2.数据挖掘:需要了解的数学知识
1.线性代数
瑞典数学家Lars Garding在Encounter with Mathematics一书中说:“如果不熟悉线性代数的概念,要去学习自然科学,现在看来就和文盲差不多。”
线性代数,概率论、统计学和微积分是数据挖掘用于表述的“语言”。学习这些数学知识将有助于深入理解底层算法机制,便于开发新算法。
在互联网大数据中,许多应用场景的分析对象(待处理的非结构化数据)都需要换成离散的矩阵或向量形式,例如,大量用户信息、文本中文本与词汇的关系等等都可以用矩阵表示。
线性代数主要研究矩阵与向量、用于处理线性关系。线性关系是指数学对象之间的关系是以一次形式来表达的。线性代数需要解决的第一个问题就是求解线性方程组。
1.1行列式
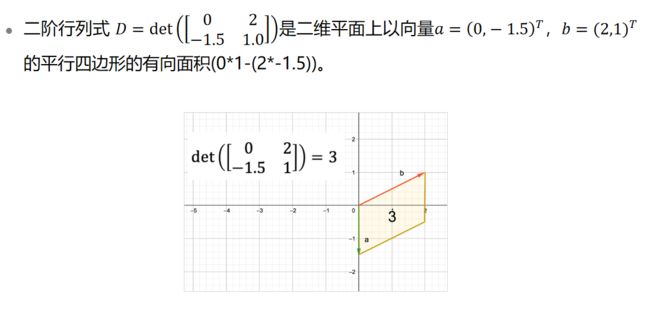
行列式是一个将方阵映射到一个标量的函数,记作det(A)或|A|。行列式也可以看作是有向面积或体积在一般欧几里得空间的推广。或者说是在n维欧几里得空间中,行列式描述的是一个线性变换对“体积”所造成的影响。
行列式的意义
行列式等于矩阵特征值的乘积。
行列式的绝对值可以用来衡量矩阵参与矩阵乘法后空间扩大或缩小了多少。
行列式的正负表示空间的定向。
行列式的应用:求矩阵特征值,求解线性方程等。
1.1.1行列式计算
二阶行列式
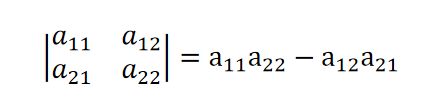
三阶行列式
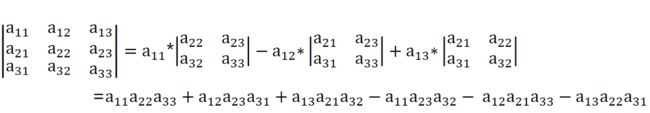
容易看出:右边的每一项都是2个或3个元素的乘积,且这些元素位于不同的列、不同的行。
1.1.2行列式的几何意义
1.2矩阵

1.2.1矩阵的运算
矩阵加法:设A=(a_ij)_s×n,B=(b_ij)_s×n都是数域K上的s×n矩阵,矩阵的和定义为C=A+B=(a_ij+b_ij)_s×n。
注:只有矩阵A、B的行列数一样,两矩阵才可以相加。
标量和矩阵乘法:设A=(a_ij)_s×n,k∈K,k与矩阵A的乘积定义为kA=(ka_ij)_s×n。标量与矩阵相加同理。
矩阵乘法:若矩阵A=(a_ij)_s×n,B=(b_ij)_n×p,则C=AB=(c_ij)_s×p, 其中C_i,j=∑_k▒A_i,kB_k,j,即C_i,j等于矩阵A第i行的所有元素与矩阵B第j列的所有元素一 一对应相乘再相加。
注:矩阵A的列数必须和矩阵B的行数相等,AB才有意义。
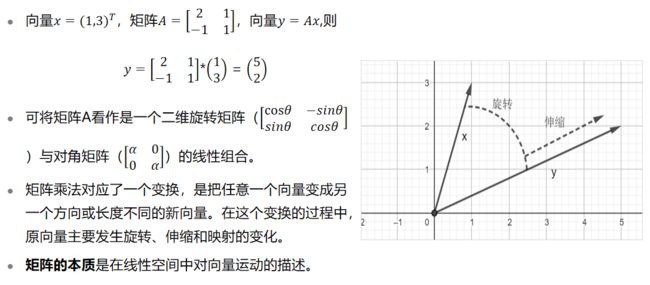
1.2.2矩阵与向量运算
1.2.3矩阵的转置

1.2.4单位矩阵和逆矩阵

1.2.5对角矩阵

1.2.6对称矩阵

1.2.7案例

1.3矩阵分解
1.3.1特征值分解
特征分解是使用最广的矩阵分解之一,即我们通过将方阵分解成一组特征向量和特征值乘积的方法来发现矩阵表示成数组元素时不明显的函数性质。
设A是数域K上的n级矩阵,如果K^n中有非零列向量α使得
Aα=λα,且λϵK,
则称λ是A的一个特征值,称α是A的属于特征值λ的一个特征向量。
例如:

