基于物品的协同过滤mysql_离线商品推荐系统(基于物品的协同过滤算法+MapReduce)...
数据采集部分
用户浏览物品的信息记录
用户Id
商品Id
商品类型
添加时间
userId
itemId
itemType
time
用户收藏物品的信息记录
用户Id
收藏商品的Id
收藏时间
userId
collerctId
collectTime
用户添加物品至购物车的信息记录
用户Id
添加至购物车的商品Id
添加时间
userId
cartId
cartTime
用户购买物品的信息记录
用户Id
购买的商品Id
添加时间
userId
consumeId
consumeTime
当用户进行如上的几个行为后,就产生对应的日志记录,将产生的日志文件里的内容合并到一个日志文件里,再用flume监控这个日志文件并上传到hdfs中。
注:这里是用flume监控每个日志产生的目录,每出现新的日志文件便上传到hdfs,还是合并到一个日志文件再上传到Hdfs还没有考虑好,先采用合并后上传的形式
2.flume配置
# 给agent组件起名
score_agent.sources = r2
score_agent.sinks = k2
score_agent.channels = c2
#监听文件
score_agent.sources.r2.type = exec
#配置监听文件路径
score_agent.sources.r2.command = tail -F /usr/local/flume1.8/test/recommend/score/score_test.log
score_agent.sources.r2.shell = /bin/bash -c
# 文件输出位置
score_agent.sinks.k2.type = hdfs
#HDFS路径,以年月日的形式存储,并且还有小时
score_agent.sinks.k2.hdfs.path = hdfs://ns/flume/recommend/score/%Y%m%d/%H
#上传文件的前缀
score_agent.sinks.k2.hdfs.filePrefix = events-
#是否按照时间滚动文件夹
score_agent.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
score_agent.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
score_agent.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
score_agent.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
score_agent.sinks.k2.hdfs.batchSize = 1000
#设置文件类型,可支持压缩
score_agent.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件,单位秒
score_agent.sinks.k2.hdfs.rollInterval = 600
#设置每个文件的滚动大小,设置为128M,单位是kb
score_agent.sinks.k2.hdfs.rollSize = 134217728
#文件的滚动与Event数量无关
score_agent.sinks.k2.hdfs.rollCount = 0
#最小冗余数
score_agent.sinks.k2.hdfs.minBlockReplicas = 1
# 使用内存保存数据
score_agent.channels.c2.type = memory
score_agent.channels.c2.capacity = 500000
score_agent.channels.c2.transactionCapacity = 600
# 绑定sources和sinks关联
score_agent.sources.r2.channels = c2
score_agent.sinks.k2.channel = c2
3.MapReduce
3.1pom.xml
org.apache.hadoop
hadoop-common
2.7.3
org.apache.hadoop
hadoop-client
2.7.3
org.apache.hadoop
hadoop-hdfs
2.7.3
org.apache.hadoop
hadoop-mapreduce-client-core
2.7.3
org.apache.hadoop
hadoop-mapreduce-client-jobclient
2.7.3
3.2 StartRun
import com.htkj.recommend.mapreduce.*;
import org.apache.hadoop.conf.Configuration;
import java.util.HashMap;
import java.util.Map;
public class StartRun {
public static void main(String[] args){
Configuration conf=new Configuration();
// conf.set("mapreduce.app-submission.corss-paltform", "true");
// conf.set("mapreduce.framework.name", "local");
Map paths = new HashMap();
//第一步 清洗数据 去重复
paths.put("CleanInput", "/test/recommend/input/");
paths.put("CleanOutput", "/test/recommend/output/clean");
//第二步 用户分组 用户对物品喜爱度的得分矩阵
paths.put("UserGroupingInput",paths.get("CleanOutput"));
paths.put("UserGroupingOutput","/test/recommend/output/user_grouping");
//第三步 物品计数 物品的同现矩阵
paths.put("ItemCountInput",paths.get("UserGroupingOutput"));
paths.put("ItemCountOutput","/test/recommend/output/item_count");
//第四步 计算物品的相似度 物品的相似矩阵
paths.put("SimilarityInput",paths.get("ItemCountOutput"));
paths.put("SimilarityOutput","/test/recommend/output/similarity");
//第五步 把相似矩阵与得分矩阵相乘 推荐矩阵
