第四章 矩阵分解
第四章 Matrix Decompositions
文章目录
-
- 第四章 Matrix Decompositions
-
- 4.1 Determinant and Trace
-
- 4.1.1 Determinant
- 4.1.2 Trace
- 4.2 Eigenvalues and Eigenvectors
- 4.3 Cholesky Decomposition
- 4.4 Eigendecomposition and Diagonalization
- 4.5 Singular Value Decomposition
-
- 4.5.1 Geometric Intuitions for the SVD
- 4.5.2 Construction of the SVD
- 4.5.3 Eigenvalue Decomposition vs. Singular Value Decomposition
- 4.6 Matrix Approximation
- 4.7 Matrix Phylogeny
- 4.7 Matrix Phylogeny
4.1 Determinant and Trace
4.1.1 Determinant
1.行列式
只有方阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n具有行列式,通常记矩阵A的行列式为 d e t ( A ) det(A) det(A) 或 ∣ A ∣ \vert A \vert ∣A∣。
d e t ( A ) = ∣ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a n 1 a n 2 ⋯ a n n ∣ det(A)= \left \vert \begin{matrix} a_{11} &a_{12} & \cdots & a_{1n} \\ a_{21} &a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} &a_{n2} & \cdots & a_{nn} \\ \end{matrix} \right\vert det(A)=∣∣∣∣∣∣∣∣∣a11a21⋮an1a12a22⋮an2⋯⋯⋱⋯a1na2n⋮ann∣∣∣∣∣∣∣∣∣
方阵A的行列式是将矩阵A映射为一个实数的函数。
2.计算行列式
(1)三角矩阵
若对于 i > j , T i j = 0 i>j ,T_{ij}=0 i>j,Tij=0,则称方阵T为上三角矩阵。(即对角线下方全为0)。
若对于 i < j , T i j = 0 i
则三角矩阵 T ∈ R n × n T \in \R^{n\times n} T∈Rn×n
d e t ( T ) = ∏ i = 1 n T i i det(T)=\prod ^n _{i=1} T_{ii} det(T)=i=1∏nTii
(2)Laplace Expansion
方阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n , j = 1 , . . . , n j=1,...,n j=1,...,n
从列计算
d e t ( A ) = ∑ k = 1 n ( − 1 ) k + j a k j d e t ( A k , j ) det(A)=\sum _{k=1} ^n (-1)^{k+j} a_{kj}det(A_{k,j}) det(A)=k=1∑n(−1)k+jakjdet(Ak,j)
从行计算
d e t ( A ) = ∑ k = 1 n ( − 1 ) k + j a j k d e t ( A j , k ) det(A)=\sum _{k=1} ^n (-1)^{k+j} a_{jk}det(A_{j,k}) det(A)=k=1∑n(−1)k+jajkdet(Aj,k)
其中$A_{k,j} $ 表示矩阵A去掉 k 行 j 列剩下的子矩阵。
3.行列式性质
(1)矩阵乘积的行列式等于矩阵行列式的乘积, d e t ( A B ) = d e t ( A ) d e t ( B ) det(AB)=det(A)det(B) det(AB)=det(A)det(B)。
(2)矩阵转置后行列式不变, d e t ( A ) = d e t ( A T ) det(A)=det(A^T) det(A)=det(AT)。
(3)若矩阵A是可逆的,则 d e t ( A − 1 ) = 1 d e t ( A ) det(A^{-1})=\frac{1}{det(A)} det(A−1)=det(A)1 。
(4)相似矩阵行列式相同。
(5)将行列式某行或某列的数倍加到另一行(列),行列式不变。
(6) d e t ( λ A ) = λ n d e t ( A ) det(\lambda A)= \lambda ^n det(A) det(λA)=λndet(A)
(7)交换两行(列),行列式符号改变。
注:
根据性质5、6、7,则可先使用高斯变化将矩阵A化为行阶梯型,然后使用三角矩阵行列式计算方法计算行列式。
4.定理(使用行列式判断矩阵可逆)
方阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n ,A可逆 当且仅当 d e t ( A ) ≠ 0 det(A)\neq 0 det(A)=0 。
方阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n , d e t ( A ) ≠ 0 det(A)\neq 0 det(A)=0 当且仅当 $rank(A)=n $ 。即矩阵A可逆当且仅当它是满秩。
4.1.2 Trace
1.定义
方阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n 的迹
t r ( A ) : = ∑ i = 1 n a i i tr(A):= \sum _{i=1} ^n a_{ii} tr(A):=i=1∑naii
2.迹的性质
-
t r ( A + B ) = t r ( A ) + t r ( B ) , A , B ∈ R n × n tr(A+B) = tr(A)+tr(B),A,B\in \R^{n \times n} tr(A+B)=tr(A)+tr(B),A,B∈Rn×n
-
t r ( α A ) = α t r ( A ) , α ∈ R , A ∈ R n × n tr(\alpha A)= \alpha tr(A),\alpha \in \R,A\in \R^{n \times n} tr(αA)=αtr(A),α∈R,A∈Rn×n
-
t r ( I n ) = n tr(I_n)= n tr(In)=n
-
t r ( A B ) = t r ( B A ) , A ∈ R n × k , B ∈ R k × n tr(AB)= tr(BA), A \in \R^{n \times k},B\in \R^{k \times n} tr(AB)=tr(BA),A∈Rn×k,B∈Rk×n
-
矩阵乘积的迹,循环排列后,其迹不变
t r ( A K L ) = t r ( K L A ) = t r ( L A K ) , A ∈ R n × k , K ∈ R k × l , L ∈ R l × n tr(AKL)= tr(KLA)=tr(LAK), A \in \R^{n \times k},K \in \R^{k \times l},L \in \R^{l \times n} tr(AKL)=tr(KLA)=tr(LAK),A∈Rn×k,K∈Rk×l,L∈Rl×n 。
3.特征多项式
方阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n , λ ∈ R \lambda \in \R λ∈R ,
p A ( λ ) : = d e t ( A − λ I ) = c 0 + c 1 λ + c 2 λ 2 + . . . + c n − 1 λ n − 1 + ( − 1 ) n λ n p_A(\lambda) := det(A-\lambda I) \\ = c_0 +c_1 \lambda + c_2\lambda^2+...+c_{n-1}\lambda^{n-1} + (-1)^n\lambda^n \\ pA(λ):=det(A−λI)=c0+c1λ+c2λ2+...+cn−1λn−1+(−1)nλn
其中
c 0 = d e t ( A ) c n − 1 = ( − 1 ) n − 1 t r ( A ) c_0=det(A) \\ c_{n-1}= (-1)^{n-1} tr(A) c0=det(A)cn−1=(−1)n−1tr(A)
4.2 Eigenvalues and Eigenvectors
1.定义(eigenvalue,eigenvector)
方阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n 。若 A x = λ x Ax = \lambda x Ax=λx ,则
λ ∈ R \lambda \in \R λ∈R 是矩阵A的特征值, x ∈ R n ╲ x\in \R^n \diagdown x∈Rn╲ {0} 是对应的特征向量。
方程 A x = λ x Ax = \lambda x Ax=λx 称为特征方程。
注: 下列语句是等价的
-
$\lambda $ 是矩阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n 的一个特征向量
-
存在 x ∈ R n ╲ x\in \R^n \diagdown x∈Rn╲ {0} 使 A x = λ x Ax = \lambda x Ax=λx 。或 ( A − λ I n ) = 0 (A-\lambda I_n)=0 (A−λIn)=0 具有非零解。
-
r k ( A − λ I n ) < n rk(A-\lambda I_n)
rk(A−λIn)<n -
d e t ( A − λ I n ) = 0 det(A-\lambda I_n)=0 det(A−λIn)=0
2.定义(Collinearity and Codirection)
两个向量指向同一方向则称为共向,两个向量指向方向相同或相反称为共线。
注:(特征向量是不唯一的) 若 x x x 是A关于特征值 λ \lambda λ 的一个特征向量 ,则 c ∈ R ╲ c\in \R \diagdown c∈R╲ {0} , c x cx cx 仍为A关于特征值 λ \lambda λ 的特征向量。
故,所有与特征向量 x x x 共线的向量也是矩阵A关于相同特征值的特征向量。
3.定理
