论文笔记 / Deep features for breast cancer histopathological image classification
仅供参考,如有翻译不到位的地方敬请指出。转载请标明出处!
论文地址:https://ieeexplore.ieee.org/abstract/document/8122889/citations#citations
摘要
乳腺癌(BC)是一种致命疾病,每年导致数百万人死亡。开发应用于患者图像的自动化恶性BC检测系统可以帮助更有效地处理该问题,使诊断更具可扩展性并且不易出错。同样重要的是,这种研究可以扩展到其他类型的癌症,对帮助挽救生命产生更大的影响。最近关于BC识别的结果表明,卷积神经网络(CNN)可以获得比手工制作的特征描述符更高的识别率,但是要付出的代价是开发系统的复杂性增加,需要更长的培训时间和特定的专业知识来细化调整CNN的架构。DeCAF(或深层)功能包括一个中间解决方案,它基于重新使用以前训练过的CNN作为特征向量,然后将其用作仅针对新分类任务训练的分类器的输入。鉴于此,我们提出了用于BC识别的DeCaf特征的评估,以便更好地理解它们与其他方法的比较。实验评估表明,这些特征可以成为快速开发高精度BC识别系统的可行替代方案,通常可以获得比传统手工制作的纹理描述符更好的结果,并且在某些情况下优于任务特定的CNN。
1、介绍
癌症目前是一种在全球范围内崛起的致命疾病。一些出版物,例如国际癌症研究机构(IARC)的出版物,是世界卫生组织(WHO)的一部分,仅报告了2012年因癌症导致的约820万人死亡的数字。预计到2030年,这种疾病的发病率将达到约2700万新病例[1]。在几种现有类型的癌症中,乳腺癌(BC)具有两个非常令人关注的特征:1)它是全世界女性中最常见的癌症; 2)与其他类型的癌症相比,它具有很高的死亡率。由于组织病理学分析仍然是最广泛使用的BC诊断方法[2]病理学家在显微镜下对组织学样本进行视觉检查,大部分诊断仍在继续进行,组织病理学图像的自动分类是一个研究课题,可以使BC诊断更快,更不容易出错。然而,直到最近,BC组织病理学图像识别系统的工作主要与小数据集一起工作,这通常是开发高精度图像识别系统的一个很大的限制。最近发布的BreaKHis数据集[3]包含超过7,900 幅图像,其中包含来自80多名患者的4种不同放大倍数,包括弥合这一差距的重要进展,允许研究人员将机器学习技术应用于此问题。
BC识别的当前最新结果遵循设计图像识别系统的两种最常见的方式。[3]中的方法,我们通常称为视觉特征描述符或手工制作的特征,遵循更“传统”的方法,其中对六个不同特征集和四个基本分类器的组合进行评估,并且最终系统由在验证集中产生最佳结果的组合定义。相反,在[4]和[5]中这些方法遵循深度学习趋势,其中卷积神经网络(CNN)被训练用于BC识别问题。第一种是基于单任务和多任务CNN架构的独立于放大的方法。第二个,这里称为从头开始的CNN或任务特定的CNN,可互换地,依赖于提取原始图像的几个小块来训练特定的CNN架构。报告的结果清楚地表明,后者可以实现更高的识别率。然而,这种系统的开发需要更长的培训时间,一些技巧如随机补丁[6]以提高性能,并且仍然有很多来自开发人员的专业知识来调整系统。
手工制作和任务特定的CNN方法的中间替代方案在文献中经常出现,通常被称为DeCAF特征或神经代码。该方法包括仅将预训练的CNN重新用作特征提取器,在该特征提取器之上,可以仅为新的分类任务学习新分类器的参数。这种方法已被证明是一种非常好的通用图像特征提取,可在各种任务中提供有竞争力的结果。虽然在大型训练集可用时从头开始训练CNN仍然是获得最佳准确度的最佳选择,但只要有适当的资源,DeCAF功能可以成为开发高精度系统的可行替代方案,类似于系统基于手工制作的功能。因此,如果DeCAF特征能够胜过其他视觉特征描述符,则可以将其设置为开发高精度图像识别系统的标准起点。与该领域相关的精确系统的开发,例如用于识别其他类型癌症的系统,可以更快地完成。