paths.put("ScoreInput1", paths.get("UserGroupingOutput"));
paths.put("ScoreInput2", paths.get("SimilarityOutput"));
paths.put("ScoreOutput", "/test/recommend/output/score");
//第六步 把相乘之后的矩阵相加 获得结果矩阵
paths.put("AllScoreInput", paths.get("ScoreOutput"));
paths.put("AllScoreOutput", "/test/recommend/output/all_score");
//第七步 排序 得到得分最高的十个物品
paths.put("ResultSortInput", paths.get("AllScoreOutput"));
paths.put("ResultSortOutput", "/test/recommend/output/result_sort");
// paths.put("CleanInput", "D:\\test\\user_bought_history.txt");
// paths.put("CleanInput", "D:\\test\\1.txt");
// paths.put("CleanOutput", "D:\\test\\test1");
// paths.put("UserGroupingInput",paths.get("CleanOutput")+"\\part-r-00000");
// paths.put("UserGroupingOutput","D:\\test\\test2");
// paths.put("ItemCountInput",paths.get("UserGroupingOutput")+"\\part-r-00000");
// paths.put("ItemCountOutput","D:\\test\\test3");
// paths.put("SimilarityInput",paths.get("ItemCountOutput")+"\\part-r-00000");
// paths.put("SimilarityOutput","D:\\test\\test4");
// paths.put("ScoreInput1", paths.get("UserGroupingOutput")+"\\part-r-00000");
// paths.put("ScoreInput2", paths.get("SimilarityOutput")+"\\part-r-00000");
// paths.put("ScoreOutput", "D:\\test\\test5");
// paths.put("AllScoreInput", paths.get("ScoreOutput")+"\\part-r-00000");
// paths.put("AllScoreOutput", "D:\\test\\test6");
// paths.put("ResultSortInput", paths.get("AllScoreOutput")+"\\part-r-00000");
// paths.put("ResultSortOutput", "D:\\test\\test7");
Clean.run(conf,paths);
UserGrouping.run(conf,paths);
ItemCount.run(conf,paths);
Similarity.run(conf,paths);
Score.run(conf,paths);
AllScore.run(conf,paths);
ResultSort.run(conf,paths);
}
public static Map action=new HashMap();
static {
action.put("click",1);//点击算1分
action.put("collect",2);//收藏算2分
action.put("cart",3);//加入购物车算3分
action.put("alipay",4);//支付算4分
}
}
3.3Clean
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Map;
public class Clean {
public static boolean run(Configuration config, Map paths){
try {
FileSystem fs=FileSystem.get(config);
Job job=Job.getInstance(config);
job.setJobName("Clean");
job.setJarByClass(Clean.class);
job.setMapperClass(CleanMapper.class);
job.setReducerClass(CleanReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job,new Path(paths.get("CleanInput")));
Path outpath=new Path(paths.get("CleanOutput"));
if (fs.exists(outpath)){
fs.delete(outpath,true);
}
FileOutputFormat.setOutputPath(job,outpath);
boolean f=job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
static class CleanMapper extends Mapper{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// String[] s = value.toString().split(" ");
// String time = s[0];
// String userId = s[1];
// String itemId = s[2];
// String values=userId+" "+itemId+" "+time;
// Text text = new Text(values);
//第一行不读 这里的第一行可以设置为表头
if (key.get()!=0){
context.write(value,NullWritable.get());
}
}
}
static class CleanReduce extends Reducer{
@Override
protected void reduce(Text key , Iterable i, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
}
3.4UserGrouping
