论文解读:《Multi-Branch-CNN:使用多分支卷积神经网络对离子通道相互作用肽进行分类》
Multi-Branch-CNN: Classification of ion channel interacting peptides using multi-branch convolutional neural network
- 1.文章概述
- 2.背景
- 3.数据
- 4.方法
-
- 4.1 特征选择
-
- 4.1.1 单一特征选择
- 4.1.2 最佳的K特征组合选择
- 4.2 实验方法
-
- 4.2.1 TML13方法
- 4.2.2 TML13-Stack方法
- 4.2.3 Multi-Branch-CNN方法
- 5.结果
-
- 5.1 单一特征选择
-
- 5.1.1 负样本生成方法的比较研究
- 5.1.2 传统机器学习方法的比较
- 5.2 Best-K 特征组合的选择
- 5.3 TML13 与 Multi-Branch-CNN 方法的比较(独立测试)
- 5.4 与 TML13-Stack 和 Single-Branch-CNN 方法的进一步比较研究
- 6.结论
文章地址:https://www.sciencedirect.com/science/article/pii/S0010482522004954
DOI:https://doi.org/10.1016/j.compbiomed.2022.105717
期刊:Computers in Biology and Medicine
影响因子/JCR分区:6.698/Q3
发布时间:2022年6月8日在线
GitHub:https://github.com/jieluyan/Multi-Branch-CNN
1.文章概述
对离子通道具有高亲和力的配体肽对于调节跨质膜的离子通量至关重要。这些肽现在被认为是许多疾病的潜在候选药物,例如心血管疾病和癌症。在这项工作中,作者开发了 Multi-Branch-CNN,这是一种具有多个输入分支的 CNN 方法,用于从特征内和特征间类型中识别三种类型的离子通道肽结合剂(钠、钾和钙)。至于其实际应用,需要能够识别与训练序列具有高或低相似性的新序列的预测模型。为此,作者在两个测试集上测试了开发的模型:一个通用测试集,包括与训练集具有不同相似度的序列;以及一个新的测试集,仅包含与训练集序列几乎没有相似之处的序列。最终的实验结果表明,Multi-Branch-CNN 方法的性能优于13种传统机器学习算法,钠、钾和钙离子通道在测试集的准确率分别提高了3.2%、1.2%和2.3%,在新测试集上分别提高了8.8%、14.3%和14.6%。作者通过将 Multi-Branch-CNN 与具有一个输入分支 (Single-Branch-CNN) 和集成方法 (TML13-Stack) 的标准 CNN 方法进行比较来确认它的有效性。
2.背景
离子通道是在膜中形成孔的跨膜蛋白家族。它们调节细胞中阳离子或阴离子的流入和流出。由于离子通道在可兴奋和不可兴奋组织中都发挥着重要作用,因此它们是许多疾病的有吸引力的治疗靶点,包括神经系统疾病、心血管和代谢疾病以及癌症。结合离子通道的肽在调节穿过质膜的离子通量中起重要作用,它们是常用于各种离子通道和受体的药理学表征的分子。然而,由于生物物理实验的复杂性,测量离子通道活性的实验方法并不总是容易执行。随着高通量筛选的进步,可以获得表达肽序列的生成,然而,这些大量序列数据的准确功能注释仍然是一个挑战。通过计算方法预测蛋白质的离子通道抑制肽有助于识别候选序列以进行进一步实验。
