PyTorch图像分类实战(Datawhale)Task3:迁移学习微调训练
迁移学习微调训练
迁移学习微调训练
- **迁移学习微调训练**
-
- 1. 数据集预处理
-
- 1.1 图像预处理
- 1.2 载入图像分类数据集
- 2. 定义训练参数
-
- 2.1 定义数据加载器
- 2.2 batch数据预览
- 2.3 训练策略设置
- 3. 训练监控
-
- 3.1 训练日志记录
- 3.2 训练日志可视化
- 3.3 创建wandb可视化项目
- 4. 总结与扩展
-
- 4.1 注意事项
- 4.2 创新点展望
- 4.3 扩展阅读
- 4.4 训练好图像分类模型之后,做什么?
本章节内容为基于基础模型以及相关公共数据集权重文件针对特定数据集进行训练(即迁移学习)的操作。具体来说,根据数据集的差异,迁移学习可以只训练最后分类层、在模型参数基础上训练所有层、以及随机初始化训练所有层三种方式。同时,本章节中也提供了大量关于训练日志以及训练监控的方式方法。
参考资料:
- 同济子豪兄教学视频:https://space.bilibili.com/1900783/channel/collectiondetail?sid=606800(P3)
- 项目代码:https://github.com/TommyZihao/Train_Custom_Dataset
1. 数据集预处理
数据集预处理即针对自建数据集,进行数据批次、标签以及图像预处理操作。
本次项目采用fruit30_split数据集,其目录结构如下图所示:
(因为实验中图像分布比较均匀,所以训练集和测试集采用同一个文件)

1.1 图像预处理
图像预处理指对于训练集和测试(验证)集中图像进行预处理操作,具体为:
- 训练集图像预处理:缩放裁剪、图像增强、转 Tensor、归一化;
- 测试集图像预处理-RCTN:缩放、裁剪、转 Tensor、归一化。
与训练集相比,测试集中少了图像增强的步骤,训练集通过图像增强来增强图像的鲁棒性。
from torchvision import transforms
# 训练集图像预处理:缩放裁剪、图像增强、转 Tensor、归一化
train_transform = transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 测试集图像预处理-RCTN:缩放、裁剪、转 Tensor、归一化
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
1.2 载入图像分类数据集
- 采用torchvision中datasets的ImageFolder方法载入数据集
## 载入数据集
from torchvision import datasets
# 载入训练集
train_dataset = datasets.ImageFolder(train_path, train_transform)
# 载入测试集
test_dataset = datasets.ImageFolder(test_path, test_transform)
- 查看载入数据集信息
print('训练集图像数量', len(train_dataset))
print('类别个数', len(train_dataset.classes))
print('各类别名称', train_dataset.classes)
————————
训练集图像数量 4375
类别个数 30
各类别名称 ['哈密瓜', '圣女果', '山竹', '杨梅', '柚子', '柠檬', '桂圆', '梨', '椰子', '榴莲', '火龙果', '猕猴桃', '石榴', '砂糖橘', '胡萝卜', '脐橙', '芒果', '苦瓜', '苹果-红', '苹果-青', '草莓', '荔枝', '菠萝', '葡萄-白', '葡萄-红', '西瓜', '西红柿', '车厘子', '香蕉', '黄瓜']
- 确定图像类型索引
将数据集图像类别和索引号 一一对应,并将映射关于通过字典进行键值存储,最终存储为Torch的npy文件。
# 各类别名称
class_names = train_dataset.classes
n_class = len(class_names)
# 映射关系:类别 到 索引号
train_dataset.class_to_idx
# 映射关系:索引号 到 类别
idx_to_labels = {y:x for x,y in train_dataset.class_to_idx.items()}
# 保存为本地的 npy 文件
np.save('idx_to_labels.npy', idx_to_labels)
np.save('labels_to_idx.npy', train_dataset.class_to_idx)
2. 定义训练参数
定义训练的Batch大小以及训练轮次Epoch,训练学习率的优化策略,训练采用的优化器等参数。
2.1 定义数据加载器
数据加载器即数据输入模型的形式和尺寸,包括定义训练的Batch大小以及随机顺序和计算核心数等数据。
from torch.utils.data import DataLoader
BATCH_SIZE = 32