import com.htkj.recommend.StartRun;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
/*
* 输入进来的数据集
* userId itemID action
* 1 100 click
* 1 101 collect
* 1 102 cart
* 1 103 alipay
*
* 输出的结果如下
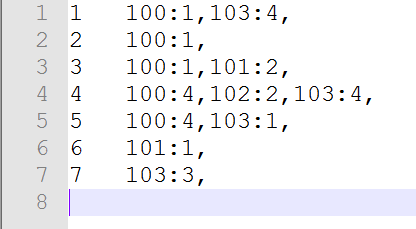
* userId itemID:分数
* 1 100:1,101:2,102:3,103:4,
* 2 100:1,101:1,102:1,103:4,
* 3 100:1,101:2,102:2,103:4,
* 4 100:4,101:2,102:2,103:4,
*/
public class UserGrouping {
public static boolean run(Configuration config , Map paths){
try {
FileSystem fs=FileSystem.get(config);
Job job=Job.getInstance(config);
job.setJobName("UserGrouping");
job.setJarByClass(StartRun.class);
job.setMapperClass(UserGroupingMapper.class);
job.setReducerClass(UserGroupingReduce.class);
job.setMapOutputValueClass(Text.class);
job.setMapOutputKeyClass(Text.class);
FileInputFormat.addInputPath(job,new Path(paths.get("UserGroupingInput")));
Path outpath=new Path(paths.get("UserGroupingOutput"));
if (fs.exists(outpath)){
fs.delete(outpath,true);
}
FileOutputFormat.setOutputPath(job,outpath);
boolean f=job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
static class UserGroupingMapper extends Mapper{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(" ");
String user = split[0];//1
String item = split[1];//100
String action = split[2];//click
Text k=new Text(user);//1
// Integer rv= StartRun.action.get(action); //click=1
Integer rv=4;
Text v=new Text(item+":"+ rv);//100:1
context.write(k,v);
/*
* userId itemId:分数
* 1 100:1
*/
}
}
static class UserGroupingReduce extends Reducer{
@Override
protected void reduce(Text key, Iterable i, Context context) throws IOException, InterruptedException {
Map map = new HashMap();
/*
* userId 1
* itmId:分数 100:1
* 101:2
* 102:3
* 103:4
*/
for (Text value : i) {
String[] split = value.toString().split(":");
String item = split[0];//101
// Integer action = Integer.parseInt(split[1]);//2
Integer action=4;
//如果 map集合中有itemId action=原来的分数+现在的action
//比如说 101物品 既点击 又收藏 又加入购物车 还购买了 那么101的分数就为1+2+3+4
if (map.get(item) != null) {
action = (Integer) map.get(item) + action;
}
map.put(item,action);//
}
StringBuffer stringBuffer = new StringBuffer();
for (Map.Entry entry:map.entrySet()){
stringBuffer.append(entry.getKey()+":"+ entry.getValue() +",");//100:1,
}
context.write(key,new Text(stringBuffer.toString()));//1 100:1,101:2,102:3,103:4,
}
}
}
3.5ItemCount
import com.htkj.recommend.StartRun;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Map;
/*
*对物品组合列表进行计数,建立物品的同现矩阵
*输入的数据集
* userId itemID:分数
* 1 100:1,101:2,102:3,103:4,
* 2 100:1,101:1,102:1,103:4,
* 3 100:1,101:2,102:2,103:4,
* 4 100:4,101:2,102:2,103:4,
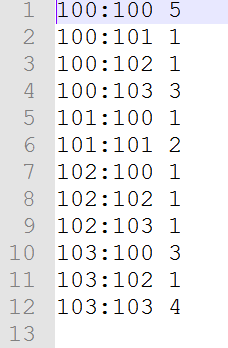
*itemA:itemB 次数
*100:100 7
*100:101 6
*100:102 6
*100:103 6
*101:100 6
*101:101 7
*101:100 6
*
* */
public class ItemCount {
private final static Text KEY=new Text();
private final static IntWritable VALUE=new IntWritable(1);
public static boolean run(Configuration config , Map paths){
try {
FileSystem fs=FileSystem.get(config);
Job job= Job.getInstance(config);
job.setJobName("ItemCount");
job.setJarByClass(StartRun.class);
job.setMapperClass(ItemCountMapper.class);