因此,2是A的一个特征值,α是A的属于特征值2的一个特征向量。
怎样求矩阵A的特征值与特征向量:
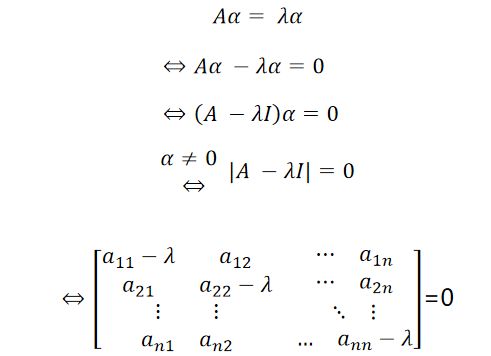
其中,|A−λI|=0称为矩阵A的特征方程,λ为特征方程的解,即特征根,将特征根λ代入Aα=λα即可求得特征向量α。
例如:

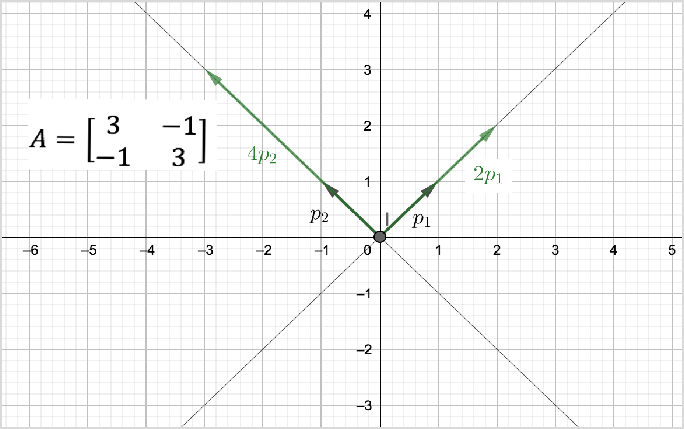
如之前所说,矩阵乘法是对向量进行旋转、压缩。如图所示,如果矩阵作用于某一个向量或某些向量使这些向量只发生伸缩变换,不对这些向量产生旋转及投影的效果,那么这些向量就称为这个矩阵的特征向量,伸缩的比例就是特征值。
设A有n个线性无关的特征向量α_1,α_2,⋯,α_n,相对应的特征值为λ_1,λ_2,⋯,λ_n,则A的特征分解为:
A=Pdiag(λ)P^−1,
其中P={α_1,α_2,⋯,α_n},λ={λ_1,λ_2,⋯,λ_n}。
奇异值分解:将矩阵分解为奇异向量和奇异值。可以将矩阵A=(a_ij)_m×n分解为三个矩阵的乘积:A=UΣV^T, 其中U=(b_ij)_m×m,Σ=(c_ij)_m×n,V^T=(d_ij)_n×n。
矩阵U和V都为正交矩阵,矩阵U的列向量称为左奇异向量,矩阵V的列向量称为右奇异向量,Σ为对角矩阵(不一定为方阵),Σ对角线上的元素称为矩阵A的奇异值,奇异值按从大到小的顺序排列。
1.3.2特征值分解应用
从线性空间的角度看,特征值越大,则矩阵在对应的特征向量上的方差越大,信息量越多。
在最优化中,矩阵特征值的大小与函数值的变化快慢有关,在最大特征值所对应的特征方向上函数值变化最大,也就是该方向上的方向导数最大。
在数据挖掘中,最大特征值对应的特征向量上包含最多的信息量。如果某几个特征值很小,说明这个方向上的信息量很小,可以用来降维的算法删除小特征值对应方向的数据,只保留大特征值方向对应的数据,这样做可以减少数据量,同时保留有用信息。
1.3.3奇异值分解
奇异值分解:将矩阵分解为奇异向量和奇异值。可以将矩阵A=(a_ij)_m×n分解为三个矩阵的乘积:
A=UΣV^T,
其中U=(b_ij)_m×m,Σ=(c_ij)_m×n,V^T=(d_ij)_n×n。矩阵U和V都为正交矩阵,矩阵U的列向量称为左奇异向量,矩阵V的列向量称为右奇异向量,Σ为对角矩阵(不一定为方阵),Σ对角线上的元素称为矩阵A的奇异值,奇异值按从大到小的顺序排列。
1.3.4奇异值分解应用
在机器学习和数据挖掘领域,有很多的应用都与奇异值相关,比如做特征减少的主成分分析(PCA)和线性判别分析(LDA),数据压缩(以图像压缩为代表)算法,还有做搜索引擎语义层次检索的LSI(Latent semantic indexing)。
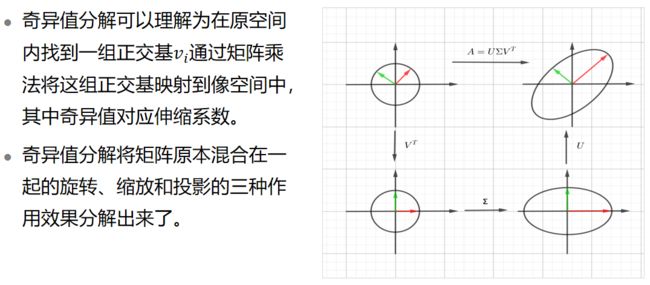
1.3.5奇异值分解的几何意义

