浅学了波ZooKeeper,我来做个总结
文章目录
- 集群操作
-
- 启动
- 停止
- 查看状态
- 客户端命令行操作
-
- 命令行语法
- znode 节点数据信息
- 节点类型(持久/短暂/有序号/无序号)
- 节点删除与状态
- 监听器
- 面试重点
-
- 选举机制
-
- 第一次启动(初始化)
- 非第一次启动
- 总结
- 生产集群安装多少 zk 合适?
- 常用命令
集群操作
集群的命令都在zookeeper的bin目录下
[mq@hadoop102 bin]$ pwd
/opt/module/zookeeper-3.5.7/bin
[mq@hadoop102 bin]$ ll
总用量 56
-rwxr-xr-x. 1 mq mq 232 5月 4 2018 README.txt
-rwxr-xr-x. 1 mq mq 2067 2月 7 2020 zkCleanup.sh
-rwxr-xr-x. 1 mq mq 1158 2月 10 2020 zkCli.cmd
-rwxr-xr-x. 1 mq mq 1621 2月 7 2020 zkCli.sh
-rwxr-xr-x. 1 mq mq 1766 2月 7 2020 zkEnv.cmd
-rwxr-xr-x. 1 mq mq 3690 1月 31 2020 zkEnv.sh
-rwxr-xr-x. 1 mq mq 1286 1月 31 2020 zkServer.cmd
-rwxr-xr-x. 1 mq mq 4573 2月 7 2020 zkServer-initialize.sh
-rwxr-xr-x. 1 mq mq 9386 2月 7 2020 zkServer.sh
-rwxr-xr-x. 1 mq mq 996 10月 3 2019 zkTxnLogToolkit.cmd
-rwxr-xr-x. 1 mq mq 1385 2月 7 2020 zkTxnLogToolkit.sh
所以想要开、关、看集群,不仅要输入命令,还要输入命令的路径:
启动
/opt/module/zookeeper-3.5.7/bin/zkServer.sh start
停止
/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop
查看状态
/opt/module/zookeeper-3.5.7/bin/zkServer.sh status
如果要开多台服务器每次就要输入很多命令,要累死,所以就要编写shell脚本简化操作
[mq@hadoop103 bin]$ vim zk.sh
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103 hadoop104
do
echo ------------- zookeeper $i 启动 -------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start"
done
}
;;
"stop"){
for i in hadoop102 hadoop103 hadoop104
do
echo ------------- zookeeper $i 停止 -------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"
done
}
;;
"status"){
for i in hadoop102 hadoop103 hadoop104
do
echo ------------- zookeeper $i 状态 -------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status"
done
}
;;
esac
写完别忘了更改权限
[mq@hadoop103 bin]$ chmod 777 zk.sh
我把它放在了用户的bin目录下
[mq@hadoop103 bin]$ pwd
/home/mq/bin
这样随处都可执行集群命令
启动
zk.sh start
[mq@hadoop102 bin]$ zk.sh start
------------- zookeeper hadoop102 启动 -------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/…/conf/zoo.cfg
Starting zookeeper … STARTED
------------- zookeeper hadoop103 启动 -------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/…/conf/zoo.cfg
Starting zookeeper … STARTED
------------- zookeeper hadoop104 启动 -------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/…/conf/zoo.cfg
Starting zookeeper … STARTED
停止
zk.sh stop
[mq@hadoop102 bin]$ zk.sh stop
------------- zookeeper hadoop102 停止 -------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/…/conf/zoo.cfg
Stopping zookeeper … STOPPED
------------- zookeeper hadoop103 停止 -------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/…/conf/zoo.cfg
