从RNN到Attention到Transformer系列-Attention介绍及代码实现
深度学习知识点总结
专栏链接:
深度学习知识点总结_Mr.小梅的博客-CSDN博客本专栏主要总结深度学习中的知识点,从各大数据集比赛开始,介绍历年冠军算法;同时总结深度学习中重要的知识点,包括损失函数、优化器、各种经典算法、各种算法的优化策略Bag of Freebies (BoF)等。
本章介绍从RNN到Attention到Transformer系列-Attention介绍及代码实现。
目录
3.4 Attention介绍
3.4.1 Encode
3.4.2 Attention
3.4.3 Encode
3.4.4 Seq2Seq
3.4.5 全部代码下载链接
3.4 Attention介绍
参考论文《Neural Machine Translation by Jointly Learning to Align and Translate》。
在之前的模型中,架构的设置方式是通过显式传递上下文向量z来减少“信息压缩”,在每个时间步长通过传递上下文向量和输入词的嵌入向量d(yt)以及隐藏层状态st到解码器,经过线性层f,得到预测结果。具体如下:
即使我们已经减少了一些压缩,但我们的上下文向量仍然需要包含有关源句子的所有信息。这次文章中实现的模型通过允许解码器在每个解码步骤中查看整个源句子(通过其隐藏状态)来避免这种压缩!它是如何做到这一点的呢?这就是Attention!
Attention运行的第一步,就是计算一个attention向量a,这是一个输入句子长度的向量。a取值在0-1之间,相加为1。我们计算源句隐藏状态的加权和H,得到加权源向量w。
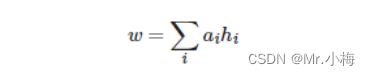
我们在解码时每个时间步长都会计算一个新的加权源矢量,将其用作解码器RNN的输入以及线性层以进行预测。我们将在教程中说明如何执行所有这些操作。
3.4.1 Encode
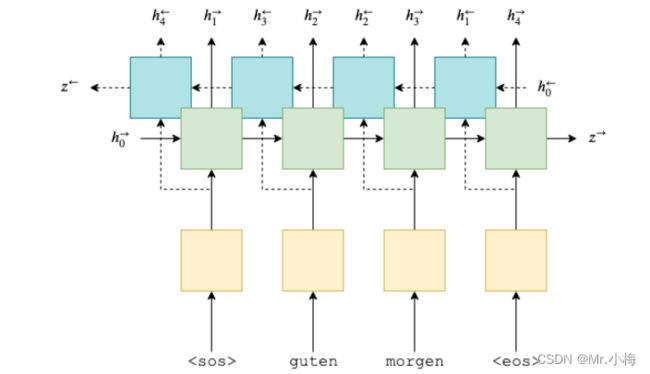
首先,我们将构建编码器。与以前的模型类似,但现在我们使用双向 GRU。使用双向 GRU时,我们每层都有两个GRU。一个前向的 GRU从左到右遍历嵌入的句子(下面以绿色显示),一个后向的 RNN 从右到左遍历嵌入的句子(蓝绿色)。我们需要在代码中做的就是设置bidirectional = True,然后像以前一样将编码好的句子向量传递给RNN。
现在有:
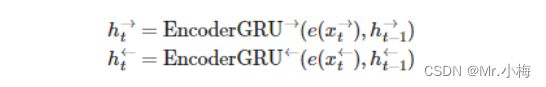
![]()
和之前一样,使用0初始化RNN前向和后向隐藏层状态![]() 和
和![]() ,仅用输入编码过的向量,然后得到两个上下文向量,一个前向的
,仅用输入编码过的向量,然后得到两个上下文向量,一个前向的![]() ,一个反向的
,一个反向的![]() ,RNN输出outputs和hidden,outputs的维度是[src len, batch size, hid dim * num directions],第三维度的hid dim是隐藏层状态前向和后向的整合,即
,RNN输出outputs和hidden,outputs的维度是[src len, batch size, hid dim * num directions],第三维度的hid dim是隐藏层状态前向和后向的整合,即![]() ,
,![]() ,整合为
,整合为![]() 。
。
Hidden的维度是[n layers * num directions, batch size, hid dim]。
由于解码器不是双向的,因此只需要一个上下文向量z,使用编码器输出的隐藏层状态初始化解码器的隐藏层状态s0,有两个,一个前向的一个后向![]() 和
和![]() ,我们通过将两个上下文向量连接在一起,将它们传递到一个线性层来解决这个问题,然后使用一个线性层g,再使用tanh作为激活函数:
,我们通过将两个上下文向量连接在一起,将它们传递到一个线性层来解决这个问题,然后使用一个线性层g,再使用tanh作为激活函数:
![]()
注意:这实际上与论文有所偏差。论文中它们仅通过线性层馈送第一个向后RNN隐藏状态,以获得上下文矢量/解码器初始隐藏状态。这对我来说似乎没有意义,所以我们改变了它。
由于我们希望我们的模型回顾我们返回的整个源句子,因此源句子中每个令牌的堆叠向前和向后隐藏状态。我们还返回 ,它充当解码器中的初始隐藏状态。
使用PyTorch实现代码如下:
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout):
super().__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.GRU(emb_dim, enc_hid_dim, bidirectional=True)
self.fc = nn.Linear(enc_hid_dim * 2, dec_hid_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