虽然有一些计算工作可以解决离子通道的肽预测,但其中大多数使用有限的机器学习 (ML) 和特征编码方法。此外,没有发布可用的预测工具,专用于离子通道相互作用肽的公共数据库也很有限。
近年来,人们对使用 ML 或深度学习 (DL) 方法预测功能性肽的兴趣急剧增加。特别是,卷积神经网络 (CNN) 已被证明在学习肽的编码序列模式方面是成功的。 CNN 的优点是通过卷积层自动和分层学习近端和远端特征。
在目前的工作中,作者提出了一种名为 Multi-BranchCNN 的深度学习方法,用于基于 CNN 的离子通道肽预测。术语多分支背后的想法是,预测器不仅可以通过多个输入 CNN 分支接受和学习来自单一特征类型(即特征内)的信息,而且还有不同特征类型(即特征间)之间的信息。机器学习中一个特殊挑战是从大量不同的蛋白质或肽描述符中确定其中哪些包含与手头的预测任务高度相关的特征。使用特征选择方法的详尽或启发式搜索总是计算密集型的,并且可能不会导致最佳模型。由于每种特征类型都包含完整但不同的肽视图,因此应将特征类型中的所有特征视为一个集合。尽管在文献中没有明确讨论,但普遍认为,当一个特征类型被选择用于模型构建时,它的所有特征都将被包括在内。然而,传统的特征选择方法,如 mRMR(最大相关最小冗余)、ANOVA(方差分析)和 IFS(增量特征选择)独立考虑每个特征,并在选择过程而不是考虑整个特征集。当发现多种特征类型在学习特定数据集时表现同样出色时,通常情况下,这些特征通常组合形成特征矩阵作为学习引擎的输入;或者,可以使用每种特征类型来训练一个单独的模型,最后将这些不同的模型组合起来产生一个预测。使用Multi-BranchCNN,可以将一组性能良好的特征类型共同包含在学习过程中,并且可以一起学习来自特征内和特征间的信息。在 Multi-Branch-CNN 与 13 种传统 ML 方法 (TML13) 的比较研究中,Multi-Branch-CNN 在一般测试用例(跨越与训练集中不同相似度的测试序列)中表现出更好的性能。然而,当测试新序列时——与训练集中的序列几乎没有或没有序列相似性的序列——与 TML13 相比,Multi-Branch-CNN 显示出分类准确性的显着提高。此外,为了确保 Multi-Branch-CNN 的有效性,将其性能与只有 1 个 CNN 输入分支和一个集成方法 TML13-Stack 的 Single-Branch-CNN 进行了比较。在这项工作中,作者还探索了准备负数据集的不同方法,并表明正确处理的负数据对于开发可靠的预测模型至关重要。
3.数据
- 正样本
钠(本文称为 Na-pep)、钾(K-pep)、钙(Ca-pep)通道的已知离子通道相互作用肽使用关键字从 Swiss-Prot数据库下载。对于每个数据集,作者首先删除了包含非天然或任意氨基酸(B、J、O、U、Z、X)的肽序列。对于每个有效序列,如果存在翻译后修饰部分,则仅提取链或肽子部分中指定的最长序列片段,即成熟蛋白质中多肽链或活性肽的范围。长于 100 个氨基酸的序列被删除,重复的序列被删除。从 Kalium 数据库下载钾通道的其他相互作用肽,并进行与上述相同的预处理步骤。最后,获得了728个Na-pep、580个K-pep 和246个Ca-pep。收集到的序列数量见下表。三个通道的预处理序列都可以在补充文件中下载,这样CDHit负数据生成方法就可以生成相应的负序列。这些肽的序列长度分布和 AAC 如图 5 所示。