(1) λ ∈ R \lambda \in \R λ∈R 是矩阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n 的一个特征向量 当且仅当 λ \lambda λ 是特征多项式 p A ( λ ) p_A(\lambda) pA(λ) 的一个根。
(2)矩阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n 的n个不同的特征值 λ 1 , . . . , λ n \lambda_1,...,\lambda_n λ1,...,λn 对应的特征向量 x 1 , . . . x n x_1,...x_n x1,...xn 是线性无关的。
注: 通过该定理,特征向量 x 1 , . . . x n x_1,...x_n x1,...xn 可表示为 R n \R ^n Rn 的一组基。
4. algebraic multiplicity
方阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n 的一个特征向量 λ i \lambda _i λi, λ i \lambda _i λi的代数多重性是其在特征多项式根中出现的次数。
5. geometric multiplicity
λ i \lambda _i λi 是方阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n 的一个特征值,则 λ i \lambda _i λi 的几何重数是其对应的线性无关的特征向量的个数。换言之 λ i \lambda _i λi 的几何重数是其对应特征向量张成的特征空间的维数。
注: 一个特征值的几何重数至少为1。一个特征值的几何重数不超过其代数多重性。
6. Eigenspace and Eigenspectrum
方阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n ,与特征值 λ \lambda λ 对应的所有特征向量组成的集合称为特征空间,记为 E λ E_\lambda Eλ。关于A的所有特征值的集合称为A的Eigenspectrum。
注: $\lambda $ 是矩阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n 的一个特征值,则其对应的特征空间 E λ E_\lambda Eλ是 方程 ( A − λ I ) x = 0 (A-\lambda I)x=0 (A−λI)x=0 的解空间。
7.特征值与特征向量的性质
-
矩阵 A A A 和他的转置 A T A^T AT 具有相同的特征值,但特征向量不一定相同。
-
特征空间 E λ E_\lambda Eλ 是 A − λ I A-\lambda I A−λI 的零空间:
A x = λ x ⟺ A x − λ x = 0 ⟺ ( A − λ I ) x = 0 ⟺ x ∈ k e r ( A − λ I ) Ax=\lambda x \Longleftrightarrow Ax-\lambda x=0 \\ \Longleftrightarrow (A-\lambda I)x=0 \Longleftrightarrow x \in ker(A-\lambda I) Ax=λx⟺Ax−λx=0⟺(A−λI)x=0⟺x∈ker(A−λI) -
相似矩阵具有相同特征值。线性映射的重要参数为特征值、行列式和迹,因为他们不会因为基的改变而变化。
-
对称正定矩阵总是具有正的实特征值。
8. 缺陷矩阵
方阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n 具有的线性无关特征向量少于n个,则A是缺陷的。
**注:**一个非缺陷矩阵不一定要有n个不同特征值,但具有n个线性无关的特征向量。
一个缺陷矩阵至少有一个特征值其代数多重性大于其几何多重性。
一个缺陷矩阵不可能具有n个不同特征值。
9. 定理
(1)对于矩阵 A ∈ R m × n A \in \R^{m \times n} A∈Rm×n ,我们可获得一个对称正定矩阵 S ∈ R n × n S \in \R^{n \times n} S∈Rn×n
S : = A T A S:=A^TA S:=ATA
注: 若 r k ( A ) = n rk(A)=n rk(A)=n,则 S : = A T A S:=A^TA S:=ATA 是对称正定的。
(2)矩阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n 的行列式
d e t ( A ) = ∏ i = 1 n λ i det(A)=\prod ^n _{i=1} \lambda_{i} det(A)=i=1∏nλi
(3)矩阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n 的迹
t r ( A ) = ∑ i = 1 n λ i tr(A) = \sum ^n _{i=1} \lambda_{i} tr(A)=i=1∑nλi
10. Spectral Theorem
如果 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n 对称,则对应的向量空间 V V V存在由A的特征向量组成的一组标准正交基,且每个特征值都是实的。
4.3 Cholesky Decomposition