# 训练集的数据加载器
train_loader = DataLoader(train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4
)
# 测试集的数据加载器
test_loader = DataLoader(test_dataset,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=4
)
2.2 batch数据预览
通过数据加载完成数据划分后,可以查看一个batch数据的信息。
- 查看一个batch的图像和标注;
# DataLoader 是 python生成器,每次调用返回一个 batch 的数据
images, labels = next(iter(train_loader))
images.shape
-- torch.Size([32, 3, 224, 224])
labels
-- tensor([27, 16, 25, 20, 10, 5, 0, 28, 6, 16, 2, 2, 12, 28, 5, 22, 11, 9, 24, 12, 16, 1, 23, 28, 9, 25, 19, 20, 27, 28, 16, 19])
- 可视化一个batch的图像和标注。
可视化图像需要将数据集中的Tensor张量转为numpy的array数据类型,并进行归一化的逆运算,及第一不中图像初始化的逆运算。
## 预处理后图像信息
# 将数据集中的Tensor张量转为numpy的array数据类型
images = images.numpy()
images[5].shape
-- (3, 224, 224)
plt.hist(images[5].flatten(), bins=50)
plt.show()
均一化后图像像素分布:
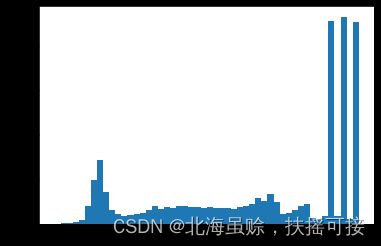
显示图像:
# batch 中经过预处理的图像
idx = 2
plt.imshow(images[idx].transpose((1,2,0))) # 转为(224, 224, 3)
plt.title('label:'+str(labels[idx].item()))
查看图像信息:
label = labels[idx].item()
label
-- 27
pred_classname = idx_to_labels[label]
pred_classname
-- '车厘子'
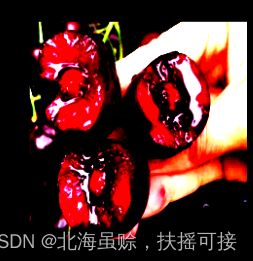
还原原始图像:
# 原始图像
idx = 2
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
plt.imshow(np.clip(images[idx].transpose((1,2,0)) * std + mean, 0, 1))
plt.title('label:'+ pred_classname)
plt.show()

2.3 训练策略设置
- 选择迁移学习训练方式:
- 只微调训练模型最后一层(全连接分类层)
# 载入预训练模型
model = models.resnet152(pretrained=True)
# 修改全连接层,使得全连接层的输出与当前数据集类别数对应
# 新建的层默认 requires_grad=True
model.fc = nn.Linear(model.fc.in_features, n_class)
model.fc
-- Linear(in_features=2048, out_features=30, bias=True)
# 只微调训练最后一层全连接层的参数,其它层冻结
optimizer = optim.Adam(model.fc.parameters())
- 微调训练所有层
# 载入预训练模型
model = models.resnet18(pretrained=True)
model.fc = nn.Linear(model.fc.in_features, n_class)
optimizer = optim.Adam(model.parameters())
- 随机初始化模型全部权重,从头训练所有层
# 只载入模型结构,不载入预训练权重参数
model = models.resnet18(pretrained=False)
model.fc = nn.Linear(model.fc.in_features, n_class)
optimizer = optim.Adam(model.parameters())
- 训练参数
model = model.to(device)
# 交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 训练轮次 Epoch
EPOCHS = 20
训练流程
在训练集上训练:
训练指标计算依赖库
from torch.optim import lr_scheduler
def train_one_batch(images, labels):
'''
运行一个 batch 的训练,返回当前 batch 的训练日志
'''
# 获得一个 batch 的数据和标注
images = images.to(device)
labels = labels.to(device)