鉴于这些观点,这项工作的主要焦点在于评估DeCAF特征用于BC组织病理学图像分类,将BreaKHis数据集作为基准,旨在更好地理解这种方法与手工描述符和任务特定CNN的比较。更确切地说,我们的目标是利用预先训练的CNN从网络的不同层提取DeCAF特征,以了解这些特征是否足以与视觉特征描述符竞争,例如[3]中提出的那些。,以及它们如何与基于深度学习的方法进行比较,如CNN从头开始训练问题,如[4],以及独立放大CNN方法,在[5]中提出。为了实现这些目标,我们利用[11]中最初描述的多特征向量(MFV)框架,这允许我们在不同场景中评估此特征集,例如通过组合子图像的分类结果(我们也称为补丁)和/或组合不同的特征集。在这种情况下,我们不仅可以在使用基于补丁的方法时评估DeCAF特征的性能,还可以结合来自预训练CNN的不同层的DeCAF特征。
2、相关工作
在文献中,首次发表的关于癌症诊断自动成像处理的工作已有40多年的历史[12]。尽管对这个问题有着长期的兴趣,但由于这种系统需要分析的图像的复杂性,为它开发解决方案仍然具有挑战性。
近年来发表的与该主题相关的大量研究论文证明了研究界对该主题的兴趣。值得一提的是,最近这些与BC分类相关的工作主要集中在整体幻像(WSI)。然而,WSI和其他形式的数字病理学的广泛采用一直面临着诸如实施和操作技术的高成本,大批量临床常规的生产力不足,内在的技术相关问题,未解决的监管问题等障碍。作为病理学家的“文化抵抗” [19]。
另一个相关方面是,直到最近,关于BC组织病理学图像分析的大部分工作都是在小型数据集上进行的。另一个缺点是科学界通常无法获得这些数据集,这不仅使其他研究人员难以开发新系统,因为他们需要收集图像来组成训练集,而且还要对基于系统。为了弥合这一差距,BreaKHis数据集已经发布并免费提供给研究界[3]。该数据库包含来自乳腺肿瘤的外科活检(SOB)的显微图像,共计7,909个图像分为良性和恶性肿瘤,这些图像已经在四种不同的放大因子(或缩放级别,这是我们使用的术语)中收集可互换的):40 × ,100 × ,200 × 和 400 ×。从乳房组织活检载玻片产生样品,用苏木精和曙红(HE)染色。制备这些样品用于组织学研究,并由Prevenção&Diagnose(P&D)实验室的病理学家进行标记。采集的数字图像有3通道RGB(红 - 绿 - 蓝)TrueColor(24位色深,每通道8位)色彩空间,尺寸为700 × 460像素。图1显示了该组中的四个相应放大系数的样本。BreaKHis数据库的完整描述可以在[3]中找到。

图1。来自breakhis数据库的图像样本。不同的区域,属于同一张乳腺恶性肿瘤(用他染色),见于不同的放大因子:(a)40 × ,(b)100 × ,(c)200 ×,和(d) 400 ×。
自最近发布BreaKHis数据集以来,已经提出了一些使用该数据集的方法。在[3]中,作者提出了对六种不同视觉特征描述符的不同组合以及不同分类器的评估。他们报告的精度范围从80%到85%,这可能会因图像放大系数而异。Span-hol 等。[4]来自CNN的该集合的结果。鉴于CNN通常需要大型数据集,他们利用随机补丁技巧,包括在训练和测试阶段提取子图像。在训练期间,想法是通过在随机定义的位置提取补丁来增加训练集。并且在测试期间,从网格中提取补丁,并且在对每个补丁进行分类之后,将它们的分类结果组合。作者表明,采用这种方法,可以在准确度上观察到大约4到6个百分点的增加。最近,Bayramoglu 等人。[5]提出了一种对BC组织病理学图像进行分类的方法,该方法与放大因子无关。他们的实验结果与先前从手工制作的特征获得的最先进结果相竞争[3]。
