yolo2
(写在前面:如果你想 run 起来,立马想看看效果,那就直接跳转到最后一张,动手实践,看了结果再来往前看吧,开始吧······)
一、YOLOv1 简介
这里不再赘述,之前的我的一个 GitChat 详尽的讲述了整个代码段的含义,以及如何一步步的去实现它,可参照这里手把手实践YOLO深度残差神经网络拐点检测
二、YOLOv2 简介
V1 版本的缺陷和不足,就是 V2 版本出现的源泉与动力,而 V1 版本究竟在哪些地方是它的短板之处呢:
V1 缺陷之处:
- 输入尺寸固定:由于输出层为全连接层,因此在检测时,YOLO 训练模型只支持与训练图像相同的输入分辨率。其它分辨率需要缩放成此固定分辨率;
- 占比较小的目标检测效果不好:虽然每个格子可以预测 B 个 bounding box,但是最终只选择只选择 IOU 最高的 bounding box 作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。
2.1 anchor box 的思想引入
为提高物体定位精准性和召回率,YOLO 作者提出了 《YOLO9000: Better, Faster, Stronger》 (Joseph Redmon, Ali Farhadi, CVPR 2017, Best Paper Honorable Mention),也就是 YOLOv2 的论文全名,相比 v1 提高了训练图像的分辨率;引入了 faster rcnn 中 anchor box 的思想,对网络结构的设计进行了改进,使得模型更易学习。
什么是(候选区域框)anchor box?
假设特征可以看做一个尺度 6448 像素的 256 通道图像,对于该图像的每一个位置,考虑 9 个可能的候选窗口:三种面积三种比例。这些候选窗口称为 anchors。下图示出 6448 图像 anchor 中心,在每个面积尺寸下,取三种不同的长宽比例(1:1,1:2,2:1),这样一来,我们得到了一共 9 种面积尺寸各异的 anchor。示意图如下:

以一个点 9 种尺寸来取 proposal,重复区域多。而且 feature map 相邻两个点对应原图的 9 个 proposal 也是很多重复区域。只是整个 faster RCNN 中的第一步,只是对候选区域进行提取 (RPN, region proposal networks, 候选区域生成网络)。这个过程只是希望能够得到覆盖目标的候选区域,所以有不同尺寸不同比例的 proposal(这样才有最大可能可以在一个候选框中包括完整的目标)。而在这之后,确实会有很多重复区域,而这其实是候选区域生成之后的下一个问题。针对这个问题,一般会采用非极大值抑制算法进行去重 (NMS, non maximum suppression)。
至于这个 anchor 到底是怎么用的,这个是理解整个问题的关键。
下面是整个 faster RCNN 结构的示意图:
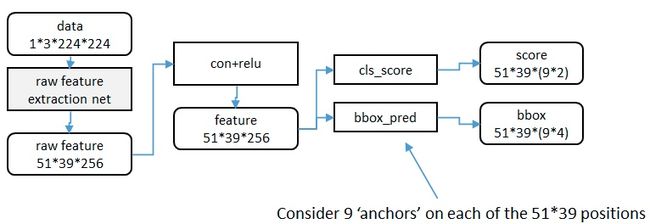
输入图像无论是什么大小的样本,都要转化为 224*224(可根据情况自己设定)大小的图片,送进网络进行训练。( 为什么要固定输入网络图片尺寸呢?后面解释。)
对于每个 3x3 的窗口,作者就计算这个滑动窗口的中心点所对应的原始图片的中心点。然后作者假定,这个 3x3 窗口,是从原始图片上通过 SPP 池化 得到的,而这个池化的区域的面积以及比例,就是一个个的 anchor。换句话说,对于每个 3x3 窗口,作者假定它来自 9 种不同原始区域的池化,但是这些池化在原始图片中的中心点,都完全一样。这个中心点,就是刚才提到的,3x3 窗口中心点所对应的原始图片中的中心点。如此一来,在每个窗口位置,我们都可以根据 9 个不同长宽比例、不同面积的 anchor,逆向推导出它所对应的原始图片中的一个区域,这个区域的尺寸以及坐标,都是已知的。而这个区域,就是我们想要的 proposal。所以我们通过滑动窗口和 anchor,成功得到了 51x39x9 个原始图片的 proposal。接下来,每个 proposal 我们只输出 6 个参数:每个 proposal 和 ground truth 进行比较得到的前景概率和背景概率 (2 个参数)(对应图上的 clsscore);由于每个 proposal 和 ground truth 位置及尺寸上的差异,从 proposal 通过平移放缩得到 ground truth 需要的 4 个平移放缩参数(对应图上的 bboxpred)。
为什么之前的 CNN 要固定输入网络图片尺寸呢?