outputs = model(images) # 输入模型,执行前向预测
loss = criterion(outputs, labels) # 计算当前 batch 中,每个样本的平均交叉熵损失函数值
# 优化更新权重
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 获取当前 batch 的标签类别和预测类别
_, preds = torch.max(outputs, 1) # 获得当前 batch 所有图像的预测类别
preds = preds.cpu().numpy()
loss = loss.detach().cpu().numpy()
outputs = outputs.detach().cpu().numpy()
labels = labels.detach().cpu().numpy()
log_train = {}
log_train['epoch'] = epoch
log_train['batch'] = batch_idx
# 计算分类评估指标
log_train['train_loss'] = loss
log_train['train_accuracy'] = accuracy_score(labels, preds)
# log_train['train_precision'] = precision_score(labels, preds, average='macro')
# log_train['train_recall'] = recall_score(labels, preds, average='macro')
# log_train['train_f1-score'] = f1_score(labels, preds, average='macro')
return log_train
训练一轮后,在整个测试集上评估:
def evaluate_testset():
'''
在整个测试集上评估,返回分类评估指标日志
'''
loss_list = []
labels_list = []
preds_list = []
with torch.no_grad():
for images, labels in test_loader: # 生成一个 batch 的数据和标注
images = images.to(device)
labels = labels.to(device)
outputs = model(images) # 输入模型,执行前向预测
# 获取整个测试集的标签类别和预测类别
_, preds = torch.max(outputs, 1) # 获得当前 batch 所有图像的预测类别
preds = preds.cpu().numpy()
loss = criterion(outputs, labels) # 由 logit,计算当前 batch 中,每个样本的平均交叉熵损失函数值
loss = loss.detach().cpu().numpy()
outputs = outputs.detach().cpu().numpy()
labels = labels.detach().cpu().numpy()
loss_list.append(loss)
labels_list.extend(labels)
preds_list.extend(preds)
log_test = {}
log_test['epoch'] = epoch
# 计算分类评估指标
log_test['test_loss'] = np.mean(loss)
log_test['test_accuracy'] = accuracy_score(labels_list, preds_list)
log_test['test_precision'] = precision_score(labels_list, preds_list, average='macro')
log_test['test_recall'] = recall_score(labels_list, preds_list, average='macro')
log_test['test_f1-score'] = f1_score(labels_list, preds_list, average='macro')
return log_test
3. 训练监控
训练监控主要包括训练过程中训练日志的记录以及采用创建wandb可视化项目,可视化训练日志等操作。
3.1 训练日志记录
通过训练日志记录训练情况,并且进行可视化操作。
训练日志-训练集包含epoch、batch、train_loss、train_accuracy四个参数;
训练日志-训练集每个batch记录一次;
# 初始化
epoch = 0
batch_idx = 0
best_test_accuracy = 0
# 训练日志-训练集
df_train_log = pd.DataFrame()
log_train = {}
log_train['epoch'] = 0
log_train['batch'] = 0
images, labels = next(iter(train_loader))
log_train.update(train_one_batch(images, labels))
