【MySQL】过年没有回老家,在出租屋里整理了一些思维导图
Xmind导图知识点
- Mysql知识点
- SQL知识点
- Mybatis知识点
- 面试题分享
-
- MySQL部分
- Mybatis部分
Mysql知识点
通过下面的图片可以看出,MySQL基础语法分为四部分:连接数据库,对数据库的操作,对表中的数据操作,对表操作等等。

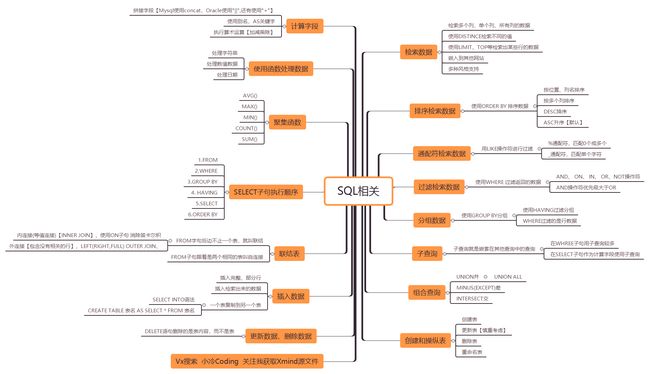
SQL知识点
SQL相关的知识点就多了,SQL就是对数据库表进行操作,需要掌握的技术知识点就比较多了。
比如:
- 如何创建表,更新表,删除表,重命名表。
- 什么是组合查询,什么是子查询等等。
- 如何过滤检索数据,分组数据,排序检索数据,快速检索数据。
- 如何使用函数处理数据,SQL中会用到哪些函数?
- 还要知道seclect查询语句的执行顺序。
- 还需要知道聚集函数的使用。
- 联表查询的实现方法。
Mybatis知识点
包含了
- 快速入门
- mybatis缓存:一级缓存,二级缓存
- Mapper代理知识点
- 映射关系, 映射文件介绍

看上图知道了一级缓存就是基于sqlSession的缓存,Mybatis默认是开启一级缓存的。实现原理就是:通过一个Map来实现
同一个sqlsession再次发出相同的sql,就从缓存中取不走数据库。如果两次中间出现commit操作(修改、添加、删除),本sqlsession中的一级缓存区域全部清空,下次再去缓存中查询不到所以要从数据库查询,从数据库查询到再写入缓存。
与Spring整合之后,使用的是Mappper代理对应,一级缓存是失效的。为什么呢?因为在同一线程里面两次查询同一数据所使用的sqlsession是不相同的。
二级缓存是基于Mapper(同一个命名空间)的缓存,Mybaits的二级缓存是需要自己在配置文件中配置的。查询结果映射的pojo需要实现 java.io.serializable接口,useCache=“false”。
这就是mybatis中一级缓存和二级缓存。面试的时候也会并经常问到,一定要掌握闹牢固。
面试题分享
MySQL部分
- 一千万条数据的表, 如何分页查询
数据量过大的情况下, limit offset分页会由于扫描数据太多而越往后查询越慢. 可以配合当前页最后一条ID进行查询。
SELECT * FROM T WHERE id > #{ID} LIMIT #{LIMIT}。
当然, 这种情况下ID必须是有序递增的, 这也是有序ID的好处之一。
- MySQL怎么恢复半个月前的数据
需要前期是有定期的备份整个数据库的数据,如果有备份可以通过binlog日志进行恢复
- MySQL事务的隔离级别, 分别有什么特点
1. 读未提交(RU): 一个事务还没提交时, 它做的变更就能被别的事务看到.
2. 读提交(RC): 一个事务提交之后, 它做的变更才会被其他事务看到.
3. 可重复读(RR): 一个事务执行过程中看到的数据, 总是跟这个事务在启动时看到的数据是一致的. 当然在可重复读隔离级别下, 未提交变更对其他事务也是不可见的.
4. 串行化(S): 对于同一行记录, 读写都会加锁. 当出现读写锁冲突的时候, 后访问的事务必须等前一个事务执行完成才能继续执行
- 唯一索引比普通索引快吗, 为什么?
唯一索引不一定比普通索引快, 还可能慢.
原因是:
1. 查询时, 在未使用limit 1的情况下, 在匹配到一条数据后, 唯一索引即返回, 普通索引会继续匹配下一条数据, 发现不匹配后返回. 如此看来唯一索引少了一次匹配, 但实际上这个消耗微乎其微.
2. 更新时, 这个情况就比较复杂了. 普通索引将记录放到change buffer中语句就执行完毕了. 而对唯一索引而言, 它必须要校验唯一性, 因此, 必须将数据页读入内存确定没有冲突, 然后才能继续操作. 对于写多读少的情况, 普通索引利用change buffer有效减少了对磁盘的访问次数, 因此普通索引性能要高于唯一索引.
- 订单表数据量越来越大导致查询缓慢, 如何处理
分库分表. 由于历史订单使用率并不高, 高频的可能只是近期订单,
因此, 将订单表按照时间进行拆分, 根据数据量的大小考虑按月分表或按年分表.
订单ID最好包含时间(如根据雪花算法生成), 此时既能根据订单ID直接获取到订单记录, 也能按照时间进行查询.