CNN 大体包含 3 部分:卷积、池化、全连接
- 卷积层。卷积操作对图片输入的大小会有要求吗?比如一个 5 * 5 的卷积核,我输入的图片是 30 * 81 的大小,可以得到 (26,77) 大小的图片,并不会影响卷积操作。我输入 600 * 500,它还是照样可以进行卷积,也就是卷积对图片输入大小没有要求,只要你喜欢,任意大小的图片进入,都可以进行卷积。
- 池化层。池化对图片大小会有要求吗?比如我池化大小为(2,2)我输入一张 30 * 40 的,那么经过池化后可以得到 15 * 20 的图片。输入一张 53 * 22 大小的图片,经过池化后,我可以得到 26 * 11 大小的图片。因此池化这一步也没对图片大小有要求。只要你喜欢,输入任意大小的图片,都可以进行池化。
- 全连接层。既然池化和卷积都对输入图片大小没有要求,那么就只有全连接层对图片结果又要求了。因为全连接层我们的连接劝值矩阵的大小 W,经过训练后,就是固定的大小了,比如我们从卷积到全连层,输入和输出的大小,分别是 50、30 个神经元,那么我们的权值矩阵(50,30)大小的矩阵了。因此空间金字塔池化,要解决的就是从卷积层到全连接层之间的一个过度。
这里插入卷积、池化层的输入输出计算方法:
 例子计算详情
例子计算详情 
怎么改变这个现状呢,也就是无论输入图片是什么大小,不需要都转化为统一大小的图片,再送入网络的预处理过程。这就出现了大神何凯明的 CNN 应用之 SPP。空间金字塔池化的卷积神经网络物体检测,很详细,能看懂其中原因和机理,不赘述。
2.2 YOLOv2 多处改进
2.2.1 输出层使用卷积层替代 YOLOv1 的全连接层
附 darknet-19 的结构表:

包含 19 conv + 5 maxpooling。用 1x1 卷积层替代 YOLOv1 的全连接层。
1x1 卷积层(此处 1x1 卷积层的存在是为了跨通道信息整合)如上图的红色矩形框部分。
引入一点:YOLO,YOLOv2、YOLO9000,Darknet-19,Darknet-53,YOLOv3 分别是什么关系?
- YOLOv2 是 YOLO 的升级版,但并不是通过对原始加深或加宽网络达到效果提升,反而是简化了网络。
- YOLO9000 是 CVPR2017 的最佳论文提名。首先讲一下这篇文章一共介绍了 YOLOv2 和 YOLO9000 两个模型,二者略有不同。前者主要是 YOLO 的升级版,后者的主要检测网络也是 YOLOv2,同时对数据集做了融合,使得模型可以检测 9000 多类物体。而提出 YOLO9000 的原因主要是目前检测的数据集数据量较小,因此利用数量较大的分类数据集来帮助训练检测模型。
- YOLOv2 使用了一个新的分类网络作为特征提取部分,参考了前人的先进经验,比如类似于 VGG,作者使用了较多的 3 * 3 卷积核,在每一次池化操作后把通道数翻倍。借鉴了 network in network 的思想,网络使用了全局平均池化(global average pooling),把 1 * 1 的卷积核置于 3 * 3 的卷积核之间,用来压缩特征。也用了 batch normalization(前面介绍过)稳定模型训练。最终得出的基础模型就是 Darknet-19,如上图,其包含 19 个卷积层、5 个最大值池化层(maxpooling layers )