该截止值的选择是基于观察到从在线收集的大多数离子通道抑制肽数据库的长度低于 100 个残基。只可以看到存在少数情况,例如KaliumDB 中有 5 个序列非常长且大于 10,000。事实上,在最终数据集中,序列的最大长度只有 83 个残基,如表 5 所示。


- 负样本
虽然文献中通常会报道负样本数据,但负样本数据却很可怕。为了监督机器学习,作者从 Swiss-Prot 下载了没有已知通道相互作用活动的序列,关键字 NOT goa:(“ion channel inhibitor activity [0008200]”) NOT goa:(“toxin activity [0090729]” ) NOT “ion channel impairing toxin” length:[1 TO 100]" 审查:是的。按照与正样本数据相同的预处理程序,去除了含有非天然氨基酸的肽序列和阴性样本中的重复肽。在同时,还通过将负样本与所有三个通道的正数据集进行比较,去除了负样本中的冗余序列,最终得到了 37437 个负样本。 - 数据集拆分:训练、测试和新测试
通常,在开发 ML 模型时,通过将整个数据集随机拆分为训练集和测试集来划分整个数据集。这样,测试集可能包含与训练序列相似的未知比例的混合序列,从而难以评估所开发模型的泛化性。为了获得更可靠的评估,作者建议使用两个不同的测试集:首先,一个通用测试集,包括从收集的数据中提取的序列,为了避免偏差,开发了一种从每个序列簇中挑选样本的受控程序,以确保测试样本与训练集中的序列具有广泛的相似性水平;其次,一个更具挑战性的测试集,这里称为新测试集,它仅包含无法与使用 CD-HIT 的训练集中的任何序列进行聚类的样本。因此,这些序列与训练集中的序列几乎没有序列相似性。需要强调的是,任意两个数据集之间不存在冗余或高度相似的序列(大于 90% 的相似性)。
具体来说,所有三个离子通道(钠、钾、钙)的训练集、测试集和新测试集都是根据图 6 中描述的工作流程创建的。我们首先使用 CD-HIT [30] 使用阈值为 0.4,字长为 2。对于包含两个或多个成员肽的每个簇,随机选择一个肽作为中间测试数据。对于无法聚类的肽,即在该组中没有发现相似的序列,它们被合并在一起形成新的测试数据集。
具体来说,所有三个离子通道(钠、钾、钙)的训练集、测试集和新测试集都是根据图 6 中描述的工作流程创建的。首先使用 CD-HIT 使用阈值为 0.4,字长为 2。对于包含两个或多个成员肽的每个簇,随机选择一个肽作为中间测试数据。对于无法聚类的肽,即在该组中没有发现相似的序列,它们被合并在一起形成新的测试数据集。CD-HIT 仅处理长度大于 10 氨基酸的序列,为避免数据丢失,这些较短的序列被添加回新的测试集。随后,未选择的肽用作训练数据。作者调整了训练集中和中间测试集中的样本数量,以保持训练:中间测试的比例为 9:1。最后,将新测试集和中间测试集的序列合并为测试集。
