aws的EMR搭建Hadoop集群
还是先极简介绍一下EMR是什么,Amazon EMR 基于 Hadoop 的开源框架将您的数据分布在可重新调整大小的 Amazon EC2 实例集群中并进行处理。Amazon EMR 可用于各种应用程序中,包括日志分析、Web 索引、数据仓库、机器学习、财务分析、科学模拟和生物信息学。具体的功能特性可以直接到官网查阅。直接上实验:
实验包括:
1. 使用EMR创建Hadoop集群
2. 定义schema,创建示例表。
3. 通过HiveQL分析数据,并将分析结果保存到S3上
4. 下载已经分析结果数据。
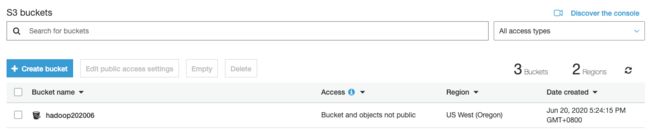
Task1:创建一个S3 桶
创建一个存储桶比如hadoop202006…
Task2:创建EMR集群
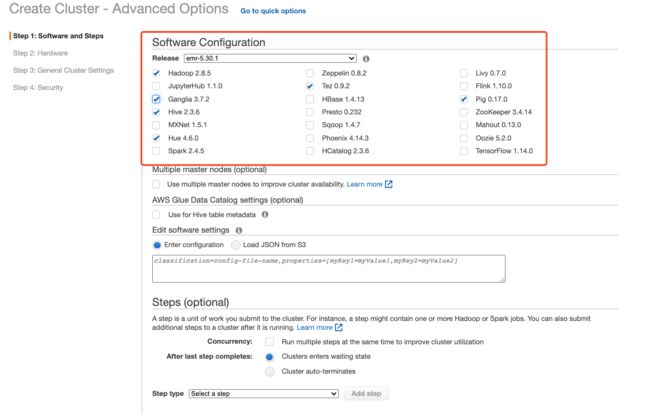
这里我解释一下Hadoop集群中的一些组件,了解大数据的同学直接忽略就好。
Apache Hadoop:在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。
Ganglia:分布式监控系统
Apache Tez:支持 DAG 作业的开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升DAG作业的性能。比如Hive或Pig可以将Tez作为执行引擎。
Hive:可以通过类似SQL语句实现快速MapReduce统计
Hue:通过使用Hue我们可以通过浏览器方式操纵Hadoop集群。例如put、get、执行MapReduce Job等等。
Pig:它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。Pig为复杂的海量数据并行计算提供了一个简单的操作和编程接口。
解释一下,Master、Core、Task。
Master Node:主节点集群管理,通常运行分布式应用程序的Master组件,例如,YARN ResourceManager,HDFS NameNode。
Core Node:会运行 HDFS的 DataNode, 运行YARN守护程序,MR任务等。
Task Node:任务节点是可选的,做为可扩展的算力。不运行HDFS的DataNode守护程序,不做HDFS的存储。
MasterNode至少有一个
CoreNode 至少一个
TaskNode 可以有一个(可选)
1.
2.
3.
当Cluster状态为Waiting时,执行Task3.
Task3:使用Hive脚本处理数据
在处理数据之前肯定要明确两件事情:
处理什么数据
如何处理数据
处理什么数据:
这里以CDN的log日志为例,其中一条数据的格式为:
2017-07-05 20:05:47 SEA4 4261 10.0.0.15 GET eabcd12345678.cloudfront.net /test-image-2.jpeg 200 - Mozilla/5.0%20(MacOS;%20U;%20Windows%20NT%205.1;%20en-US;%20rv:1.9.0.9)%20Gecko/2009040821%20Chrome/3.0.9
解释如下:
如何处理数据
在EMR集群中,添加STEP,
Step类型选择:Hive progran。
多说一句:目前有4中Task类型,自定义JAR,Streaming program来处理流数据,Hive/Pig执行类SQL。
Name:Process logs
Script S3 location:s3://us-west-2.elasticmapreduce.samples/cloudfront/code/Hive_CloudFront.q
(一会儿分析一个这个脚本都执行了什么)
Input S3 location: s3://us-west-2.elasticmapreduce.samples(这个就是CDN的log日志)
Output S3 Location:选择我创建的hadoop202006(这个就是我们处理后的文件存放的位置)
Arguments:-hiveconf hive.support.sql11.reserved.keywords=false
如下图:
脚本都干了啥?(你可以SSH到Cluster上直接执行HiveQL)
创建一个叫cloudfront_logs的Hive table
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs (DateObject Date,Time STRING,Location STRING,Bytes INT,RequestIP STRING,Method STRING,Host STRING,Uri STRING,Status INT,Referrer STRING,OS String,Browser String,BrowserVersion String)
对log的格式进行序列化/反序列化 RegEx SerDe 并写入CDN的log数据到Hive表中
ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.RegexSerDe’WITH SERDEPROPERTIES ( “input.regex” = "(?!#)([ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+([^ ]+)\s+[(]+[(]( https://s3-us-west-2.amazonaws.com/us-west-2-aws-training/awsu-spl/spl-166/1.0.7.prod/instructions/en_us/[^;]+).*%20([/]+) /") LOCATION '")LOCATION
′
{INPUT}/cloudfront/data/’;
查询日中Client端使用的OS数量by日期并把查询结果写入S3
INSERT OVERWRITE DIRECTORY '${OUTPUT}/os_requests/'SELECT os, COUNT(*) countFROM cloudfront_logsWHERE dateobjectBETWEEN ‘2014-07-05’ AND '2014-08-05’GROUP BY os;
Task4:收获果实:
Done!
-----------------------------------
©著作权归作者所有:来自51CTO博客作者栗子哥的原创作品,如需转载,请与作者联系,否则将追究法律责任
【AWS征文】[大数据][Hadoop] 使用EMR做大数据分析
https://blog.51cto.com/u_13746986/2531865