【时序】DeepGLO:可以学习全局依赖和局部信息的多时间序列预测模型
论文名称:Think Globally, Act Locally: A Deep Neural Network Approach to High-Dimensional Time Series Forecasting
论文下载:https://arxiv.org/abs/1905.03806
论文年份:NeurIPS 2019
论文被引:134(2022/04/21)
论文代码:https://github.com/rajatsen91/deepglo
Abstract
Forecasting high-dimensional time series plays a crucial role in many applications such as demand forecasting and financial predictions. Modern datasets can have millions of correlated time-series that evolve together, i.e they are extremely high dimensional (one dimension for each individual time-series). There is a need for exploiting global patterns and coupling them with local calibration for better prediction. However, most recent deep learning approaches in the literature are one-dimensional, i.e, even though they are trained on the whole dataset, during prediction, the future forecast for a single dimension mainly depends on past values from the same dimension. In this paper, we seek to correct this deficiency and propose DeepGLO, a deep forecasting model which thinks globally and acts locally. In particular, DeepGLO is a hybrid model that combines a global matrix factorization model regularized by a temporal convolution network, along with another temporal network that can capture local properties of each time-series and associated covariates. Our model can be trained effectively on high-dimensional but diverse time series, where different time series can have vastly different scales, without a priori normalization or rescaling. Empirical results demonstrate that DeepGLO can outperform state-of-the-art approaches; for example, we see more than 25% improvement in W APE over other methods on a public dataset that contains more than 100K-dimensional time series.
【研究意义】
预测高维时间序列在需求预测和财务预测等许多应用中起着至关重要的作用。
【已有研究的局限性】
现代数据集可以有数百万个相关的时间序列一起演化,即它们具有极高的维度(每个单独的时间序列一个维度)。需要利用全局模式并将它们与局部校准相结合以进行更好的预测。然而,文献中最近的深度学习方法是一维的,即,即使它们是在整个数据集上训练的,在预测过程中,单个维度的未来预测主要取决于同一维度的过去值。
【本文解决方案】