2.2.2 卷积层全部使用 Batch Normalization
v1 中也大量用了 Batch Normalization,同时在定位层后边用了 dropout,v2 中取消了 dropout,在卷积层全部使用 Batch Normalization。
2.2.3 K-Means 算法
我们知道在 Faster R-CNN 中 anchor box 的大小和比例是按经验设定的,然后网络会在训练过程中调整 anchor box 的尺寸。但是如果一开始就能选择到合适尺寸的 anchor box,那肯定可以帮助网络越好地预测 detection。所以作者采用 k-means 的方式对训练集的 bounding boxes 做聚类,试图找到合适的 anchor box。
另外作者发现如果采用标准的 k-means(即用欧式距离来衡量差异),在 box 的尺寸比较大的时候其误差也更大,而我们希望的是误差和 box 的尺寸没有太大关系。所以通过 IOU 定义了如下的距离函数,使得误差和 box 的大小无关:
Faster R-CNN 采用的是手选先验框方法,YOLOv2 对其做了改进,采用 k-means 在训练集 bbox 上进行聚类产生合适的先验框. 由于使用欧氏距离会使较大的 bbox 比小的 bbox 产生更大的误差,而 IOU 与 bbox 尺寸无关, 因此使用 IOU 参与距离计算, 使得通过这些 anchor boxes 获得好的 IOU 分值。距离公式:

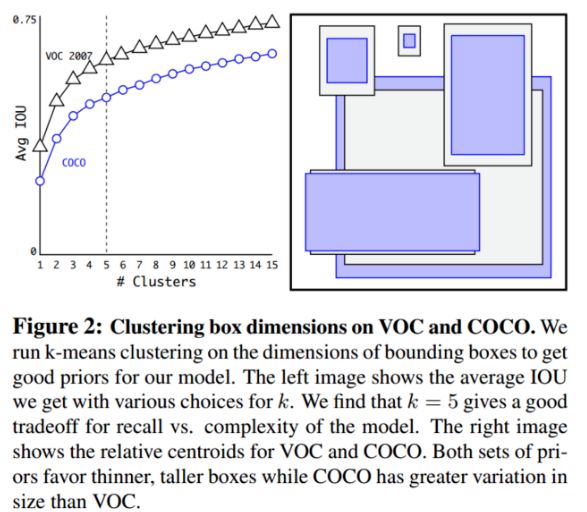
如下图 Figure2,左边是聚类的簇个数核 IOU 的关系,两条曲线分别代表两个不同的数据集。在分析了聚类的结果并平衡了模型复杂度与 recall 值,作者选择了 K=5,这也就是 Figure2 中右边的示意图是选出来的 5 个 box 的大小,这里紫色和黑色也是分别表示两个不同的数据集,可以看出其基本形状是类似的。而且发现聚类的结果和手动设置的 anchor box 大小差别显著。聚类的结果中多是高瘦的 box,而矮胖的 box 数量较少。
K-Means 算法概述:k-means 是非监督学习中的聚类算法; 基本 K-Means 算法的思想很简单,事先确定常数 K,常数 K 意味着最终的聚类类别数,首先随机选定初始点为质心,并通过计算每一个样本与质心之间的相似度 (这里为欧式距离),将样本点归到最相似的类中,接着,重新计算每个类的质心 (即为类中心),重复这样的过程,知道质心不再改变,最终就确定了每个样本所属的类别以及每个类的质心。由于每次都要计算所有的样本与每一个质心之间的相似度,故在大规模的数据集上,K-Means 算法的收敛速度比较慢。

使用聚类进行选择的优势是达到相同的 IOU 结果时所需的 anchor box 数量更少, 使得模型的表示能力更强, 任务更容易学习。
