CUDA学习之CUDA执行模型--part2
文章目录
- 3.2 理解线程束执行的本质
-
- 3.2.1 线程束和线程块
- 3.2.2 线程束分化
-
- 例
- 3.2.3 资源分配
-
- 活跃的线程束
- 3.2.4 延迟隐藏
-
- 举个例子:
- 指令分类
- 利特尔法则(Little's Law)
- 吞吐量和带宽
- 内存所需的并行
- 显示充足的并行
- 3.2.5 占用率
-
- CUDA GPU Occupancy Calculator
- 3.2.6 同步
-
- 3.2.6.1 全局
- 3.2.6.2 局部
- 3.2.6.3 竞争条件或危险
-
- 块内
- 块间
- 3.2.7 可扩展性
3.2 理解线程束执行的本质
启动内核时, 从软件的角度你看到了什么?对于你来说,在内核中似乎所有的线程都是并行地运行的。在逻辑上这是正确的,但从硬件的角度来看,
不是所有线程在物理上都可以同时并行地执行。
本章已经提到了把32个线程划分到一个执行单元中的概念:线程束。现在从硬件的角度来介绍线程束执行,并能够获得指导内核设计的方法。
3.2.1 线程束和线程块
线程束是SM中基本的执行单元,一个线程束由32个连续的线程组成
- 当一个线程块的网格被启动后,网格中的线程块分布在SM中。
- 一旦线程块被调度到一个SM上,线程块中的线程会被进一步划分为线程束。
- 在一个线程束中,所有的线程按照单指令多线程(SIMT)方式执行;也就是说,所有线程都执行相同的指令,每个线程在私有数据上进行操作。下图展示了线程块的逻辑视图和硬件视图之间的关系。
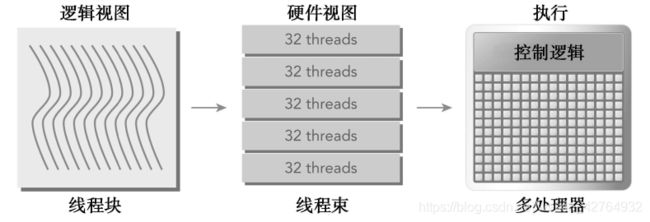
线程块在逻辑上可以被配置为一维、二维或三维,但从硬件角度看,所有线程都被组织成一维形式。在一个块中每个线程都有唯一ID,如果将x作为最内层维度,y作为第二个维度,z作为最外层维度,则二维或三维逻辑块布局可以转化为一维物理布局,且拥有连续值的线程被分组到线程束中。
一个块中每个线程的独特标识符:
-
对于一维线程块,唯一的线程ID被存储在CUDA内置变量
threadIdx.x中; -
对于二维线程块,线程ID可根据公式
threadIdx.y*blockDim.x+threadIdx.x计算; -
对于三维线程块,则可以根据
threadIdx.z*blockDim.y*blockDim.x+threadIdx.y*blockDim.x+threadIdx.x计算。
一个线程块的线程束的数量可以根据下式确定:
c e i l ( n u m _ t h r e a d s / w a r p _ s i z e ) ceil(num\_threads / warp\_size) ceil(num_threads/warp_size)

因此,硬件总是给一个线程块分配一定数量的线程束。线程束不会在不同的线程块之间分离。如果线程块的大小不是线程束大小的偶数倍,那么在最后的线程束里有些线程就不会活跃。
举例:
下图是一个在x轴中有40个线程、在y轴中有2个线程的二维线程块。从应用程序的角度来看,在一个二维网格中共有80个线程。
硬件为这个线程块配置了3个线程束,使总共96个硬件线程去支持80个软件线程。注意,最后半个线程束是不活跃的。即使这些线程未被使用,它们仍然消耗SM的资源,如寄存器。

总之,从逻辑角度来看,线程块是线程集合,可以被组织为一维、二维或三维布局;但从硬件角度看,线程块是一维线程束的集合,在线程块中线程被组织成一维布局,每32个连续线程组成一个线程束。
3.2.2 线程束分化
控制流是高级编程语言的基本构造中的一种。GPU支持传统的、C风格的、显式的控制流结构,例如,if…then…else、for和while。
CPU拥有复杂的硬件结构来执行分支预测,即在每个条件检查中预测控制流会使用哪个分支,若预测正确,则只需付出很小的性能代价;若预测不正确,则可能会停止运行很多周期,因为指令流水线被清空了。
GPU则没有复杂的分支预测机制,一个线程束中的所有线程在同一周期中必须执行相同的指令,如果一个线程执行一条指令,则线程束中的所有线程都必须执行该指令。
若同一线程束中的线程使用不同的路径通过同一个应用程序,则有可能产生问题。比如下面的语句:
if(cond)
{ ... }
else
{ ... }
若一个线程束有16个线程执行这段代码时cond为True,另外16个为False,则有一半的线程束需要执行if语句块中的指令,另一半需要执行else语句块的指令。在同一线程束中的线程执行不同的指令,被称为线程束分化。 前面已经说过,一个线程束中所有线程在每个周期必须执行相同的指令,所以线程束分化会产生一个悖论。