Cholesky Decomposition为对称正定矩阵提供了一个类平方根操作,可将对称正定矩阵分解为两个对角矩阵的乘积。
定理(Cholesky Decomposition)
一个对称正定矩阵A,可被分解为 A = L L T A = LL^T A=LLT 。其中 L L L是下三角矩阵(其对角元素为正)。
[ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a n 1 a n 2 ⋯ a n n ] = [ l 11 0 ⋯ 0 l 21 l 22 ⋯ 0 ⋮ ⋮ ⋱ ⋮ l n 1 l n 2 ⋯ l n n ] [ l 11 l 21 ⋯ l n 1 0 l 22 ⋯ l n 2 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ l n n ] \left[ \begin{matrix} a_{11} &a_{12} & \cdots & a_{1n} \\ a_{21} &a_{22} & \cdots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{n1} &a_{n2} & \cdots & a_{nn} \\ \end{matrix} \right] = \left[ \begin{matrix} l_{11} &0 & \cdots & 0 \\ l_{21} &l_{22} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ l_{n1} &l_{n2} & \cdots & l_{nn} \\ \end{matrix} \right] \left[ \begin{matrix} l_{11} &l_{21} & \cdots & l_{n1} \\ 0 &l_{22} & \cdots & l_{n2} \\ \vdots & \vdots & \ddots & \vdots \\ 0 &0 & \cdots & l_{nn} \\ \end{matrix} \right] ⎣⎢⎢⎢⎡a11a21⋮an1a12a22⋮an2⋯⋯⋱⋯a1na2n⋮ann⎦⎥⎥⎥⎤=⎣⎢⎢⎢⎡l11l21⋮ln10l22⋮ln2⋯⋯⋱⋯00⋮lnn⎦⎥⎥⎥⎤⎣⎢⎢⎢⎡l110⋮0l21l22⋮0⋯⋯⋱⋯ln1ln2⋮lnn⎦⎥⎥⎥⎤
L L L被称为A的Cholesky因子,且 L L L是唯一的。
注: 可利用Cholesky分解求解行列式
d e t ( A ) = d e t ( L ) d e t ( L T ) = d e t ( L ) 2 = ∏ i l i i 2 det(A)=det(L)det(L^T)=det(L)^2=\prod_i l_{ii}^2 det(A)=det(L)det(LT)=det(L)2=i∏lii2
4.4 Eigendecomposition and Diagonalization
1.对角矩阵
非对角线元素全为0的矩阵称为对角矩阵。
D = [ c 1 0 ⋯ 0 0 c 2 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ c n ] D=\left[ \begin{matrix} c_{1} &0 & \cdots & 0 \\ 0 &c_{2} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 &0 & \cdots & c_{n} \\ \end{matrix} \right] D=⎣⎢⎢⎢⎡c10⋮00c2⋮0⋯⋯⋱⋯00⋮cn⎦⎥⎥⎥⎤
对角矩阵可以很方便的计算其行列式、幂、逆。
行 列 式 : ∣ D ∣ = ∏ i n c i 行列式: \vert D \vert = \prod _i ^n c_i 行列式:∣D∣=i∏nci
k 次 幂 : D k = [ c 1 k 0 ⋯ 0 0 c 2 k ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ c n k ] k次幂:D^k =\left[ \begin{matrix} c_{1}^k &0 & \cdots & 0 \\ 0 &c_{2}^k & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 &0 & \cdots & c_{n}^k \\ \end{matrix} \right] k次幂:Dk=⎣⎢⎢⎢⎡c1k0⋮00c2k⋮0⋯⋯⋱⋯00⋮cnk⎦⎥⎥⎥⎤
逆 : D − 1 = [ 1 c 1 0 ⋯ 0 0 1 c 2 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ 1 c n ] 逆:D^{-1} = \left[ \begin{matrix} \frac{1}{c_{1}} &0 & \cdots & 0 \\ 0 &\frac{1}{c_{2}} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 &0 & \cdots & \frac{1}{c_{n}} \\ \end{matrix} \right] 逆:D−1=⎣⎢⎢⎢⎡c110⋮00c21⋮0⋯⋯⋱⋯00⋮cn1⎦⎥⎥⎥⎤
注: 计算逆时,当对角元素均不为0时成立。
2.定义(对角化)