2.2.4 Multi-Scale Training
和 YOLOv1 训练时网络输入的图像尺寸固定不变不同,YOLOv2(在 cfg 文件中 random=1 时)每隔几次迭代后就会微调网络的输入尺寸。训练时每迭代 10 次,就会随机选择新的输入图像尺寸。因为 YOLOv2 的网络使用的 downsamples 倍率为 32,所以使用 32 的倍数调整输入图像尺寸 {320,352,…,608}。训练使用的最小的图像尺寸为 320 x 320,最大的图像尺寸为 608 x 608。 这使得网络可以适应多种不同尺度的输入。更多详细的资料可查看这里目标检测之 YOLOv3,YOLOv3 才是全文的的重点。
这里给出官方的 YOLOv2 与其它模型在 VOC 2007 数据集上的效果对比

三:YOLO v3 简介
本文的重点,先一张图看看 V3 版本的强大
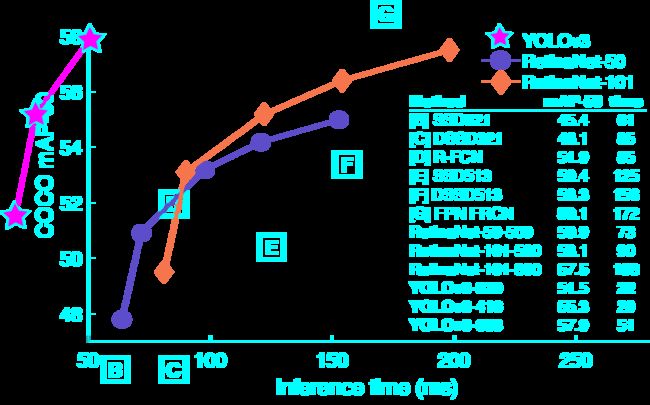
横轴是每张图像的预测推理时间,单位 ms。纵轴是在 COCO 数据集上预测的 [email protected] 的精度。无论是在耗费时间,还是预测精度上面,v3 版本都完胜过去的一些模型。
darknet-53 模型
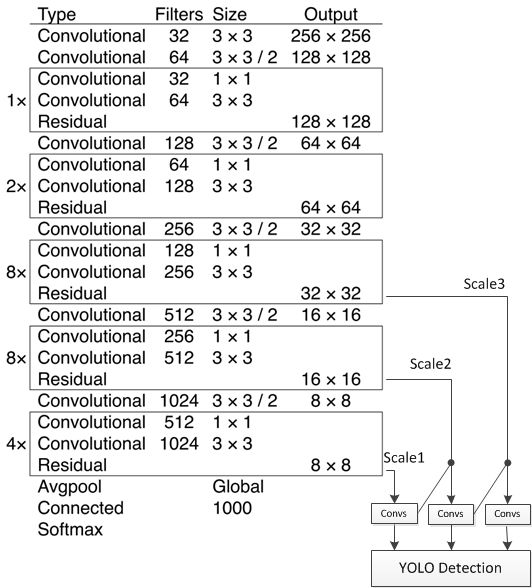 注:YOLO Detection 层: 坐标及类别结果输出层;Region 82,Region 94,Region 106。
注:YOLO Detection 层: 坐标及类别结果输出层;Region 82,Region 94,Region 106。
YOLOv3 的改进之处:多尺度预算
-
坐标预测:bbox 预测仍是 yolov2 的使用维度聚类(dimension clusters )作为 anchor boxes 来预测边界框. 在训练期间,我们使用平方误差损失的总和。
-
对象分数:YOLOv3 使用逻辑回归预测每个边界框(bounding box)的对象分数。 如果先前的边界框比之前的任何其他边界框重叠 ground truth 对象,则该值应该为 1。如果以前的边界框不是最好的,但是确实将 ground truth 对象重叠了一定的阈值以上,我们会忽略这个预测,按照 [15] 进行。我们使用阈值 0.5。与 [15] 不同,我们的系统只为每个 ground truth 对象分配一个边界框。如果先前的边界框未分配给 grounding box 对象,则不会对坐标或类别预测造成损失。
-
类别预测:每个框使用多标签分类来预测边界框可能包含的类。在训练过程中,使用二元交叉熵损失来进行类别预测。
补充:Darknet 框架 Darknet 由 C 语言和 CUDA 实现, 对 GPU 显存利用效率较高 (CPU 速度差一些, 通过与 SSD 的 Caffe 程序对比发现存在 CPU 较慢,GPU 较快的情况). Darknet 对第三方库的依赖较少, 且仅使用了少量 GNU linux 平台 C 接口, 因此很容易移植到其它平台, 如 Windows 或嵌入式设备.