作者测试了四种不同的方法来生成负数据集。通过比较研究结果表明,提供可靠模型和稳定性能的最佳方法是使用 CDHit。所以作者描述了使用 CDHit 生成负数据集。负训练集、测试集和新测试集是通过以与正数据集相同的方式从聚集的负序列中提取序列来创建的。负集中的序列数等于正集中的序列数,即创建了平衡数据集。为避免长度偏差,仔细选择阴性组中的肽,以使该组的长度分布与相应的正样本组匹配。用于模型构建和测试的最终平衡训练集、测试集和新测试集列于表 6 中。

- 产生负数据的四种方法
负样本的数量远远超过正样本的数量。 Na-pep、K-pep 和 Ca-pep 的正负数据之间的不平衡分别约为 1:50、1:65 和 1:150。众所周知,高度不平衡的数据难以训练,导致创建具有高特异性但灵敏度太低的不切实际的预测模型。为了创建支持可靠预测模型开发的平衡数据集,我们探索了四种不同的方法来生成平衡的负训练集、测试集和新测试集。
(1)正常的:通过从从 SwissProt 下载的负肽序列中随机选择肽来生成负数据集。在这个过程中,负数据集的数量和长度分布故意与正数据集的数量和长度分布相匹配。正样本组与负样本组的冗余肽被去除。
(2)CDHit:如上所述,首先使用 CDHit 将负数据集分为训练集、测试集和新测试集。然后,对于每个通道(钠、钾和钙通道)的训练、测试和新测试正样本数据集,从训练、测试和新测试集中随机选择相同数量的肽作为负样本,并保持相应的正负样本数据集之间的长度分布相同。从正样本组到负样本组的冗余肽被去除。
(3)随机:对于正样本数据集中的每个序列(钠、钾和钙离子通道的训练、测试和新测试集),通过将模板中的每个残基随机突变为任何天然氨基酸。在这样做时,假设具有随机序列的肽是离子通道相互作用肽的概率非常低。
(4)乱序:作者没有改变序列中的残基,而是改组正肽序列中的氨基酸以产生负样本序列。同样,假设随机序列肽是离子通道相互作用肽的概率非常低。
4.方法
4.1 特征选择
iFeature 包用于通过生成 21 种不同的特征类型(如 AAC、CSKAAP、DPC 等)和 233 个不同的 PseKRAAC 特征组来对肽序列进行数字编码。本研究中使用的所有特征类型列于表 7 中。

Pseudo K-tuple Reduced Amino Acid Composition (PseKRAAC) 是一类蛋白质特征生成方法,可通过实施简化的氨基酸字母表 (RAAC) 编码肽或蛋白质特征。该方法以不同的方式对相关氨基酸进行分组,尝试减少序列数据中的信息冗余,生成复杂度较低的特征矩阵,从而避免过拟合。 PseKRAAC 共有 250 个功能组,但删除了 20 个组的 RAAC。太大(即 20 组)的 RAAC 与 AAC 相同,即未应用缩减编码。经过作者的初步测试,只有 233 个 PseKRAAC 特征组被进一步用于特征选择步骤。在 PseKRAAC 特征生成中使用了以下参数:ktuple= 2、gap-λ = 1、gap = 0 和 λ-correlation = 4
4.1.1 单一特征选择
由于考虑了许多特征类型(总共 254 个),因此检查特征类型的所有组合在计算上是令人望而却步的。然而,为了获得特征类型的最佳组合,作者首先检查了每种特征类型的预测能力,并只选择那些表现相当好的那些。然后,测试这些特征类型的组合以确定最佳特征编码方法。