矩阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n 与一个对角矩阵相似,则称A是可对角化的。即存在可逆矩阵 P ∈ R n × n P \in \R^{n \times n} P∈Rn×n ,使得 D = P − 1 A P D=P^{-1}AP D=P−1AP 。
其中 D D D 为对角矩阵,且其对角线元素为矩阵A 的特征值。矩阵P 由与特征值对应的特征向量组成,且该组向量线性无关。
设 λ 1 , . . . , λ n \lambda_1,...,\lambda_n λ1,...,λn 为A的特征值, p 1 , . . . , p n p_1,...,p_n p1,...,pn 为特征值对应的特征向量,且线性无关,可作为 R n \R^n Rn 的一组基。则
D = [ λ 1 0 ⋯ 0 0 λ 2 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ λ n ] , P = [ p 1 , p 2 , ⋯ , p n ] D=\left[ \begin{matrix} \lambda_{1} &0 & \cdots & 0 \\ 0 &\lambda_{2} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 &0 & \cdots & \lambda_{n} \\ \end{matrix} \right] , P=\left[ \begin{matrix} p_{1} , &p_{2} , & \cdots ,& p_{n} \end{matrix} \right] D=⎣⎢⎢⎢⎡λ10⋮00λ2⋮0⋯⋯⋱⋯00⋮λn⎦⎥⎥⎥⎤,P=[p1,p2,⋯,pn]
3.定理(特征分解)
当且仅当方阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n 的特征向量可作为 R n \R^n Rn 的一组基时, 方阵 $A $ 可被分解为 A = P D P − 1 A= PDP^{-1} A=PDP−1 。
P ∈ R n × n P \in \R^{n \times n} P∈Rn×n ; D D D 为对角矩阵,对角元素为A的特征值。
注: 只有非缺陷矩阵能被对角化。
- 特征分解步骤
假设对矩阵 A ∈ R n × n A \in \R^{n\times n} A∈Rn×n 进行特征分解
(1)计算特征值和特征向量;
(2)验证特征向量是否可以作为 R n \R^n Rn 的一组基;
(3)若(2)成立,构造矩阵 P = [ p 1 , . . . , p n ] P=[p_1,...,p_n] P=[p1,...,pn] ,对角化 A A A ,得对角矩阵 D = P − 1 A P D=P^{-1}AP D=P−1AP。故 A = P D P − 1 A=PDP^{-1} A=PDP−1
4. 对称方阵 S ∈ R n × n S \in \R^{n \times n} S∈Rn×n 一定可被对角化。
注:
-
由 A = P D P − 1 A= PDP^{-1} A=PDP−1 可得
A k = ( P D P − 1 ) K = P D K P − 1 A^k =(PDP^{-1})^K = PD^KP^{-1} Ak=(PDP−1)K=PDKP−1 -
若存在 A = P D P − 1 A= PDP^{-1} A=PDP−1 ,则
d e t ( A ) = d e t ( P D P − 1 ) = d e t ( P ) d e t ( D ) d e t ( P − 1 ) = d e t ( D ) = ∏ i d i i det(A)=det(PDP^{-1}) = det(P)det(D)det(P^{-1}) = det(D) = \prod _i d_{ii} det(A)=det(PDP−1)=det(P)det(D)det(P−1)=det(D)=i∏dii
4.5 Singular Value Decomposition
奇异值分解(SVD)称为线性代数基本理论,因为他可应用于任何矩阵,且总是存在的。
SVD Theorem
矩阵 A ∈ R m × n A \in \R^{m \times n} A∈Rm×n ,其秩 r ∈ [ 0 , min ( m , n ) ] r \in [0,\min(m,n)] r∈[0,min(m,n)],矩阵 A A A 的SVD如下形式
A m × n = U m × m Σ m × n V n × n A_{m \times n} = U_{m \times m}\Sigma _{m \times n} V_{n \times n} Am×n=Um×mΣm×nVn×n
U ∈ R m × m U \in \R^{m \times m} U∈Rm×m 是列向量为 u i , i = 1 , . . . , m u_i,i=1,...,m ui,i=1,...,m 的正交矩阵;
V ∈ R n × n V \in \R^{n \times n} V∈Rn×n 是列向量为 v i , i = 1 , . . . , n v_i,i=1,...,n vi,i=1,...,n 的正交矩阵;