四:动手实践篇
来开始本文的重中之重吧——
第一步:首先根据官网提示,一步步的走一遍,直到能够训练 VOC 数据集,就可以停下来歇歇了。官网点这里穿越如果一起正常,恭喜你,就可以开始之后的步骤了。当然有兴趣想了解 YOLOv3 中设计上的更多细节,可以去看下诙谐幽默的论文,点这里,看 YOLOv3: An Incremental Improvement后面也会就论文中和修改中的一些联系,做个解释。
第二步:上面做完,只是说明你可以检测和训练了官方的图片数据集,下面开始自己的数据集。
注意点: 如果你的电脑设备是有 GPU 加速图像运算的,那样在第一步中,默认的还是 CPU 下的训练,想要使用 GPU 就要改 Makefile 文件这里了
 这是我这一个博客中看到的,将红色框圈中的部分改为 1,修改了之后,在 darknet 文件目录下 make clean 清除之前的 make 文件,重新 make,发现速度明显提高,使用上了 GPU 训练。(其实在之前第一次我重新 make 时候报 opencv 错误,后来尽管发错 opencv 没有安装好,make 也通过了,对这个没有影响,就没有太关注这里了,有经验的求告知)。相同的命令,再来训练一次 VOC 数据试试看,速度是不是提高杠杠的。
这是我这一个博客中看到的,将红色框圈中的部分改为 1,修改了之后,在 darknet 文件目录下 make clean 清除之前的 make 文件,重新 make,发现速度明显提高,使用上了 GPU 训练。(其实在之前第一次我重新 make 时候报 opencv 错误,后来尽管发错 opencv 没有安装好,make 也通过了,对这个没有影响,就没有太关注这里了,有经验的求告知)。相同的命令,再来训练一次 VOC 数据试试看,速度是不是提高杠杠的。
第三步:数据集的采集,制作标签,这块还参考手把手实践 YOLO 深度残差神经网络拐点检测,一句话也就是 labelImg 标记软件工具了,具体不详述了。其中有一点就是 ImageSets/Main/ 文件夹下的 train.txt,test.txt,val.txt,这里的文件需要改为自己待训练的图片所有名字编号,在生成待训练的 train.txt 大有用处。
第四步:对待训练初始配置参数进行修改
**改动一 **
首先确定你需要做几个类别的物体检测,也就是 classes=1,还是 classes=5 或者 7,或者 20。我这里待检测的类别为一类,所以 classes=1, 如下图的 cfg 文件夹下的.data 文件:
- class 为训练的类别数
- train 为训练集 train.txt
- valid 为验证集 val.txt(未标识添加,后期可加入)
- names 为 my_target.names,里面为自己训练的目标名称
- backup 为 weights 的存储位置
将 VOC 格式的 xml 文件转换成 YOLO 格式的 txt 文件。
- train.txt 为 python voclabel.py 自动生成的,为自己的待训练样本文件位置。其中在 voclabel.py 文件我对其进行了修改,sets=[] 也进行了删减,只留下自己需要的那一部分;lasses=[" "], 里面为自己的检测类别;生成的 train.txt 也只是自己需要的部分,如下图(如有不妥或者错误,求批评指正,自己想着改的,并未看到相关材料指导)

- <文件名>.names 文件 原始的部分为 coco.data。如果你不想惹麻烦,直接将此处更名为 coco.data 即可。如若你想将此处的.data 文件更改为自己的特有命名,如 my_yolov3.data。这就需要在 examples 里面的 darknet.c 文件的 440 行处进行修改为自己的命名,然后 cd 到 darknet 文件夹下 make clean 删除之前的 make 文件,然后重新 make 即可。
没改之前直接使用,会出现这个错误提示(训练和检测报错都有):

改动就是在这里修改:

make 命令百科