1.3.6特征值分解和奇异值分解的区别
奇异值分解适用于所有矩阵;特征值分解只适用于方阵。
特征值分解和奇异值分解都是给一个矩阵找一组特殊的基,特征值分解找到了特征向量这组基,在这组基下该变换只有缩放效果。而奇异值分解则是一组基,将变换的旋转、缩放、投影三种功能独立地展示出来。
奇异值都是非负的,而特征值可能是负的。
1.4线性变换

1.5向量空间
设V为n维空间向量的集合,如果集合V非空,且集合V对于向量的加法及乘法两种算法封闭,那么就称集合V为向量空间。
所谓封闭,是指在集合V中可以进行向量的加法 及乘法两种运算。具体地说,就是:若a∈V,b∈V,则a+b∈V;若a∈V,λ∈V,则 λa∈V。
例如,三维向量全体ℝ^3,就是一个向量空间。这个空间用于装载全体三维向量且空间对于三维向量的加法和乘法封闭,即任意两个三维向量之和仍是三维向量,数λ乘以三维向量也仍然是三维向量。类似地,n维向量全体ℝ^n,也是一个向量空间。不过当n大于3后,它就没有直接的几何意义了。
2.概率论与数理统计
2.1概率论与数据挖掘
2.1.1基本概念
数据挖掘是在海量的数据中归纳、总结、分析数据的内在规律,概率论与数理统计是研究数据分布与如何处理数据的学科,在数据挖掘中的应用提高了数据挖掘的精度与效率。
举例:
大数据都有高维特征,在高维空间中进行数据模型的设计分析就需要一定的多维随机变量及其分布方面的基础。
贝叶斯定理是分类器构建的基础之一。
条件随机场、隐马尔科夫模型等在大数据分析中可用于对词汇、文本的分析,可以用于构建预测分类模型。
2.1.2随机实验
满足以下三个特点的试验称为随机试验:
可以在相同的条件下重复进行。
每次试验的可能结果不止一个,并且能事先明确试验的所有可能结果。
进行一次试验之前不能确定哪一个结果会出现。
举例:
E_1:抛两枚硬币,出现正面H、反面T的情况。
E_2:抛一枚骰子,观察可能出现的点数情况。
2.1.3样本点、样本空间、随机事件
样本点(sample point):随机试验的每一个可能的结果称为样本点,用e表示。
样本空间(sample space):随机试验E的所有可能结果组成的集合,记作S,即S={e_1,e_2,…,e_n}。
随机事件(random variables events):样本空间S的任一子集A。属于事件A的样本点出现,则称事件A发生。特别的,仅含一个样本点的随机事件,称为基本事件。
举例:
随机试验E_2:抛一枚骰子,观察可能出现的点数情况。
样本空间为:S={1,2,3,4,5,6}
样本点为:e_i=1,2,3,4,5,6
随机事件A_1:“骰子出现的点数为5”,即A_1={x│x=5}
2.1.4频率与概率
频率:在相同的条件下,进行n次试验,在这n次试验中,事件A发生的次数n_A称为事件A发生的频数。比值n_A/n称为事件A发生的概率,并记成f_n(A)。
概率:设E是随机试验,S是其样本空间。对于E的每一事件A赋予一个实数,记为P(A),称为事件A的概率,如果集合函数P(∗),满足下列条件:
非负性:对于每一个事件A,有0≤P(A)≤1。
规范性:对于必然事件S,有P(S)=1。
可列可加性:设A_1,A_2,…是两两互不相容的事件,即对于A_iA_j=∅,i≠j,i,j=1,2,⋯,有P(A_1∪A_2∪…)=P(A_1)+P(A_2)+…
概率是理想值,频率是实验值。例如,扔5次硬币,4正1反。出现正面的频率为0.8,但出现正面的概率为0.5。
2.2随机变量及其分布
随机变量(random variable): 表示随机试验各种结果的实值单值函数。
举例1:随机试验E_1:抛两枚骰子,观察可能出现的点数的和。试验的样本空间是S={e}={(i,j)|i,j=1,2,3,4,5,6},i,j分别是第1次,第2次出现的点数,以X记为两球号码之和,则X 是一个随机变量。
X=X(e)=X(i,j)=i+j,i,j=1,2,⋯,6
举例2:随机试验E_2:抛两枚硬币,出现正面、反面的情况。试验的样本空间是S={HH,HT,TH,TT},以Y记为两次投掷硬币得到反面T的总数,则Y是一个随机变量。
2.2.1 离散型随机变量及其分布
离散型随机变量:随机变量的全部可能取到的值是有限个或可列无限多个。如记录某监控卡口在1分钟内通过的车辆数目。
分布律:设离散型随机变量X的所有可能取值为x_k(k=1,2,⋯),X取各个可能值的概率,即事件{X=x_k}的概率,为
P{X=x_k}=p_k,k=1,2,⋯。
由概率的定义,p_k满足如下两个条件:
(1)p_k≥0,k=1,2,⋯。
(2)∑_k=1^∞▒p_k=1。
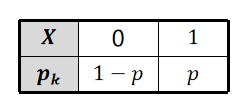
分布律也可以用表格的形式来表示:

2.2.2特殊离散分布 - 伯努利分布
伯努利分布(0-1分布,两点分布,a-b分布):设随机变量X只可能取0与1两个值,它的分布律是:
P{X=k}=p^k(1−p)^1−k,k=0,1 (0
则称X服从以p为参数的伯努利分布。
伯努利分布的分布律也可以写成:
其中,E(X)=p,Var(X)=p(1−p)。
伯努利分布主要用于二分类问题。
2.2.3特殊离散分布 - 二项分布
n次独立重复试验:将实验E重复进行n次,若各次试验的结果互不影响,则称这n次实验是相互独立的。
满足如下条件的试验称为n重伯努利试验:
每次实验都在相同的条件下重复进行。
每次试验只有两个可能的结果:A及A ̅且P(A)=p。
每次试验的结果相互独立。
若用X表示n重伯努利试验中事件A发生的次数,则n次试验中事件A发生k次的概率为:
P(X=k)=C_n^kp^k(1−p)^n−k,k=0,1,2,⋯n,
此时称X服从参数为n,p的二项分布,记为X~B(n,p)。其中E(X)=np,Var(x)=np(1−p)。
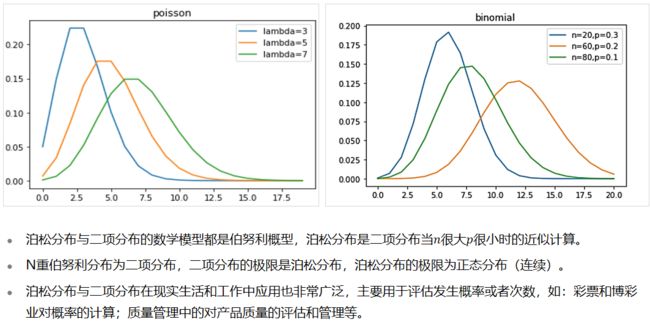
2.2.4 特殊离散分布 - 泊松分布

2.2.5泊松分布与二项分布的关系与应用
2.2.6连续型随机变量与概率密度函数

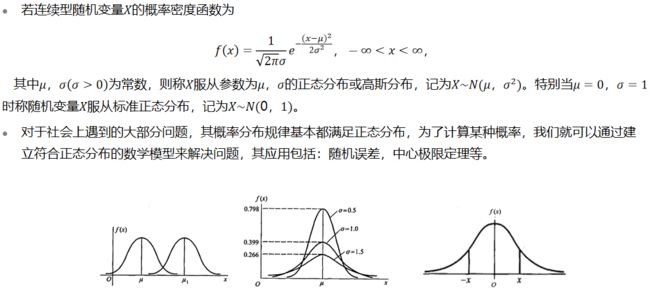
2.2.7 特殊分布 - 正态分布
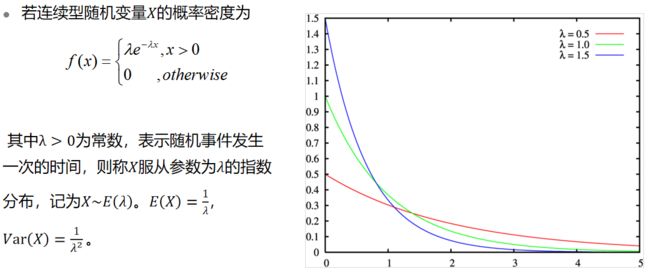
2.2.8特殊分布 - 指数分布
2.3随机向量及其分布
在实际应用中,经常需要对所考虑的问题用多个变量来描述。我们把多个随机变量放在一起组成向量,称为多维随机变量或者随机向量
定义:如果X_1(ω),X_2(ω),…,X_n(ω)是定义在同一个样本空间Ω={ω}上的n个随机变量,则称
X(ω)= (X_1(ω),X_2(ω),…,X_n(ω))为n维(或n元)随机变量或随机向量。
举例1:对每个家庭(样本点ω)在衣食住行四个方面的支出研究,若用X_1(ω),X_2(ω),X_3(ω),X_4(ω)分别表示衣食住行的花费占其家庭总收入的百分比,则(X_1(ω),X_2(ω),X_3(ω),X_4(ω))就是一个4维的随机变量或随机向量。
2.3.1联合分布函数
对任意的n个实数x_1,x_2, …,x_n,则n个事件{X_1≤x_1} ,{X_2≤x_2},…,{X_n≤x_n}同时发生的概率为
F(x_1,x_2, …,x_n)=P(X_1≤x_1,X_2≤x_2,…,X_n≤x_n)
称为n维随机变量的联合分布函数。
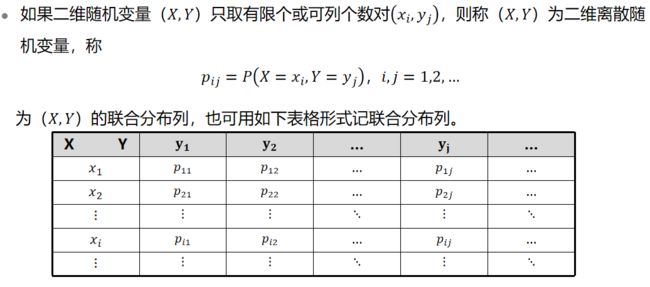
联合分布列
联合概率密度