Σ ∈ R m × n \Sigma \in \R^{m \times n} Σ∈Rm×n 其中 Σ i i = σ i ⩾ 0 , Σ i j = 0 , i ≠ j \Sigma_{ii}=\sigma_i \geqslant 0, \Sigma_{ij}=0,i \neq j Σii=σi⩾0,Σij=0,i=j 。
(1)若 m > n m>n m>n
Σ = [ σ 1 ⋯ 0 ⋮ ⋱ ⋮ 0 ⋯ σ r 0 ⋯ 0 ⋮ ⋱ ⋮ 0 ⋯ 0 ] \Sigma =\left[ \begin{matrix} \sigma_{1} & \cdots & 0 \\ \vdots & \ddots & \vdots \\ 0 & \cdots & \sigma_{r} \\ 0 & \cdots & 0 \\ \vdots & \ddots & \vdots \\ 0 & \cdots & 0 \end{matrix} \right] Σ=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎡σ1⋮00⋮0⋯⋱⋯⋯⋱⋯0⋮σr0⋮0⎦⎥⎥⎥⎥⎥⎥⎥⎥⎤
(2)若 m < n m
Σ = [ σ 1 ⋯ 0 0 ⋯ 0 ⋮ ⋱ ⋮ 0 ⋯ 0 0 ⋯ σ r 0 ⋯ 0 ] \Sigma =\left[ \begin{matrix} \sigma_{1} & \cdots & 0 & 0 & \cdots & 0\\ \vdots & \ddots & \vdots & 0 & \cdots & 0\\ 0 & \cdots & \sigma_{r} & 0 & \cdots & 0 \end{matrix} \right] Σ=⎣⎢⎡σ1⋮0⋯⋱⋯0⋮σr000⋯⋯⋯000⎦⎥⎤
- Σ ∈ R m × n \Sigma \in \R^{m \times n} Σ∈Rm×n 的对角元素 σ i , i = 1 , . . . , r \sigma_i ,i=1,...,r σi,i=1,...,r ,称为奇异值,且奇异值是唯一的。
- u i u_i ui 称为左奇异向量; v i v_i vi 称为右奇异向量。
- 按照惯例,奇异值是有序的,如 σ 1 ⩾ σ 2 ⩾ . . . ⩾ σ r \sigma_1 \geqslant \sigma_2 \geqslant ...\geqslant \sigma_r σ1⩾σ2⩾...⩾σr 。
- 任意矩阵 A ∈ R m × n A \in \R^{m \times n} A∈Rm×n ,其SVD均存在。
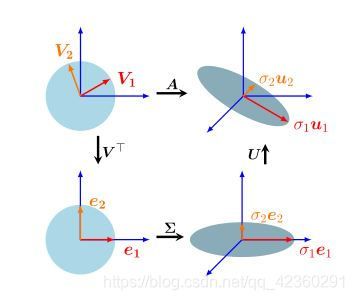
4.5.1 Geometric Intuitions for the SVD
一个矩阵 A ∈ R m × n A \in \R^{m \times n} A∈Rm×n 的奇异值分解可以被解释为线性映射 Φ : R n → R m \Phi : \R^n \rightarrow \R^m Φ:Rn→Rm 。
1.首先通过矩阵 V V V 进行基底变换;
2.再通过 Σ \Sigma Σ 对坐标进行拉伸,升维或降维;
3.最后通过矩阵 U U U 对变化后的空间基底进行变换。
如下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XT1MrtE3-1599566320640)(第四章 矩阵分解.assets/SVD几何直观.JPG)]
4.5.2 Construction of the SVD
1. 比较一个对称正定矩阵的特征分解和SVD:
S = S T = P D P T S = U Σ V T S=S^T=PDP^T \\ S=U\Sigma V^T S=ST=PDPTS=UΣVT
若我们设
U = P = V , D = Σ U=P=V,D=\Sigma U=P=V,D=Σ
则对称正定矩阵的SVD和特征分解相同。
2. 对于矩阵 A ∈ R m × n A \in \R^{m \times n} A∈Rm×n ,我们总可以构造一个对称正定矩阵 A T A A^TA ATA 。因此我们可以对角化 A T A A^TA ATA
A T A = P D P T = P [ λ 1 0 ⋯ 0 0 λ 2 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ λ n ] P T A^TA = PDP^T = P \left[ \begin{matrix} \lambda_{1} &0 & \cdots & 0 \\ 0 &\lambda_{2} & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 &0 & \cdots & \lambda_{n} \\ \end{matrix} \right] P^T ATA=PDPT=P⎣⎢⎢⎢⎡λ10⋮00λ2⋮0⋯⋯⋱⋯00⋮λn⎦⎥⎥⎥⎤PT
注: 因为A是对称正定的,故P是正交矩阵,所以 P T = P − 1 P^T=P^{-1} PT=P−1 。
3. 假设 A A A 的SVD是存在的
A T A = ( U Σ V T ) T U Σ V T = V Σ T U T U Σ V T A^TA= (U\Sigma V^T)^T U\Sigma V^T = V\Sigma^T U^T U\Sigma V^T ATA=(UΣVT)TUΣVT=VΣTUTUΣVT
因为 U , V U,V U,V 都是正交矩阵,故