在本文中,我们试图纠正这一缺陷并提出 DeepGLO,这是一种全局思考和局部行动的深度预测模型。特别是,DeepGLO 是一种混合模型,它结合了由时间卷积网络规范化的全局矩阵分解模型,以及另一个可以捕获每个时间序列和相关协变量的局部属性的时间网络。我们的模型可以在高维但多样化的时间序列上进行有效训练,其中不同的时间序列可以具有截然不同的尺度,无需先验归一化或重新缩放。
【实验结果】
实证结果表明,DeepGLO 可以超越最先进的方法;例如,在包含超过 100K 维时间序列的公共数据集上,WAPE 比其他方法提高了 25% 以上。
1 Introduction
时间序列预测是许多工业应用的一个重要问题,如零售需求预测 [21]、财务预测 [15]、预测交通或天气模式 [5]。一般来说,它在自动化业务流程中起着关键作用[17]。现代数据集可以在数千个时间点上拥有数百万个相关的时间序列。例如,在亚马逊或沃尔玛这样的在线购物门户网站中,人们可能对未来对某一类别中所有商品的日常需求感兴趣,其中商品的数量可能以百万计。考虑到过去 t 个时间步长的需求,这会导致预测 n 个时间序列(n 个项目中的每个项目一个)的问题。这样的时间序列数据集可以表示为矩阵 Y ∈ R n × t Y \in \R^{n \times t} Y∈Rn×t,我们对 n 可以达到数百万量级的高维设置感兴趣。
传统的时间序列预测方法一次对单个时间序列或少量时间序列进行操作。这些方法包括众所周知的 AR、ARIMA、指数平滑 [19]、经典的 Box-Jenkins 方法 [4] 以及更普遍的线性状态空间模型 [13]。然而,由于需要单独训练,这些方法不容易扩展到具有数百万时间序列的大型数据集。此外,它们在训练和预测时无法从整个数据集中的共享时间模式中受益。
深度网络最近在时间序列预测中得到了普及,因为它们能够对非线性时间模式进行建模。循环神经网络 (RNN) [10] 在顺序建模中很受欢迎,但是它们在训练中会遇到梯度消失/爆炸问题。长短期记忆 (LSTM) [11] 网络缓解了这个问题,并在语言建模和其他 seq-to-seq 任务中取得了巨大成功 [11, 22]。最近,深度时间序列模型使用 LSTM 块作为内部组件 [9, 20]。另一种流行的架构,它可以与 LSTM 竞争并且可以说更容易训练,是 Wavenet 模型 [24] 推广的时间卷积/因果卷积。时间卷积最近被用于时间序列预测 [3, 2]。这些基于深度网络的模型可以在整个大型时间序列数据集上进行小批量训练。然而,它们仍然有两个重要的缺点。
首先,上述大多数深度模型很难在单个时间序列的尺度变化很大的数据集上训练。例如,在项目需求预测用例中,对一些流行项目的需求可能比利基项目的需求高出几个数量级。在这样的数据集中,需要对每个时间序列进行适当的归一化才能使训练成功,然后需要将预测缩小到原始规模。归一化的模式和参数难以选择,会导致不同的精度。例如,
- 在 [9, 20] 中,每个时间序列都使用相应的经验均值和标准差进行白化,
- 而在 [3] 中,时间序列在第一个时间点上按相应值进行缩放。
其次,即使这些深度模型是在整个数据集上训练的,但在预测过程中,模型只关注局部历史的数据,即仅使用时间序列的过去数据来预测该时间序列的未来。然而,在大多数数据集中,全局属性在预测期间可能很有用。例如,在股市预测中,查看 Alphabet 过去的市值以及亚马逊的股价,同时预测苹果的股价可能会有所帮助。同样,在零售需求预测中,可以利用类似商品的过去价值来预测某个商品的未来。
- 为此,在 [16] 中,作者提出了 2D 卷积和循环连接的组合,它可以在输入层中接收多个时间序列,从而在预测期间捕获全局属性。然而,由于输入层的规模不断扩大,这种方法的规模不会超过几千个时间序列。
- 另一方面,TRMF [29] 是一种时间正则化矩阵分解模型,可以将所有时间序列表示为基本时间序列的线性组合。这些基础时间序列可以在预测期间捕获全局模式。然而,TRMF 只能对线性时间依赖性进行建模。此外,由于分解可能存在近似误差,这可以解释为缺乏局部关注,即模型在预测期间仅关注全局模式。
鉴于上述讨论,我们的目标是提出一种可以全局思考和局部行动的深度学习模型,即在训练和预测过程中同时利用局部和全局模式,即使在规模变化很大的情况下也可以进行可靠的训练。本文的主要贡献如下:
- 在 A 节中,我们讨论了不同时间序列中尺度变化很大的问题,并提出了一个简单的初始化方案,即用于时间卷积网络 (TCN) 的 LeveledInit,它可以在没有先验归一化的情况下进行训练。
- 在第 5.1 节中,我们提出了一个由 TCN (TCN-MF) 正则化的矩阵分解模型,它可以将每个时间序列表示为 k 个基时间序列的线性组合,其中 k 远小于时间序列的数量。与 TRMF 不同,该模型可以捕获非线性依赖关系,因为正则化和预测是使用同时训练的时间卷积完成的,并且还适合可扩展的小批量训练。该模型可以在预测期间处理全局依赖关系。
