63789 | train acc: 0.77 | test acc: 0.77
手动实现前馈网络-多分类实验 40轮 总用时: 285.410
1.3 实验结果分析
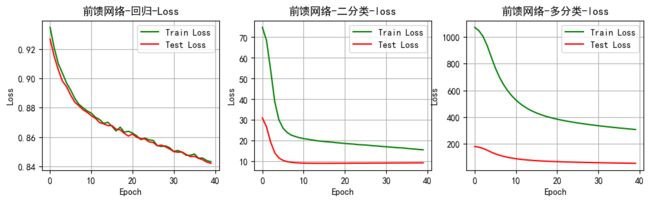
将上述前馈网络回归任务每一轮得训练和测试得损失值绘制成图表,如下图:
plt.figure(figsize=(12,3))
plt.title('Loss')
plt.subplot(131)
picture('前馈网络-回归-Loss',train_all_loss1,test_all_loss1)
plt.subplot(132)
picture('前馈网络-二分类-loss',train_all_loss2,test_all_loss2)
plt.subplot(133)
picture('前馈网络-多分类-loss',train_all_loss3,test_all_loss3)
plt.show()
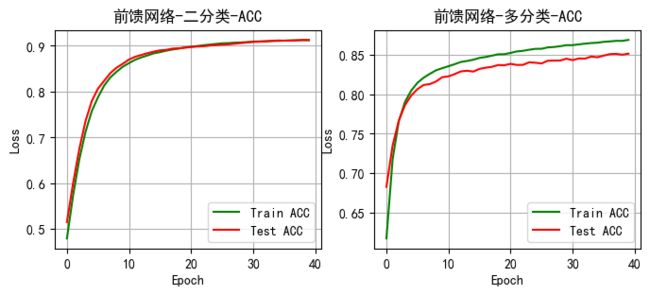
将上述的二分类和多分类的正确率绘制成表格
plt.figure(figsize=(8, 3))
plt.subplot(121)
picture('前馈网络-二分类-ACC',train_Acc12,test_Acc12,type='ACC')
plt.subplot(122)
picture('前馈网络-多分类—ACC', train_ACC13,test_ACC13, type='ACC')
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-40l3VFzC-1668230795956)(file://D:\System_Default\桌面\前馈神经网络实验\output_14_0.png?msec=1668230466074)]
由上面的Loss曲线图和Acc曲线图可以看出手动构建的前馈神经网络在回归问题,二分类问题和多分类问题上具有很好的效果
Loss曲线呈不断下降的效果,其中在二分类上下降最快,在多分类上下降较缓。这和数据集的特性和数据量的大小有关系。
ACC曲线不断随着训练的次数增多不断增加,由于本次实验设置的训练轮数为40次,所以多分类的ACC较低,如继续增大训练轮数,准确率会继续增加
时间相关信息和准确率
| Task | Epoch | Total Time | Max ACC |
|---|---|---|---|
| 回归 | 40 | 9.466s | xxxxx |
| 二分类 | 40 | 12.688s | 0.92 |
| 多分类 | 40 | 285.410 | 0.77 |
- 可见模型不同的数据集上的训练时间不大相同,主要是由于数据集的大小不一样
- 在各种数据集上,loss总体呈现下降趋势,acc呈现上升趋势,由于局部最优点的存在,acc可能会出现一定的摆幅,但总体上增加
二、任务2-利用torch.nn实现前馈神经网络
2.1 任务内容
- 任务具体要求
利用torch.nn实现前馈神经网络解决上述回归、二分类、多分类任务 - 任务目的
利用torch.nn实现的前馈神经网络完成对应的回归、分类等任务 - 任务算法或原理介绍
见任务一 - 任务所用数据集(若此前已介绍过则可略)
见任务一
2.2 任务思路及代码
- 构建回归、二分类、多分类数据集
- 利用torch.nn构建前馈神经网络,损失函数,优化函数
- 使用网络预测结果,得到损失值
- 进行反向传播,和梯度更新
- 对loss、acc等指标进行分析
2.2.1 torch.nn实现前馈神经网络-回归任务
from torch.optim import SGD
from torch.nn import MSELoss
# 利用torch.nn实现前馈神经网络-回归任务 代码
# 定义自己的前馈神经网络
class MyNet21(nn.Module):
def __init__(self):
super(MyNet21, self).__init__()
# 设置隐藏层和输出层的节点数
num_inputs, num_hiddens, num_outputs = 500, 256, 1
# 定义模型结构
self.input_layer = nn.Flatten()
self.hidden_layer = nn.Linear(num_inputs, num_hiddens)
self.output_layer = nn.Linear(num_hiddens, num_outputs)
self.relu = nn.ReLU()
# 定义前向传播
def forward(self, x):
x = self.input_layer(x)
x = self.relu(self.hidden_layer(x))
x = self.output_layer(x)
return x
# 训练
model21 = MyNet21() # logistics模型
model21 = model21.to(device)
print(model21)
criterion = MSELoss() # 损失函数
criterion = criterion.to(device)
optimizer = SGD(model21.parameters(), lr=0.1) # 优化函数
epochs = 40 # 训练轮数
train_all_loss21 = [] # 记录训练集上得loss变化
test_all_loss21 = [] # 记录测试集上的loss变化
begintime21 = time.time()
for epoch in range(epochs):
train_l = 0
for data, labels in traindataloader1:
data, labels = data.to(device=device), labels.to(device)
pred = model21(data)
train_each_loss = criterion(pred.view(-1, 1), labels.view(-1, 1)) # 计算每次的损失值
optimizer.zero_grad() # 梯度清零
train_each_loss.backward() # 反向传播
optimizer.step() # 梯度更新
train_l += train_each_loss.item()
train_all_loss21.append(train_l) # 添加损失值到列表中
with torch.no_grad():
test_loss = 0
for data, labels in testdataloader1:
data, labels = data.to(device), labels.to(device)
pred = model21(data)
test_each_loss = criterion(pred,labels)
test_loss += test_each_loss.item()
test_all_loss21.append(test_loss)
if epoch == 0 or (epoch + 1) % 10 == 0:
print('epoch: %d | train loss:%.5f | test loss:%.5f' % (epoch + 1, train_all_loss21[-1], test_all_loss21[-1]))
endtime21 = time.time()