df_train_log = df_train_log.append(log_train, ignore_index=True)
df_train_log
epoch batch train_loss train_accuracy
0 0.0 0.0 3.4983625 0.03125
训练日志-测试集包含epoch、test_loss、test_accuracy、test_precision、test_recall、test_f1-score六个参数;
训练日志-测试集每个epoch记录一次。
# 训练日志-测试集
df_test_log = pd.DataFrame()
log_test = {}
log_test['epoch'] = 0
log_test.update(evaluate_testset())
df_test_log = df_test_log.append(log_test, ignore_index=True)
df_test_log
epoch test_loss test_accuracy test_precision test_recall test_f1-score
0 0.0 3.312752 0.030584 0.017317 0.030714 0.020133
3.2 训练日志可视化
# 载入训练日志表格
df_train = pd.read_csv('训练日志-训练集.csv')
df_test = pd.read_csv('训练日志-测试集.csv')
- 训练集损失函数
plt.figure(figsize=(16, 8))
x = df_train['batch']
y = df_train['train_loss']
plt.plot(x, y, label='训练集')
plt.tick_params(labelsize=20)
plt.xlabel('batch', fontsize=20)
plt.ylabel('loss', fontsize=20)
plt.title('训练集损失函数', fontsize=25)
plt.savefig('图表/训练集损失函数.pdf', dpi=120, bbox_inches='tight')
plt.show()

- 训练集准确率
plt.figure(figsize=(16, 8))
x = df_train['batch']
y = df_train['train_accuracy']
plt.plot(x, y, label='训练集')
plt.tick_params(labelsize=20)
plt.xlabel('batch', fontsize=20)
plt.ylabel('loss', fontsize=20)
plt.title('训练集准确率', fontsize=25)
plt.savefig('图表/训练集准确率.pdf', dpi=120, bbox_inches='tight')
plt.show()
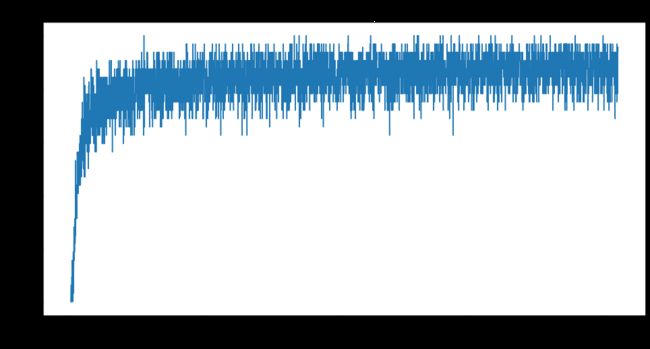
- 测试集损失函数
plt.figure(figsize=(16, 8))
x = df_test['epoch']
y = df_test['test_loss']
plt.plot(x, y, label='测试集')
plt.tick_params(labelsize=20)
plt.xlabel('epoch', fontsize=20)
plt.ylabel('loss', fontsize=20)
plt.title('测试集损失函数', fontsize=25)
plt.savefig('图表/测试集损失函数.pdf', dpi=120, bbox_inches='tight')
plt.show()
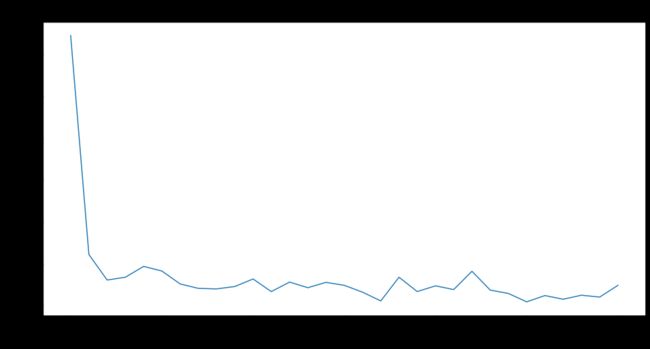
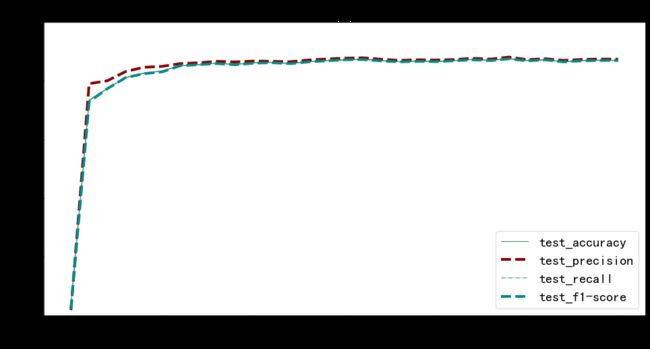
- 测试集评估指标
from matplotlib import colors as mcolors
import random
random.seed(124)
colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k', 'tab:blue', 'tab:orange', 'tab:green', 'tab:red', 'tab:purple', 'tab:brown', 'tab:pink', 'tab:gray', 'tab:olive', 'tab:cyan', 'black', 'indianred', 'brown', 'firebrick', 'maroon', 'darkred', 'red', 'sienna', 'chocolate', 'yellow', 'olivedrab', 'yellowgreen', 'darkolivegreen', 'forestgreen', 'limegreen', 'darkgreen', 'green', 'lime', 'seagreen', 'mediumseagreen', 'darkslategray', 'darkslategrey', 'teal', 'darkcyan', 'dodgerblue', 'navy', 'darkblue', 'mediumblue', 'blue', 'slateblue', 'darkslateblue', 'mediumslateblue', 'mediumpurple', 'rebeccapurple', 'blueviolet', 'indigo', 'darkorchid', 'darkviolet', 'mediumorchid', 'purple', 'darkmagenta', 'fuchsia', 'magenta', 'orchid', 'mediumvioletred', 'deeppink', 'hotpink']