A T A = V Σ T Σ V T = V [ σ 1 2 0 ⋯ 0 0 σ 2 2 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ σ n 2 ] V T A^TA=V\Sigma^T \Sigma V^T = V \left[ \begin{matrix} \sigma_{1}^2 &0 & \cdots & 0 \\ 0 &\sigma_{2}^2 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 &0 & \cdots & \sigma_{n}^2 \\ \end{matrix} \right] V^T ATA=VΣTΣVT=V⎣⎢⎢⎢⎡σ120⋮00σ22⋮0⋯⋯⋱⋯00⋮σn2⎦⎥⎥⎥⎤VT
4. 对比2、3中式子 ,可得
V T = P T σ i 2 = λ i V^T=P^T \\ \sigma_i ^2 =\lambda_i VT=PTσi2=λi
故 A T A A^TA ATA 的特征向量组成的矩阵 P P P 是 A A A 的右奇异向量 V V V 。
5. 为保证 U U U 的正交性,可利用矩阵 A A A 对右奇异向量 v i v_i vi 变换后,其正交性不变得
u i : = A v i ∥ A v i ∥ = 1 λ i A v i = 1 σ i A v i u_i:= \frac {A v_i}{\Vert A v_i \Vert } = \frac {1}{\sqrt{\lambda_i} } A v_i = \frac {1}{\sigma_i} A v_i ui:=∥Avi∥Avi=λi1Avi=σi1Avi
4.5.3 Eigenvalue Decomposition vs. Singular Value Decomposition
对比特征分解 A = P D P − 1 A=PDP^{-1} A=PDP−1 和SVD A = U Σ V T A=U\Sigma V^T A=UΣVT
-
(1)SVD可用于任意矩阵 A ∈ R m × n A \in \R^{m \times n} A∈Rm×n ,而特征分解只适用于方阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n ,且要求其特征向量可作为 R n \R^n Rn 的一组基。
-
(2)特征分解中矩阵 P P P 中列向量不要求正交;而SVD中 U , V U,V U,V 中向量是标准正交的。
-
(3)特征分解和SVD都是由三个线性映射组成:
- 在原域内改变基;
- 独立的缩放每个基向量,将其映射到另一个域上;
- 在新域上进行基变换。
注: 两者之间的不同是,在SVD中,两个域维数可不相同。
-
(4)在SVD 中, U , V U,V U,V 通常不互为逆;而特征分解中 P , P − 1 P,P^{-1} P,P−1 互为对方的逆。
-
(5)SVD中 $\Sigma $中对角元素均是非负的;特征分解中对角矩阵不是。
-
(6)SVD 和特征分解密切相关:
-
A A A 的左奇异向量是 A A T AA^T AAT 的特征向量;
-
A A A 的右奇异向量是 A T A A^TA ATA 的特征向量;
-
A A A 的非零奇异值是 A T A A^TA ATA ( A A T AA^T AAT)的特征值的平方根。
-
-
(7) 对称矩阵 A ∈ R n × n A \in \R^{n \times n} A∈Rn×n 的特征分解和SVD 是相同的。
**SVD 的术语和约定 **
(1)SVD 有时也成为 full SVD。
(2)更关注奇异值矩阵为方阵形式时,SVD 也可写为:
A m × n = U m × n Σ n × n V n × n A_{m \times n} = U_{m \times n}\Sigma _{n \times n} V_{n \times n} Am×n=Um×nΣn×nVn×n
该形式也称为 reduce SVD。
(3)若 A ∈ R m × n A \in \R^{m \times n} A∈Rm×n 秩为 r,则SVD可写为
A m × n = U m × r Σ r × r V r × n A_{m \times n} = U_{m \times r}\Sigma _{r \times r} V_{r \times n} Am×n=Um×rΣr×rVr×n
4.6 Matrix Approximation
矩阵近似:根据SVD A = U Σ V T ∈ R m × n A=U\Sigma V^T \in \R^{m\times n} A=UΣVT∈Rm×n将矩阵 A A A 表示为一些简单的低秩矩阵 A i A_i Ai之和。
- 构造秩为1的矩阵 A i ∈ R m × n A_i\in \R^{m \times n} Ai∈Rm×n
A i : = u i v i T A_i := u_iv_i^T Ai:=uiviT
其中 u i , v i u_i,v_i ui,vi 分别为 U , V U,V U,V 的第 i 个正交列向量。
- 秩为 r 的矩阵 A ∈ R m × n A \in \R^{m \times n} A∈Rm×n 可被表示为秩为1的矩阵 A i A_i Ai 之和
A = ∑ i = 1 r σ i u i v i T = ∑ i = 1 r σ i A i A = \sum_{i=1}^r \sigma_i u_iv_i^T =\sum_{i=1}^r \sigma_i A_i A=i=1∑rσiuiviT=i=1∑rσiAi