print("torch.nn实现前馈网络-回归实验 %d轮 总用时: %.3fs" % (epochs, endtime21 - begintime21))
MyNet21(
(input_layer): Flatten(start_dim=1, end_dim=-1)
(hidden_layer): Linear(in_features=500, out_features=256, bias=True)
(output_layer): Linear(in_features=256, out_features=1, bias=True)
(relu): ReLU()
)
epoch: 1 | train loss:179.20287 | test loss:0.46446
epoch: 10 | train loss:0.26332 | test loss:0.16052
epoch: 20 | train loss:0.16424 | test loss:0.14287
epoch: 30 | train loss:0.11388 | test loss:0.13307
epoch: 40 | train loss:0.08121 | test loss:0.13289
torch.nn实现前馈网络-回归实验 40轮 总用时: 6.538s
2.2.2 torch.nn实现前馈神经网络-二分类
# 利用torch.nn实现前馈神经网络-二分类任务
import time
from torch.optim import SGD
from torch.nn.functional import binary_cross_entropy
# 利用torch.nn实现前馈神经网络-回归任务 代码
# 定义自己的前馈神经网络
class MyNet22(nn.Module):
def __init__(self):
super(MyNet22, self).__init__()
# 设置隐藏层和输出层的节点数
num_inputs, num_hiddens, num_outputs = 200, 256, 1
# 定义模型结构
self.input_layer = nn.Flatten()
self.hidden_layer = nn.Linear(num_inputs, num_hiddens)
self.output_layer = nn.Linear(num_hiddens, num_outputs)
self.relu = nn.ReLU()
def logistic(self, x): # 定义logistic函数
x = 1.0 / (1.0 + torch.exp(-x))
return x
# 定义前向传播
def forward(self, x):
x = self.input_layer(x)
x = self.relu(self.hidden_layer(x))
x = self.logistic(self.output_layer(x))
return x
# 训练
model22 = MyNet22() # logistics模型
model22 = model22.to(device)
print(model22)
optimizer = SGD(model22.parameters(), lr=0.001) # 优化函数
epochs = 40 # 训练轮数
train_all_loss22 = [] # 记录训练集上得loss变化
test_all_loss22 = [] # 记录测试集上的loss变化
train_ACC22, test_ACC22 = [], []
begintime22 = time.time()
for epoch in range(epochs):
train_l, train_epoch_count, test_epoch_count = 0, 0, 0 # 每一轮的训练损失值 训练集正确个数 测试集正确个数
for data, labels in traindataloader2:
data, labels = data.to(device), labels.to(device)
pred = model22(data)
train_each_loss = binary_cross_entropy(pred.view(-1), labels.view(-1)) # 计算每次的损失值
optimizer.zero_grad() # 梯度清零
train_each_loss.backward() # 反向传播
optimizer.step() # 梯度更新
train_l += train_each_loss.item()
pred = torch.tensor(np.where(pred.cpu()>0.5, 1, 0)) # 大于 0.5时候,预测标签为 1 否则为0
each_count = (pred.view(-1) == labels.cpu()).sum() # 每一个batchsize的正确个数
train_epoch_count += each_count # 计算每个epoch上的正确个数
train_ACC22.append(train_epoch_count / len(traindataset2))
train_all_loss22.append(train_l) # 添加损失值到列表中
with torch.no_grad():
test_loss, each_count = 0, 0
for data, labels in testdataloader2:
data, labels = data.to(device), labels.to(device)
pred = model22(data)
test_each_loss = binary_cross_entropy(pred.view(-1),labels)
test_loss += test_each_loss.item()
# .cpu 为转换到cpu上计算
pred = torch.tensor(np.where(pred.cpu() > 0.5, 1, 0))
each_count = (pred.view(-1)==labels.cpu().view(-1)).sum()
test_epoch_count += each_count
test_all_loss22.append(test_loss)
test_ACC22.append(test_epoch_count / len(testdataset2))
if epoch == 0 or (epoch + 1) % 4 == 0:
print('epoch: %d | train loss:%.5f test loss:%.5f | train acc:%.5f | test acc:%.5f' % (epoch + 1, train_all_loss22[-1],
test_all_loss22[-1], train_ACC22[-1], test_ACC22[-1]))
endtime22 = time.time()
print("torch.nn实现前馈网络-二分类实验 %d轮 总用时: %.3fs" % (epochs, endtime22 - begintime22))
MyNet22(
(input_layer): Flatten(start_dim=1, end_dim=-1)
(hidden_layer): Linear(in_features=200, out_features=256, bias=True)
(output_layer): Linear(in_features=256, out_features=1, bias=True)