# src = [src len, batch size]
embedded = self.dropout(self.embedding(src))
# embedded = [src len, batch size, emb dim]
outputs, hidden = self.rnn(embedded)
# outputs = [src len, batch size, hid dim * num directions]
# hidden = [n layers * num directions, batch size, hid dim]
# hidden is stacked [forward_1, backward_1, forward_2, backward_2, ...]
# outputs are always from the last layer
# hidden [-2, :, : ] is the last of the forwards RNN
# hidden [-1, :, : ] is the last of the backwards RNN
# initial decoder hidden is final hidden state of the forwards and backwards
# encoder RNNs fed through a linear layer
# 通过线性层转和tanh,使用前向和后向隐藏层状态,将两个特征融合使用
hidden = torch.tanh(self.fc(torch.cat((hidden[-2, :, :], hidden[-1, :, :]), dim=1)))
# outputs = [src len, batch size, enc hid dim * 2]
# hidden = [batch size, dec hid dim]
return outputs, hidden3.4.2 Attention
接下来是注意力层。这将采用解码器以前的隐藏状态st-1,以及编码器中所有堆叠的向前和向后隐藏状态H,输出一个attention向量at,数值在0-1之间,相加和为1.
首先,我们计算先前解码器隐藏状态和编码器隐藏状态之间的energy 。由于我们的编码器隐藏状态维度是一个sequence 的,长度为T的,而解码器的上一个隐藏层状态是1个tensor,第一件事是重复之前解码器隐藏层状态T次。 然后计算energy Et,使用线性层attention将他们连接在一起:

这可以被认为是计算每个编码器隐藏状态与先前解码器隐藏状态“匹配”的程度。
每个batch中每个example的Et维度是 [dec hid dim, src len],我们希望批处理中的每个示例都是 [src len],因为注意力应该放在源句子的长度上。这是通过将乘以 v=[1, dec hid dim] 张量来实现的:
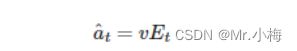
我们把v当为所有编码器隐藏状态的能量加权总和的权重。这些权重告诉我们应该关注源序列中的每个令牌的程度。参数v是随机初始化的,但通过反向传播与模型的其余部分一起学习。注意如何v不依赖于时间,并且相同v用于解码的每个时间步长。我们实施v作为没有偏差的线性层。
最后,我们确保注意力向量符合使所有元素在 0 和 1 之间以及向量求和为 1 的约束,方法是通过softmax层:
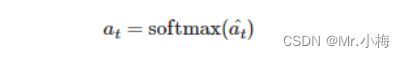
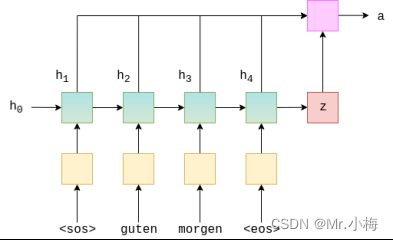
从图形上看,这看起来像下面这样。这是为了计算第一个注意力向量,其中st−1=0=z.绿色/蓝绿色块表示来自前向和向后RNN的隐藏状态,注意力计算全部在粉红色块内完成。
使用PyTorch实现代码如下:
class Attention(nn.Module):
def __init__(self, enc_hid_dim, dec_hid_dim):
super().__init__()
self.attn = nn.Linear((enc_hid_dim * 2) + dec_hid_dim, dec_hid_dim)
self.v = nn.Linear(dec_hid_dim, 1, bias=False)
def forward(self, hidden, encoder_outputs):
# hidden = [batch size, dec hid dim]
# encoder_outputs = [src len, batch size, enc hid dim * 2]
batch_size = encoder_outputs.shape[1]
src_len = encoder_outputs.shape[0]
# repeat decoder hidden state src_len times
hidden = hidden.unsqueeze(1).repeat(1, src_len, 1)
encoder_outputs = encoder_outputs.permute(1, 0, 2)