在软件开发中,make 是一个工具程序(Utility software),经由读取叫做“makefile”的文件,自动化建构软件。它是一种转化文件形式的工具,转换的目标称为“target”;与此同时,它也检查文件的依赖关系,如果需要的话,它会调用一些外部软件来完成任务。它的依赖关系检查系统非常简单,主要根据依赖文件的修改时间进行判断。大多数情况下,它被用来编译源代码,生成结果代码,然后把结果代码连接起来生成可执行文件或者库文件。它使用叫做“makefile”的文件来确定一个 target 文件的依赖关系,然后把生成这个 target 的相关命令传给 shell 去执行。
许多现代软件的开发中 (如 Microsoft Visual Studio),集成开发环境已经取代 make,但是在 Unix 环境中,仍然有许多任务程师采用 make 来协助软件开发。
- /backup/ 文件夹下用于存放训练好的.weights 参数文件,源代码里面是迭代次数小于 1000 时,每 100 次保存一次,大于 1000 时,没 10000 次保存一次。自己可以根据需求进行更改,然后重新编译即可。代码位置在 examples 里面的 detector.c line 138,和上面的一样,cd 到 darknet 文件夹下 make clean 删除之前的 make 文件,然后重新 make 即可。这样.data 文件就这么些内容。

**改动二 **
cfg 文件夹下的.cfg 文件,有很多,用到的只是 yolov3-voc.cfg(现在还不知道别的.cfg 文件该怎么用,求指点,于是我把别的文件全删除了,只留下 coco.data 和 yolov3-voc.cfg)一切正常,还没发现出错。删了 -- 改名,就这样了(改了名之后报错?就需要改动一处的指示了,回看改动一)
最重要的改动,是在 my_yolov3.cfg(已图片处的名字为例)下的参数,欲知详情,娓娓道来······
- my_yolov3.cfg 下参数改动:Training or Testing pattern?
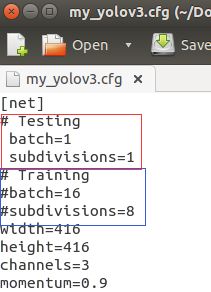
如图:
- batch:每次迭代要进行训练的图片数量
- subdivisions:batch 中的图片再产生子集,源码中的图片数量 int imgs = net.batch * net.subdivisions * ngpus (一次传入 batch 张图像,细分成 subdivisions 组行迭代训练,此时的 subdivisions=8,就会发现 train 时候,两次迭代输出之间,共输出了 8 次 Region 82,Region 94,Region 106。这里的 batch 是 16,即 8 组 2 个图像。你也可以设定 batch=64,此时的训练迭代就有 8 组 8 个图像了。)
- Training pattern:注释掉 Testing 下的 batch 和 subdivisions 两个初始参数,让 Training 下的 batch 和 subdivisions 两个初始参数参与运算;
- Testing pattern:反之,注释掉 Training 下的 batch 和 subdivisions 两个初始参数,让 Testing 下的 batch 和 subdivisions 两个初始参数参与运算。(上图就是在 test 下的参数模式,切记)
YOLOv3 预测 3 个不同尺度的 box
我们的系统使用类似的概念以金字塔网络(SPP)从这些量表中提取特征。最后一层网络预测一个 3D 张量编码的边界框,对象和类的预测(classes)。COCO 试验中,我们预测每个尺度上的 3 个盒子,所以这个张量是 NN3(4+1+80)的 4 个边界框偏移量,1 个目标预测,和 80 个类的预测。如果 classes=1,也就是上面的 my_yolov3.data,文件里面定义的,此时的最后一层 filters=3*(4+1+1)=18。
论文对最后一层网络的解释如下

第五步:Now we can train my target_yolo!