- 在第 5.2 节中,我们提出了一种混合模型 DeepGLO,其中来自全局 TCN-MF 模型的预测作为时间卷积网络的协变量提供,从而使最终模型能够在训练和预测的同时,既关注每个时间序列的局部属性,也关注全局数据集范围的属性。
- 在第 6 节中,我们展示了 DeepGLO 在四个真实世界时间序列数据集上的表现优于其他基准,包括一个包含超过 110K 维度时间序列的公共 wiki 数据集。更多细节可以在表 1 和表 2 中找到。
2 Related Work
关于时间序列预测的文献浩如烟海,跨越了几十年。在这里,我们将主要关注最近的深度学习方法。对于传统方法,可以参考文献[13,19,4,18,12]。
近年来,深度学习模型在时间序列预测中得到了普及。
- DeepAR [9] 提出了一个基于 LSTM 的模型,其中未来时间步长的贝叶斯模型的参数被预测为 LSTM 的相应隐藏状态的函数。
- DeepState [20],将线性状态空间模型与深度网络相结合。
- MQ-RNN [26],提出了一个时间序列模型,其中一个时间序列的所有历史使用 LSTM 块进行编码,一个multi horizon MLP 解码器用于解码输入到未来预测中。
- LSTNet [16] 可以通过2D卷积和递归结构的组合利用多个时间序列之间的相关性。然而,由于输入层的规模不断扩大,很难将这一模型扩展到几千个时间序列以外。
- 时间卷积(Temporal convolutions) 最近被用于时间序列预测[3]。
具有时间正则化的矩阵分解
- 首先在 [27] 中用于语音去噪。
- 在 [28] 中提出了一种交通数据的时空深度模型。
- 也许与我们的工作最接近的是 TRMF [29],作者提出了一种基于 AR 的时间正则化。在本文中,我们将这项工作扩展到非线性设置,其中时间正则化可以通过时间卷积网络执行(参见第 4 节)。我们进一步将全局矩阵分解模型与时间卷积网络相结合,从而创建了一个可以同时关注局部和全局属性的混合模型。
- 有一项并行工作 [25],其中 RNN 已被用于演化所有时间序列共有的全局状态。
3 Problem Setting
我们考虑在未来时间步长上预测高维时间序列的问题。高维时间序列数据集由几个可能相关的时间序列以及相应的协变量组成,任务是预测这些时间序列在未来时间步长中的值。在正式定义问题之前,我们会设置一些符号。
使用粗体大写字母表示矩阵 M ∈ R m × n M \in \R ^{m \times n} M∈Rm×n, M i , j M_{i,j} Mi,j 和 M [ i , j ] M[i,j] M[i,j] 可以互换使用来表示矩阵 M M M 的第 ( i , j ) (i,j) (i,j) 项。

目标:预测的质量通常使用在测试范围内的预测值和实际值之间计算的度量来衡量。一种流行的指标是归一化绝对偏差指标[29],定义如下,

4 LeveledInit: Handling Diverse Scales with TCN
在本节中,我们提出了 LeveledInit 一种简单的时间卷积网络 (TCN) [2] 初始化方案,该方案旨在处理具有广泛规模变化的高维时间序列数据,无需先验归一化。如前所述,深度网络很难在时间序列数据集上训练,其中单个时间序列具有不同的尺度。基于 LSTM 的模型无法在此类数据集上可靠地训练,并且可能需要先验标准归一化 [16] 或贝叶斯均值预测的预缩放 [9]。 TCN 也被证明需要先验归一化 [3] 来进行时间序列预测。归一化参数的选择会对预测性能产生重大影响。在这里,我们展示了一个简单的 TCN 网络权重初始化方案可以缓解这个问题,并在没有先验归一化的情况下实现可靠的训练。首先,我们将简要讨论 TCN 架构。

LeveledInit Scheme:缓解不同尺度问题的一种可能方法是从初始网络参数开始,这导致近似预测过去时间点 y j − l : j − 1 y_{j-l:j-1} yj−l:j−1 的给定窗口的平均值,作为未来预测值 y ^ j \hat{y}_j y^j。在训练过程中,网络将学会预测围绕该均值预测的变化,因为该均值周围的变化是相对无标度的。这可以通过 TCN 的一些配置的简单初始化方案来实现,我们称之为 LeveledInit。为了便于说明,考虑没有协变量且每层只有一个通道的设置,它可以在功能上表示为 y ^ J + 1 = T ( y J ∣ θ ) \hat{y}_{J+1} = T(y_J|\theta) y^J+1=T(yJ∣θ)。在这种情况下,初始化方案是简单地将所有滤波器的权重设置为 1 / k 1/k 1/k,其中 k k k 是每一层的滤波器大小。这引出了一个命题。