如果一个线程束中的线程产生分化,线程束将连续执行每一个分支路径,而禁用不执行这一路径的线程。因此线程束分化会导致性能明显地下降, 在前面的例子中线程束中并行线程数量减少了一半。而条件分支越多,并行性削弱越严重,下图显示了线程束分化。需要注意的是,线程束分化只发生在同一线程束中,不同线程束中不同的条件值不会引起线程束分化。

-
为了获得最佳性能,应该避免在同一线程束中有不同的执行路径。
-
需要记住在一个线程块中,线程的线程束分配是确定的,
-
因此以这样的方式对数据区分是可行的,以确保同一个线程束中的所有线程在一个应用程序中使用同一控制路径。
例
例如,假设有两个分支,下面展示了简单的算术内核示例。我们可以用一个偶数和奇数线程方法来模拟一个简单的数据分区,目的是导致线程束分化。该条件(tid%2==0)使偶数编号的线程执行if子句,奇数编号的线程执行else子句。
__global__ void mathKernel1(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float a = 0.0f, b = 0.0f;
if(tid % 2 == 0)
a = 100.f;
else
b = 200.f;
c[tid] = a + b;
}
如果使用线程束方法(而不是线程方法)来交叉存取数据,可以避免线程束分化,并且设备的利用率可达到100%。条件(tid/warpSize)%2==0使分支粒度是线程束大小的倍数;
偶数编号的线程束执行if子句 ,奇数编号的线程束执行else子句。这个核函数产生相同的输出,但是顺序不同。
__global__ void mathKernel2(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float a = 0.0f, b = 0.0f;
if((tid/warpSize) % 2 == 0)
a = 100.f;
else
b = 200.f;
c[tid] = a + b;
}
代码:
#include "../common/common.h"
#include 通过使用nvprof分析器,可以从GPU中获得指标,从而可以直接观察到线程束分化。
在这里,nvprof的branch_efficiency指标是用来计算simpleDivergence的样本执行的:
$ nvcc -O3 -arch=sm_60 main.cu -o main
$ sudo nvprof --metrics branch_efficiency ./main
=33900== NVPROF is profiling process 33900, command: ./main
./main using Device 0: GeForce GTX 1050
Data size 64 Execution Configure (block 64 grid 1)
warmup <<< 1 64 >>> elapsed 0.008052 sec
mathKernel1 <<< 1 64 >>> elapsed 0.005340 sec
mathKernel2 <<< 1 64 >>> elapsed 0.005455 sec
mathKernel3 <<< 1 64 >>> elapsed 0.006032 sec
mathKernel4 <<< 1 64 >>> elapsed 0.005699 sec
==33900== Profiling application: ./main
==33900== Profiling result:
==33900== Metric result:
Invocations Metric Name Metric Description Min Max Avg
Device "GeForce GTX 1050 (0)"
Kernel: mathKernel1(float*)
1 branch_efficiency Branch Efficiency 100.00% 100.00% 100.00%
Kernel: mathKernel2(float*)
1 branch_efficiency Branch Efficiency 100.00% 100.00% 100.00%
Kernel: mathKernel3(float*)
1 branch_efficiency Branch Efficiency 100.00% 100.00% 100.00%
Kernel: mathKernel4(float*)
1 branch_efficiency Branch Efficiency 100.00% 100.00% 100.00%
Kernel: warmingup(float*)
