
| 导读 | 本文主要介绍了Amazon Redshift新一代企业级云平台数据仓库服务,并结合实际的客户使用案例与场景描述了如何基于Amazon Redshift构建高可靠,性能优化,并且成本节约的数据仓库系统。 |
因为Amazon Redshift优异的计算效率与性能,基于Amazon Redshift的BI系统被广泛地应用于互联网数据分析类场景,例如电商中产品维度报表的计算生成,社交类应用中用户画像计算与分析,或者用于替代传统的数据仓库的解决方案。
Amazon Redshift是性能优异并且完全托管的PB级别数据仓库服务。Amazon Redshift提供了标准SQL数据库访问接口,并且可以十分方便地与现有的主流商业智能数据分析工具整合,构建企业级数据仓库。
Amazon Redshift高性能硬件架构
Amazon Redshift底层硬件是基于高度定制化的高性能硬件节点,整个集群是由头节点(leader node,又称领导节点)与计算节点(compute node)的架构组成,如图1所示。其中,头节点负责与所有的客户端程序(标准SQL兼容的客户端,或者通过JDBC/ODBC访问的客户端应用)进行通信,并把对应的SQL命令进行编译后分发给底层的计算节点。同时,头节点还负责存储所有的数据仓库元数据(metadata)。需要注意的是,所有的计算节点同时也是存储节点(单个节点最大支持2TB的存储量)。每个计算节点上配置有定制化的高性能CPU、内存及直接连接硬盘的存储介质。当用户数据仓库的数据量增加的时候,可以通过动态地增加计算节点的数目,以及升级对应计算节点的硬件配置提升集群的存储容量与计算能力。同时,节点与节点的通信是基于AWS定制化的高速内网带宽,减少了因为数据传输带来的时延,提高了计算效率。

图1 Amazon Redshift架构示意图
目前,Amazon Redshift主要支持两大类计算节点类型——DS1/DS2与DC1。其中DS类型节点是为大数据量的工作复杂优化而设计,而且DS2是DS1的硬件升级版本。DC1主要应用于数据计算要求相对更高但是数据总量相对较小的场景。
从应用的角度结合上述架构看,Amazon Redshift的头节点负责基本的SQL编译,查询计划的优化,以及数据仓库原数据的存储。所有的用户数据会以列式存储的方式存放与计算节点之上。因为大部分数据仓库的应用计算围绕于具体的属性列做查询筛选,所以列式存储的计算方式大大提高了数据仓库的计算效率。同时,以MPP的架构组织数据为例,Amazon Redshift也从表设计的角度为用户提供了数据在计算节点的存放方式,用户可以根据具体的SQL表中的键值做分布式存放,或者对某些常用维度表做所有计算节点的全分布存放,从而大大减少数据在节点之间的传输,以提高整体的计算效率。从图1还可以看到,计算节点以MPP的方式并行的从Amazon S3、Amazon DynamoDB、SSH及Amazon EMR并发的实现数据快速加载。另外,Amazon Redshift的整体设计实现了数据的多份冗余存放(对用户使用量透明)——计算节点之间冗余存放,同时定期对数据以增量快照的方式存放于高持久度的Amazon S3之上。
基于Amazon Redshift的BI大数据分析架构
Amazon Redshift针对数据仓库提供了优异的计算与存储效率,利用Amazon Redshift托管服务可以十分方便地构建智能数据仓库系统。同时,因为AWS云计算平台提供了一整套完整的数据分析套件与工具,利用这些组件与Amazon Redshift相结合,可以十分轻松地实现性能优化、成本经济、可靠性强、安全度高的大数据分析架构。图2为一个典型的数据分析平台的基础数据架构。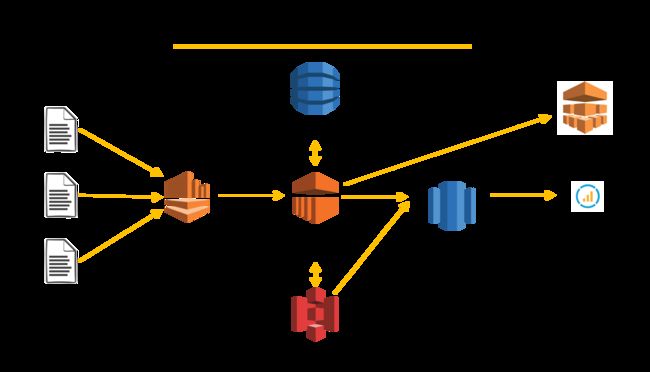
图2 基于AWS数据分析组件的数据架构