(relu): ReLU()
)
epoch: 1 | train loss:79.07320 test loss:32.92679 | train acc:0.47936 | test acc:0.51533
epoch: 4 | train loss:67.24074 test loss:28.13028 | train acc:0.71221 | test acc:0.73583
epoch: 8 | train loss:56.03760 test loss:23.48878 | train acc:0.83114 | test acc:0.84050
epoch: 12 | train loss:47.73045 test loss:20.03178 | train acc:0.86971 | test acc:0.87617
epoch: 16 | train loss:41.48397 test loss:17.45700 | train acc:0.88629 | test acc:0.89017
epoch: 20 | train loss:36.86592 test loss:15.55864 | train acc:0.89643 | test acc:0.89600
epoch: 24 | train loss:33.54197 test loss:14.16518 | train acc:0.90271 | test acc:0.90067
epoch: 28 | train loss:31.02676 test loss:13.14387 | train acc:0.90700 | test acc:0.90467
epoch: 32 | train loss:29.09306 test loss:12.38178 | train acc:0.90971 | test acc:0.90917
epoch: 36 | train loss:27.60086 test loss:11.78166 | train acc:0.91136 | test acc:0.91133
epoch: 40 | train loss:26.49638 test loss:11.34545 | train acc:0.91279 | test acc:0.91233
torch.nn实现前馈网络-二分类实验 40轮 总用时: 15.395s
2.2.3 torch.nn实现前馈神经网络-多分类任务
# 利用torch.nn实现前馈神经网络-多分类任务
from collections import OrderedDict
from torch.nn import CrossEntropyLoss
from torch.optim import SGD
# 定义自己的前馈神经网络
class MyNet23(nn.Module):
"""
参数: num_input:输入每层神经元个数,为一个列表数据
num_hiddens:隐藏层神经元个数
num_outs: 输出层神经元个数
num_hiddenlayer : 隐藏层的个数
"""
def __init__(self,num_hiddenlayer=1, num_inputs=28*28,num_hiddens=[256],num_outs=10,act='relu'):
super(MyNet23, self).__init__()
# 设置隐藏层和输出层的节点数
self.num_inputs, self.num_hiddens, self.num_outputs = num_inputs,num_hiddens,num_outs # 十分类问题
# 定义模型结构
self.input_layer = nn.Flatten()
# 若只有一层隐藏层
if num_hiddenlayer ==1:
self.hidden_layers = nn.Linear(self.num_inputs,self.num_hiddens[-1])
else: # 若有多个隐藏层
self.hidden_layers = nn.Sequential()
self.hidden_layers.add_module("hidden_layer1", nn.Linear(self.num_inputs,self.num_hiddens[0]))
for i in range(0,num_hiddenlayer-1):
name = str('hidden_layer'+str(i+2))
self.hidden_layers.add_module(name, nn.Linear(self.num_hiddens[i],self.num_hiddens[i+1]))
self.output_layer = nn.Linear(self.num_hiddens[-1], self.num_outputs)
# 指代需要使用什么样子的激活函数
if act == 'relu':
self.act = nn.ReLU()
elif act == 'sigmoid':
self.act = nn.Sigmoid()
elif act == 'tanh':
self.act = nn.Tanh()
elif act == 'elu':
self.act = nn.ELU()
print(f'你本次使用的激活函数为 {act}')
def logistic(self, x): # 定义logistic函数
x = 1.0 / (1.0 + torch.exp(-x))
return x
# 定义前向传播
def forward(self, x):
x = self.input_layer(x)
x = self.act(self.hidden_layers(x))
x = self.output_layer(x)
return x
# 训练
# 使用默认的参数即: num_inputs=28*28,num_hiddens=256,num_outs=10,act='relu'
model23 = MyNet23()
model23 = model23.to(device)
# 将训练过程定义为一个函数,方便实验三和实验四调用
def train_and_test(model=model23):
MyModel = model
print(MyModel)
optimizer = SGD(MyModel.parameters(), lr=0.01) # 优化函数
epochs = 40 # 训练轮数
criterion = CrossEntropyLoss() # 损失函数
train_all_loss23 = [] # 记录训练集上得loss变化
test_all_loss23 = [] # 记录测试集上的loss变化
train_ACC23, test_ACC23 = [], []
begintime23 = time.time()
for epoch in range(epochs):
train_l, train_epoch_count, test_epoch_count = 0, 0, 0
for data, labels in traindataloader3:
data, labels = data.to(device), labels.to(device)
pred = MyModel(data)
train_each_loss = criterion(pred, labels.view(-1)) # 计算每次的损失值
optimizer.zero_grad() # 梯度清零