1 branch_efficiency Branch Efficiency 100.00% 100.00% 100.00%
分支效率被定义为未分化的分支与全部分支之比,可以使用以下公式来计算:

没有报告显示出有分支分化(即分支效率是100%)。这个奇怪的现象是CUDA编译器优化导致的结果,它将短的、有条件的代码段的断定指令取代了分支指令(导致分化的实际控制流指令)。
在分支预测中,根据条件,把每个线程中的一个断定变量设置为1或0。这两种条件流路径被完全执行,但只有断定为1的指令被执行。断定为0的指令不被执行,但相应的线程也不会停止。这和实际的分支指令之间的区别是微妙的,但理解它很重要。只有在条件语句的指令数小于某个阈值时,编译器才用断定指令替换分支指令。因此,一段很长的代码路径肯定会导致线程束分化。
使用下面的命令,可以强制CUDA编译器不利用分支预测去优化内核:
nvcc -g -G -arch=sm_60 main.cu -o main
用nvprof再次检查没有被优化的内核分化:
sudo nvprof --metrics branch_efficiency ./main
==34153== NVPROF is profiling process 34153, command: ./main
./main using Device 0: GeForce GTX 1050
Data size 64 Execution Configure (block 64 grid 1)
warmup <<< 1 64 >>> elapsed 0.007652 sec
mathKernel1 <<< 1 64 >>> elapsed 0.006174 sec
mathKernel2 <<< 1 64 >>> elapsed 0.005870 sec
mathKernel3 <<< 1 64 >>> elapsed 0.005246 sec
mathKernel4 <<< 1 64 >>> elapsed 0.006234 sec
==34153== Profiling application: ./main
==34153== Profiling result:
==34153== Metric result:
Invocations Metric Name Metric Description Min Max Avg
Device "GeForce GTX 1050 (0)"
Kernel: mathKernel1(float*)
1 branch_efficiency Branch Efficiency 83.33% 83.33% 83.33%
Kernel: mathKernel2(float*)
1 branch_efficiency Branch Efficiency 100.00% 100.00% 100.00%
Kernel: mathKernel3(float*)
1 branch_efficiency Branch Efficiency 100.00% 100.00% 100.00%
Kernel: mathKernel4(float*)
1 branch_efficiency Branch Efficiency 100.00% 100.00% 100.00%
Kernel: warmingup(float*)
1 branch_efficiency Branch Efficiency 100.00% 100.00% 100.00%
用nvprof获得分支和分化分支的事件计数器,如下所示:
$ sudo nvprof --events branch,divergent_branch ./main
==34183== NVPROF is profiling process 34183, command: ./main
./main using Device 0: GeForce GTX 1050
Data size 64 Execution Configure (block 64 grid 1)
warmup <<< 1 64 >>> elapsed 0.005558 sec
mathKernel1 <<< 1 64 >>> elapsed 0.004425 sec
mathKernel2 <<< 1 64 >>> elapsed 0.003924 sec
mathKernel3 <<< 1 64 >>> elapsed 0.005054 sec
mathKernel4 <<< 1 64 >>> elapsed 0.003943 sec
==34183== Profiling application: ./main
==34183== Profiling result:
==34183== Event result:
Invocations Event Name Min Max Avg Total
Device "GeForce GTX 1050 (0)"
Kernel: mathKernel1(float*)
1 branch 12 12 12 12
1 divergent_branch 2 2 2 2
Kernel: mathKernel2(float*)
1 branch 11 11 11 11
1 divergent_branch 0 0 0 0
Kernel: mathKernel3(float*)
1 branch 16 16 16 16
1 divergent_branch 0 0 0 0
Kernel: mathKernel4(float*)
1 branch 6 6 6 6
1 divergent_branch 0 0 0 0
Kernel: warmingup(float*)
1 branch 11 11 11 11
1 divergent_branch 0 0 0 0
CUDA的nvcc编译器仍然是在mathKernel1和mathKernel3上执行有限的优化,以保持分支效率在50%以上。注意,mathKernel2不报告分支分化的唯一原因是它的分支粒度是线程束大小的倍数。
-
当一个分化的线程采取不同的代码路径时,会产生线程束分化
-
不同的if-then-else分支会连续执行
-
尝试调整分支粒度以适应线程束大小的倍数,避免线程束分化
-
不同的分化可以执行不同的代码且无须以牺牲性能为代价
3.2.3 资源分配
-
线程束的本地上下文主要由程序计数器、寄存器、共享内存这几个资源组成,
-
由SM处理的每个线程束的执行上下文,在整个线程束的生存期中是保存在芯片内的,因此从一个执行上下文切换到另一个执行上下文没有损失。
-
每个SM都有32位的寄存器,它存储在寄存器文件中,可以在线程中进行分配,同时有固定数量的共享内存在线程块中进行分配。
-
对于一个给定的内核,同时存在于同一个SM中的线程块和线程束的数量,取决于在SM中可用的且内核所需的寄存器和共享内存数量。
- 如下图所示,若每个线程消耗的寄存器越多,则可以放在一个SM中的线程束就越少;若可以减少内核消耗寄存器的数量,就可以同时处理更多的线程束。

- 如下图所示,若一个线程块消耗的共享内存越多,则在一个SM中可同时处理的线程块就会越少。如果每个线程块使用的共享内存数量变少,则可以同时处理更多的线程块。

- 资源可用性通常会限制SM中常驻线程块的数量。
- 每个SM中寄存器和共享内存的数量因设备拥有不同的计算能力而不同。如果每个SM没有足够的寄存器或共享内存去处理至少一个块,那么内核将无法启动。
活跃的线程束
当计算资源(如寄存器和共享内存)已分配给线程块时,线程块被称为活跃的块。它所包含的线程束被称为活跃的线程束。
如果同时满足这两个条件:1. 有32个CUDA核心可用于执行、2. 当前指令中的所有参数都已就绪,则线程束符合执行条件。
活跃的线程束可以进一步被分为以下3种类型:
-
选定线程束:一个SM上的线程束调度器在每个周期都选择活跃线程束将它们调度到执行单元,活跃执行的线程束被称为选定线程束;
-
符合条件线程束:如果一个活跃线程束准备执行但尚未执行,则是一个符合条件线程束;
-
阻塞线程束:如果一个线程束没有做好执行准备,则是一个阻塞线程束。
例如,在Kepler SM上活跃的线程束数量,
- 从启动到完成在任何时候都必须小于或等于64个并发线程束的架构限度;
- 在任何周期,选定线程数量都小于等于4;
- 如果线程束阻塞,线程束调度器会令一个符合条件线程束去代替它执行;
- 由于计算资源在线程束之间进行分配,而且线程束在整个生存期中都保持在芯片内,因此线程束上下文切换非常快。
总之,在CUDA编程中需要特别关注计算资源分配:计算资源限制了活跃线程束数量,因此必须了解由硬件产生的限制和内核用到的资源。为最大程度地利用GPU,需要最大化活跃线程束数量。
3.2.4 延迟隐藏
SM依赖线程级并行来最大化功能单元的利用率,因此利用率与常驻线程的数量直接相关。
指令延迟:在指令发出与完成之间的时钟周期
当每个时钟周期中所有线程调度器都有一个符合条件线程束时,可以达到计算资源的完全利用。这样就能保证,通过在其他常驻线程束中发布其他指令,可以隐藏每个指令的延迟。
延迟隐藏在CUDA编程中十分重要,GPU是为处理大量并发和轻量级线程以最大化吞吐量而设计的,GPU的指令延迟被其他线程束的计算隐藏。
举个例子:
如果活跃的线程束有32个,线程束调度器有4个,线程束调度器每时钟周期会调度4个线程束进行指令执行,也就是说需要8个时钟周期进行调度,32个活跃的线程束都会执行。