2.3.2 二元正态分布
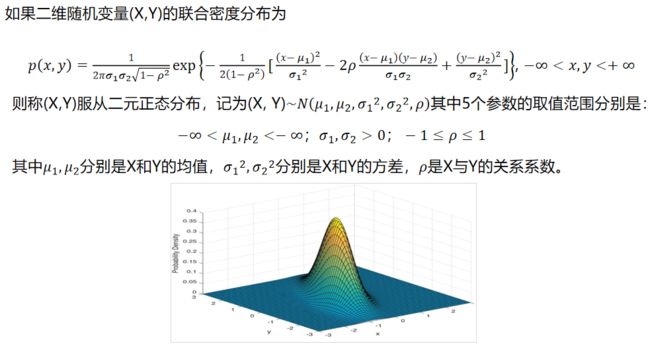
2.3.3条件概率、贝叶斯公式
如果某人出门之前听到新闻说路上出了个交通事故,那么堵车的概率,即P(堵车|交通事故),被叫做条件概率也叫后验概率:
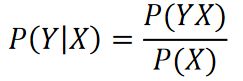
我们经常需要在已知P(Y|X)的情况下计算P(X|Y),此时若还知道P(X),我们可以用贝叶斯公式来计算:
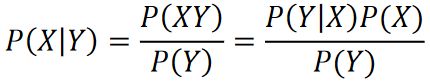
假设X是由相互独立的事件组成的概率空间{X_1,X_2,…,X_n},则P(Y)可以用全概率公式展开:P(Y)=P(Y│X_1)P(X_1)+P(Y│X_2)P(X_2)+…+P(Y│X_n)P(X_n),此时贝叶斯公式可表示为:
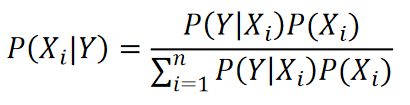
条件概率的链式法则:
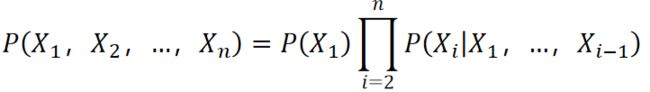
条件概率和贝叶斯公式主要用于朴素贝叶斯算法。
例:

2.3.4独立性和条件独立
两个随机变量X和Y,若对于所有x,y有
P(X=x,Y=y)=P(X=x)P(Y=y),
则称随机变量X和Y是相互独立的,记作X⊥Y。
如果关于X和Y的条件概率对于Z的每一个值有
P(X=x,Y=y|Z=z)=P(X=x|Z=z)P(Y=y|Z=z),
则称随机变量X和Y在给定随机变量Z时是条件独立的,记作X⊥Y|Z 。
2.4随机变量的数字特征
2.4.1期望、方差
数学期望(或均值,亦简称期望):是试验中每次可能结果的概率乘以其结果的总和,是最基本的数学特征之一。它反映随机变量平均取值的大小。
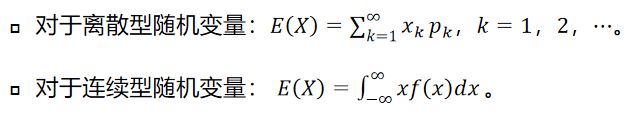
方差:是在概率论和统计方差衡量随机变量或一组数据时离散程度的度量。概率论中方差用来度量随机变量和其数学期望之间的偏离程度。
D(X)=Var(X)=E{[X−E(X)]^2}
另外,√D(X),记为σ(X),称为标准差或均方差。X^∗=X−E(X)/σ(X)称为X的标准化变量。
2.4.1协方差、相关系数、协方差矩阵
协方差:在某种意义上给出了两个变量线性相关性的强度以及这些变量的尺度。
Cov(X,Y)=E(X−E(X))E(Y−E(Y))
相关系数又叫线性相关系数,用来度量两个变量间的线性关系。
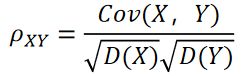
随机变量(X_1,X_2)的协方差矩阵:
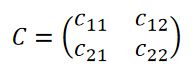
其中,c_ij=Cov(X_i,X_j)=E{[X_i−E(X_i)][X_j−E(X_j)]},i,j=1,2,⋯,n。协方差矩阵对角线上的元素分别是X_1,X_2的方差,其余元素为X_1,X_2的协方差。
2.5大数定律和中线极限定理
2.5.1大数定律
定义:设{X_k}是随机变量序列,数学期望E(X_k)(k=1,2…)存在,若对于任意ε>0,有
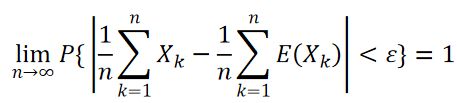
则称随机变量序列{X_k}服从大数定律。
大数定律可分为伯努利大数定理、切比雪夫大数定理和马尔可夫大数定理等。不同的大数定理的差别只是在于不同的随机变量序列。
大数定律证明了随着试验次数n的增加,事件A发生的频率越来越接近其概率。
大数定律在保险业、银行经营管理、Boosting算法和投资领域等都有着广泛的应用。
2.5.2 中心极限定律
误差的产生是由大量微小且独立的随机因素叠加而成的。中心极限定理就是研究独立随机变量和的极限分布为正态分布的问题。
林德贝格-勒维中心极限定理:若X_1,X_2,…,X_n,…为独立同分布的随机变量序列,均值为μ,方差为σ^2。当n趋于无穷时,有
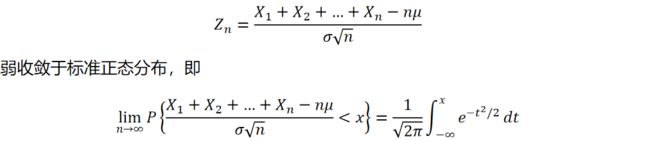
棣莫弗-拉普拉斯极限定理:设n重伯努利试验中,事件A在每次试验中出现的概率为p(0
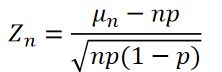
弱收敛于标准正态分布,即
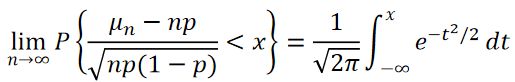
只有当n充分大时, Z_n才近似服从标准正态分布N(0,1),而n较小时,此种近似不能用。
在中心极限定理中,所谈及的一般条件可以非正式地概括为:在总和中的每个单独的项为总和的变化提供了一个不可忽视的量,而每一个单独的项都不可能给总和作出很大的贡献
2.5.3 中心极限定律应用
中心极限定理证明了一系列相互独立的随机变量的和的极限分布为正态分布,它揭示了大部分的社会经济现象表现为正态分布的本质原因。
中心极限定理在商业管理,计量经济学、保险、求解极限问题、图像处理等领域都有着广泛的应用。
举例:在进行观测时,有很多不可避免的随机误差,例如测量仪器误差、人为误差等。我们将总的误差看作很多相互独立的随机误差的总和,按照林德贝格中心极限定理,误差的总和应该服从正态分布。
2.6样本与抽样分布
2.6.1样本与抽样分布
为推断总体分布及各种特征,按一定的规则从总体中抽取若干个体进行观察试验,以获得有关总体的信息,这一抽取过程称为“抽样”,所抽取的部分个体称为样本,样本中所含的个体数目称为样本容量。一旦取定一组样本,得到的是n个具体的数(x_1,x_2,…,x_n),称为样本的一次观察值,简称样本观察值。
抽样中的基本概念:
总体:研究对象的全体
个体:总体中的每个成员
总体的容量:总体中所包含的个体的个数
最常用的抽样方法为简单随机抽样,由此抽样方法得到的样本称为简单随机样本。它要求抽取的样本满足:
代表性:样本X_1,X_2,…,X_n中每一个与所考察的总体有相同的分布
独立性:样本X_1,X_2,…,X_n是相互独立的随机变量
由样本值去推断总体情况,需要对样本进行“加工”,这就要构造一些样本的函数,把样本中的某一方面信息集中起来。这种不含任何未知参数的样本的函数称为统计量。它是完全有样本决定的量。统计量的分布称为抽样分布。
由大数定律可知,样本的数字特征依概率收敛到总体的数字特征,例如:
样本均值 n→ ∞ 总体均值E(X)
样本方差 n→ ∞ 总体方差D(X)
样本矩 n→ ∞ 总体矩
常见的来自正态分布的抽样分布有:
χ^2分布
t分布
F分布
2.6.2数据挖掘中常用抽样方法
数据挖掘中常用的抽样方法有简单随机抽样、系统抽样、分层抽样和整群抽样等。