上述命题表明,LeveledInit 导致预测 ^yj,它是过去 l 个时间点的平均值,其中 l 是 TCN 的动态范围,当滤波器大小为 k = 2 时(见图 1a)。命题 1 的证明(参见 A 节)源于这样一个事实,即内部层中的激活值是来自前一层的相应 k 个输入的平均值,并且层上的归纳产生结果。 LeveledInit 也可以通过在输入层中将相应的滤波器权重设置为 0 来扩展到具有协变量的情况。它也可以很容易地扩展到每层的多个通道,k = 2。在第 6 节中,我们展示了具有 LeveledInit 的 TCN 可以在现实世界数据集上可靠地训练而无需先验归一化,即使对于 k != 2 的值也是如此。我们提供使用 LeveledInit 作为算法 1 训练 TCN 的伪代码。
请注意,我们还尝试了一种更复杂的时间卷积架构变体,称为深层次网络 (Deep Leveled Network ,DLN),我们将其包含在附录 A 中。但是,我们观察到 TCN 的简单初始化方案 (LeveledInit) 可以匹配深层次网络的性能。
5 DeepGLO: A Deep Global Local Forecaster
在本节中,我们将介绍我们的混合模型 DeepGLO,它可以在训练和预测期间利用全局和局部特征。在 5.1 节中,我们介绍了全局组件,TCN 正则化矩阵分解(TCN-MF)。该模型可以在预测期间捕获全局模式,通过将每个原始时间序列表示为 k 个基本时间序列的线性组合,其中 k ≪ n k \ll n k≪n。在 5.2 节中,我们详细介绍了如何将全局模型的输出合并为 TCN 的输入协变量维度,从而产生一个混合模型,该模型既可以关注局部每个时间序列信号,又可以利用全局数据集范围的组件。

5.1 Global: Temporal Convolution Network regularized Matrix Factorization (TCN-MF)
在本节中,我们提出了一个用于时间序列预测的低秩矩阵分解模型(low-rank matrix factorization model),该模型使用 TCN 进行正则化。想法是将训练时间序列矩阵 Y ( t r ) Y^{(tr)} Y(tr) 分解为低秩因子 F ∈ R n × k F \in \R^{n\times k} F∈Rn×k 和 X ( t r ) ∈ R k × t X^{(tr)} \in \R^{k \times t} X(tr)∈Rk×t,其中 k ≪ n k \ll n k≪n。这在图 1b 中进行了说明。此外,我们希望鼓励 X ( t r ) X^{(tr)} X(tr) 矩阵中的时间结构,以便也可以预测测试范围内的未来值 X ( t e ) X^{(te)} X(te) 。令 X = [ X ( t r ) X ( t e ) ] X = [X^{(tr)}X^{(te)}] X=[X(tr)X(te)]。因此,可以认为矩阵 X X X 由 k k k 个基本时间序列组成,这些基本时间序列捕获整个数据集中的全局时间模式,并且所有原始时间序列都是这些基本时间序列的线性组合。在下一小节中,我们将描述如何使用 TCN 来鼓励 X 的时间结构。

图 1:图 1a 包含 TCN 的图示。请注意,基本图像是从 [24] 中借用的。该网络有 d = 4 层,滤波器大小 k = 2。网络将输入 y t − l : t − 1 y_{t-l:t-1} yt−l:t−1 映射到一个移位的输出 y ^ t − l + 1 : t \hat{y}_{t-l+1:t} y^t−l+1:t 。图 1b 展示了时间序列预测中的矩阵分解方法。 Y ( t r ) Y^{(tr)} Y(tr) 训练矩阵可以分解为低秩因子 F ( ∈ R n × k ) F (\in \R^{n \times k}) F(∈Rn×k) 和 X ( t r ) ( ∈ R k × t ) X^{(tr)} (\in \R^{k \times t}) X(tr)(∈Rk×t)。如果 X ( t r ) X^{(tr)} X(tr) 保留时间结构,则未来值 X ( t e ) X^{(te)} X(te) 可以通过时间序列预测模型进行预测,因此可以将测试期预测作为 F X ( t e ) FX^{(te)} FX(te) 。
TCN 的时间正则化:如果提供了一个 TCN,它可以捕获训练数据集 Y ( t r ) Y^{(tr)} Y(tr) 中的时间模式,那么可以使用这个模型来鼓励 X ( t r ) X^{(tr)} X(tr) 中的时间结构。假设所述网络是 T X ( ⋅ ) T_X(·) TX(⋅)。可以通过在目标函数中包含以下时间正则化来鼓励时间模式:
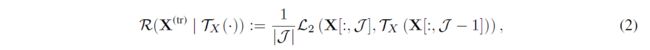