train_each_loss.backward() # 反向传播
optimizer.step() # 梯度更新
train_l += train_each_loss.item()
train_epoch_count += (pred.argmax(dim=1)==labels).sum()
train_ACC23.append(train_epoch_count.cpu()/len(traindataset3))
train_all_loss23.append(train_l) # 添加损失值到列表中
with torch.no_grad():
test_loss, test_epoch_count= 0, 0
for data, labels in testdataloader3:
data, labels = data.to(device), labels.to(device)
pred = MyModel(data)
test_each_loss = criterion(pred,labels)
test_loss += test_each_loss.item()
test_epoch_count += (pred.argmax(dim=1)==labels).sum()
test_all_loss23.append(test_loss)
test_ACC23.append(test_epoch_count.cpu()/len(testdataset3))
if epoch == 0 or (epoch + 1) % 4 == 0:
print('epoch: %d | train loss:%.5f | test loss:%.5f | train acc:%5f test acc:%.5f:' % (epoch + 1, train_all_loss23[-1], test_all_loss23[-1],
train_ACC23[-1],test_ACC23[-1]))
endtime23 = time.time()
print("torch.nn实现前馈网络-多分类任务 %d轮 总用时: %.3fs" % (epochs, endtime23 - begintime23))
# 返回训练集和测试集上的 损失值 与 准确率
return train_all_loss23,test_all_loss23,train_ACC23,test_ACC23
train_all_loss23,test_all_loss23,train_ACC23,test_ACC23 = train_and_test(model=model23)
你本次使用的激活函数为 relu
MyNet23(
(input_layer): Flatten(start_dim=1, end_dim=-1)
(hidden_layers): Linear(in_features=784, out_features=256, bias=True)
(output_layer): Linear(in_features=256, out_features=10, bias=True)
(act): ReLU()
)
epoch: 1 | train loss:657.80222 | test loss:74.67226 | train acc:0.617033 test acc:0.68250:
epoch: 4 | train loss:294.04037 | test loss:49.02613 | train acc:0.790417 test acc:0.78640:
epoch: 8 | train loss:240.90404 | test loss:42.03059 | train acc:0.825967 test acc:0.81290:
epoch: 12 | train loss:220.93427 | test loss:38.98449 | train acc:0.838167 test acc:0.82560:
epoch: 16 | train loss:209.56696 | test loss:37.69722 | train acc:0.846100 test acc:0.83220:
epoch: 20 | train loss:201.51846 | test loss:36.26622 | train acc:0.850833 test acc:0.83680:
epoch: 24 | train loss:195.08846 | test loss:35.30845 | train acc:0.856483 test acc:0.84050:
epoch: 28 | train loss:189.75432 | test loss:34.98433 | train acc:0.859967 test acc:0.84270:
epoch: 32 | train loss:185.09050 | test loss:34.47698 | train acc:0.863317 test acc:0.84540:
epoch: 36 | train loss:181.01641 | test loss:33.44194 | train acc:0.866517 test acc:0.84900:
epoch: 40 | train loss:177.54666 | test loss:33.11320 | train acc:0.868933 test acc:0.85150:
torch.nn实现前馈网络-多分类任务 40轮 总用时: 282.329s
2.3 实验结果分析
将上述前馈网络回归任务每一轮得训练和测试得损失值绘制成图表,如下图:
plt.figure(figsize=(12,3))
plt.subplot(131)
picture('前馈网络-回归-loss',train_all_loss21,test_all_loss21)
plt.subplot(132)
picture('前馈网络-二分类-loss',train_all_loss22,test_all_loss22)
plt.subplot(133)
picture('前馈网络-多分类-loss',train_all_loss23,test_all_loss23)
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8Snas3rX-1668230795957)(file://D:\System_Default\桌面\前馈神经网络实验\output_25_0.png?msec=1668230466074)]
将上述前馈网络回归任务每一轮得训练和测试得准确率值绘制成图表,如下图:
plt.figure(figsize=(8,3))
plt.subplot(121)
picture('前馈网络-二分类-ACC',train_ACC22,test_ACC22,type='ACC')
plt.subplot(122)
picture('前馈网络-多分类-ACC',train_ACC23,test_ACC23,type='ACC')
plt.show()
torch.nn实现的前馈网络在不同的数据集上表现出不同的效果,在回归问题中,损失函数下降速度极快,在前几轮就充分训练模型,并取得较好的效果。
在二分类中,loss值稳步下降,准确率逐步提升。
在多分类中,数据的规模较大,loss值在前6轮中下降较快,准确率提升较大,在后续的训练中,loss值相比前几轮下降较慢,准确率提升速度也不及前几轮。同时由于训练轮数的不足,模型并未没被完全训练好,可以通过增大epochs和lr来解决这个问题。