Stopping zookeeper … STOPPED
------------- zookeeper hadoop104 停止 -------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/…/conf/zoo.cfg
Stopping zookeeper … STOPPED
查看状态
zk.sh status
[mq@hadoop102 bin]$ zk.sh status
------------- zookeeper hadoop102 状态 -------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/…/conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
------------- zookeeper hadoop103 状态 -------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/…/conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: leader
------------- zookeeper hadoop104 状态 -------------
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/…/conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
客户端命令行操作
命令行语法
| 命令基本语法 | 功能描述 |
|---|---|
| help | 显示所有操作命令 |
| ls | 使用 ls 命令来查看当前 znode 的子节点(可监听的节点) -w 监听子节点变化 -s 附加次级信息 |
| create | 普通创建 -s 含有序列 -e 临时(重启或者超时消失) |
| get | 获得节点的值 (可监听的节点) -w 监听节点内容变化 -s 附加次级信息 |
| set | 设置节点的具体值 |
| stat | 查看节点状态 |
| delete | 删除节点 |
| deleteall | 递归删除节点 |
(1)启动客户端(启动集群的前提下)
[mq@hadoop104 bin]$ /opt/module/zookeeper-3.5.7/bin/zkCli.sh
注意:这个不用 start
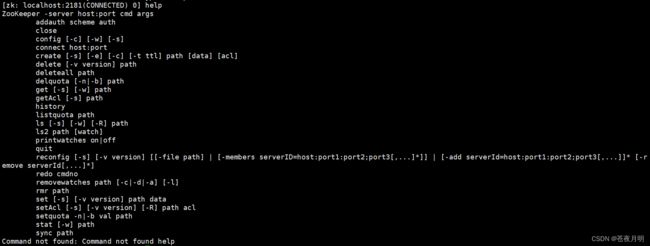
(2)显示所有操作命令
[zk: localhost:2181(CONNECTED) 0] help
znode 节点数据信息
(1)查看当前znode中所包含的内容
[zk: localhost:2181(CONNECTED) 1] ls /
[servers, zookeeper]
(2)查看当前节点详细数据
[zk: localhost:2181(CONNECTED) 2] ls -s /
[servers, zookeeper]cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x70000000b
cversion = 16
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 2
节点类型(持久/短暂/有序号/无序号)
-
持久(persistent):客户端和服务器端断开连接后,创建的节点不删除。默认不写参数是持久的
-
短暂(ephemeral):客户端和服务器端断开连接后,创建的节点自动删除
-
无序列:节点默认没有顺序编号
-
有序列(sequence):节点后面跟着顺序编号
节点种类(排列组合那四种):
-
持久化目录节点(永久节点 + 不带序号):
客户端与Zookeeper断开连接后,该节点依旧存在。 -
持久化顺序编号目录节点(永久节点 + 带序号):
客户端与Zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号。 -
临时目录节点(短暂节点 + 不带序号):
客户端与Zookeeper断开连接后,该节点被删除。 -
临时顺序编号目录节点(短暂节点 + 带序号):
客户端与 Zookeeper 断开连接后 , 该 节 点 被 删 除 , 只 是 Zookeeper给该节点名称进行顺序编号。
(1)分别创建2个普通节点(永久节点 + 不带序号)
[zk: localhost:2181(CONNECTED) 3] create /sanguo “diaochan”
Created /sanguo
[zk: localhost:2181(CONNECTED) 4] create /sanguo/shuguo “liubei”
Created /sanguo/shuguo
注意:创建节点时,要赋值
(2)获得节点的值
[zk: localhost:2181(CONNECTED) 12] get /sanguo
diaochan
[zk: localhost:2181(CONNECTED) 11] get -s /sanguo
diaochan
cZxid = 0xa00000002
ctime = Sun Jul 24 11:34:54 CST 2022
mZxid = 0xa00000002
mtime = Sun Jul 24 11:34:54 CST 2022
pZxid = 0xa00000005
