《python深度学习》第三章神经网络入门
神经网络入门
主要从例子入手,实现向量数据的分类和回归问题。
一、神经网络的剖析
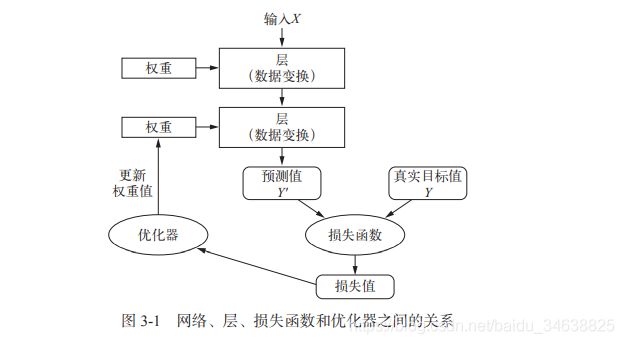
神经网络的四个方面:
(1)层:多个层组合形成网络(模型),将一个或多个输入张量转换为一个或多个输出张量,大多数层都有权重(利用随机梯度下降学到的一个或多个张量,包含网络的知识)。
注意:不同的张量格式和不同的数据处理类型要用到不同的层。例如:(samples, features)2D张量通常使用全连接层Dense来处理。(samples, timestep, features)3D张量序列数据
通常使用循环层LSTM来处理。图像数据4D张量,通常使用卷积层conv2D来处理。在keras中由函数式建模和序列建模(Sequential),只需要堆叠不同的层就可以,比较方面。
tensorflow2.3自带keras2.4而且有一些属性只能是tf自带的keras可用,keras2.4不支持多引擎了,所以直接都是用tf自带的keras。对于低版本的keras还是支持多引擎的。
(2)模型:深度学习模型是层构成的有向无环图。keras中可以使用最简单的线性堆叠,很快的就能建立一个模型。网络的拓扑结构:双分支网络、多头网络、Inception模块等。
选定了网络的拓扑结构,就可以理解为将可能性空间(机器学习的定义:在预定义的可能性空间里,利用反馈信号的指引来寻找输入数据的有用表示)限定为一系列特定的张量运算,将输入数据映射为输出数据。模型由层来组成的,层进行的是一系列的张量运算。
(3)损失函数与优化器:
损失函数(目标函数):衡量当前任务是否成功,需要将其最小化。但要注意过拟合问题。如何选择正确的损失函数十分重要,要使得损失函数和当前的任务相关,否则最终得到的结果可能不符合预期。一般的二分类问题可以使用二元交叉熵(binary crossentropy),多分类问题可以试用分类交叉熵(categorical crossentropy),回归问题可以使用均方误差(mean-squared error),序列学习问题可以使用联结主义时序分类(CTC, connectionist temporal classification)等。
优化器:决定如何基于损失函数对网络进行更新。
注意:多个输出的神经网络可能具有多个损失函数,但是梯度下降过程必须基于单个标量损失值,那么具有多个损失函数的网络,需要将所有损失进行再次操作,变为一个标量值。在计算损失的时候,特别要注意。
二、keras开发
(1)定义训练数据:输入张量和目标张量。
(2)定义层组成的网络(模型):将输入数据映射到目标。
(3)配置学习过程:选择损失函数、优化器和需要监控的指标。
(4)调用模型的fit方法在训练数据上进行迭代。
三、keras开发实例
下面会用三个例子来说明keras开发流程以及神经网络中的细节,代码在jupyter notebook运行,tensorflow2.3。
-
IMDB数据集进行电影评论的二分类
#%%
import tensorflow as tf
from tensorflow.keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000) #筛选出每条评论汇中,排名前10000的词。
#%%
print(train_data[0])
print(train_labels[0])
print(type(train_data))
#%%
t=[]
for sequence in train_data:
t.append(max(sequence))
print(max(t)) #两种是等价的
print(max([max(sequence) for sequence in train_data]))
#%%
word_index = imdb.get_word_index()
reverse_word_index = dict(
[(value, key) for (key, value) in word_index.items()])
decoded_review = ' '.join(
[reverse_word_index.get(i-3, '?') for i in train_data[0]])
print(reverse_word_index)
print(decoded_review)
print(reverse_word_index.get(1,'?'))