参考这个官方提示来做对应的修改,改为自己的命名形式,如果还是不行,恐怕就是你的 make 步骤没有做。make clean-- --make

- 红色框:cfg 文件夹下的.data 文件
- 绿色框:cfg 文件夹下的.cfg 文件
- 黄色框:darknet-53 的预训练参数作为整个 train 的初始参数
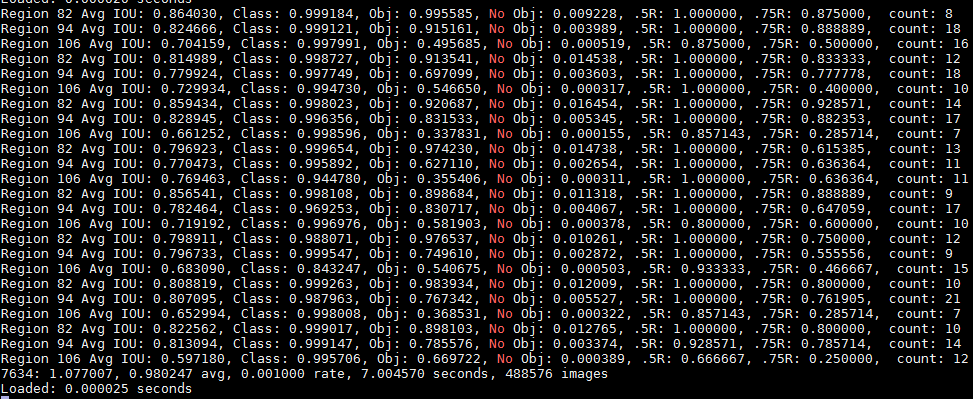 具体的输出详解
具体的输出详解 
Region Avg IOU: ----0.326577 is the average of the IOU of every image in the current subdivision. A 32,66% overlap in this case, this model still requires further training. Class: -----0.742537 still figuring this out Obj: -----0.033966 still figuring this out No Obj:----- 0.000793 still figuring this out The Avg Recall:------ 0.12500 is defined in code as recall/count, and thus a metric for how many positives YOLOv2 detected out of the total amount of positives in this subdivision. In this case only one of the eight positives was correctly detected. count: -----8 is the amount of positives (objects to be detected) present in the current subdivision of images (subdivision with size 8 in our case). Looking at the other lines in the log, you'll see there are also subdivision that only have 6 or 7 positives, indicating there are images in that subdivision that do not contain an object to be detected.
如果不幸,输出的是这个样子
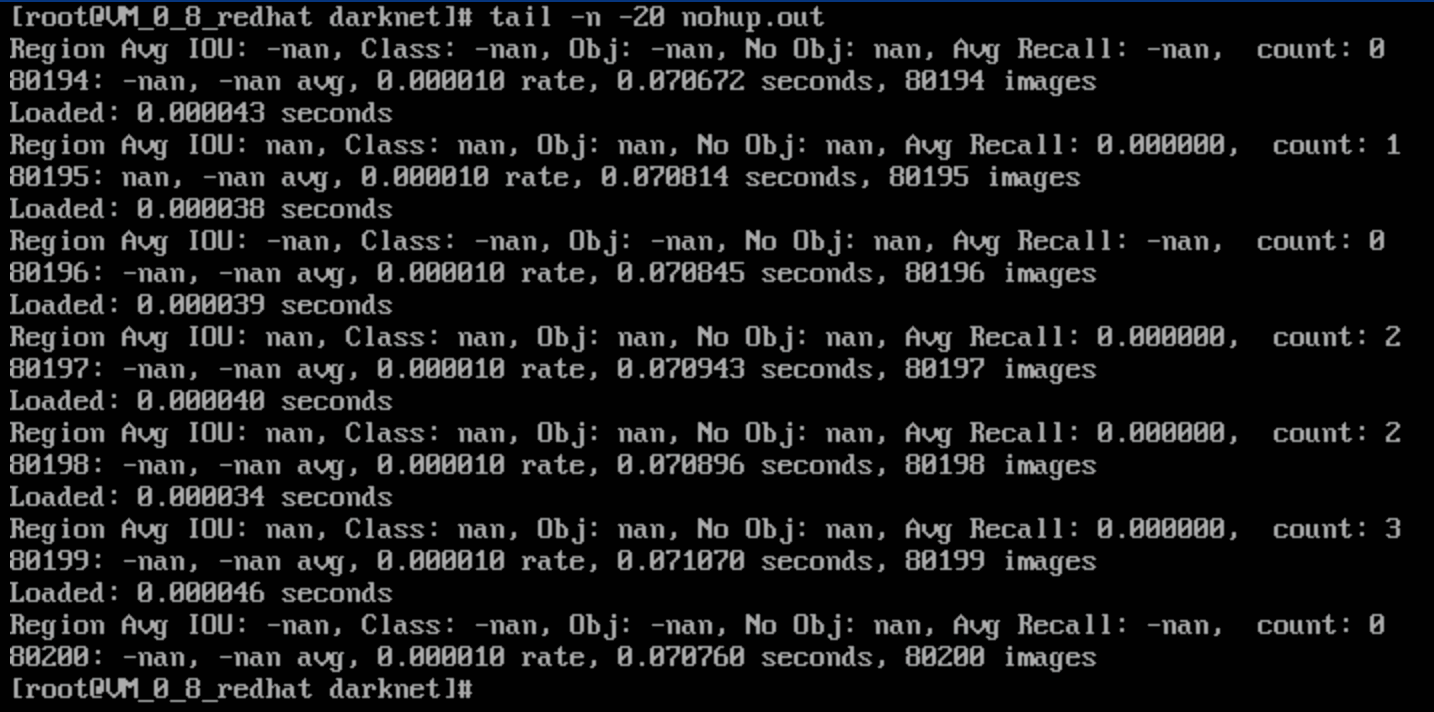
那就是你在 2.1.1 节时候,把 Training or Testing 注释错了,更改下,再试试。
如果成功了,那就出去溜溜等着吧,记得回来看看 loss 参数,迭代输出像这样