cversion = 3
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 8
numChildren = 1
[zk: localhost:2181(CONNECTED) 13] get -s /sanguo/shuguo
liubei
cZxid = 0xa00000005
ctime = Sun Jul 24 11:37:33 CST 2022
mZxid = 0xa00000005
mtime = Sun Jul 24 11:37:33 CST 2022
pZxid = 0xa00000005
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 6
numChildren = 0
(3)创建带序号的节点(永久节点 + 带序号)
先创建一个普通的根节点/sanguo/weiguo
[zk: localhost:2181(CONNECTED) 14] create /sanguo/weiguo “caocao”
Created /sanguo/weiguo
创建带序号的节点
[zk: localhost:2181(CONNECTED) 15] create -s /sanguo/weiguo/zhangliao “zhangliao”
Created /sanguo/weiguo/zhangliao0000000000
[zk: localhost:2181(CONNECTED) 16] create -s /sanguo/weiguo/zhangliao “zhangliao”
Created /sanguo/weiguo/zhangliao0000000001
[zk: localhost:2181(CONNECTED) 17] create -s /sanguo/weiguo/xuchu “xuchu”
Created /sanguo/weiguo/xuchu0000000002
序号从 0 开始依次递增
(4)创建短暂节点(短暂节点 + 不带序号 or 带序号)
1.创建短暂的不带序号的节点
[zk: localhost:2181(CONNECTED) 18] create -e /sanguo/wuguo “zhouyu”
Created /sanguo/wuguo
2.创建短暂的带序号的节点
[zk: localhost:2181(CONNECTED) 19] create -e -s /sanguo/wuguo “zhouyu”
Created /sanguo/wuguo0000000004
在当前客户端是能查看到的
[zk: localhost:2181(CONNECTED) 20] ls /sanguo
[shuguo, weiguo, wuguo, wuguo0000000004]
退出当前客户端然后再重启客户端
[zk: localhost:2181(CONNECTED) 21] quit
[mq@hadoop102 ~]$ /opt/module/zookeeper-3.5.7/bin/zkCli.sh
再次查看根目录下短暂节点已经删除
[zk: localhost:2181(CONNECTED) 0] ls /sanguo
[shuguo, weiguo]
(5)修改节点数据值
[zk: localhost:2181(CONNECTED) 3] set /sanguo/weiguo “simayi”
节点删除与状态
(1)删除节点
[zk: localhost:2181(CONNECTED) 9] ls /sanguo/weiguo
[xuchu0000000002, zhangliao0000000000, zhangliao0000000001]
删除 xuchu0000000002:
[zk: localhost:2181(CONNECTED) 13] delete /sanguo/weiguo/xuchu0000000002
[zk: localhost:2181(CONNECTED) 14] ls /sanguo/weiguo
[zhangliao0000000000, zhangliao0000000001]
(2)递归删除节点
如果想删除 /weiguo,不能直接 delete /sanguo/weiguo:
[zk: localhost:2181(CONNECTED) 7] delete /sanguo/weiguo
Node not empty: /sanguo/weiguo
这时候就要递归删除了:
[zk: localhost:2181(CONNECTED) 16] deleteall /sanguo/weiguo
[zk: localhost:2181(CONNECTED) 18] ls /sanguo/weiguo
Node does not exist: /sanguo/weiguo
(3)查看节点状态
[zk: localhost:2181(CONNECTED) 19] stat /sanguo
cZxid = 0xa00000002
ctime = Sun Jul 24 11:34:54 CST 2022
mZxid = 0xa00000002
mtime = Sun Jul 24 11:34:54 CST 2022
pZxid = 0xa00000013
cversion = 9
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 8
numChildren = 1
监听器
一、节点的值变化监听
(1)在 hadoop104 主机上注册监听 /sanguo 节点数据变化