其中 J = {2,····, t} 和 L2(·,·) 是之前定义的平方损失度量。这意味着时间索引 j 上的 X ( t r ) X^{(tr)} X(tr) 的值接近于时间网络应用于时间步 {j - l, …, j - 1} 之间的过去值的预测。这里,l + 1 等于第 4 节中定义的网络的动态范围。因此,因子和时间网络的整体损失函数如下:
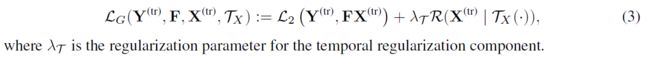
训练:可以交替训练低秩因子 F F F, X ( t r ) X^{(tr)} X(tr) 和时间网络 T X ( ⋅ ) T_X(·) TX(⋅),以近似最小化方程 (3) 中的损失。整体训练可以通过 mini-batch SGD 进行,并且可以分解为两个交替执行的主要部分:
- i)给定一个固定的 T X ( ⋅ ) T_X(·) TX(⋅),相对于因子 F F F, X ( t r ) X^{(tr)} X(tr) 最小化 L G ( F , X ( t r ) , T X ) L_G(F, X^{(tr)}, T_X) LG(F,X(tr),TX) - 算法 3
- ii)使用算法 1 在矩阵 X ( t r ) X^{(tr)} X(tr) 上训练网络 T X ( ⋅ ) T_X(·) TX(⋅)。
整体算法详见算法2。TCN T X ( ⋅ ) T_X(·) TX(⋅) 首先由 LeveledInit 初始化。然后在第二个初始化步骤中,使用初始化的 T X ( ⋅ ) T_X(·) TX(⋅) 训练两个因子 F 和 X ( t r ) X^{(tr)} X(tr) (步骤3),用于 i t e r s i n i t iters_{init} itersinit 迭代。接下来是更新 F F F, X ( t r ) X^{(tr)} X(tr) 和 T X ( ⋅ ) T_X(·) TX(⋅) (步骤5-7) 的 i t e r s a l t iters_{alt} itersalt 替代步骤。
预测:经过训练的模型局部网络 T X ( ⋅ ) T_X(·) TX(⋅) 可用于以标准方式进行多步前瞻预测。给定一个基础时间序列的过去数据点 x j − l : j − 1 x_{j-l:j-1} xj−l:j−1,下一个时间步长的预测 x ^ j \hat{x}_j x^j 由 [ x ^ j − l + 1 , ⋅ ⋅ ⋅ , x ^ j ] = T X ( x j − l : j − 1 ) [\hat{x}_{j-l+1}, · · · ,\hat{x}_j] = T_X(x_{j-l:j-1}) [x^j−l+1,⋅⋅⋅,x^j]=TX(xj−l:j−1) 给出。现在,一步前瞻预测可以与过去的值连接形成序列 x ~ j − l + 1 : j = [ x j − l + 1 : j − 1 x ^ j ] \tilde{x}_{j-l+1:j} = [x_{j-l+1:j-1} \hat{x}_j] x~j−l+1:j=[xj−l+1:j−1x^j],可以再次通过网络得到下一个预测: [ . . . , x ^ j + 1 ] = T X ( x ~ j − l + 1 : j ) [..., \hat{x}_{j+1}]=T_X(\tilde{x}_{j-l+1:j}) [...,x^j+1]=TX(x~j−l+1:j)。相同的过程可以重复 τ 次来预测未来的 τ 时间步长。因此,我们可以获得测试范围 X ^ ( t e ) \hat{X}^{(te)} X^(te) 中的基本时间序列。然后由 Y ( t e ) = F X ^ ( t e ) Y^{(te)} = F\hat{X}^{(te)} Y(te)=FX^(te) 给出最终的全局预测。

5.2 Combining the Global Model with Local Features
在本节中,将展示最终的混合模型。回想一下,我们的预测任务将训练原始时间序列 Y ( t r ) Y^{(tr)} Y(tr) 和协变量 Z ∈ R n × r × ( t + τ ) Z \in \R ^{n \times r \times (t+ \tau)} Z∈Rn×r×(t+τ) 作为输入。我们的混合预测器是一个 TCN T Y ( ⋅ ∣ Θ Y ) T_Y (·|\Theta_Y) TY(⋅∣ΘY),输入大小为 r + 2 维:
- i)其中一个输入保留用于原始原始时间序列的过去点,
- ii)r 个输入用于原始 r 维协变量
- iii)剩余维度保留用于全局 TCN-MF 模型的输出,该模型作为输入协变量馈送。
整个模型如图 2 所示。我们模型的训练伪代码作为算法 4 提供。