# hidden = [batch size, src len, dec hid dim]
# encoder_outputs = [batch size, src len, enc hid dim * 2]
energy = torch.tanh(self.attn(torch.cat((hidden, encoder_outputs), dim=2)))
# energy = [batch size, src len, dec hid dim]
attention = self.v(energy).squeeze(2)
# attention= [batch size, src len]
return F.softmax(attention, dim=1)3.4.3 Encode
解码器包含注意力层,该层采用先前的隐藏状态attentin st-1,和所有编码器的隐藏状态H,并返回attention向量at。然后,我们使用此注意力向量来创建加权源向量wt,代表编码器隐藏状态H的加权和,at是权重:
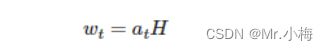
嵌入的输入字,d(yt) ,加权源向量wt和之前的解码器隐藏状态st−1 然后,全部传递到解码器 RNN 中,计算隐藏状态:
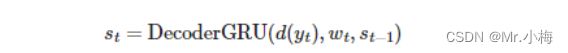
然后使用d(yt),wt和st通过线性层f,以预测目标句子中的下一个单词,y^t+1.这是通过将它们连接在一起来完成的。
![]()
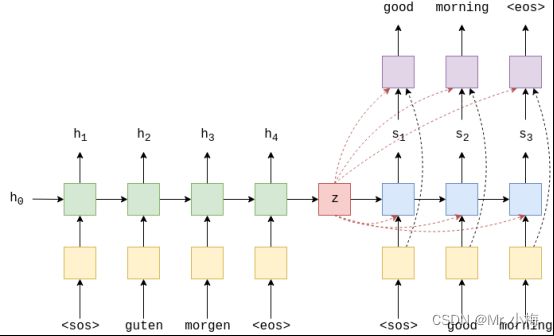
下图显示了对示例翻译中第一个单词的解码:
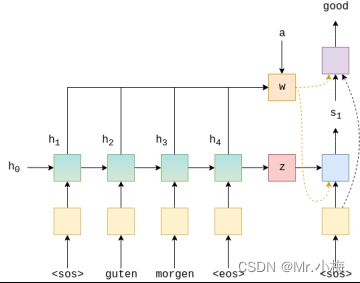
绿色/蓝绿色块显示输出的正向/反向编码器RNN,编码器RNN输出H,红色的方格代表上下文向量。
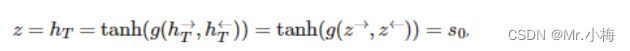
蓝色块代表解码器RNN和输出的st,紫色块代表线性层f,输出y^t+1,橙色块表示H用过at加权后的输出wt。
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, enc_hid_dim, dec_hid_dim, dropout, attention):
super().__init__()
self.output_dim = output_dim
self.attention = attention
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.GRU((enc_hid_dim * 2) + emb_dim, dec_hid_dim)
self.fc_out = nn.Linear((enc_hid_dim * 2) + dec_hid_dim + emb_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, encoder_outputs):
# input = [batch size]
# hidden = [batch size, dec hid dim]
# encoder_outputs = [src len, batch size, enc hid dim * 2]
input = input.unsqueeze(0)
# input = [1, batch size]
embedded = self.dropout(self.embedding(input))
# embedded = [1, batch size, emb dim]
a = self.attention(hidden, encoder_outputs)
# a = [batch size, src len]
a = a.unsqueeze(1)
# a = [batch size, 1, src len]
encoder_outputs = encoder_outputs.permute(1, 0, 2)
# encoder_outputs = [batch size, src len, enc hid dim * 2]
weighted = torch.bmm(a, encoder_outputs)
# weighted = [batch size, 1, enc hid dim * 2]
weighted = weighted.permute(1, 0, 2)
# weighted = [1, batch size, enc hid dim * 2]
rnn_input = torch.cat((embedded, weighted), dim=2)
# rnn_input = [1, batch size, (enc hid dim * 2) + emb dim]
output, hidden = self.rnn(rnn_input, hidden.unsqueeze(0))