#%%
#数据预处理
#将整数序列编码为二进制矩阵
import numpy as np
def vectorize_sequences(sequences, dimension=10000): #sequences 是ndarray, 里面的内容是一个个的list, len(sequences)是样本(list)的数量
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences): #enumerate函数将 sequences组合成一个索引序列(加了一个索引),索引默认从0开始。
results[i, sequence] = 1.
return results
x_train = vectorize_sequences(train_data) #讲训练数据向量化
x_test = vectorize_sequences(test_data) #将测试数据向量化
print(x_train[0])
print(x_test[0])
#%%
y_train = np.array(train_labels).astype('float32')
y_test = np.array(test_labels).astype('float32')
print(y_train)
print(y_test)
#%%
#构建网络
#输入是向量,标签是标量(0,1)
#使用全连接层Dense来进行二分类问题。
from tensorflow.keras import models
from tensorflow.keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid')) #sigmoid 函数将任意值压缩到[0, 1]之间,可以看做是概率值
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
#划分数据集为训练集和验证集
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
#训练模型
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
#%%
history_dict = history.history
print(history_dict.keys())
#%%
#绘制训练损失和验证损失
import matplotlib.pyplot as plt
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1, len(loss_values)+1)
plt.plot(epochs, loss_values, 'bo', label='Training loss')
plt.plot(epochs, val_loss_values, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
#%%
#绘制训练精度和验证精度
plt.clf() #清空图像
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and Validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
#%%
#利用最好的参数来训练模型
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=4, batch_size=512)
results = model.evaluate(x_test, y_test)
print(results)
#%%
#在新数据上进行预测
x = model.predict(x_test)
print(x)
#%%
总结:
(1)原始数据通常不能直接输入到网络中,需要预处理转换为张量。
(2)二分类的最后一层使用sigmoid激活的Dense层,输出0-1之间的标量,可以理解为概率值。
(3)二分类的sigmoid输出应使用binary_crossentropy损失函数,rmsporp优化器在所有问题上都是一个较好的选择。
(4)训练中,可能在训练集上的效果非常好,但是由于过拟合,在全所未见的数据上可能效果非常差,一定要监控模型在训练集之外的数据上的性能。
(5)激活函数(relu、sigmoid等)是非线性操作,由于线性操作使得每层的假设空间非常有限,无法利用多个表示层的优势,多层的线性运算并不会扩展假设空间。激活函数可以丰富假设空间,充分利用多个层的表示优势。
2.路透社(reuters)数据集新闻多分类
含有46个分类。
#%%
from tensorflow.keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)
#%%
print(len(train_data))
print(len(test_data))
print(type(train_data))
print(len(train_data))
print(train_data.shape)
print(len(test_data[0]))
print(len(train_data[0])) #数据是选择前10000个最常用的单词保存,但是每条新闻并不会包含所有的单词,长度不一。
#%%
print(train_data[10])
#%%
word_index = reuters.get_word_index()
reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
decoded_newwire = ' '.join([reverse_word_index.get(i-3, '?') for i in train_data[0]])
print(decoded_newwire)
print(train_labels[0])
#%%
#准备数据
import numpy as np
#编码数据
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
#将训练数据向量化
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
#%%
#将标签向量化
def to_one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
one_hot_train_labels = to_one_hot(train_labels)
one_hot_test_labels = to_one_hot(test_labels)
#tf.keras自带的方法
from tensorflow.keras.utils import to_categorical
one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)
#%%
#构建网络
from tensorflow.keras import models
from tensorflow.keras import layers
#模型定义
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax')) #softmax函数将输出在46个类别上的概率分布。46个概率总和为1
#编译模型
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
#%%
#验证方法
#分割训练数据,留出验证集
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]
#训练模型
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
#%%
#绘制训练损失和验证损失
import matplotlib.pyplot as plt
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss)+1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and Validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
#%%
#绘制训练精度和验证精度
plt.clf()
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and Validation acc')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
#%%
#根据损失和精度,重新训练一个模型
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.losses import categorical_crossentropy
from tensorflow.keras.metrics import categorical_accuracy
from tensorflow.keras.initializers import he_normal
he_normal(seed=None)