markers = [".",",","o","v","^","<",">","1","2","3","4","8","s","p","P","*","h","H","+","x","X","D","d","|","_",0,1,2,3,4,5,6,7,8,9,10,11]
linestyle = ['--', '-.', '-']
def get_line_arg():
'''
随机产生一种绘图线型
'''
line_arg = {}
line_arg['color'] = random.choice(colors)
# line_arg['marker'] = random.choice(markers)
line_arg['linestyle'] = random.choice(linestyle)
line_arg['linewidth'] = random.randint(1, 4)
# line_arg['markersize'] = random.randint(3, 5)
return line_arg
metrics = ['test_accuracy', 'test_precision', 'test_recall', 'test_f1-score']
plt.figure(figsize=(16, 8))
x = df_test['epoch']
for y in metrics:
plt.plot(x, df_test[y], label=y, **get_line_arg())
plt.tick_params(labelsize=20)
plt.ylim([0, 1])
plt.xlabel('epoch', fontsize=20)
plt.ylabel(y, fontsize=20)
plt.title('测试集分类评估指标', fontsize=25)
plt.savefig('图表/测试集分类评估指标.pdf', dpi=120, bbox_inches='tight')
plt.legend(fontsize=20)
plt.show()
3.3 创建wandb可视化项目

4. 总结与扩展
4.1 注意事项
- 严禁把测试集图像用于训练(反向传播更新权重) 抛开baseline基准模型谈性能(速度、精度),都是耍流氓
- 测试集上的准确率越高,模型就一定越好吗?
- 常用数据集中存在大量的错标、漏标:https://mp.weixin.qq.com/s/4NbIA4wsNdX-N2uMOUmPLA
4.2 创新点展望
- 更换不同预训练图像分类模型
- 分别尝试三种不同的迁移学习训练配置:只微调训练模型最后一层(全连接分类层)、微调训练所有层、随机初始化模型全部权重,从头训练所有层
- 更换不同的优化器、学习率
4.3 扩展阅读
同济子豪兄的论文精读视频:https://openmmlab.feishu.cn/docs/doccnWv17i1svV19T0QquS0gKFc
开源图像分类算法库 MMClassificaiton:https://github.com/open-mmlab/mmclassification
机器学习分类评估指标
公众号 人工智能小技巧 回复 混淆矩阵
手绘笔记讲解:https://www.bilibili.com/video/BV1iJ41127wr?p=3
混淆矩阵: https://www.bilibili.com/video/BV1iJ41127wr?p=4
https://www.bilibili.com/video/BV1iJ41127wr?p=5
ROC曲线: https://www.bilibili.com/video/BV1iJ41127wr?p=6
https://www.bilibili.com/video/BV1iJ41127wr?p=7
https://www.bilibili.com/video/BV1iJ41127wr?p=8
F1-score:https://www.bilibili.com/video/BV1iJ41127wr?p=9
F-beta-score:https://www.bilibili.com/video/BV1iJ41127wr?p=10
4.4 训练好图像分类模型之后,做什么?
在新图像、视频、摄像头实时画面预测
在测试集上评估:混淆矩阵、ROC曲线、PR曲线、语义特征降维可视化
可解释性分析:CAM热力图
模型TensorRT部署:智能手机、开发板、浏览器、服务器
转ONNX并可视化模型结构
MMClassification图像分类、MMDeploy模型部署
开发图像分类APP和微信小程序