那么如果说一个指令的耗时或者说延迟是7个周期,当线程束调度器调度最后4给线程执行该指令的时候,第一组线程束的指令已经执行完毕了(第一组的线程束指令延迟被隐藏了),此时,我们就说指令的延迟被隐藏了或这说完成了延时延迟。
换句话说,一个SM中32个线程束执行一个耗时8个时钟周期的指令,它们全部执行完毕最短需要的时间是,8+8 = 16个时钟周期,在延迟隐藏的情况下,即每个线程束都处于活跃状态,耗时是16个周期,即16个周期即完成了任务。
在非延迟隐藏的情况下,即没有足够多的线程束处于活跃状态,那么线程束调度器就会存在等待的情况,在这种情况下,耗时将>16个周期。
延迟隐藏需要有足够多的活跃的线程束,足够多活跃的线程束正相关于设备开启的线程束数量,设备开启的线程束数量由块的大小(执行配置)和资源约束(一个核函数中寄存器和共享内存的使用情况)决定。
总之,如果有足够的并发活跃线程,那么可以让GPU在每个周期内的每一个流水线阶段中忙碌。GPU的指令延迟被其他线程束的计算隐藏。
指令分类
按照指令延迟,指令可分为两种基本类型:
-
算数指令:指令延迟是一个算数操作从开始到产生输出之间的时间,大约10~20个周期;
-
内存指令:指令延迟是指发出的加载或存储操作和数据到达目的地之间的时间,全局访存为400~800个周期。
下图表示线程束0阻塞执行流水线的示例,线程束调度器选取其他线程束执行,当线程束0符合条件时再执行:

利特尔法则(Little’s Law)
利特尔法则(Little’s Law)提供了一个隐藏延迟所需活跃线程数量的合理近似值,它源于队列理论中的定理,也可应用于GPU中:所需线程束数量=延迟×吞吐量
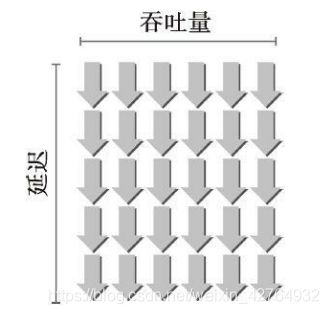
形象地说明了利特尔法则。假设在内核里一条指令的平均延迟是5个周期。为了保持在每个周期内执行6个线程束的吞吐量,则至少需要30个未完成的线程束
吞吐量和带宽
它们经常被混淆,根据实际情况它们可被交换使用,都是用来度量性能的速度指标。
带宽通常是理论峰值,用来描述单位时间内最大可能的数据传输量;
吞吐量是指已达到的值,用来描述单位时间内任何形式的信息或操作的执行速度,如每个周期完成了多少指令。
吞吐量由SM中每个周期内的操作数量确定
有两种方法可以提高并行:
-
指令级并行(ILP):一个线程中有很多独立的指令
-
线程级并行(TLP):很多并发地符合条件的线程
内存所需的并行
对内存操作来说,其所需的并行可以表示为在每个周期内隐藏内存延迟所需的字节数。

-
因为内存吞吐量通常表示为每秒千兆字节数,所以首先需要用对应的内存频率将吞吐量转换为每周期千兆字节数。
例如,Fermi的内存频率(在Tesla C2070上测量得到)是1.566 GHz。Kepler的内存频率(在Tesla K20上测量得到)是2.6 GHz。因为1 Hz被定义为每秒一个周期,所以可以把带宽从每秒千兆字节数转换为每周期千兆字节数,公式如下所示:
144 G B / s ÷ 1.566 G H z ≌ 92 个 字 节 / 周 期 144 GB/s÷1.566 GHz ≌ 92个字节/周期 144GB/s÷1.566GHz≌92个字节/周期 -
用内存延迟乘以每周期字节数,可以得到Fermi内存操作所需的并行:
即92*800/1000,约为74KB,
接近74KB的内存I/O运行,用以实现充分的利用。这个值是对于整个设备,而不是对于每个SM来说的,因为内存带宽是对于整个设备而言的。 -
假设每个线程都把一浮点数据(4个字节)从全局内存移动到SM中用于计算,则在Fermi GPU上,总共需要18500个线程或579个线程束来隐藏所有内存延迟:
74 K B ÷ 4 字 节 / 线 程 ≌ 18500 个 线 程 74 KB÷4字节/线程≌18500个线程 74KB÷4字节/线程≌18500个线程 18500 个 线 程 ÷ 32 个 线 程 / 线 程 束 ≌ 579 个 线 程 束 18500个线程÷32个线程/线程束≌579个线程束 18500个线程÷32个线程/线程束≌579个线程束 -
Fermi架构有16个SM, 579 个 线 程 束 ÷ 16 个 S M = 36 个 线 程 束 / S M 579个线程束÷16个SM=36个线程束/SM 579个线程束÷16个SM=36个线程束/SM
以隐藏所有的内存延迟。如果每个线程执行多个独立的4字节加载,隐藏内存延迟需要的线程就可以更少。
与指令延迟很像,通过在每个线程/线程束中创建更多独立的内存操作,或创建更多并发地活跃的线程/线程束,可以增加可用的并行。
延迟隐藏取决于每个SM中活跃线程束的数量,这一数量由执行配置和资源约束隐式决定(一个内核中寄存器和共享内存的使用情况)。选择一个最优执行配置的关键是在延迟隐藏和资源利用之间找到一种平衡。下一节将会更加详细地研究这个问题。
