8种视觉Transformer整理(上)
一、ViT
原文链接:https://arxiv.org/pdf/2010.11929.pdf

首先将图像分割成长宽均为 的patch(共
的patch(共 个),然后将每个patch reshape成一个向量,得到所谓的flattened patch(记为
个),然后将每个patch reshape成一个向量,得到所谓的flattened patch(记为![]() )。
)。
为了避免模型结构受到patch size的影响,对flattened patch向量做了Linear Projection,将flattened patch向量转化为固定长度的向量( 维)。
维)。
此外引入额外的可学习的embedding(类似于BERT中的[class] token),第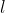 层的记为
层的记为![]() 。Transformer输入端的该embedding(即
。Transformer输入端的该embedding(即![]() )为
)为![]() ;Transformer输出端的该embedding(即
;Transformer输出端的该embedding(即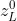 )提供整个图像的表达
)提供整个图像的表达 。最后的分类头总是连接在上,从而分类头的结构与patch数量无关。
。最后的分类头总是连接在上,从而分类头的结构与patch数量无关。
然后将position embedding(![]() )和patch embedding相加输入到encoder中,即
)和patch embedding相加输入到encoder中,即
![]()
其中![]() 为权重向量。
为权重向量。
查了一下,BERT中的[class] token貌似是利用self attention求所有embedding的加权平均得到的
encoder包含多头自注意力机制(MSA)、双层MLP(激活函数为GELU)、LayerNorm(LN),公式如下:
混合结构:使用ResNet中间层的feature map作为Transformer的输入。直接将ResNet某一中间层的2D feature map展平为序列,再通过Linear Projection变为Transformer输入的维度,然后直接输入Transformer。[class] embedding和position embedding与前面一样。
更高分辨率图像下的fine-tune:保持patch大小不变,得到的patch个数将增加(![]() )。但是由于在预训练后,position embedding的个数是固定的(
)。但是由于在预训练后,position embedding的个数是固定的( ),因此根据其在原始图像中的位置将预训练得到的position embedding插值为
),因此根据其在原始图像中的位置将预训练得到的position embedding插值为![]() 个。
个。
二、CoAtNet
原文链接:https://arxiv.org/pdf/2106.04803.pdf
将depthwise卷积与自注意力机制结合:
depthwise卷积:
![]()
其中![]() 是
是 的局部邻域;
的局部邻域;![]() 表示该权重仅与相对位置有关;
表示该权重仅与相对位置有关; 表示按元素乘法。
表示按元素乘法。
自注意力机制:

其中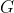 为全局空间。
为全局空间。
两者结合为

或
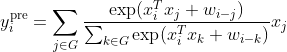
前者称为后归一化,后者称为预归一化。
为避免全局卷积核的参数量爆炸,这里的![]() 为标量而非矢量。
为标量而非矢量。
网络结构确定:搭建5个stage的网络,实验比较(泛化性、模型容量、可迁移性)得出下图所示(卷积-卷积-Transformer-Transformer)结果最好。

2D相对注意力:实施CoAtNet的预归一化版本。设输入图像为 的。对每个头(head)创建一个可训练参数(全局卷积核?),大小为
的。对每个头(head)创建一个可训练参数(全局卷积核?),大小为![]() ,则
,则 和
和![]() 的相对偏差为
的相对偏差为![]() 。
。
对于更高分辨率图像下的fine-tune,使用双线性插值将的大小增加即可。
预激活:MBConv和Transformer都使用预激活结构,即![]() ,其中Module表示MBConv、自注意力或FFN模块;Norm表示MBConv中的BatchNorm或自注意力/FFN中的LayerNorm。GELU作为MBConv块和Transformer的激活函数。
,其中Module表示MBConv、自注意力或FFN模块;Norm表示MBConv中的BatchNorm或自注意力/FFN中的LayerNorm。GELU作为MBConv块和Transformer的激活函数。
分类头:对最后一个stage的输出,采用全局均值池化来得到表达,而非像ViT一样增加额外的
三、CoT
原文链接:https://arxiv.org/pdf/2107.12292.pdf
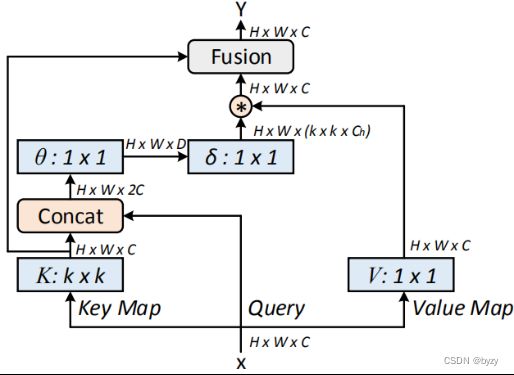
传统的 和
和 用
用 卷积得到,忽略了上下文信息;这里取
卷积得到,忽略了上下文信息;这里取![]() ;首先对应用
;首先对应用 卷积得到
卷积得到![]() ,称为静态上下文表示。然后与拼接后通过2层的MLP得到
,称为静态上下文表示。然后与拼接后通过2层的MLP得到 (权重矩阵):
(权重矩阵):
![]()
然后得到![]() (称为动态上下文表示):
(称为动态上下文表示):
![]()
输出为![]() 和
和![]() 通过注意力机制的融合(图中Fusion方框)。
通过注意力机制的融合(图中Fusion方框)。
应用:使用CoT直接替换ResNet中的 卷积。
卷积。
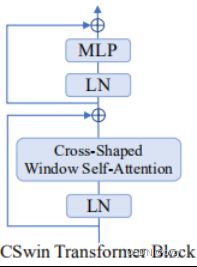
四、CSWin Transformer
原文链接:https://arxiv.org/pdf/2107.00652.pdf
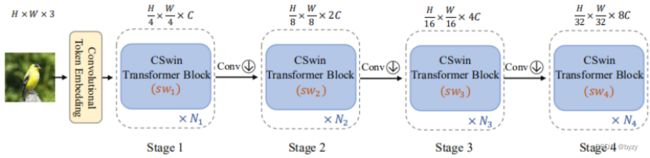
整体结构:先用一个 步长为4的卷积进行下采样;4个stage,stage之间的下采样为步长为2的卷积。
步长为4的卷积进行下采样;4个stage,stage之间的下采样为步长为2的卷积。
具体实现:将个head分为两半,一半做水平自注意力(Horizontal Self Attention),另一半做垂直自注意力(Vertical Self Attention)。
对于水平自注意力,就是将图像分割为宽度为![]() 的横条,对每一个横条分别做自注意力后拼接;
的横条,对每一个横条分别做自注意力后拼接;
![]()
![]()
![]()
垂直自注意力同理。
最后将两半head的输出拼接后通过卷积,即
![]()
![]()
局部增强位置编码:depth-wise卷积作用于 。
。
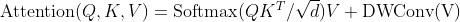
CSWin Transformer块: