Python高级编程(深度学习) 04-卷积神经网络图像分类
计算机视觉
- 眼睛不等于视觉
- 摄像机不等于视觉
- 单个像素只有一个颜色信息,不表示任何复杂语义
传统图像特征举例:HOG
- 方向梯度直方图

传统图像特征举例:LBP
- 局部二值模式(以中间的值作为阈值,若像素值高于阈值则设置为1低于则为0)

图像分类任务
- 怎么区分鱼和自行车?
- 有效描述图像内容(像素图像比较无效)
- 找出区分鱼和自行车的关键信息(比如不能通过鱼有眼睛来区分,自行车上挂一个小黄人也是有眼睛的)
- 逻辑分类
卷积(Convolution)
- 对于一个有噪声的函数y=f(x),使用一个核(kernel)函数k(n)对其进行滤波
- 形象描述:滚动式的加权平均
离散二维卷积


计算方法就是3*3的模板一直移动,模板框出来的数字和卷积核对应相乘然后相加得到对应的值,在没有增加padding 的情况下,获得的输出的大小是(width-2,height-2)
- 图中的卷积核可以用来检测边缘。
- 对图像进行三维卷积运算,得到特征图。
- 卷积核是可训练参数。
- 卷积沟通了临近像素,一二增加了视野。
- 当图像内容与卷积核形状吻合的时候,激活度会很高,因而是一个特征提取器。
- 输出特征图的通道数等于使用的卷积核个数。
padding
- 使用padding可以对图像进行填充,使得卷积后的图像大小不变。
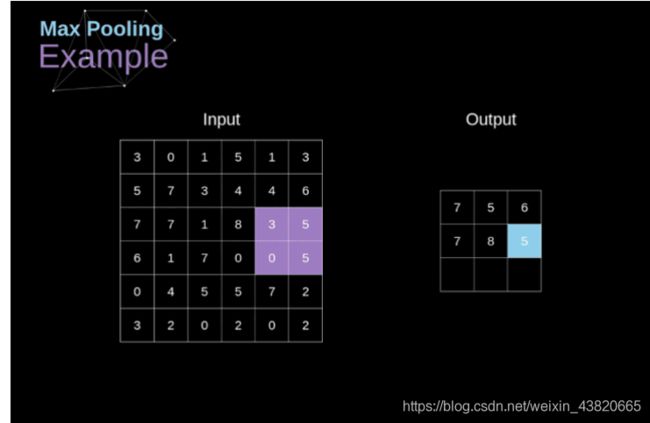
池化
- 池化是模板在输入图像上不断移动,模板框中的最大像素值输出,最后形成一个矩阵。
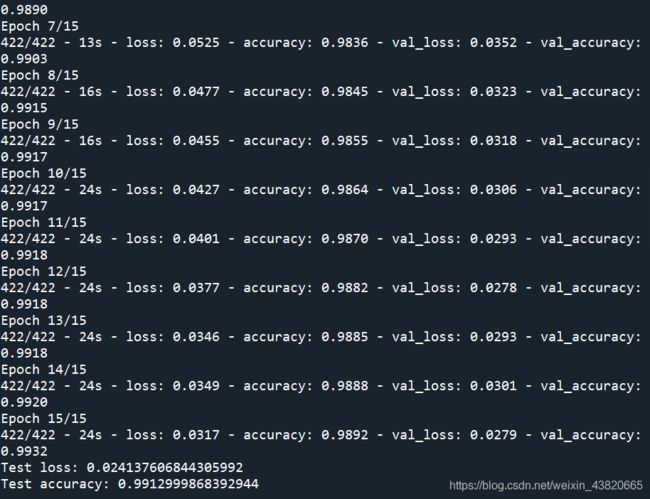
例题:MNIST手写数字识别
用卷积神经网络去构建模型,解决手写数字识别的问题。
这里就放构建模型的部分,如果需要把模型进行识别,用一下predict。
import numpy as np
#import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
#读取数据
def load_mnist(): #读取离线的MNIST.npz文件。
path = r'mnist.npz' #放置mnist.py的目录,这里默认跟本代码在同一个文件夹之下。
f = np.load(path)
x_train, y_train = f['x_train'], f['y_train']
x_test, y_test = f['x_test'], f['y_test']
f.close()
return (x_train, y_train), (x_test, y_test)
(x_train, y_train), (x_test, y_test) = load_mnist()
#数据预处理
# Scale images to the [0, 1] range
x_train = x_train.astype("float32") / 255 #实现变量类型转化并进行归一化
x_test = x_test.astype("float32") / 255
# Make sure images have shape (28, 28, 1)
x_train = np.expand_dims(x_train, -1) #把(28,28)扩展成(28,28,1)其中1为通道数,这样的转化是为后续的卷积做准备
x_test = np.expand_dims(x_test, -1)
print("x_train shape:", x_train.shape)
print(x_train.shape[0], "train samples")
print(x_test.shape[0], "test samples")
# convert class vectors to binary class matrices
num_classes = 10
y_train = keras.utils.to_categorical(y_train, num_classes) #label转成onehot编码
y_test = keras.utils.to_categorical(y_test, num_classes)
#构建模型
input_shape = (28, 28, 1)
model = keras.Sequential(
[
keras.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"), #二维卷积,其中卷积核为32个,每个卷积核是3*3的尺寸,卷积是将3*3的模板在图上移动,模板中9个像素值和框中的9个像素值相乘相加得到一个数值,从而生成(width-2,height-2)的矩阵,(没有设置padding的情况下)
layers.MaxPooling2D(pool_size=(2, 2)), #池化,即2*2的模板在图上移动,将模板中4个像素值最大的那个提取出来形成一个(width/2,height/2)的矩阵
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(), #把输入的向量压平,多维输入转成一维输出
layers.Dropout(0.5), #缓解过拟合
layers.Dense(num_classes, activation="softmax"),
]
)
model.summary() #输出参数各层情况
#训练
batch_size = 128
epochs = 20 #训练次数,训练15次结果约为0.9903,训练20次结果约为0.9905,训练150结果约为0.993
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1,verbose=2) #validation_split从数据集中切分出10%作为val验证集
#测试
score = model.evaluate(x_test, y_test, verbose=0)
print("Test loss:", score[0])
print("Test accuracy:", score[1])