值得一提的是,深度学习方法在多个任务中始终优于更传统的机器学习方法。尽管如此,实现良好的性能取决于训练集的大小,或取决于更专业的训练方案,例如随机补丁,这通常需要非常长的训练时间。避免必须处理大型训练数据集和长训练时间的解决方案,并且最近报告具有非常好的性能,是依赖于重用现有的预训练CNN。这种方法通常被称为DeCAF特征或神经代码,之前已应用于各种任务,如物体识别[7],图像检索[8],纹理识别[9]等[10]。
3、DeCAF功能
DeCAF功能的构思包括从图像中提取特征并将其用作分类器的输入,就像任何其他特征集一样。然而,DeCAF基于表示学习,其中神经网络的参数以原始数据(即图像的像素)可以转换为高级表示的方式学习[20]。DeCAF特征与当前使用CNN的标准[4],[6],[21]之间的主要区别在于,先前训练的CNN被简单地重新用作特征提取器,其输出被馈送到另一个分类器,训练有素关于特定问题的数据。
详细地说,DeCAF特征集包括重用预训练神经网络(通常是CNN)的架构和参数,通过前馈步骤传递输入图像,并使用网络的给定层的输出作为输入。分类器[7] - [8] [9] [10]。为了实现这一想法,我们使用预先训练的BVLC CaffeNet Model 1 (或简称为CaffeNet),Caffe深度学习框架2免费提供。该模型包含对AlexNet模型的轻微修改[21]鉴于它没有经过数据增强训练,并且池化和归一化层的顺序被切换,即在CaffeNet池中进行归一化。
CaffeNet模型已经在ImageNet数据集[22]上进行了培训,更具体地说是针对ILSVRC12挑战发布的数据集,在验证集上获得了57.4%的前1准确度和80.4%的前5准确度。该集包含大约120万个样本,分布在1,000个不同的类中。鉴于类的数量和可变性以及大量样本,主要假设是从在该数据集上训练的CNN获得的表示定义了非常好的通用特征提取器。
为了将CaffeNet模型转换为特征提取器,我们利用CNN最顶层的输出,例如层fc6,fc7和fc8(参考图示在图2的右下方)。然后,对应于那些层的输出的向量可以用作分类器的输入,仅对任务特定数据进行训练。
4、实验
在本节中,我们对BreaKHis数据集进行了广泛的实验评估,以评估不同情景下的DeCAF特征。考虑到图像级别和患者级别的准确度指标,独立评估每个级别的准确度。第二个度量标准的原因在于,通常,在医学成像中,决策是在患者方面做出的。为了更好地理解,我们在下面定义了两个指标。
图像级精度仅对应于正确分类图像总数的分数。那就是,让ñ我中号 是数据集中的图像总数,和 ñC 正确分类的图像总数,图像级精度定义为:
图像级精度=Nc / Nim
另一方面,患者级精确度对应于每位患者的平均图像级准确度。更正式的是,让我们ñP 是患者总数, ñpC 是来自患者的正确分类图像的总和 p,和 ñp我中号 同一患者的图像总数,患者级别的准确度定义为:
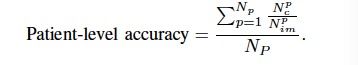
尽管CaffeNet模型中的层数相对较多,但在这项工作中,我们只关注从三个最顶层提取特征,即fc6,fc7和fc8,它们可能是三个最高级别的特征。这些层分别由4,096,4,096和1,000维组成。鉴于这些向量的高维性,我们仅考虑Logistic回归作为基本分类器,因为它在训练和分类阶段都很快,并且可以提供输出概率。