job.setReducerClass(ItemCountReduce.class);
job.setCombinerClass(ItemCountReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path(paths.get("ItemCountInput")));
Path outpath=new Path(paths.get("ItemCountOutput"));
if (fs.exists(outpath)){
fs.delete(outpath,true);
}
FileOutputFormat.setOutputPath(job,outpath);
boolean f = job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
static class ItemCountMapper extends Mapper{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
/*
* userId itemID:分数
* 1 100:1,101:2,102:3,103:4,
* */
String[] s = value.toString().split("\t");
String[] items = s[1].split(",");//[100:1 101:2 102:3 103:4]
for (int i = 0; i < items.length; i++) {
String itemA = items[i].split(":")[0];//100
for (int j = 0; j < items.length; j++) {
String itemB = items[j].split(":")[0];//第一次是100 第二次是101
KEY.set(itemA+":"+itemB);//第一次 100:100 第二次100:101
context.write(KEY,VALUE);//第一次 100:100 1 第二次100:101 1
}
}
}
}
static class ItemCountReduce extends Reducer{
@Override
protected void reduce(Text key, Iterable i, Context context) throws IOException, InterruptedException {
int sum=0;
for (IntWritable v : i) {
sum=sum+v.get();
}
VALUE.set(sum);
context.write(key,VALUE);
}
}
}
3.6Similarity
import com.htkj.recommend.StartRun;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class Similarity {
private static Map map=new HashMap();
private static Map countMap=new HashMap();
public static boolean run(Configuration config , Map paths){
try {
FileSystem fs=FileSystem.get(config);
Job job=Job.getInstance(config);
job.setJobName("Similarity");
job.setJarByClass(StartRun.class);
job.setMapperClass(SimilarityMapper.class);
job.setReducerClass(SimilarityReduce.class);
job.setMapOutputValueClass(Text.class);
job.setMapOutputKeyClass(Text.class);
FileInputFormat.addInputPath(job,new Path(paths.get("SimilarityInput")));
Path outpath=new Path(paths.get("SimilarityOutput"));
if (fs.exists(outpath)){
fs.delete(outpath,true);
}
FileOutputFormat.setOutputPath(job,outpath);
boolean f=job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
static class SimilarityMapper extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] s = value.toString().split("\t");
String item = s[0];
String count = s[1];
Text k = new Text(item);
Text v = new Text(item+"\t"+count);
context.write(k,v);
}
}
static class SimilarityReduce extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
for (Text line : values) {
String[] s = line.toString().split("\t");
String item = s[0];
int count = Integer.parseInt(s[1]);
int itemA = Integer.parseInt(item.split(":")[0]);
int itemB = Integer.parseInt(item.split(":")[1]);
if (itemA==itemB){
countMap.put(itemA,count);
}
map.put(item,s[1]);
}
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
Iterator iterator = map.keySet().iterator();
double weight=0.5;//weight的范围是[0.5,1],提高weight,就可以惩罚热门物品itemb
while (iterator.hasNext()){
String item = iterator.next();
Integer count = Integer.valueOf(map.get(item));
int itemA = Integer.parseInt(item.split(":")[0]);
int itemB = Integer.parseInt(item.split(":")[1]);