每种特征类型的预测性能是使用 TML13 度量来测量的。总共进行了 39,624 次(254 种特征类型 × 13 ML 算法 × 3 离子通道类型 × 4 负数据集生成方法)实验,用于单特征类型选择。
4.1.2 最佳的K特征组合选择
作者计算了所有最佳特征组合的 TML13 指标,并使用 CDHit 数据生成方法通过所有三个通道的平均准确度对它们进行排序。最好的特征组合表示为 {best-1, best-2, . . . , best-K} (K ∈ {1, 2, … , 30}),其中 best-K 表示第 K(K ∈ {1, 2, … , K}) 的特征类型在所有三个中的平均准确度最高在训练集上使用 CDHit 数据生成方法的通道。
4.2 实验方法
4.2.1 TML13方法
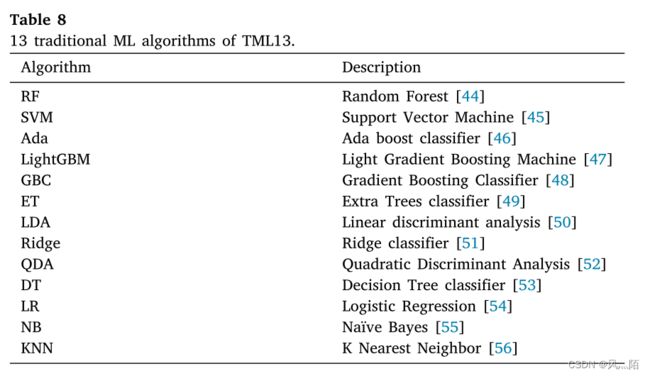
为了在特征选择中做出预测性能并与 Multi-Branch-CNN 方法进行比较,使用了 TML13 方法,由 13 种传统 ML 算法组成(如表 8 所示)。
4.2.2 TML13-Stack方法
TML13-Stack 是一种两级方法,它首先根据训练集上 5 倍交叉验证准确度的平均值对 13 种算法(如表 8 所示)进行排序。具有第 2 高到第 13 高算法的预测作为第二层的输入,具有第1高算法的预测可以作为分类算法进行最终预测。


4.2.3 Multi-Branch-CNN方法
在预测与离子通道相互作用的肽段时,传统的 ML 方法表现得非常好。然而,作者观察到的一个有趣现象是,不同的特征类型可以给出非常相似的预测性能,这使得准确选择特征子集变得困难。这里提出的方法的想法是利用不同特征类型的预测能力,而不需要详尽的特征选择。通过基于所选特征类型训练单个 CNN 模型,然后将所有 CNN 模型的独立预测结合起来,以获得更好的组合预测。训练过程旨在并行训练模型,因此命名为“Multi-Branch-CNN”。在说明 Multi-Branch-CNN 模型之前,将首先描述一个通用的 CNN 模型,称为 Single-Branch-CNN,以便于理解。

输入 Best-K,其中 K ∈ {1, 2, …, K},表示在特征选择阶段选择的 best-K 特征组合中的 best-K(本文为 18 个,参见图 3)。
5.结果
为了找到信息最丰富的特征类型作为所提出的 Multi-Branch-CNN 方法的输入,作者测试了 254 种不同的单一特征类型及其与 13 种常用 ML 算法 (TML13) 的组合。对所有 3 种类型的离子通道相互作用肽(Na-pep、K-pep、Ca-pep)独立进行测试。虽然正样本是经过实验验证的序列,但负样本是从 UniProt 数据库中收集的那些功能上不相关的肽或那些通过计算生成的。生成负数据的 4 种不同方法称为 Normal、CDHit、Random 和 Shuffle。每个数据集都分为训练集、测试集和新测试集。测试集包含从训练集中的每个序列簇和新测试集的所有序列中选择的序列,其中新测试集包含与训练集中的序列几乎没有或没有序列相似性的序列,并且是真正的看不见的序列。代替传统的随机抽样,从每个集群中收集测试序列确保了总体的多样性在测试集中得到了体现,因此测试性能应该更好地反映模型的实际性能。