实验按以下方式组织。通过考虑基于补丁的识别和不同的配置,我们首先通过利用fc6,fc7或fc8层的输出单独评估DeCAF功能集的使用,并考虑具有1,4和16的系统补丁,基于[11]中提出的MFV框架。这些实验的主要目的是观察不同层的DeCAF特征的准确性差异,以及进行基于贴片的分类时的影响。
然后,我们进行类似的实验,但同时考虑多个特征集的组合,即来自网络的多个层的特征。同样,我们基于[11]中提出的框架实现了这个想法,其中功能组合考虑了补丁级别的输出。
为了与现有技术直接比较,在[3],[4]中使用的五重复制的相同分区可用于数据集3的下载页面。
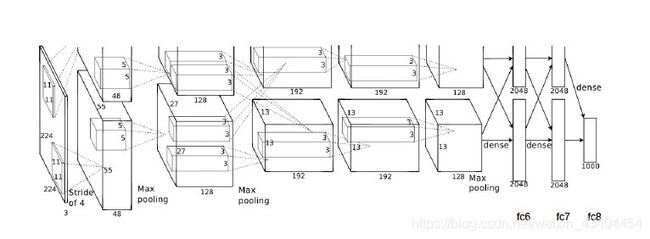
图2。alexnet模型的例证(摘自[21]),用作caffe模型的基线。在右下角,列出了顶层的引用名称。
A.结果
通过考虑先前描述的设置,第一评估使用来自三个上述层中的每一个的DeCAF特征,单独地,具有1,4和16个块。结果列于表I中。很明显,来自fc8层的特征比来自其他两层的特征表现更差,这在所有情况下都表现出最好的结果。与fc7和fc6相比,第一个具有轻微优势,在4个缩放级别中有3个具有最佳患者级别准确度,考虑到两个放大因子都在图像级别达到最佳准确度。关于补丁的使用,结果表明这可能是一个有趣的替代方案,以改善这些功能的结果。除了400 ×缩放级别,使用整个图像(单个补丁)实现最佳患者级别准确度,所有其他缩放级别的最佳结果是至少有4个补丁。具有缩放级别200 ×,具有16个补丁的系统表现得相当好。
B.使用组合的结果
这里给出的结果与评估来自层fc6,fc7和fc8的DeCAF特征的组合的实验有关(考虑到可以使用的四种可能的特征集,考虑到空间限制,仅指出为6,7和8)。即6 + 7 + 8,6 + 7,6 + 8和7 + 8。鉴于我们已经观察到同时组合来自三个层的特征没有提供最高的识别率,表II仅显示了成对组合的结果。
总的来说,尽管我们可以观察到某些情况下准确性的一些改进,但与单个特征集在时间上获得的最佳结果相比,最大增益幅度仅为0.3%,即从86.0%增加到患者准确率为86.3% 200 × 放大系数,图像精度从84.3%增加到84.6% 40 × 放大系数。
C.方法准确性的比较
在表III中,我们比较了基于传统手工制作的特征[3],任务特定的CNN [4]和DeCAF特征(这项工作)的方法的准确性。这些方法在F1得分(也称为文献中的F-得分和F-度量[23])方面进行了比较,由精度和召回之间的调和平均值给出(方程(3))
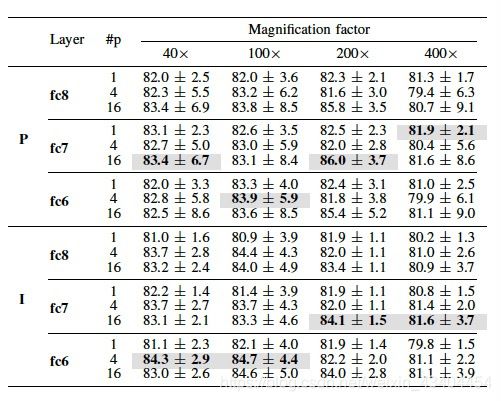
表I:精度,各自的标准偏差,没有层的组合。P代表患者级别的准确度,I代表图像级别的准确度,P代表补丁的数量。粗体,灰色背景,突出显示每个级别和放大系数的最佳结果
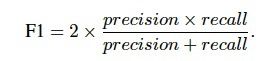
对于患者水平评估,我们考虑所有患者的平均F1评分,类似于公式(2)中定义的患者水平准确度。该指标可以更好地了解检测阳性病例(即恶性癌症)的准确性,其中这种检测中的错误对于这类问题是非常昂贵的(它可能花费患者的生命)。一般来说,F1得分更能突出DeCAF功能的优异表现。与[3]中发表的视觉特征提取器的性能相比,我们的方法在患者和图像级别得分方面优于其他方法。与来自[4]的任务专用CNN相比,我们可以观察到与整体精度相似的结果。然而,观察到方法之间的更小间隙,尤其是在100倍放大系数下。