if (itemA!=itemB){
Integer countA = countMap.get(itemA);
Integer countB = countMap.get(itemB);
double valueA = Math.pow(countA, 1 - weight);
double valueB = Math.pow(countB, weight);
double value=count/(valueA*valueB);
value = (double) Math.round(value * 100) / 100;
Text k = new Text(item);
Text v = new Text(String.valueOf(value));
context.write(k,v);
}
}
}
}
}
3.7Score
import com.htkj.recommend.StartRun;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
/*
*把物品的同现矩阵和用户的得分矩阵相乘
*输入的数据集 物品的同现矩阵A
*itemA:itemB 次数
*100:100 7
*100:101 6
*100:102 6
*100:103 6
*101:100 6
*101:101 7
*101:100 6
* 输入的数据集 用户的得分矩阵B
* userId itemID:分数
* 1 100:1,101:2,102:3,103:4,
* 2 100:1,101:1,102:1,103:4,
* 3 100:1,101:2,102:2,103:4,
* 4 100:4,101:2,102:2,103:4,
* */
public class Score {
public static boolean run(Configuration config, Map paths) {
try {
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJobName("Score");
job.setJarByClass(StartRun.class);
job.setMapperClass(ScoreMapper.class);
job.setReducerClass(ScoreReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
Path[] inputPaths = {new Path(paths.get("ScoreInput1")), new Path(paths.get("ScoreInput2"))};
FileInputFormat.setInputPaths(job,inputPaths);
Path outpath = new Path(paths.get("ScoreOutput"));
if (fs.exists(outpath)) {
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath);
boolean f = job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
static class ScoreMapper extends Mapper{
private String flag;//A 同现矩阵 B得分矩阵
@Override
protected void setup(Context context){
FileSplit split= (FileSplit) context.getInputSplit();
flag=split.getPath().getParent().getName();//判断读的数据集
// System.out.println(flag+"-------------------");
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] s = value.toString().split("\t");
if (flag.equals("similarity")){//相似矩阵 //test4 similarity
/*
* itemA:itemB 次数
* 100:101 6
* */
String[] split = s[0].split(":");
String item1 = split[0];//100
String item2 = split[1];//101
String num = s[1];//6
Text k = new Text(item1);//100
Text v = new Text("A:" + item2 + "," + num);//A:101,6
context.write(k,v);//100 A:101,6
}else if (flag.equals("user_grouping")){//得分矩阵 //test2 user_grouping
/*
* userId itemID:分数
* 1 100:1,101:2,102:3,103:4,
*/
String userId = s[0];//1
String[] vector = s[1].split(",");//[100:1 101:2 102:3 103:4]
for (int i = 0; i < vector.length; i++) {
String[] split = vector[i].split(":");
String itemId=split[0];//i=0时 100
String score = split[1];//1
Text k = new Text(itemId);//100
Text v = new Text("B:" + userId + "," + score);//B:1,1
context.write(k,v);//100 B:1,1
}
}
}
}
static class ScoreReduce extends Reducer{
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
Map mapA=new HashMap();//基于物品的同现矩阵A
Map mapB=new HashMap();//基于用户的得分矩阵B
for (Text line : values) {
String s = line.toString();
if (s.startsWith("A:")){// A:101,6
String[] split =s.substring(2).split(",");
try {
mapA.put(split[0],Double.valueOf(split[1]));//101 6(itemId num)
}catch (Exception e){
e.printStackTrace();
}
}else if (s.startsWith("B:")){//B:1,1