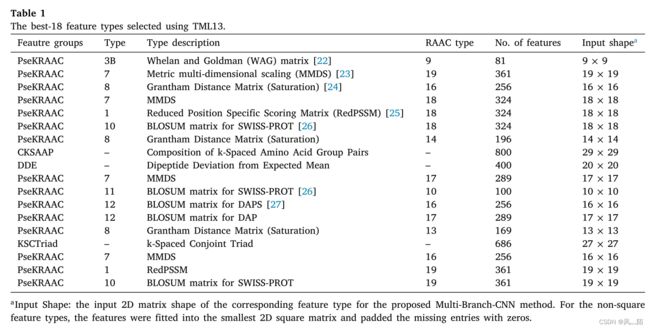
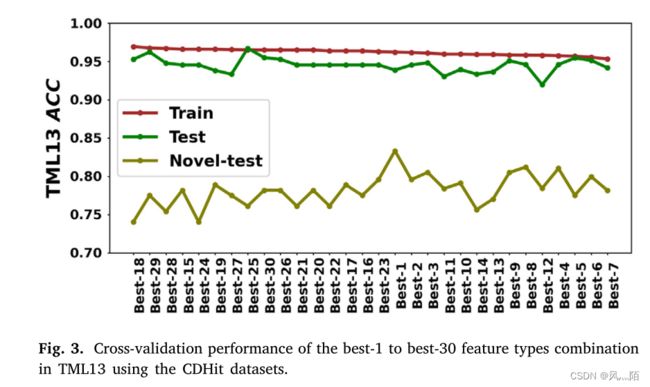
对于特征选择,作者选取了排名前 30 的特征类型,并详尽地搜索了一个特征组合,即 best-K 特征组合 (K ∈ {1, 2, … , 30}),使用 TML13 产生了最好的结果。最后,选择 best-18 特征组合作为 Multi-Branch-CNN 的输入。
5.1 单一特征选择
5.1.1 负样本生成方法的比较研究
为了概述使用传统 ML 算法的所有单特征类型模型的预测能力,作者绘制了图 1 中四种数据生成方法的所有单特征模型在三个通道上的训练、测试和新颖测试结果的分布。 如图1(A)所示,Na-pep 模型在训练集和测试集上的表现都优于 K-pep 和 Ca-pep 模型,但在新的测试集中,Ca-pep 模型表现最好。作者还注意到,K-pep 的训练集是三者中最大的,而 Ca-pep 的训练集是最小的。这似乎表明训练集的大小不仅在相似肽(测试序列)的预测中起作用,而且可能对不同肽(新测试序列)的预测准确性产生负面影响。
图 1(B) 比较了使用不同负数据集生成方法构建的模型的性能。可以观察到,在大多数单一特征编码模型中,Normal 和 CDHit 的性能优于 Shuffle 和 Random。而且CDHit的密度曲线与Normal的密度曲线对比表明,前者更平滑,后者波动更大。对此的一种可能解释是,CDHit 中的数据样本分布更均匀,因为非常相似的序列已被过滤掉以确保它们在数据集中不会过度表示。所以可得出结论,使用 CDHit 为 ML 创建非冗余数据集是一个有益的过程。此后,CDHit 用于处理最终的负数据集,随后用于创建生产模型。

5.1.2 传统机器学习方法的比较
图2显示了使用不同的训练集预测每个通道的肽的每种算法的平均性能的热图。每个值平均超过 254 个单一特征类型(21 个特征类型和 233 个 PseKRAAC 特征组)。

5.2 Best-K 特征组合的选择
为了确定创建通道肽预测的最佳模型需要多少特征类型,作者评估了 best-1、best-2、best-3 等最多 30 个特征类型的组合,其中排名每种特征类型都是基于使用 CDHit 数据集的 TML13 ACCtr 得分。由于计算资源有限,仅选择排名前 30 的特征类型进行组合搜索,不再选择更多。如图 3 所示,就平均交叉验证精度而言,所有三个通道都获得了最佳模型,并具有 18 个特征的最佳组合。最好的特征类型来自 PseKRAAC 特征组,不同之处在于它们的类型和减少的氨基酸簇的数量。 best-18 特征列在表 1 中,交叉验证准确度在图 3 中。可以看出,一些测试准确度可以达到训练集的平均交叉验证准确度,但新测试准确度的表现要远低于训练集的测试准确率和平均交叉验证准确率的差异,在图 1 的单个特征选择图中显示了相同的趋势。
5.3 TML13 与 Multi-Branch-CNN 方法的比较(独立测试)
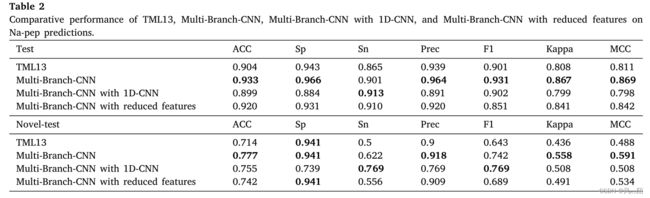
使用 best-18 特征组合和 CDHit 训练集,作者为 Na-pep、Kpep 和 Ca-pep 创建了最终的最优 Multi-Branch-CNN 模型。这些模型针对所有三个通道的测试集和新测试集进行了测试。训练和测试实验重复 5 次,并报告平均性能指标。