Mybatis部分
1.Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的就是 一对一,collection指的就是一对多查询。在Mybatis配置文件中,可以配置是否启用延迟加载 lazyLoadingEnabled=true|false。
它的原理是: 使用CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调 用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好 的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完 成a.getB().getName()方法的调用。
这就是延迟加载的基本原理。 当然了,不光是Mybatis,几乎所有的包括Hibernate,支持延迟加载的原理都是一样的。
2.#{}和${}的区别
#{}是占位符,预编译处理;${}是拼接符,字符串替换,没有预编译处理。
Mybatis在处理#{}时,#{}传入参数是以字符串传入,会将SQL中的#{}替换为?号,调用
PreparedStatement的set方法来赋值。
#{} 可以有效的防止SQL注入提高系统安全性 。后者不能防止SQL 注入#{} 的变量替换是在DBMS 中;${} 的变量替换是在 DBMS 外
- 使用MyBatis的mapper接口调用时有哪些要求?
1.Mapper接口方法名和mapper.xml中定义的每个sql的id相同。
2.Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相 同。
3.Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同。
4.Mapper.xml文件中的namespace即是mapper接口的类路径。
- Mybatis如何执行批量操作
使用foreach标签
foreach的主要用在构建in条件中,它可以在SQL语句中进行迭代一个集合。foreach标签的属性主 要有item,index,collection,open,separator,close。
item 表示集合中每一个元素进行迭代时的别名,随便起的变量名;
index 指定一个名字,用于表示在迭代过程中,每次迭代到的位置,不常用;
open 表示该语句以什么开始,常用“(”;
separator 表示在每次进行迭代之间以什么符号作为分隔符,常用“,”;
close 表示以什么结束,常用“)”。 在使用foreach的时候最关键的也是最容易出错的就是collection属性,该属性是必须指定的,但是 在不同情况下,该属性的值是不一样的,
主要有一下3种情况:
- 如果传入的是单参数且参数类型是一个List的时候,collection属性值为list
- 如果传入的是单参数且参数类型是一个array数组的时候,collection的属性值为array
- 如果传入的参数是多个的时候,我们就需要把它们封装成一个Map了,当然单参数也可以封 装成map,实际上如果你在传入参数的时候,在MyBatis里面也是会把它封装成一个Map 的, map的key就是参数名
所以这个时候collection属性值就是传入的List或array对象在自己封 装的map里面的key
具体用法如下:
<!-- 批量保存(foreach插入多条数据两种方法)int addEmpsBatch(@Param("emps") List<Employee> emps); -->
<!-- MySQL下批量保存,可以foreach遍历 mysql支持values(),(),()语法 --> //推荐使用
<insert id="addEmpsBatch">
INSERT INTO emp(ename,gender,email,did) VALUES
<foreach collection="emps" item="emp" separator=","> (#{emp.eName},#{emp.gender},#{emp.email},#{emp.dept.id})
</foreach>
</insert>
<!-- 这种方式需要数据库连接属性allowMutiQueries=true的支持 如jdbc.url=jdbc:mysql://localhost:3306/mybatis?allowMultiQueries=true -->
<insert id="addEmpsBatch">
<foreach collection="emps" item="emp" separator=";">
INSERT INTO emp(ename,gender,email,did) VALUES
(#{emp.eName},#{emp.gender},#{emp.email},#{emp.dept.id})
</foreach>
</insert>
使用ExecutorType.BATCH
Mybatis内置的ExecutorType有3种,
默认为simple,该模式下它为每个语句的执行创建一个 新的预处理语句,单条提交sql;而batch模式重复使用已经预处理的语句,并且批量执行所 有更新语句,显然batch性能将更优; 但batch模式也有自己的问题,比如在Insert操作时, 在事务没有提交之前,是没有办法获取到自增的id,这在某型情形下是不符合业务要求的 具体用法如下:
mapper和mapper.xml如下
//批量保存方法测试
@Test
public void testBatch() throws IOException{
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
//可以执行批量操作的sqlSession SqlSession openSession =
sqlSessionFactory.openSession(ExecutorType.BATCH);
//批量保存执行前时间
long start = System.currentTimeMillis(); try {
EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class);
for (int i = 0; i < 1000; i++) { mapper.addEmp(new
Employee(UUID.randomUUID().toString().substring(0, 5), "b", "1"));
}
openSession.commit();
long end = System.currentTimeMillis();
//批量保存执行后的时间 System.out.println("执行时长" + (end - start));
//批量 预编译sql一次==》设置参数==》10000次==》执行1次 677
//非批量 (预编译=设置参数=执行 )==》10000次 1121
} finally {
openSession.close();
}
mapper和mapper.xml如下
public interface EmployeeMapper {
//批量保存员工
Long addEmp(Employee employee);
}
<mapper namespace="com.jourwon.mapper.EmployeeMapper"
<!--批量保存员工 -->
<insert id="addEmp">
insert into employee(lastName,email,gender) values(#{lastName},#{email},#{gender})
</insert>
</mapper>
写到最后,一直在技术路上前行…
昨天,删去,今天,争取,明天,努力
需要资料的VX 搜索 小冷coding 关注 获取