目标检测算法SSD论文解读
版权声明:本文为博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/jy001227801/article/details/80388192
参考链接:https://blog.csdn.net/a8039974/article/details/77592395
论文题目:SSD: Single Shot MultiBox Detector
论文地址:http://arxiv.org/abs/1512.02325
代码地址:https://github.com/balancap/SSD-Tensorflow
SSD提供了一种多尺度特征图预测分类和回归的思想,精确度和速度都很高。
SSD框架如下:
一、论文解读
1、多尺度特征(最大贡献)
YOLO在卷积层后接全连接层,即检测时只利用了最高层feature maps(包括Faster RCNN也是如此);而SSD采用了特征金字塔结构进行检测,即检测时利用了conv4-3,conv-7(FC7),conv6-2,conv7-2,conv8_2,conv9_2这些大小不同的feature maps,在多个feature maps上同时进行softmax分类和位置回归。也就是说,SSD就是Faster-RCNN和YOLO中做了一次的分类和检测过程放在不同的图像大小上做了多次。

2、先验框个数计算
一共有8732个boxes,和 Faster-RCNN一样,SSD也是特征图上的每一个点对应一组预选框。然后每一层中每一个点对应的prior box的个数,是由PriorBox这一层的配置文件决定的。

3、生成先验框
在SSD中引入了Prior Box,实际上与anchor非常类似,就是一些目标的预选框,后续通过softmax分类+bounding box regression获得真实目标的位置。区别是SSD每个位置的prior box一般是4~6个,少于Faster RCNN默认的9个anchor;同时prior box是设置在不同尺度的feature maps上的,而且大小不同。

SSD按照如下规则生成prior box:
(1)以feature map上每个点的中点为中心,生成一些列同心的prior box,然后中心点的坐标会乘以step,相当于从feature map位置映射回原图位置。
(2)正方形prior box最小边长为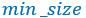 ,最大边长为:
,最大边长为:
(3)每在prototxt设置一个aspect ratio,会生成2个长方形,长: 宽:
宽:
(4)而每个feature map对应prior box的min_size和max_size由以下公式决定,m是使用feature map的数量(SSD 300中m=6):
第一层feature map对应的min_size=S1,max_size=S2;第二层min_size=S2,max_size=S3;其他类推。在原文中,Smin=0.2,Smax=0.9,但是在SSD 300中prior box设置并不能和paper中上述公式对应:

4、step参数选择
中心点的坐标会乘以step,相当于从feature map位置映射回原图位置。Cal_scale = 300/out_size,实际就是 原图与特征图 大小的比值,比如conv4-3 width = 38 ,输入的大小为300,那么scale=7.8,所以这里设置的step=8。

5、先验框的使用
以conv4_3为例,在conv4_3 feature map网络pipeline分为了3条线路:
(1)分类:经过一次batch norm+一次卷积后,生成了[1, num_class*num_priorbox, layer_height, layer_width]大小的feature用于softmax分类目标和非目标(其中num_class是目标类别,SSD 300中num_class = 21)
(2)框回归:经过一次batch norm+一次卷积后,生成了[1, 4*num_priorbox, layer_height, layer_width]大小的feature用于bounding box regression(即每个点一组[dxmin,dymin,dxmax,dymax])
(3)先验框:生成了[1, 2, 4*num_priorbox]大小的prior box blob,其中2个channel分别存储prior box的4个点坐标和对应的4个variance(bounding regression中的权重)

6、SSD优缺点
优点:运行速度可以和YOLO媲美,检测精度可以和Faster RCNN媲美
缺点:
(1)需要人工设置prior box的min_size,max_size和aspect_ratio值。网络中prior box的基础大小和形状不能直接通过学习获得,而是需要手工设置。而网络中每一层feature使用的prior box大小和形状恰好都不一样,导致调试过程非常依赖经验。
(2)虽然采用了pyramdial feature hierarchy的思路,但是对小目标的recall依然一般,并没有达到碾压Faster RCNN的级别。作者认为,这是由于SSD使用conv4_3低级feature去检测小目标,而低级特征卷积层数少,存在特征提取不充分的问题。
7、损失函数
(1)整体损失函数是定位损失和置信损失(类条件概率:类别概率*置信度)的加权和:

其中n是匹配的默认框数,如果n=0,将损失设置为0。α参数用于调整confidence loss和location loss之间的比例,默认α=1。
(2)其中confidence loss是典型的softmax loss:

其中, 表示第i个默认框和第j个p类真值框匹配。
表示第i个默认框和第j个p类真值框匹配。
(3)其中location loss是典型的smooth L1 loss:

8、匹配策略
在训练时,groundtruth boxes 与 default boxes(就是prior boxes) 按照如下方式进行配对:
(1)首先,寻找与每一个ground truth box有最大的jaccard overlap的default box,这样就能保证每一个groundtruth box与唯一的一个default box对应起来(所谓的jaccard overlap就是IoU)。
(2)SSD之后又将剩余还没有配对的default box与任意一个groundtruth box尝试配对,只要两者之间的jaccard overlap大于阈值,就认为match(SSD 300 阈值为0.5)。
(3)配对到GT的default box就是positive,没有配对到GT的default box就是negative。
9、硬负样本挖掘
一般情况下negative default boxes数量 >> positive default boxes数量,直接训练会导致网络过于重视负样本,从而loss不稳定。所以SSD在训练时会依据confidience score排序default box,挑选其中confidience高的box进行训练,控制positive:negative=1:3
10、数据增强
随机的进行如下几种选择:
(1)使用原始的图像
(2)采样一个 patch,与物体之间最小的 jaccard overlap 为:0.1,0.3,0.5,0.7 或 0.9
(3)随机的采样一个 patch,采样的 patch 是原始图像大小比例是[0.1,1],aspect ratio在1/2与2之间。
11、思考:SSD多尺度得到的预测结果如何综合考虑?
每个尺度结果互不影响,得到的预测结果个数是各层的总和,然后进行NMS,得到最终预测结果。也就是说,SSD就是(把Faster-RCNN和YOLO中做了一次的)分类和检测过程放在不同的图像大小上做了多次。

二、代码解读
1、SSDNet网络结构
在vgg16的基础上(前5个block),新增一些卷积层,分别提取block4,block7,block8,block9,block10,block11层的不同大小特征图,在多个feature maps上同时进行softmax分类和位置回归。
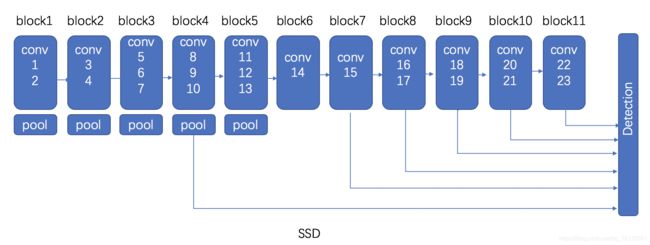
block1~5代码如下:

block6~11代码如下:

对这些层:block4,block7,block8,block9,block10,block11都做softmax分类和位置回归。

其中ssd_multibox_layer函数如下:

2、SSD loss

硬负样本挖掘、分类用交叉熵损失函数、框位置回归用smooth L1