图 2:在图 2a 中,我们展示了从交通数据集中提取的一些基本时间序列,它们可以线性组合以产生单独的原始时间序列。可以看出,基序列具有高度的时间性,可以使用网络 T X ( ⋅ ∣ Θ X ) T_X(·|\Theta_X) TX(⋅∣ΘX) 在测试范围内进行预测。在图 2b(从 [24] 借用的基础图像)中,我们展示了 DeepGLO 的插图。所示的 TCN 是网络 T Y ( ⋅ ) T_Y (·) TY(⋅),它将原始时间点、原始协变量和全局模型的输出作为协变量作为输入。因此,该网络可以在预测期间将局部属性与全局模型的输出相结合。
因此,通过将全局 TCN-MF 模型预测作为协变量提供给 TCN,我们可以使最终预测成为全局数据集范围属性以及局部时间序列和协变量的过去值的函数。请注意,滚动预测和多步前瞻预测都可以由 DeepGLO 执行,因为全局 TCN-MF 模型和混合 TCN TY (·) 可以执行预测,而无需重新训练。我们在图 2 中的数据集的时间序列上说明了一些具有代表性的结果。在图 2a 中,我们展示了从交通数据集中提取的一些基本时间序列(全局特征),它们可以线性组合以产生个体原始时间序列。可以看出,基序列具有高度的时间性,可以使用网络 T X ( ⋅ ∣ Θ X ) T_X(·|\Theta_X) TX(⋅∣ΘX) 在测试范围内进行预测。在图 2b 中,我们展示了 DeepGLO 的完整架构。可以观察到,全局 TCN-MF 模型的输出作为协变量输入到 TCN T Y ( ⋅ ) T_Y (·) TY(⋅),然后将其与局部特征相结合,并通过多步前瞻预测在测试范围内进行预测。
6 Empirical Results
在本节中,我们在滚动预测任务的四个真实数据集上验证我们的模型(有关更多详细信息,请参见第 C.1 节),并与其他基准进行对比。
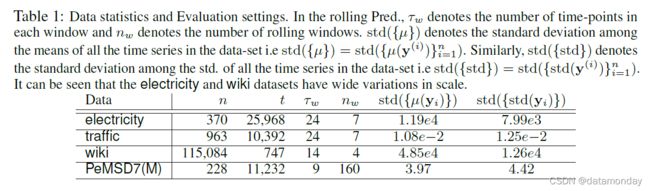
考虑的数据集是:
- i)电力 [23] - 370 所房屋的每小时负荷。训练集由 25968 个时间点组成,任务是在接下来的 7 天(一次 24 个时间点,7 个窗口)执行滚动验证,如 [29,20,9] 中所做的那样
- ii)交通 [7] - 旧金山 963 条道路上的每小时交通。训练集由 10m392 个时间点组成,任务是在接下来的 7 天(一次 24 个时间点,7 个窗口)执行滚动验证,如 [29、20、9]
- iii)wiki [14] - 来自维基百科的大约 115084 篇文章的每日网络流量。我们只保留原始数据集中没有缺失值的时间序列。每天的值由当天所有时间序列的总流量标准化,然后乘以 1e8。训练集由 747 个时间点组成,任务是在接下来的 86 天,每次 14 天执行滚动验证。表 1 提供了更多表明尺度变化的数据统计数据。
- iv)PeMSD7(M) [6] - 从 Caltrain PeMS 系统收集的数据,其中包含 228 个时间序列的数据,以 5 分钟的间隔收集。训练集由 11232 个时间点组成,我们对接下来的 1440 个时间点进行滚动验证,一次 9 个点。
对于每个数据集,所有模型都在两个不同的设置上进行比较。
- 第一个设置,模型在数据集的标准化版本上进行训练,其中训练集中的每个时间序列都重新缩放为 y ~ 1 : t − τ ( i ) = ( y ( i ) 1 : t − τ − µ ( y 1 : t − τ ( i ) ) ) / ( σ ( y 1 : t − τ ( i ) ) ) \tilde{y}^{(i)}_{1:t-\tau} = (y^(i)_{1:t-\tau} - µ(y^{(i)}_{1:t-\tau}))/(\sigma (y^{(i)}_{1:t-\tau})) y~1:t−τ(i)=(y(i)1:t−τ−µ(y1:t−τ(i)))/(σ(y1:t−τ(i))),然后将预测按比例缩小到原始比例。
- 第二种设置,数据集是非标准化的,即在训练和预测时保持原样。请注意,所有模型都是在数据原始规模的测试范围内进行比较的。这两个设置的目的是衡量缩放对不同模型准确性的影响。
争论的模型是:
- 1)DeepGLO:5.2 节提出的局部和全局组合模型。我们使用时间特征,如时间、星期等作为全局协变量,类似于 DeepAR。有关更详细的讨论,请参阅第 C.3 节。
- 2)Local TCN (LeveledInit):第 4 节中讨论的基于时间卷积的架构,带有 LeveledInit。
- 3)LSTM:一个简单的 LSTM 块,可将时间序列值预测为隐藏状态的函数 [11]。
- 4)DeepAR:[9]中提出的模型。
- 5)TCN:一个简单的时间卷积模型,如第 4 节所述。
- 6)Prophet:来自 Facebook 基于经典技术的多功能预测模型 [8]。