String[] split = s.substring(2).split(",");
try {
mapB.put(split[0],Integer.valueOf(split[1]));//1 1(userId score)
}catch (Exception e){
e.printStackTrace();
}
}
}
double result=0;
Iterator iter = mapA.keySet().iterator();//基于物品的同现矩阵A
while (iter.hasNext()){
String mapkey = iter.next();//itemId 101
Double num = mapA.get(mapkey);//num 6
Iterator iterB = mapB.keySet().iterator();//基于用户的得分矩阵B
while (iterB.hasNext()){
String mapBkey = iterB.next();//userId 1
int socre = mapB.get(mapBkey);//score 1
result=num*socre;//矩阵乘法相乘 6*1=6
Text k = new Text(mapBkey);//userId 1
Text v = new Text(mapkey + "," + result);//101,6
context.write(k,v);//1 101,6
}
}
}
}
}
3.8AllScore
import com.htkj.recommend.StartRun;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class AllScore {
public static boolean run(Configuration config, Map paths){
try {
FileSystem fs=FileSystem.get(config);
Job job=Job.getInstance(config);
job.setJobName("AllScore");
job.setJarByClass(StartRun.class);
job.setMapperClass(AllScoreMapper.class);
job.setReducerClass(AllSCoreReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job,new Path(paths.get("AllScoreInput")));
Path outpath=new Path(paths.get("AllScoreOutput"));
if (fs.exists(outpath)){
fs.delete(outpath,true);
}
FileOutputFormat.setOutputPath(job,outpath);
boolean f=job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
static class AllScoreMapper extends Mapper{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] s = value.toString().split("\t");
String userId = s[0];
String[] split = s[1].split(",");
String itemId = split[0];
String score = split[1];
Text k = new Text(userId);
Text v = new Text(itemId + "," +score);
context.write(k,v);
}
}
static class AllSCoreReduce extends Reducer{
@Override
protected void reduce(Text key, Iterable values , Context context) throws IOException, InterruptedException {
Map map=new HashMap();
for (Text line : values) {
String[] split = line.toString().split(",");
String itemId = split[0];
Double score = Double.parseDouble(split[1]);
if (map.containsKey(itemId)){
map.put(itemId,map.get(itemId)+score);//矩阵乘法求和计算
}else {
map.put(itemId,score);
}
}
Iterator iter=map.keySet().iterator();
while (iter.hasNext()){
String itemId = iter.next();
Double score = map.get(itemId);
Text v = new Text(itemId + "," + score);
context.write(key,v);
}
}
}
}
3.9ResultSort
import com.htkj.recommend.StartRun;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.Map;
public class ResultSort {
private final static Text K = new Text();
private final static Text V = new Text();
public static boolean run(Configuration config, Map paths){
try {
FileSystem fs=FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJobName("ResultSort");
job.setJarByClass(StartRun.class);
job.setMapperClass(ResultSortMapper.class);
job.setReducerClass(ResultSortRduce.class);
job.setSortComparatorClass(SortNum.class);
job.setGroupingComparatorClass(UserGroup.class);
job.setMapOutputKeyClass(SortBean.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(paths.get("ResultSortInput")));