表II:结合FC6,FC7和FC8层的脱咖啡特征得到的精度,各自的标准偏差。P代表患者级别的准确度,I代表图像级别的准确度,P代表补丁的数量。粗体,灰色背景,突出显示每个级别和放大系数的最佳结果。
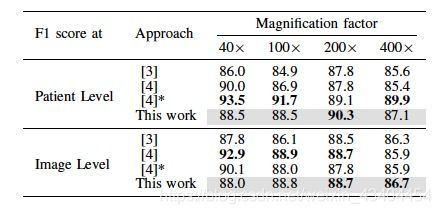
表III:三种方法的F1得分(患者和图像水平)。最佳结果以粗体显示,在灰色背景下是在这项工作中获得更高结果的情况,与[3]中提供的结果相比较。多个分类器组合的结果标有*
D.讨论
为了更好地理解这里给出的结果,在表IV中我们汇总了这项工作中获得的最佳结果,并将它们与[3],[4]和[5]中给出的最佳结果一起列出。[5]中公布的所有结果均基于患者评分,并且无法进行图像水平分析。
主要观察结果是,使用DeCAF特征通常可以获得比使用更传统的视觉特征描述符更好的结果,例如LBP(局部二进制模式)[24]和PFTAS(参数自由阈值分析)[25],[26 ] ],而且,在几乎一半的情况下,甚至击败CNN的结果[4] ,[5] 。与传统方法相比[3],仅在200 × 缩放级别与图像级精度相关,而DeCAF在患者精确度方面失去了 400 ×放大系数。在其余情况下,使用DeCAF功能获得的识别率至少提高0.4%,但这种差异可能高达4.1%。与[4]中提出的基于CNN的方法相比,取得了更高的成果,DeCAF的功能优于该方法200 ×:缩放级别,并在 400 ×在图像准确性。在不考虑[4]中提出的分类器组合的情况下,具有DeCAF特征的系统在该放大因子中也以患者精度击败CNN。并在40 ×放大系数,图像级精度接近CNN。但是,对于相同缩放级别的患者级别准确度,以及两种指标100 ×放大倍数,CNN以更大的幅度击败我们的结果,范围从4.5%到6.0%。这指出特定于任务的CNN可能更好地处理具有更细粒度结构的图像,而DeCAF特征可以更好地适用于更粗粒度的问题。
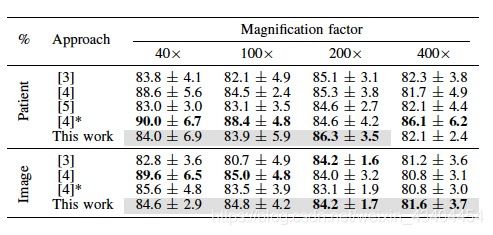
表IV:与文献的比较。最好的结果以粗体显示,在灰色背景下是在这项工作中获得更高结果的情况,与[3]中的结果相比较。多个分类器组合的结果标有*
5、结论
在这项工作中,我们使用BreaKHis数据集展示了使用DeCAF特征进行乳腺癌识别的研究。BreaKHis数据集的大尺寸使我们有机会在同一数据集上比较从头开始训练的CNN与从自然图像训练的另一个CNN重新利用的(DeCAF)特征,这通常是医学图像数据集不可能的,因为它们是太小。从结果我们可以看出,这些特征是使用深度学习快速创建图像识别系统的可行替代方案,并且该系统可以比使用视觉特征描述符的系统更好地执行。与从零开始训练的CNN相比,DeCAF具有可比较的识别率。请注意,专门针对该问题培训CNN需要更复杂和更慢的培训方案。
该结果对于计算机辅助诊断中基于未来分类的系统的设计是重要的,因为它表明深度学习的特征,即使通过在其他类型的图像上训练的CNN获得,也是有价值的。通过这项研究,我们向医学图像分析和CAD / CADx系统的转移学习迈出了一步,如[27],CNN在ImageNet上训练,可以检测医学图像中的结节。
作为未来的工作,一个方向是使用补丁提高DeCAF功能的识别准确性。进一步研究贴片的大小以及重叠贴片可能有助于提高DeCAF功能所获得的准确度。另一项可以产生良好结果的调查是将这些特征与其他视觉描述符和任务特定的CNN结合起来,以利用这些方法的互补性。此外,对特征和分类器选择的更好调查也可以提高性能。
个人总结
我会把我看的每篇文章都会翻译吗出来,由于不是专业的,可能翻译的不好,请大家多多包涵。如有侵权,麻烦联系我!