# output = [seq len, batch size, dec hid dim * n directions]
# hidden = [n layers * n directions, batch size, dec hid dim]
# seq len, n layers and n directions will always be 1 in this decoder, therefore:
# output = [1, batch size, dec hid dim]
# hidden = [1, batch size, dec hid dim]
# this also means that output == hidden
assert (output == hidden).all()
embedded = embedded.squeeze(0)
output = output.squeeze(0)
weighted = weighted.squeeze(0)
prediction = self.fc_out(torch.cat((output, weighted, embedded), dim=1))
# prediction = [batch size, output dim]
return prediction, hidden.squeeze(0)
3.4.4 Seq2Seq
简要介绍一下所有步骤:
-
创建张量以保存所有的预测结果Y^
-
输入原始序列X到编码器,得到z和H
-
初始化解码器隐藏层状态使用上下文向量,s0=z=hT
-
使用一个batch的
token作为解码器的第一个输入y1 -
然后在一个循环中完成解码:
-
插入输入token yt、上一次的隐藏层状态st-1和所有的编码器输出H到解码器
-
得到预测结果y^t+1和新的隐藏层状态st
-
然后,决定是否要强制教师模式,并根据需要决定下一个输入token
-
使用PyTorch实现代码如下:
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio=0.5):
# src = [src len, batch size]
# trg = [trg len, batch size]
# teacher_forcing_ratio is probability to use teacher forcing
# e.g. if teacher_forcing_ratio is 0.75 we use teacher forcing 75% of the time
batch_size = src.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim
# tensor to store decoder outputs
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
# encoder_outputs is all hidden states of the input sequence, back and forwards
# hidden is the final forward and backward hidden states, passed through a linear layer
encoder_outputs, hidden = self.encoder(src)
# first input to the decoder is the tokens
input = trg[0, :]
for t in range(1, trg_len):
# insert input token embedding, previous hidden state and all encoder hidden states
# receive output tensor (predictions) and new hidden state
output, hidden = self.decoder(input, hidden, encoder_outputs)
# place predictions in a tensor holding predictions for each token
outputs[t] = output
# decide if we are going to use teacher forcing or not
teacher_force = random.random() < teacher_forcing_ratio
# get the highest predicted token from our predictions
top1 = output.argmax(1)
# if teacher forcing, use actual next token as next input
# if not, use predicted token
input = trg[t] if teacher_force else top1
return outputs 3.4.5 全部代码下载链接
见下载链接
从RNN到Attention到Transformer系列-Attention介绍及代码实现-深度学习文档类资源-CSDN文库