三、任务3-在多分类任务中使用至少三种不同的激活函数
3.1 任务内容
- 任务具体要求
在上述实现的多分类任务中使用至少三种不同的激活函数,本次实验使用分别使用四个激活函数:Relu、Tanh、Sigmoid、ELU - 任务目的
学习不同激活函数的作用 - 任务算法或原理介绍
同任务二中多分类 - 任务所用数据集(若此前已介绍过则可略)
同见任务二中多分类数据集
3.2 任务思路及代码
- 构建回归、二分类、多分类数据集
- 利用torch.nn构建前馈神经网络,损失函数,优化函数
- 构建不同的激活函数
- 使用网络预测结果,得到损失值
- 进行反向传播,和梯度更新
- 对loss、acc等指标进行分析
默认的网络为一个隐藏层,神经元个数为[256],激活函数为relu函数
3.2.1画图函数
def ComPlot(datalist,title='1',ylabel='Loss',flag='act'):
plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体
plt.rcParams["axes.unicode_minus"]=False #该语句解决图像中的“-”负号的乱码问题
plt.title(title)
plt.xlabel('Epoch')
plt.ylabel(ylabel)
plt.plot(datalist[0],label='Tanh' if flag=='act' else '[128]')
plt.plot(datalist[1],label='Sigmoid' if flag=='act' else '[512 256]')
plt.plot(datalist[2],label='ELu' if flag=='act' else '[512 256 128 64]')
plt.plot(datalist[3],label='Relu' if flag=='act' else '[256]')
plt.legend()
plt.grid(True)
3.2.1 使用Tanh激活函数
# 使用实验二中多分类的模型定义其激活函数为 Tanh
model31 = MyNet23(1,28*28,[256],10,act='tanh')
model31 = model31.to(device) # 若有gpu则放在gpu上训练
# 调用实验二中定义的训练函数,避免重复编写代码
train_all_loss31,test_all_loss31,train_ACC31,test_ACC31 = train_and_test(model=model31)
你本次使用的激活函数为 tanh
MyNet23(
(input_layer): Flatten(start_dim=1, end_dim=-1)
(hidden_layers): Linear(in_features=784, out_features=256, bias=True)
(output_layer): Linear(in_features=256, out_features=10, bias=True)
(act): Tanh()
)
epoch: 1 | train loss:614.44055 | test loss:72.26356 | train acc:0.635750 test acc:0.69720:
epoch: 4 | train loss:288.82626 | test loss:48.12523 | train acc:0.795517 test acc:0.79060:
epoch: 8 | train loss:238.00103 | test loss:41.35938 | train acc:0.826917 test acc:0.81620:
epoch: 12 | train loss:218.78028 | test loss:38.68566 | train acc:0.838517 test acc:0.82570:
epoch: 16 | train loss:207.86982 | test loss:37.10549 | train acc:0.845550 test acc:0.83370:
epoch: 20 | train loss:200.26399 | test loss:36.04159 | train acc:0.850883 test acc:0.83600:
epoch: 24 | train loss:194.53169 | test loss:35.21199 | train acc:0.854200 test acc:0.84010:
epoch: 28 | train loss:189.79102 | test loss:34.56415 | train acc:0.857767 test acc:0.84210:
epoch: 32 | train loss:185.85091 | test loss:33.98912 | train acc:0.860000 test acc:0.84430:
epoch: 36 | train loss:182.23084 | test loss:33.53722 | train acc:0.862267 test acc:0.84570:
epoch: 40 | train loss:179.19994 | test loss:33.02570 | train acc:0.864867 test acc:0.84950:
torch.nn实现前馈网络-多分类任务 40轮 总用时: 276.785s
3.2.2 使用Sigmoid激活函数
# 使用实验二中多分类的模型定义其激活函数为 Sigmoid
model32 = MyNet23(1,28*28,[256],10,act='sigmoid')
model32 = model32.to(device) # 若有gpu则放在gpu上训练
# 调用实验二中定义的训练函数,避免重复编写代码
train_all_loss32,test_all_loss32,train_ACC32,test_ACC32 = train_and_test(model=model32)
你本次使用的激活函数为 sigmoid
MyNet23(
(input_layer): Flatten(start_dim=1, end_dim=-1)
(hidden_layers): Linear(in_features=784, out_features=256, bias=True)
(output_layer): Linear(in_features=256, out_features=10, bias=True)
(act): Sigmoid()
)
epoch: 1 | train loss:995.80085 | test loss:150.25593 | train acc:0.435450 test acc:0.59430:
epoch: 4 | train loss:522.85408 | test loss:82.88827 | train acc:0.695683 test acc:0.69070:
epoch: 8 | train loss:370.86663 | test loss:61.70778 | train acc:0.738917 test acc:0.73290:
epoch: 12 | train loss:321.10749 | test loss:54.31158 | train acc:0.758450 test acc:0.75520:
epoch: 16 | train loss:294.92375 | test loss:50.29494 | train acc:0.775283 test acc:0.76910:
epoch: 20 | train loss:276.84129 | test loss:47.50861 | train acc:0.790217 test acc:0.78500:
epoch: 24 | train loss:263.20515 | test loss:45.42484 | train acc:0.800983 test acc:0.79580:
epoch: 28 | train loss:252.69126 | test loss:43.83572 | train acc:0.810400 test acc:0.80020:
epoch: 32 | train loss:244.45354 | test loss:42.66255 | train acc:0.817433 test acc:0.80570:
epoch: 36 | train loss:237.77932 | test loss:41.69042 | train acc:0.822250 test acc:0.80920:
epoch: 40 | train loss:232.28827 | test loss:40.81849 | train acc:0.826767 test acc:0.81430:
torch.nn实现前馈网络-多分类任务 40轮 总用时: 275.495s
3.2.3 使用ELU激活函数
# 使用实验二中多分类的模型定义其激活函数为 ELU
model33 = MyNet23(1,28*28,[256],10,act='elu')
model33 = model33.to(device) # 若有gpu则放在gpu上训练
# 调用实验二中定义的训练函数,避免重复编写代码m
train_all_loss33,test_all_loss33,train_ACC33,test_ACC33 = train_and_test(model=model33)
你本次使用的激活函数为 elu
MyNet23(
(input_layer): Flatten(start_dim=1, end_dim=-1)
(hidden_layers): Linear(in_features=784, out_features=256, bias=True)
(output_layer): Linear(in_features=256, out_features=10, bias=True)
(act): ELU(alpha=1.0)
)
epoch: 1 | train loss:614.85905 | test loss:71.33988 | train acc:0.622367 test acc:0.68490:
epoch: 4 | train loss:287.24690 | test loss:48.03733 | train acc:0.796583 test acc:0.79180:
epoch: 8 | train loss:239.79761 | test loss:41.75318 | train acc:0.826650 test acc:0.81640:
epoch: 12 | train loss:221.79838 | test loss:39.30922 | train acc:0.837183 test acc:0.82830:
epoch: 16 | train loss:211.67667 | test loss:37.82760 | train acc:0.843600 test acc:0.83100:
epoch: 20 | train loss:205.04718 | test loss:36.92112 | train acc:0.849783 test acc:0.83580:
epoch: 24 | train loss:199.93171 | test loss:36.18179 | train acc:0.852900 test acc:0.83730:
epoch: 28 | train loss:195.87270 | test loss:35.63731 | train acc:0.855517 test acc:0.83860:
epoch: 32 | train loss:192.41613 | test loss:35.19403 | train acc:0.858200 test acc:0.84070:
epoch: 36 | train loss:189.43485 | test loss:34.66838 | train acc:0.859967 test acc:0.84310:
epoch: 40 | train loss:186.66312 | test loss:34.41900 | train acc:0.862283 test acc:0.84550:
torch.nn实现前馈网络-多分类任务 40轮 总用时: 275.706s
3.3实验结果分析
对比使用不同的激活函数得到的loss曲线值和正确率
plt.figure(figsize=(16,3))
plt.subplot(141)
ComPlot([train_all_loss31,train_all_loss32,train_all_loss33,train_all_loss23],title='Train_Loss')
plt.subplot(142)
ComPlot([test_all_loss31,test_all_loss32,test_all_loss33,test_all_loss23],title='Test_Loss')
plt.subplot(143)
ComPlot([train_ACC31,train_ACC32,train_ACC33,train_ACC23],title='Train_ACC')
plt.subplot(144)
ComPlot([test_ACC31,test_ACC32,test_ACC33,test_ACC23],title='Test_ACC')
plt.show()
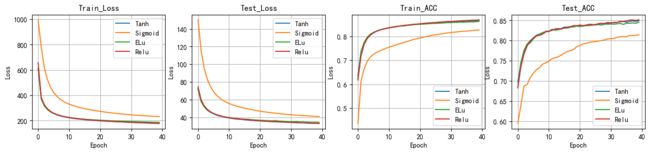
由上图loss值得变化和acc的变化,我们可以看出使用不同的激活函数构建的模型具有不同的效果
在本次实验中,四种损失函数的loss结果不断下降,acc值总体上随epoch呈上升趋势,但是两者的变化的速度随着epoch有着不同的表现。
由上图可清晰看出激活函数’Relu’,'Tanh’和’ELU’三者的曲线接近,在最后几轮epoch上的表现略有不同。在loss值和acc方面,但Sigmoid激活函数在minist数据集上的表现不如前三者。故对于该多分类数据集推荐使用前三者激活函数,效果会更好。
应用不同激活函数的模型的训练时间
| Act | Time | Acc | Rank |
|---|---|---|---|
| Relu | 282.329s | 0.851 | 1 |
| Tanh | 276.785s | 0.849 | 2 |
| Sigmoid | 275.495s | 0.814 | 4 |
| ELU | 275.706s | .8455 | 3 |
可以看出不同的激活函数,模型的训练时间会有较小的差异,ACC也有差异,其中表现最好的为Relu函数,表现最差的是Sigmoid激活函数
三、任务4-对多分类任务中的模型评估隐藏层层数和隐藏单元个数对实验结果的影响