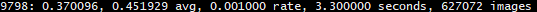
9798----- indicates the current training iteration/batch. 0.370096 -----is the total loss. 0.451929 ------avg is the average loss error, which should be as low as possible. As a rule of thumb, once this reaches below 0.060730 avg, you can stop training. 0.001000----- rate represents the current learning rate, as defined in the .cfg file. 3.300000 -----seconds represents the total time spent to process this batch. The 627072 -----images at the end of the line is nothing more than 9778 * 64, the total amount of images used during training so far.
序列测试,这里将 cfg/myyolov3.data 进行修改,加入 valid 的测试序列地址,重新 python voclabel.py

valid 测试
./darknet detector valid cfg/myyolov3.data cfg/myyolov3.cfg backup/yolo-voc_final.weights
/在终端只返回用时,在./results/comp4dettest_[类名].txt 里保存测试结果/
打开查看内容
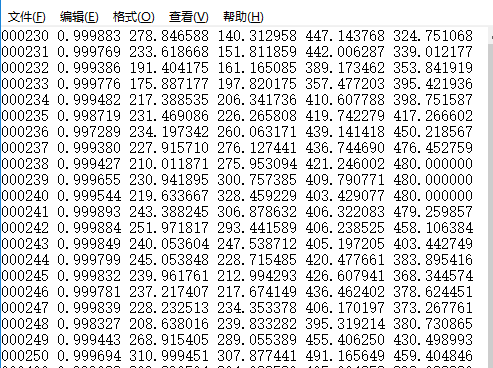
依次表示的是:文件名;每个框中存在该分类物体的概率;框框坐标 xmin;框框坐标 ymin;框框坐标 xmax;框框坐标 ymax,代码区如下截图,位置 examples/detector.c 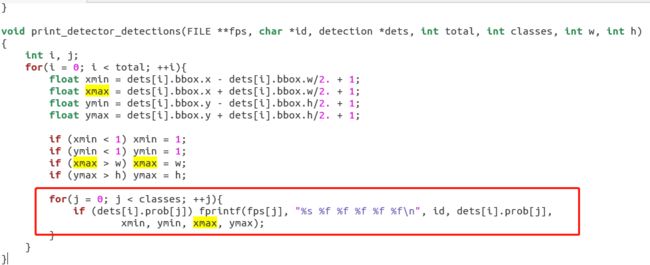
当然也有别的测试方式,并返回评价指标,如图,可自己尝试 
参考资料:
- https://timebutt.github.io/static/understanding-yolov2-training-output/
- https://www.zhihu.com/question/42205480
- https://blog.csdn.net/qq_30401249/article/details/51694298
转载:https://gitbook.cn/books/5aceab0afafeca4b1a33e7b4/index.html