其中 σ i \sigma_i σi 是矩阵 A A A 的第 i 个特征值。
∑ i j u i v j T , i ≠ j \sum _{ij} u_iv_j^T , i \neq j ∑ijuivjT,i=j 不存在是因为 Σ \Sigma Σ 是对角矩阵; i > r i>r i>r 不存在是因为其对应特征值为0 。
- 矩阵A的秩k近似(k
1.定义(Spectral Norm of a Matrix)
对 x ∈ R x \in \R x∈R\ {0} ,矩阵 A ∈ R m × n A \in \R^{m \times n} A∈Rm×n 的Spectral Norm 被定义为
∥ A ∥ 2 : = m a x x ∥ A x ∥ 2 ∥ x ∥ 2 \Vert A\Vert_2 :=max_{x} \frac{\Vert Ax\Vert_2}{\Vert x\Vert_2} ∥A∥2:=maxx∥x∥2∥Ax∥2
Spectral Norm决定了任何向量x乘以A最多可以变成多长。
2.定理
矩阵 A ∈ R m × n A \in \R^{m \times n} A∈Rm×n 的Spectral Norm为其最大奇异值 σ 1 \sigma_1 σ1。
3.定理(Eckart-Young Theorem)
矩阵 A ∈ R m × n A \in \R^{m \times n} A∈Rm×n 秩为r ,矩阵 B ∈ R m × n B \in \R^{m \times n} B∈Rm×n 秩为k。对任意 k ⩽ r k \leqslant r k⩽r , A ^ ( k ) : = ∑ i = 1 k σ i u i v i T \hat{A}(k) := \sum_{i=1}^k \sigma_i u_iv_i^T A^(k):=∑i=1kσiuiviT 满足:
A ^ ( k ) = a r g m i n r k ( B ) = k ∥ A − B ∥ 2 ∥ A − A ^ ( k ) ∥ 2 = σ k + 1 \hat{A}(k) = argmin_{rk(B)=k} \Vert A-B \Vert _2 \\ \Vert A-\hat{A}(k) \Vert _2 = \sigma_{k+1} A^(k)=argminrk(B)=k∥A−B∥2∥A−A^(k)∥2=σk+1
Eckart-Young定理明确地陈述了用rank-k近似逼近A时引入的误差有多大。
4.7 Matrix Phylogeny
**不同类型矩阵关系的 phylogenetic tree **
(黑色箭头表示是其子集)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gl9ZnF5V-1599566320654)(第四章 矩阵分解.assets/矩阵关系.JPG)]
- 任意实矩阵均可求伪逆和SVD。实矩阵分出两个分支:方阵、非方阵
- 对于方阵可求行列式、迹、特征值特征向量;
- 行列式判断矩阵是否可逆。(行列式不为0,矩阵可逆)
- 特征向量判断矩阵是否缺陷。(特征向量可作为一组基则是非缺陷矩阵)
- 非缺陷矩阵可进行对角化。
- 可逆矩阵若列是互相正交的则为正交矩阵, A T = A − 1 A^T=A^{-1} AT=A−1。
- 对称矩阵的特征值均为实数,对称矩阵有 正定矩阵、对角矩阵两个子集。
- 正定矩阵可进行Cholesky分解,其特征向量是大于0的。正定矩阵一定可逆。
- 单位矩阵是特殊的对角矩阵。
A ( k ) : = ∑ i = 1 k σ i u i v i T {A}(k) := \sum_{i=1}^k \sigma_i u_iv_i^T A(k):=∑i=1kσiuiviT 满足:
A ^ ( k ) = a r g m i n r k ( B ) = k ∥ A − B ∥ 2 ∥ A − A ^ ( k ) ∥ 2 = σ k + 1 \hat{A}(k) = argmin_{rk(B)=k} \Vert A-B \Vert _2 \\ \Vert A-\hat{A}(k) \Vert _2 = \sigma_{k+1} A^(k)=argminrk(B)=k∥A−B∥2∥A−A^(k)∥2=σk+1
Eckart-Young定理明确地陈述了用rank-k近似逼近A时引入的误差有多大。
4.7 Matrix Phylogeny
**不同类型矩阵关系的 phylogenetic tree **
(黑色箭头表示是其子集)
[外链图片转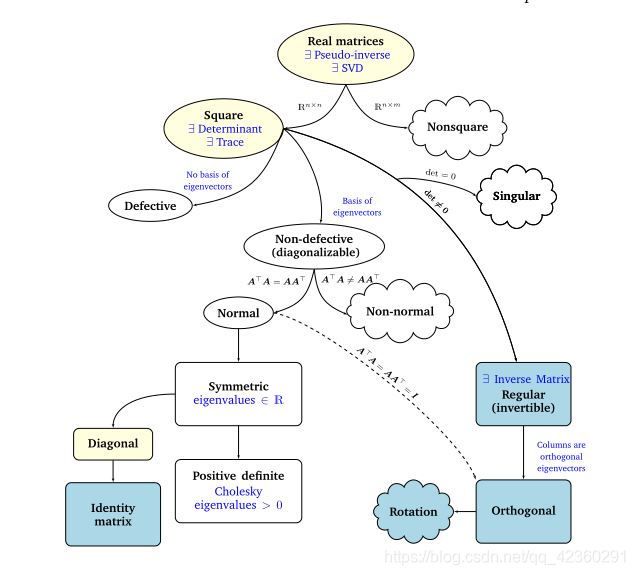
存中…(img-gl9ZnF5V-1599566320654)]
- 任意实矩阵均可求伪逆和SVD。实矩阵分出两个分支:方阵、非方阵
- 对于方阵可求行列式、迹、特征值特征向量;
- 行列式判断矩阵是否可逆。(行列式不为0,矩阵可逆)
- 特征向量判断矩阵是否缺陷。(特征向量可作为一组基则是非缺陷矩阵)
- 非缺陷矩阵可进行对角化。
- 可逆矩阵若列是互相正交的则为正交矩阵, A T = A − 1 A^T=A^{-1} AT=A−1。
- 对称矩阵的特征值均为实数,对称矩阵有 正定矩阵、对角矩阵两个子集。
- 正定矩阵可进行Cholesky分解,其特征向量是大于0的。正定矩阵一定可逆。
- 单位矩阵是特殊的对角矩阵。