4.1 任务内容
- 任务具体要求
使用不同的隐藏层层数和隐藏单元个数,进行对比实验并分析实验结果,为了体现控制变量原则,统一使用RELU为激活函数 - 任务目的
学习不同激活函数的作用 - 任务算法或原理介绍
同任务二中多分类 - 任务所用数据集(若此前已介绍过则可略)
同见任务二中多分类数据集
4.2 任务思路及代码
- 构建多分类数据集
- 利用torch.nn构建前馈神经网络,损失函数,优化函数
- 构建不同的隐藏层和隐藏神经元个数
- 使用网络预测结果,得到损失值
- 进行反向传播,和梯度更新
- 对loss、acc等指标进行分析
默认的网络为一个隐藏层,神经元个数为[256],激活函数为relu函数
4.2.1一个隐藏层,神经元个数为[128]
# 使用实验二中多分类的模型 一个隐藏层,神经元个数为[128]
model41 = MyNet23(1,28*28,[128],10,act='relu')
model41 = model41.to(device) # 若有gpu则放在gpu上训练
# 调用实验二中定义的训练函数,避免重复编写代码
train_all_loss41,test_all_loss41,train_ACC41,test_ACC41 = train_and_test(model=model41)
你本次使用的激活函数为 relu
MyNet23(
(input_layer): Flatten(start_dim=1, end_dim=-1)
(hidden_layers): Linear(in_features=784, out_features=128, bias=True)
(output_layer): Linear(in_features=128, out_features=10, bias=True)
(act): ReLU()
)
epoch: 1 | train loss:679.69445 | test loss:75.43487 | train acc:0.593267 test acc:0.67750:
epoch: 4 | train loss:296.15307 | test loss:49.17869 | train acc:0.788883 test acc:0.78460:
epoch: 8 | train loss:242.33678 | test loss:42.06035 | train acc:0.825617 test acc:0.81300:
epoch: 12 | train loss:221.84079 | test loss:39.23156 | train acc:0.837867 test acc:0.82340:
epoch: 16 | train loss:210.24818 | test loss:37.37779 | train acc:0.845400 test acc:0.83350:
epoch: 20 | train loss:201.90868 | test loss:36.61562 | train acc:0.850933 test acc:0.83330:
epoch: 24 | train loss:195.41365 | test loss:35.32518 | train acc:0.856033 test acc:0.84170:
epoch: 28 | train loss:190.04806 | test loss:34.82272 | train acc:0.859617 test acc:0.84480:
epoch: 32 | train loss:185.48290 | test loss:34.17104 | train acc:0.863700 test acc:0.84790:
epoch: 36 | train loss:181.42996 | test loss:33.58404 | train acc:0.866400 test acc:0.85040:
epoch: 40 | train loss:177.64588 | test loss:32.95457 | train acc:0.868917 test acc:0.85340:
torch.nn实现前馈网络-多分类任务 40轮 总用时: 256.331s
4.2.2 两个隐藏层,神经元个数分别为[512,256]
# 使用实验二中多分类的模型 两个隐藏层,神经元个数为[512,256]
model42 = MyNet23(2,28*28,[512,256],10,act='relu')
model42 = model42.to(device) # 若有gpu则放在gpu上训练
# 调用实验二中定义的训练函数,避免重复编写代码
train_all_loss42,test_all_loss42,train_ACC42,test_ACC42 = train_and_test(model=model42)
你本次使用的激活函数为 relu
MyNet23(
(input_layer): Flatten(start_dim=1, end_dim=-1)
(hidden_layers): Sequential(
(hidden_layer1): Linear(in_features=784, out_features=512, bias=True)
(hidden_layer2): Linear(in_features=512, out_features=256, bias=True)
)
(output_layer): Linear(in_features=256, out_features=10, bias=True)
(act): ReLU()
)
epoch: 1 | train loss:721.23681 | test loss:77.65762 | train acc:0.597033 test acc:0.66200:
epoch: 4 | train loss:290.02748 | test loss:48.21799 | train acc:0.785700 test acc:0.78350:
epoch: 8 | train loss:233.58869 | test loss:40.98045 | train acc:0.827000 test acc:0.81450:
epoch: 12 | train loss:214.90069 | test loss:38.51032 | train acc:0.840033 test acc:0.82750:
epoch: 16 | train loss:204.69288 | test loss:37.38850 | train acc:0.847967 test acc:0.83400:
epoch: 20 | train loss:197.78729 | test loss:35.71079 | train acc:0.853783 test acc:0.84090:
epoch: 24 | train loss:191.70526 | test loss:35.84411 | train acc:0.857483 test acc:0.83980:
epoch: 28 | train loss:187.40948 | test loss:34.54823 | train acc:0.861317 test acc:0.84490:
epoch: 32 | train loss:182.39799 | test loss:33.89679 | train acc:0.864967 test acc:0.84980:
epoch: 36 | train loss:179.16446 | test loss:33.09553 | train acc:0.867117 test acc:0.85320:
epoch: 40 | train loss:175.48380 | test loss:32.61282 | train acc:0.869417 test acc:0.85420:
torch.nn实现前馈网络-多分类任务 40轮 总用时: 278.211s
4.2.3 四个隐藏层,神经元个数分别为[512,256,128,64]
# 使用实验二中多分类的模型 四个隐藏层,神经元个数为[512,256,128,64]
model43 = MyNet23(3,28*28,[512,256,128],10,act='relu')
model43 = model43.to(device) # 若有gpu则放在gpu上训练
# 调用实验二中定义的训练函数,避免重复编写代码
train_all_loss43,test_all_loss43,train_ACC43,test_ACC43 = train_and_test(model=model43)
你本次使用的激活函数为 relu
MyNet23(
(input_layer): Flatten(start_dim=1, end_dim=-1)
(hidden_layers): Sequential(
(hidden_layer1): Linear(in_features=784, out_features=512, bias=True)
(hidden_layer2): Linear(in_features=512, out_features=256, bias=True)
(hidden_layer3): Linear(in_features=256, out_features=128, bias=True)
)
(output_layer): Linear(in_features=128, out_features=10, bias=True)
(act): ReLU()
)
epoch: 1 | train loss:826.53139 | test loss:91.98144 | train acc:0.439383 test acc:0.59060:
epoch: 4 | train loss:308.51752 | test loss:50.76393 | train acc:0.762300 test acc:0.76810:
epoch: 8 | train loss:240.67431 | test loss:41.38339 | train acc:0.819217 test acc:0.81350:
epoch: 12 | train loss:218.27895 | test loss:39.66492 | train acc:0.835900 test acc:0.82200:
epoch: 16 | train loss:205.91386 | test loss:36.80909 | train acc:0.845617 test acc:0.83080:
epoch: 20 | train loss:197.43931 | test loss:35.69519 | train acc:0.852383 test acc:0.83730:
epoch: 24 | train loss:191.46616 | test loss:37.09589 | train acc:0.857333 test acc:0.83610:
epoch: 28 | train loss:186.57159 | test loss:34.91067 | train acc:0.860400 test acc:0.84470:
epoch: 32 | train loss:181.72905 | test loss:33.75175 | train acc:0.863333 test acc:0.85110:
epoch: 36 | train loss:177.50958 | test loss:33.11897 | train acc:0.866917 test acc:0.84950:
epoch: 40 | train loss:174.15993 | test loss:32.97797 | train acc:0.868233 test acc:0.85210:
torch.nn实现前馈网络-多分类任务 40轮 总用时: 269.510s
4.3 实验结果分析
对比使用不同的隐藏层和隐藏神经元个数得到的loss曲线值和正确率
plt.figure(figsize=(16,3))
plt.subplot(141)
ComPlot([train_all_loss41,train_all_loss42,train_all_loss43,train_all_loss23],title='Train_Loss',flag='hidden')
plt.subplot(142)
ComPlot([test_all_loss41,test_all_loss42,test_all_loss43,test_all_loss23],title='Test_Loss',flag='hidden')
plt.subplot(143)
ComPlot([train_ACC41,train_ACC42,train_ACC43,train_ACC23],title='Train_ACC',flag='hidden')
plt.subplot(144)
ComPlot([test_ACC41,test_ACC42,test_ACC43,test_ACC23],title='Test_ACC', flag='hidden')
plt.show()
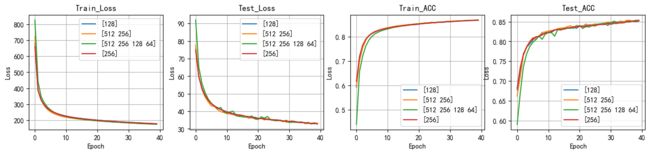
在本次实验中我对比了相同隐藏层数和不同隐藏神经元个数,以及不同隐藏层和不同隐藏神经元个数构成的前馈神经网络的效果。各种模型汇总如下:
| Model | Hidden layer num | Each hidden num | time | ACC | Rank |
|---|---|---|---|---|---|
| model41 | 1 | [128] | 256.331s | 0.853 | 2 |
| model42 | 2 | [512 256] | 278.211s | 0.854 | 1 |
| model43 | 3 | [512 256 108] | 269.510s | 0.852 | 3 |
| model23 | 1 | [256] | 282.329s | 0.851 | 4 |
- 从训练时间大致可以看出 隐藏层数越多,隐藏神经元个数越多,所需要的时间越久。
- 从准确率来看,并不是隐藏层数越多,隐藏神经元个数越多,准确率越高,可能会有相反的效果。
- 更多的隐藏层和隐藏神经元个数,可能会导致模型的过拟合现象,导致在训练集上准确率很高,但在测试集上准确率很低(注:在本次实验中未能体现)
A1 实验心得
学会手动构建前馈神经网络和利用torch.nn构建前馈神经网络解决回归、二分类、和多分类问题
- 实验中发现学习率的设置至关重要,如果学习率过大则会导致准确率下降的趋势,若学习率过小会导致模型需要更多时间收敛
- 实验过程中发现出现过拟合现象,通过修改相关参数得以纠正
- 学会程序模块话的编写,避免重复编写代码
- 对激活函数的选取有了更加清晰的认识
- 隐藏层的个数和隐藏层的神经元个数对模型有着很大的影响。