简单随机抽样:将调查总体编号,再用抽签法或随机数字表随机抽取部分观察数据组成样本。分为有放回和无放回抽样。简单随机抽样常用于压缩数据量以减少费用和时间开销。
系统抽样:又称为等距抽样,首先设定抽样间距为n,然后在前n个数据中抽取初始数据,再按顺序每隔n个单位选取一个数据组成样本数据。
分层抽样:先将总体中按照某种特征划分成若干类型或层次,然后再在各个类型或层次中采用简单随机抽样或系统抽样的办法抽取一个子样本,最后,将这些子样本合起来构成总体的样本。分层抽样常用于离网预警模型或者金融欺诈预测模型等严重有偏的数据。
整群抽样:将全体数据拆分成若干个互不交叉、互不重复的群,每个群内的数据应尽可能具有不同属性,尽量能代表整体数据的情况,然后以群为单位进行抽样。
2.7参数估计和假设检验
对总体进行抽样后,我们需要根据样本对总体的指标作出具有一定可靠度的估计和判断,主要推断统计方法有参数估计和假设检验。
2.7.1参数估计
模型已定,参数未知:总体分布形式已知,而是其中几个参数未知。估计未知参数的方法为:
点估计(常用的点估计方法有矩阵计法和极大似然估计法)。
区间估计。
点估计和区间估计:二者的相同点都是基于一个样本作出估计;不同点是点估计只提供单一的估计值,而区间估计在点估计的基础上还提供了一个误差界限,给出了取值范围——这个取值范围又叫置信区间(confidence interval)。
设灯泡寿命T∽N(μ,σ^2),但参数μ和σ^2未知。现要通过对总体抽样得到的样本构造两样本函数分别对μ和σ^2作出估计,称为估计量,记作μ^′和σ^2′。代入观察值 x=(x_1,…,x_n),得到的值称为估计值。这种借助总体的一个样本,构造适当的样本函数来估计总体未知参数的值的问题称为参数的点估计。
极大似然估计的目的:利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
机器学习中,线性回归、逻辑回归都是基于极大似然估计计算的损失函数。
2.7.2 假设检验
为了推断总体的某些未知特性,提出某些关于总体的假设。例如,提出总体服从泊松分布的假设。又如,对于正态分布的总体提出数学期望为μ_0的假设等。根据样本对所提出假设作出是接受还是拒绝的决策的过程称为假设检验。
假设检验的基本思想是小概率反证法思想。小概率思想是指小概率事件(P<0.01或P<0.05)在一次试验中基本上不会发生。反证法思想是先提出假设,再用适当的统计方法确定假设成立的可能性大小,如可能性小,则认为假设不成立,若可能性大,则还不能认为假设不成立。
2.8方差分析和回归分析
方差分析(Analysis of Variance , ANOVA): 用于两个及以上均数差别的显著性检验,即检测某个因素(自变量)对总体(因变量)是否具有显著影响。虽然我们关注的是均值,但是需要借助方差判断均值之间是否有差异。
回归分析(regression of analysis): 确定两种或两种以上变量之间互相依赖的定量关系的一种统计分析方法。回归分析得到的是因变量和自变量之间的更精确的回归函数关系。
两者关系:方差分析给出自变量(因素)与因变量(总量)是否相互独立的初步判断,不需要自变量(因素)的具体数据,只需要因变量(总量)的观察数据。在不独立即相关的条件下,自变量与因变量到底是什么样的关系类型,则需应用回归分析作出进一步的判断,此时需要自变量(因素)及因变量(总量)的具体观察数据,得到它们之间的回归函数关系式。
应用:回归分析在预测、优化、做决策与数据拟合等方面都有着广泛的应用。
3.信息熵和基尼系数
3.1信息熵
3.1.1 信息量
信息论是应用数学的一个分支,主要研究的是对一个信号包含信息的多少进行量化。
信息论的基本想法是小概率事件比大概率事件能提供更多的信息。
举例1:“太阳东升西落”,信息量太少以至于没必要发送;但一条消息说:“太阳从西边出来了”,信息量就很丰富。那么定义一个事件X=x的自信息为I(x)应满足以下条件:
f(p)应是概率p的严格单调递减函数,即当p_1>p_2, f(p_1)
当p=1时,f(p)=0。
当p=0时,f(p)=∞。
两个独立事件的联合信息量应等于它们分别的信息量之和。
因此若一个消息出现的概率为p,则这一消息所含的信息量为:
I(x)=−log_2p
例:抛一枚均匀硬币,出现正面与反面的信息量为:I(正)= I(反)= 1bit。
3.1.2信息熵
信源含有的信息量是信源发出的所有可能消息的平均不确定性。信息论创始人香农把信源所含有的信息量称为信息熵(Entropy),是指数据分区D所含信息量的统计平均值。对D中有m个元组分类的信息熵计算如下:
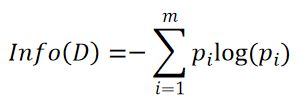
其中,p_i是D中任意一个元组属于类C_i的非零概率
例如:抛一枚均匀硬币的信息熵是多少?
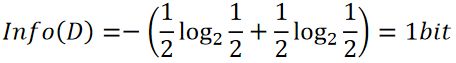
3.1.3基尼系数Gini
Gini系数是一种与信息熵类似的做特征选择的方式,可以用来表示数据的不纯度。
Gini系数计算公式:
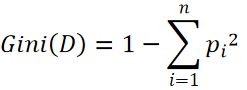
基尼系数普遍的运用是衡量一个国家和地区的财富分配水平。数值越低,表明财富在社会成员之间的分配越均匀;反之亦然。它还可以用于分类、推荐等算法中。
4.最优化
4.1最优化问题
最优化问题:指的是改变x以最小化或最大化某个函数f(x)的任务。可以表示为:
min(max)f(x) 目标函数的极小(极大)
s.t. g_i(x)≥0,i=1,2,⋯,m, 不等式约束
ℎ_j(x)=0,j=1,2,⋯,p, 等式约束
其中x=(x_1,x_2,⋯,x_n)^T∈R^n,我们将f(x)称为目标函数或准则,当对其进行最小化时, 也把它称为代价函数、损失函数或误差函数。
如果除目标函数以外,对参与优化的各变量没有其他函数或变量约束,则称为无约束最优化问题。反之,称为有约束最优化问题。
4.1.1最优化问题分类
无约束条件可以写为
minf(x),
常用方法为Fermat定理,即令f′(x)=0,求得临界点。然后验证临界点是否取得极值。
约束优化:是优化问题的分支。实际生活中的优化问题大多都是带约束条件得。我们可能希望在x的某些集合s中找f(x)的最大值或最小值。集合s内的点称为可行点。
等式约束条件可以写为
minf(x)
s.t. g_i(x)=0,i=1,2,⋯,n
不等式约束条件可以写为
minf(x)
s.t. g_i(x)=0,i=1,2,⋯,n,
ℎ(x)≤0,j=1,2,⋯,m
4.1.2无约束最优化问题
无约束最优化的求解方法主要有解析法和直接法。
解析法,即间接法,是根据无约束最优化问题的目标函数的解析表达式给出一种求最优解的方法,主要有梯度下降法、牛顿法、拟牛顿法、共轭方向法和共轭梯度法等。
直接法通常用于当目标函数表达式十分复杂或写不出具体表达式时的情况。通过数值计算,经过一系列迭代过程产生点列,在其中搜索最优点。
4.1.3梯度下降法
凸函数:对于λ∈(0,1),任意x_1,x_2∈R,都有
f(λx_1+(1−λ)x_2)≤λf(x_1)+(1−λ)f(x_2),
则称f(x)是一个凸函数。凸函数的极值点出现在驻点处。
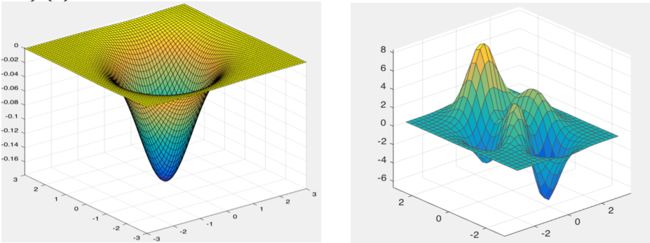
一元函数的极值问题:
函数的局部极值点意味着不能通过移动x减小或增大f(x)。
f^′(x)=0的点称为临界点或驻点。
函数的极值点一定是驻点,反之未必。
推广至多维函数的情形,用偏导数描述函数相对于各自变量的变化程度。
寻找函数极值:导数表示了沿坐标轴正方向函数的变化率。沿导数的正方向函数值增大,沿导数的反方向函数值减小。我们可以将x往导数的反方向移动一小步来减小f(x)以寻找函数极值。
当我们讨论函数沿任意方向的变化率时,需要求得某一点在某一方向的导数,即方向导数。
当函数在变量空间的某一点处,沿着哪一个方向有最大的变化率?最大方向导数方向,即梯度方向。
梯度(gradient):函数在某一点的梯度是一个向量。它的方向与取得最大方向导数的方向一致,而它的模为方向导数的最大值。
正梯度向量指向上坡,负梯度向量指向下坡。我们在负梯度方向上移动可以减小f(x),这被称为最速下降法(method of steepest descent)或梯度下降(gradient descent)。
在梯度下降法下,更新点被建议为:
x^′=x−ε∇_xf(x),
其中ε为学习率(learning rate),是一个确定步长的正标量。
迭代在梯度为零或趋近于零的时候收敛。
4.1.4 约束最优化
4.1.4.1等式约束最优化
拉格朗日乘子法是解决等式约束最优化的问题的最常用方法。其基本思想就是通过引入拉格朗日乘子来将含有n个变量和k个约束条件的约束优化问题转化为含有(n+k)个变量的无约束优化问题。拉格朗日乘子背后的数学意义是其为约束方程梯度线性组合中每个向量的系数。
等式优化条件可写为:
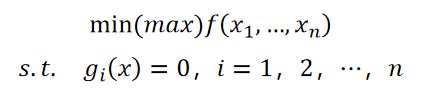
引入拉格朗日乘数λ后,我们只需要优化:
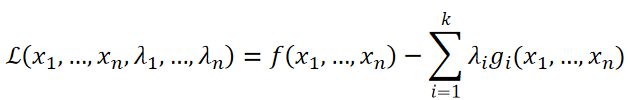
4.1.4.2 不等式约束最优化
不等式约束比等式约束更为常见,大部分实际问题的约束都是不超过多少时间,不超过多少人力,不超过多少成本等等。所以科学家对拉格朗日乘子法进行了扩展,增加了KKT条件,以求解不等式约束的优化问题。
不等式约束条件,可以写为
minf(x)
s.t. g_i(x)=0,i=1,2,⋯,n,
ℎ(x)≤0,j=1,2,⋯,m.
通常方法为引入新的变量λ_i和α_j,将所有的等式、不等式约束以及f(x)构造成广义拉格朗日函数,即
L(x,λ,α)=f(x)−∑_i▒λ_iℎ_i(x)−∑_j▒a_jg_j(x),
可以使用一组简单的性质来描述约束优化问题的最优点,这些性质称为KKT(Kuhn-Kuhn-Tucker)条件,如下:
∇f(x^∗)−∑_i▒λ_i∇ℎ_i(x^∗)−∑_j▒a_j∇g_j(x^∗)=0
g_j(x^∗)=0
ℎ_i(x^∗)≤0,λ_j≥0,λ_jℎ_j(x^∗)=0
根据上述案例得,其广义拉格朗日函数为:
ℒ(x_1,x_2,x_3,μ_1,μ_2)= x_1(30−x_1)+x_2(50−2x_2)−3x_1−5x_2−10x_3
−μ_1(x_1+x_2−x_3)−μ_2(x_3−17.25)
根据KKT条件得:
∇ℒ(x_1^∗)=30−2x_1−3−μ_1=0
∇ℒ(x_2^∗)=50−4x_2−5−μ_1=0
∇ℒ(x_3^∗)=−10−μ_1−μ_2=0
x_1+x_2−x_3≤0,x_3≤17.25
μ_1(x_1+x_2−x_3)=0
μ_2(x_3−17.25)=0
μ_1, μ_2≥0
解得x_1=8.5,x_2=8.75,x_3=17.25