在传统的 ML 或单个 CNN 学习中,特征选择对于消除冗余特征以实现更低的模型复杂度和更高的准确度非常重要。在依赖多种特征类型来实现良好性能的肽预测模型中,这些特征类型可能包含许多冗余特征。 Multi-Branch-CNN 的目的是处理具有鲁棒性的冗余特征,因此无需详尽地选择它们。为了支持这个的观点,作者将提出的 Multi-Branch-CNN 模型与具有相同架构但删除了所有冗余特征的模型进行了比较。为此,在将 1D 特征向量转换为 2D 方阵之前,与之前 CNN 分支中的特征类型相比,来自第二个 CNN 和后续分支的输入特征类型的所有冗余特征都被删除。
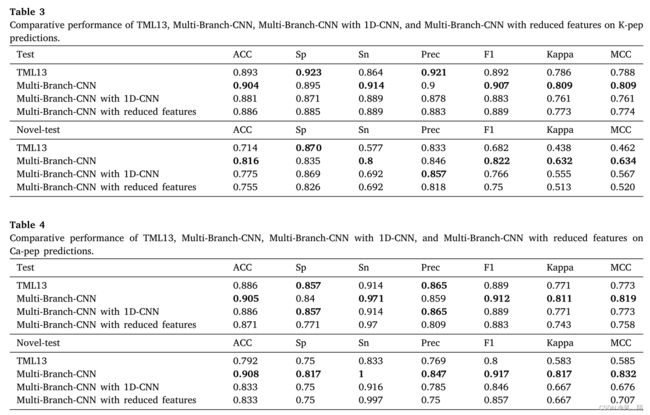
5.4 与 TML13-Stack 和 Single-Branch-CNN 方法的进一步比较研究
尽管 Multi-Branch-CNN 优于 TML13,但不足以证明它优于只有一个输入分支和集成方法的普通 CNN 方法。因此,作者创建了 Single-BranchCNN,它使用了 Multi-Branch-CNN 架构,将所有 best-18 特征组合到一个输入矩阵中,并将其性能与 Multi-Branch-CNN 进行了比较。此外,还开发了 TML13-Stack 来测试 Multi-Branch-CNN 是否比集成方法表现更好。在这里,在特征选择阶段选择的相同的 best-18 特征组合被用作所有四种方法(TML13、TML13-Stack、Single-Branch-CNN 和 Multi-Branch-CNN)的特征编码方法。
图4显示了通过五次实验重复获得的四种方法的平均准确度,即 TML13、TML13-Stack、Single-Branch-CNN 和 Multi-Branch-CNN。

6.结论
在这项工作中,作者提出了一种具有多个输入分支的 CNN 方法(Multi-Branch-CNN)来预测钠、钾和钙离子通道相互作用的肽。作者广泛地测试了一个大数量的特征编码方法(总共 254 种),并将它们优先用于模型构建。讨论了四种不同的生成负数据的方法,发现使用方法 CDHit 是一个可靠的预处理步骤,可以生成一组有助于预测建模的负序列。为了测试方法在真正看不见的序列上的预测性能,这在现实世界的应用中经常出现,作者创建了新的测试集,其中的序列与训练集中的序列几乎没有相似性。基于进行的广泛实验,可以证实,虽然 Multi-BranchCNN 在预测一般测试序列方面可以达到与最佳传统机器学习模型 (TML13) 相当的性能,但它在预测新测试序列预测方面显示出 9%–15% 的显着改进。所有三通道肽。我们还发现,Multi-Branch-CNN 方法的性能优于集成算法(TML13-Stacked)和只有一个输入分支的普通 CNN 方法(Single-Branch-CNN)。
然而,建立离子通道肽预测模型的一个主要限制是数据有限。未来,将探索使用具有未知离子通道活性的相关肽数据(例如毒素肽),通过半监督学习来提高模型性能。可以尝试其他深度学习方法,例如循环神经网络 (RNN) 和长短期记忆 (LSTM),还应该探索使用生成对抗网络 (GAN) 进行肽设计。