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer=RMSprop(),
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=9,
batch_size=512,
validation_data=(x_val, y_val))
results = model.evaluate(x_test, one_hot_test_labels)
#%%
print(results)
#完全随机的精度
import copy
test_labels_copy = copy.copy(test_labels)
np.random.shuffle(test_labels_copy)
hits_array = np.array(test_labels) == np.array(test_labels_copy)
print(hits_array)
result = float(np.sum(hits_array))/len(test_labels) #np.sum 可以对布尔型数组true进行统计
print(result)
#%%
#在新数据上生成预测结果
predictions = model.predict(x_test)
print(predictions[0].shape)
print(np.sum(predictions[0]))
print(np.argmax(predictions[0])) #概率最大的那个就是预测的类别
#%%
#中间层维度足够大的重要性
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(4, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=128,
validation_data=(x_val, y_val))
#%%
总结:
(1)对于多分类类别数量N,那么在设置网络的隐藏层的单元时要注意不要小于N,这样很可能会因为过低的维度无法学习到全部信息,而导致分类的精度降低。
(2)N个类别进行分类,最后一层Dense的大小应为N。
(3)对于单标签、多分类问题,网络最后一层使用softmax激活函数,这样可以输出在N个输出类别上的概率分布。
(4)损失函数使用分类交叉熵,将网络输出的概率分布与目标的真实分布之间的距离最小化。
(5)处理多分类问题的标签可以使用分类编码(one-hot)编码,使用categorical_crossentropy作为损失函数。也可以将标签编码为整数,使用sparse_categorical_crossentropy损失函数。
3. 波士顿(boston)房价预测
回归问题,输出为一个连续值而不是离散的标签。数据量较少,所以使用了K折交叉验证。
#%%
#加载波士顿房价数据
from tensorflow.keras.datasets import boston_housing
(train_data, train_targets), (test_data, test_targets) = boston_housing.load_data()
#%%
print(train_data.shape)
print(test_data.shape)
print(train_targets)
#%%
#准备数据
#将数据标准化
mean = train_data.mean(axis=0)
train_data -= mean
std = train_data.std(axis=0)
train_data /= std
test_data -= mean
test_data /= std
print(mean)
print(std)
#%%
#构建网络
from tensorflow.keras import models
from tensorflow.keras import layers
def build_model():
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1)) #没有添加激活函数(是一个线性层),添加激活函数会限制输出的范围,这里是标量回归
model.compile(optimizer='rmsprop', loss='mse', metrics=['mae']) #损失使用均方误差,指标使用平均绝对误差
return model
#%%
#利用k折交叉验证方法
#在数据量少的时候常用,由于训练中验证集非常少,那么评估模型的分数可能因为验证集的问题而波动特别大。
#K折验证
import numpy as np
k=4
num_val_samples = len(train_data) // k #//整数除法
num_epochs = 500
all_scores=[]
all_mae_histories = []
for i in range(k):
print('processing fold #', i)
val_data = train_data[i * num_val_samples:(i+1) * num_val_samples]
val_targets = train_targets[i * num_val_samples: (i+1) * num_val_samples]
partial_train_data = np.concatenate( #将其他分区的数据,作为训练数据
[train_data[:i * num_val_samples],
train_data[(i+1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[(i+1) * num_val_samples:]],
axis=0)
model = build_model() #构建模型
history = model.fit(partial_train_data,
partial_train_targets,
epochs = num_epochs,
batch_size=1,
verbose=0,
validation_data=(val_data, val_targets))
val_mse, val_mae = model.evaluate(val_data, val_targets, verbose=0)
all_scores.append(val_mae)
print(history.history.keys())
mae_history = history.history['val_mae']
all_mae_histories.append(mae_history)
#%%
print(all_scores)
print(np.mean(all_scores))
#计算所有轮次epoch中K折验证分数平均值
average_mae_history = [
np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)]
#%%
#绘制验证分数
import matplotlib.pyplot as plt
plt.plot(range(1, len(average_mae_history)+1), average_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()
#%%
#删掉前10个点,并且将每个数据点替换为前面数据点的指数移动平均值
def smooth_curve(points, factor=0.9):
smoothed_points=[]
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous * factor + point * (1-factor)) #前一个值占 factor 后一个占 1-factor
else:
smoothed_points.append(point)
return smoothed_points
smooth_mae_history = smooth_curve(average_mae_history[10:])
plt.plot(range(1, len(smooth_mae_history)+1), smooth_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()
#%%
#利用最佳的轮次来训练最终模型
model = build_model()
model.fit(train_data, train_targets,
epochs=80, batch_size=16, verbose=0)
test_mse_score, test_mae_score = model.evaluate(test_data, test_targets)
print(test_mae_score)
#%%
总结:
(1)回归问题使用的损失函数与分类问题不同,回归问题常用的损失函数是均方误差(MSE)。
(2)回归问题使用的评估指标与分类问题也不同,常用的回归指标是平均绝对误差(MAE)。
(3)如果输入数据的特征具有不同的取值范围,要先进行预处理,对每个特征单独进行缩放。
(4)可用数据少,使用k折验证可以进行可靠地评估模型。
(5)如果可用数据少,最好使用隐藏层较少的网络,避免严重过拟合。