Path outpath = new Path(paths.get("ResultSortOutput"));
if (fs.exists(outpath)){
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath);
boolean f = job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
static class SortBean implements WritableComparable{
private String userId;
private double num;
public int compareTo(SortBean o) {
int i = this.userId.compareTo(o.getUserId());
if (i==0){
return Double.compare(this.num,o.getNum());
}
return i;
}
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(userId);
dataOutput.writeDouble(num);
}
public void readFields(DataInput dataInput) throws IOException {
this.userId=dataInput.readUTF();
this.num=dataInput.readDouble();
}
public String getUserId(){
return userId;
}
public void setUserId(String userId){
this.userId=userId;
}
public double getNum(){
return num;
}
public void setNum(double num){
this.num=num;
}
}
static class UserGroup extends WritableComparator{
public UserGroup(){
super(SortBean.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b ){
SortBean o1=(SortBean)a;
SortBean o2=(SortBean)b;
return o1.getUserId().compareTo(o2.getUserId());
}
}
static class SortNum extends WritableComparator{
public SortNum(){
super(SortBean.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b){
SortBean o1=(SortBean)a;
SortBean o2=(SortBean)b;
int i = o1.getUserId().compareTo(o2.getUserId());
if (i==0){
return -Double.compare(o1.getNum(), o2.getNum());
}
return i;
}
}
static class ResultSortMapper extends Mapper{
@Override
protected void map(LongWritable key, Text value , Context context) throws IOException, InterruptedException {
String[] s = value.toString().split("\t");
String userId = s[0];
String[] split = s[1].split(",");
String itemId = split[0];
String score = split[1];
SortBean k = new SortBean();
k.setUserId(userId);
k.setNum(Double.parseDouble(score));
V.set(itemId+":"+score);
context.write(k,V);
}
}
static class ResultSortRduce extends Reducer{
@Override
protected void reduce(SortBean key, Iterable values, Context context) throws IOException, InterruptedException {
int i=0;
StringBuffer stringBuffer = new StringBuffer();
for (Text v : values) {
if (i==10){break;}
stringBuffer.append(v.toString()+",");
i++;
}
K.set(key.getUserId());
V.set(stringBuffer.toString());
context.write(K,V);
}
}
}
4.本地模式下的测试
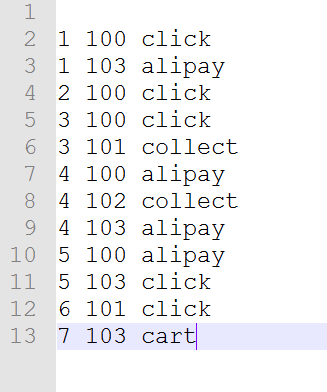
4.1测试数据集1
4.2各阶段输出结果
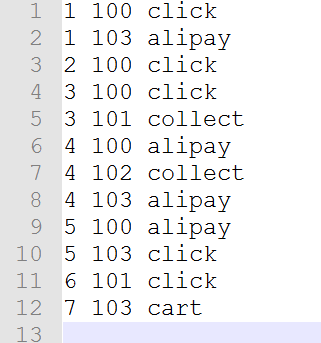
4.2.1 Clean
4.2.2UserGrouping
4.2.3ItemCount
4.2.4Similarity

4.2.5Score

4.2.6AllScore

4.2.7ResultSort

5.在Linux下运行
5.1将项目打成jar包
目录选择到src下即可
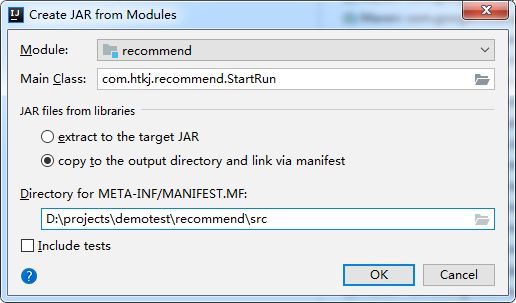
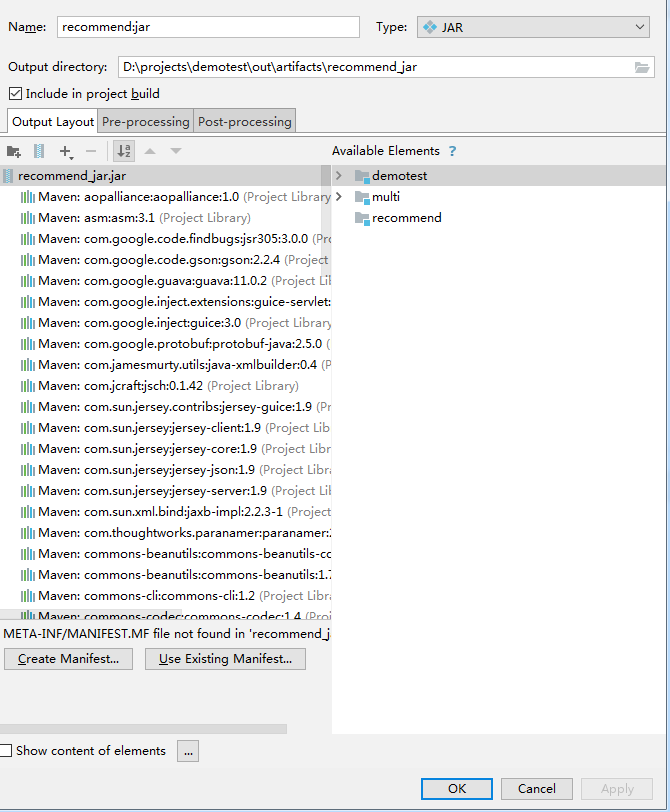
编译好后找到Jar包文件,打开并找到其中的recommend.jar,将其解压后上传到Linux下
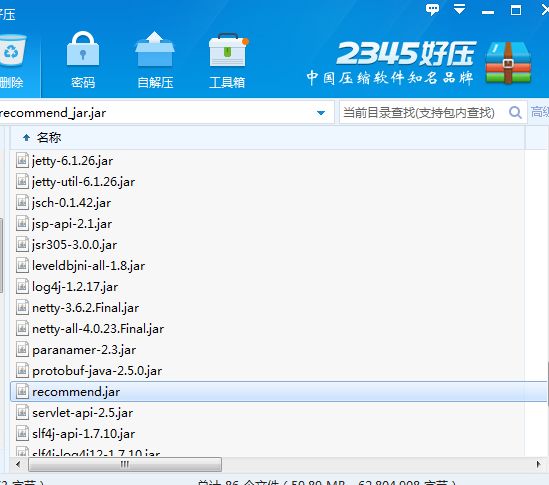
运行
命令:hadoop jar recommend.jar
这个命令后面是写main的参数,一般是指定文件输入的地址,但是在这里因为已经设置了地址,所以不用写
后期可能通过设置定时任务,每天定时分析一次,可以将指定的输入地址改成由main方法的参数指定
6.关于测试
如何判断程序的准确性?
可以通过简单的数据集来手动计算矩阵,看看计算的结果是否一致
如何知道推荐的准不准
可以设置极端的数据集来进行检验,比如说1号用户买了编号为100的商品,其他用户买编号100的商品的同时都买了编号103的商品
看最后的推荐结果有无103商品
7.一些注意事项
协同过滤算法要求的矩阵是稀疏矩阵,也就是说总有商品列表是空着的没买
这也很好理解,用户不能把所有的商品都看了,或者进行了其他的行为操作,要不然还推荐什么呢?