图2中的架构是基于AWS的典型的实时与批量叠加的大数据分析架构。其中Amazon Kinesis是托管的高速实时流分析服务,可以从前端的应用服务器(例如Web服务器)或者移动的客户端(手机等移动设备或者IoT设备)直接注入流式数据,数据可以通过EMR进行流式处理和计算(例如基于Spark Stream的EMR计算框架),并将数据存储于Amazon DynamoDB或者对象存储S3之上。其中,Amazon DynamoDB是托管的高性能NoSQL数据库,可以承载100TB数据量级别而响应时间低于10毫秒。S3作为高可靠(11个9的持久度)的对象存储,在大量的AWS应用场景中,被作为典型的数据湖(data lake)的应用。利用Amazon EMR对S3上的原始数据进行基本的ETL或者结构化操作之后,可以直接从S3以SQL的“copy”命令复制到Amazon Redshift数据仓库中进行SQL的维度计算。另外,可以利用AWS集成的BI分析工具(Quick Sight)或者已有的商业套件直接实现对Amazon Redshift上的数据进行分析与展示。
在实际的业务场景中,数据库的来源包含Amazon DynamoDB或者Amazon RDS这类业务数据库,以及用户活动日志或者行为日志等Web前端日志。这些数据需要以增量的方式汇聚于AWS S3及ETL之后进入到Amazon Redshift之中。常用的做法,可以利用AWS的Data Pipeline服务直接定义对应的原端数据源及对应的后端数据目标,自定义采集周期,一次性配置之后就可以直接进行数据通路的增量拷贝。
小红书电商基于Amazon Redshift的用户数据分析
小红书是新一代的社区电商,它将海外购物分享社区与跨境电商相结合,精准捕捉85后和90后的消费升级需求,迅速发展成为极具影响力的全球购物分享社区。目前小红书的注册用户数量已超过1800万,其中近90%是女性、超过50%是90后。作为新一代消费人群,这些用户有着共同的价值观,更注重感觉和体验,对优质商品和生活充满向往。“社区+电商”的模式推动了小红书的快速发展,在电商平台成立的半年内,其销售额就达到7亿人民币。
与小红书自身高速发展的业务模式一样,小红书的数据架构与数据分析团队也经历了从基本日志服务器脚本分析到目前利用Amazon Redshift作为数据仓库与数据分析核心工具的演化。图3是目前小红书数据分析的主要架构。
图3 小红书数据架构示意图
NoSQL DB(主要是MongoDB)小红书的业务数据库数据,其中的数据库业务日志通过Fluentd的流式客户端经过Amazon Kinesis的方式进入到AWS中国北京区域。之后,Amazon Kinesis的流式数据会写入S3作为整个原始数据存储。当然,Amazon S3还会作为数据湖汇聚其他的前段web服务器的日志,或者其他的数据来源。其中,构建于AmazonEMR的Spark集群对S3中的日志进行批量和实时的ETL。之后,结构化的数据从S3通过并行的拷贝直接进入Amazon Redshift进行数据分析师与工程师的业务分析。整个数据分析链条与分析架构实现了端到端的实时分析。其中,数据通路上的各个组件,Amazon Kinesis、Amazon S3、Amazon EMR与Amazon Redshift可以十分简单与方便地实现水平扩展以提高计算与处理能力。因为S3作为整个数据架构的数据湖,并且基于S3自身分布式无限制的容量大小的设计,小红书的架构系统可以十分方便的实现数据容量的夸张和升级。同时,因为EMR利用EMRFS实现了存储S3(类似于传统的Hadoop集群的HDFS)与计算(EMR计算实例)的分离,从而从架构上解决了数据系统ETL弹性与增长的需求。小红书又利用Amazon Kinesis来实时地解析同步用户行为日志,并开发了销售实时监控系统。使用AWS使小红书在两个方面获益匪浅:其一是大幅度缩短了数据处理系统上线的时间;其二是改变了整个公司的业务模式。目前,小红书数据团队正在持续优化其数据处理架构,包括提供更直观的展示平台、提升处理速度等,同时包括Spark在内的离线计算系统也开始投入使用。目前,业务数据的增量以每个月3~5TB的存量增加,并且随着业务增加还有快速递增的趋势。
原文来自:https://aws.amazon.com/cn/blogs/china/amazon-redshift-bi/
本文地址:http://www.linuxprobe.com/amazon-redshift-bi.html