[zk: localhost:2181(CONNECTED) 0] get -w /sanguo
diaochan
(2)在 hadoop103 主机上修改 /sanguo 节点的数据
[zk: localhost:2181(CONNECTED) 2] set /sanguo “xishi”
(3)观察 hadoop104 主机收到数据变化的监听
[zk: localhost:2181(CONNECTED) 1]
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged path:/sanguo
注意:在hadoop103上再次/多次修改 /sanguo 的值,hadoop104上不会再收到监听。因为注册
一次,只能监听一次。想再次监听,需要再次注册。
二、节点的子节点变化监听(路径变化)
(1)在 hadoop104 主机上注册监听 /sanguo 节点的子节点变化
[zk: localhost:2181(CONNECTED) 1] ls -w /sanguo
[shuguo]
(2)在 hadoop103 主机 /sanguo 节点上创建子节点
[zk: localhost:2181(CONNECTED) 3] create /sanguo/jin “simayi”
Created /sanguo/jin
(3)观察 hadoop104 主机收到子节点变化的监听
[zk: localhost:2181(CONNECTED) 2]
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/sanguo
注意:节点的路径变化,也是注册一次,生效一次。想多次生效,就需要多次注册。
面试重点
选举机制
当ZooKeeper集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举:
-
服务器初始化启动 —— 第一次
-
服务器运行期间无法和 Leader 保持连接 —— 第二次及以后
需要知道的三个概念:
-
SID:服务器ID。用来
唯一标识一台ZooKeeper集群中的机器,每台机器不能重复,和myid一致。每台服务器的编号,类似于身份证。 -
ZXID:事务ID,用来标识一次服务器状态的变更。在某一时刻,集群中的每台机器的ZXID值不一定完全一致,这和ZooKeeper服务器对于客户端“更新请求”的处理逻辑有关。
-
Epoch:每个Leader任期的代号。没有Leader时同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加
第一次启动(初始化)
服务器刚启动时,第一次选 leader 怎么选。
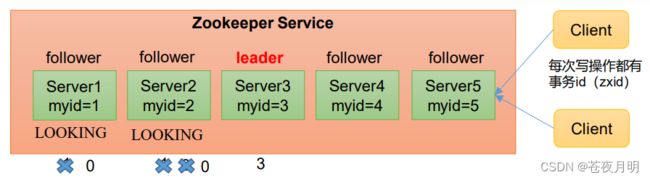
(1)服务器1启动,发起一次选举。服务器1投自己一票(每个服务器在启动时,都会先给自己一票)。此时服务器1票数为一票,不够半数以上(3票),选举无法完成,服务器1状态保持为Looking。
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1)大,(服务器判断自己的myid和传过来选票的myid两者谁大),更改选票为推举服务器2(自动把选票投给大的myid)。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持Looking。
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为Following,服务器3更改状态为Leading。
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是Looking状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为Following。
(5)服务器5启动,同4一样当小弟(Follower)。
选举Leader规则: 投票过半数时,服务器 id 大的胜出
非第一次启动
zookeeper集群正常启动后如果发生了意外,第一次(开服时)选择的 leader 突然挂了,集群中不存在Leader,二次选举甚至n次选举又是如何选择leader的。
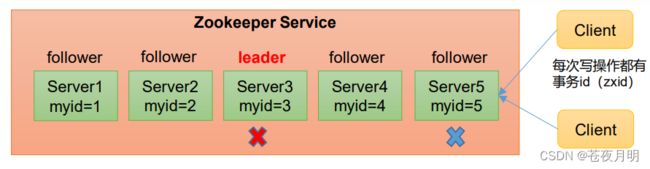
假设ZooKeeper由5台服务器组成,SID(服务器id)分别为1、2、3、4、5,ZXID(事务id)分别为8、8、8、7、7,并且此时SID为3的服务器是Leader。某一时刻,3和5服务器出现故障,因此开始进行Leader选举。
SID为1、2、4的机器投票情况: (1,8,1) (1,8,2) (1,7,4)
(EPOCH,ZXID,SID )
PS:开启的服务器数量超过集群总服务器数量的一半时,集群就能正常工作
选举Leader规则:
①EPOCH大的直接胜出
②EPOCH相同,事务id(ZXID)大的胜出
③事务id相同,服务器id(SID)大的胜出
总结
半数机制:超过半数的投票通过,即通过。
(1)第一次启动选举规则:
投票过半数时,服务器 id 大的胜出
(2)第二次及以后启动选举规则:
① Epoch 大的直接胜出
② Epoch 相同,事务 id 大的胜出
③ 事务 id 相同,服务器 id 大的胜出
生产集群安装多少 zk 合适?
安装奇数台。
生产经验:
-
10 台服务器:3 台 zk
-
20 台服务器:5 台 zk
-
100 台服务器:11 台 zk
-
200 台服务器:11 台 zk
服务器台数多
好处:提高可靠性;坏处:增加通信延时
常用命令
ls、get、create、delete
上面具体写了