- 7)TRMF:[29]中提出的模型。请注意,该模型需要针对每个滚动预测窗口进行重新训练。
- 8)SVD+TCN:SVD和TCN的组合。使用 SVD 将原始数据分解为 Y = UV,并在 V 上训练水平网络。这是仅用于全局方法的简单基线。
- 9)STGCN:[28] 中的时空模型。我们在交通和电力数据集上使用与 DeepAR 相同的超参数,如 [9] 中指定的,在 GluonTS [1] 中实现。
原始论文中的 WAPE 值不能直接使用,因为在 [9] 和 [20] 中报告了不同的值。请注意,对于 DeepAR,标准化和非标准化设置对应于在 GluonTS 包中使用 sclaing=True 和 scaling=False。 TRMF [29] 中的模型使用与原始论文不同的超参数(更大的秩)进行训练,因此结果略好。 C 部分提供了有关使用的所有超参数的更多详细信息。对于 DeepGLO/TRMF,电力、交通、wiki 和 PeMSD7(M) 中使用的等级(rank)k 是 64/60、64/60、256/1024 和 64/-。

在表 2 中,我们报告了标准化和非标准化训练下前三个数据集的 WAPE/MAPE/SMAPE(参见第 C.2 节中的定义)。我们可以看到,
- 在所有三个指标下,DeepGLO 在几乎所有类别中的前两个模型中都具有特征。
- 平均而言,DeepGLO 比单个局部 TCN (LeveledInit) 方法和全局 TCN-MF 模型做得更好,因为它受到全局和局部因素的帮助。
- 就 WAPE 而言,局部 TCN (LeveledInit) 模型在更大的 wiki 数据集上表现最好,比所有模型(本文未提出)提高了 30% 以上,而 DeepGLO 紧随其后,比所有其他模型提高了 25% 以上。
- 我们还发现 DeepGLO 在所有样本的非标准化设置中表现更好,因为不需要缩放模型的输入和重新缩放输出。
- 我们发现 TCN(无 LeveledInit)、DeepAR1 和 LSTM 模型在未归一化的设置中表现不如预期。
- 在第二个表中,我们将 DeepGLO 与 [28] 中的模型进行了比较,它们可以捕获全局特征,但需要一个表示时间序列之间密切关系的加权图作为外部输入。我们看到 DeepGLO(未归一化)在所有指标上表现最好,即使它不需要任何外部输入。
A Deep Leveled Network
包含数十万个时间序列的大规模时间序列数据集可以具有非常多样化的尺度。规模的多样性导致训练深度模型时出现问题,包括时间卷积和基于 LSTM 的架构,并且需要一些规范化才能使训练成功 [16,3,9]。然而,为每个时间序列选择正确的归一化因子并不是一门精确的科学,可能会对预测性能产生影响。例如,在 [9] 中,数据集在训练时使用每个时间序列的训练标准差和均值进行白化,并对预测进行重新归一化。另一方面,在 [3] 中,每个时间序列在第一个时间步上根据该时间序列的值重新缩放。此外,当使用预训练模型执行滚动预测时,当观察到新数据时,可能需要通过合并新的时间点来更新比例因子。在本节中,我们提出了 DLN,这是一种简单的 leveling network 架构,可以在不同的数据集上进行训练,而无需先验规范化。
DLN 由两个同时训练的时间卷积块(具有相同的动态范围/回溯 l)组成。让我们分别用 Tm(·|Θm) 和 Tr(·|Θr) 来表示两个网络和相关的权重。关键思想是让 Tm(·|Θm) (水平分量)预测给定过去的下 w 个未来时间点的滚动平均值。另一方面,Tr(·|Θr)(残差分量)将用于预测相对于该平均值的变化。给定适当的窗口大小 w,滚动平均值对于每个时间序列都保持稳定,并且可以通过简单的时间卷积模型进行预测,并且给定这些预测,加性变化是相对无标度的,即可以可靠地训练网络 Tr(·|Θr)没有标准化。这可以通过以下等式来概括:



命题1的证明:

B Rolling Prediction without Retraining
一旦使用算法 2 训练了 TCN-MF 模型,我们就可以使用多步前瞻预测对测试范围进行预测。该方法很简单——我们首先使用 TX(·) 在第 4 节中详述的 X(tr) 中的基础时间序列上进行多步前瞻预测,得到 ^X(te);那么原始的时间序列预测可以通过 ^Y(te) = F ^X(te) 获得。该模型还可以适应进行滚动预测而无需重新训练。在滚动预测的情况下,任务是在训练周期 Y[:, 1: t1] 上训练模型,然后在未来时间段上进行预测,比如 ^Y[:, t1 + 1: t2],然后接收未来时间范围 Y[:, t1 + 1 : t2] 的实际值,并在合并这些值后对未来更远的时间范围 ^Y[:, t2 + 1 : t3] 进行进一步预测,依此类推。在这种情况下,关键挑战是合并新观察到的值 Y[:, t1 + 1: t2] 以生成该时段内的基本时间序列值 X[:, t1 + 1: t2]。我们建议通过最小化 (3) 中定义的全局损失来获得这些值,同时保持 F 和 TX(·) 固定:
![]()
一旦我们获得 X[:, t1 + 1 : t2],我们就可以在下一组未来时间段 ^Y[:, t2 + 1: t3] 中进行预测。请注意,[29] 中的 TRMF 模型需要从头开始重新训练以合并新观察到的值。在这项工作中,不需要再训练来获得良好的性能,正如我们将在第 6 节的实验中看到的那样。
C More Experimental Details
我们将提供有关实验的更多详细信息,例如每个数据集中的精确滚动预测设置、评估指标和模型超参数。
C.1 Rolling Prediction
在第 6 节的实验中,我们比较了模型在滚动预测任务上的性能。此设置的目标是随着更多数据的披露,批量预测未来的时间步长。假设初始训练时间段为 {1, 2, …, t0},滚动窗口大小 τ 和测试窗口数 nw。令 ti = t0 + iτ。滚动预测任务是一个顺序过程,给定数据直到最后一个窗口 Y[:, 1: ti−1],我们预测下一个未来窗口的值 ^Y[:, ti−1 + 1: ti],并且然后显示下一个窗口 Y[:, ti−1 + 1: ti] 的实际值,并在 i = 1, 2, …, nw 时继续该过程。性能的最终衡量标准是公式中定义的度量 L 的损失 L( ^Y[:, t0 + 1 : tnw], Y[:, t0 + 1 : tnw])。 (1)。
例如,在交通数据集实验中,我们有 t0 = 10392,τ = 24,w = 7,在电力方面,t0 = 25968,τ = 24,w = 7。wiki 数据集实验的参数为 t0 = 747 , τ = 14, w = 4。
C.2 Loss Metrics

C.3 Model Parameters and Settings
在本节中,我们将更详细地描述比较模型。对于 TC 网络,重要的参数是卷积核大小/滤波器大小、层数和每层滤波器/通道的数量。 [c1, c2, c3] 描述的网络意味着在第 i 层中有 3 层具有 ci 滤波器的层。因为,一个 LSTM 的参数 (nh, nl) 表示隐藏层的神经元个数为 nh,隐藏层的个数为 nl。所有模型训练时都以 patience=7 进行提前停止,最大 epoch 数为 300。所有模型的超参数如下:
- DeepGLO:在所有数据集中,除了 wiki 和 PeMSD7(M),网络 TX 和 TY 都有参数 [32, 32, 32, 32, 32, 1],卷积核大小为 7。在 wiki 数据集上,我们设置网络TX 和 TY 参数为 [32, 32, 32, 32, 1]。在 PeMSD7(M) 数据集上,我们将参数设置为 [32, 32, 32, 32, 32, 1] 和 [16, 16, 16, 16, 16, 1]。在所有实验中,我们将 α 和 λT 都设置为 0.2。电力、交通、wiki 和 PeMSD7(M) 中使用的秩 k 分别为 64、64、256 和 64。我们使用 7 个时间协变量,包括小时的分钟、一天中的小时、星期几、一个月中的一天、一年中的一天、一年中的一个月、一年中的一周,所有这些都在一个范围内归一化 [ −0.5, 0.5],这是 GluonTS 库中默认使用的时间协变量的子集。
- Local TCN (LeveledInit):对所有数据集使用设置 [32, 32, 32, 32, 32, 1]。
- Local DLN:在所有数据集中,水平网络的参数为 [32, 32, 32, 32, 32, 1],卷积核大小为 7。
- TRMF:在电力、交通、wiki 中使用的秩 k 分别为 60、60、1024。滞后指数设置为包括交通和电力数据的最后一天和上周的同一天。
- SVD+Leveled:电力、交通、wiki使用的rank k分别为60、60、500。在所有数据集中,水平网络的参数为 [32, 32, 32, 32, 32, 1],卷积核大小为 7。
- LSTM:在所有数据集中,参数为 (45, 3)。
- DeepAR:在所有数据集中,我们在 GluonTS 实现中使用 DeepAREstimator 中的默认参数。
- TCN:在所有数据集中,参数为 [32, 32, 32, 32, 32, 1],卷积核大小为 7。
- Prophet:自动选择参数。该模型在 32 个卷积核上并行化。该模型以增长 = ‘logistic’ 运行,因为它被发现表现最好。
请注意,我们在 PeMSD7(M) 数据集上为 STGCN 模型复制了 [28] 中报告的确切值。