显示充足的并行
因为GPU在线程间分配计算资源并在并发线程束之间切换的消耗(在一个或两个周期命令上)很小,所以所需的状态可以在芯片内获得。如果有足够的并发活跃线程,那么可以让GPU在每个周期内的每一个流水线阶段中忙碌。在这种情况下,一个线程束的延迟可以被其他线程束的执行隐藏。因此,向SM显示足够的并行对性能是有利的。
计算所需并行的一个简单的公式是,用每个SM核心的数量乘以在该SM上一条算术指令的延迟。
例如,Fermi有32个单精度浮点流水线线路,一个算术指令的延迟是20个周期,所以,每个SM至少需要有32×20=640个线程使设备处于忙碌状态。然而,这只是一个下边界。
3.2.5 占用率
在每个CUDA核心里指令是顺序执行的。当一个线程束阻塞时,SM切换执行其他符合条件的线程束。理想情况下,我们想要有足够的线程束占用设备的核心。
占用率是每个SM中活跃的线程束占最大线程束数量的比值。

使用下述函数,可以检测设备中每个SM的最大线程束数量:
cudaError_t cudaGetDeviceProperties(struct cudaDeviceProp *prop, int device)
函数cudaGetDeviceProperties 中,来自设备的统计数据在cudaDeviceProp结构中返回,每个SM的最大线程数量在maxThreadsPerMultiProcessor中,将其数值除以32,就可以得到最大线程束数量。
#include "../common/common.h"
#include Device 0: GeForce GTX 1050
Number of multiprocessors: 5
Total amount of constant memory: 64.00 KB
Total amount of shared memory per block: 48.00 KB
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per block: 1024
Maximum number of threads per multiprocessor: 2048
Maximum number of warps per multiprocessor: 64
int iDev = 0;
cudaDeviceProp iProp;
CHECK(cudaGetDeviceProperties(&iProp, iDev));
结构体iProp包含了其信息,
| iProp.name | GeForce GTX 1050 | GPU名称 |
| iProp.multiProcessorCount | 5 | SM个数 |
| iProp.totalConstMem | 64KB | 常量内存 |
| iProp.sharedMemPerBlock | 48KB | 每个线程块的共享内存 |
| iProp.regsPerBlock | 65536 | 每个线程块的可用寄存器 |
| iProp.warpSize | 32 | 线程束大小 |
| iProp.maxThreadsPerBlock | 1024 | 每个线程块内的最大线程数 |
| iProp.maxThreadsPerMultiProcessor | 2048 | 每个SM中最多的线程数 |
| iProp.maxThreadsPerMultiProcessor / 32 | 64 | 每个SM内最多的线程束 |
CUDA GPU Occupancy Calculator
CUDA工具包包含了一个电子表格,它被称为CUDA占用率计算器,有助于选择网格和块的维数以使一个内核的占用率最大化
占用率计算器包含几个部分。
- 首先,必须提供GPU的计算能力和内核的资源使用情况的信息。
- 在确定GPU的计算能力后,物理限制部分的数据是自动填充的。
- 接下来,需要输入以下内核资源信息:
1)每个块的线程(执行配置)
2)每个线程的寄存器(资源使用情况)iProp.regsPerBlock
3)每个块的共享内存(资源使用情况)iProp.sharedMemPerBlock
每个线程的寄存器和每个块的共享内存资源的使用情况可以从nvcc中用以下编译器标志获得:
nvcc --ptxas-options=-v main.cu -o main
一旦进入这个数据,内核占用率便会显示在GPU占用率数据段。其他部分提供必要的信息,来调整执行配置和资源使用情况,以获得更好的设备占用率。
内核使用的寄存器数量会对常驻线程束数量产生显著的影响。寄存器的使用可以用下面的nvcc标志手动控制。
-maxrregcount=NUM
-maxrregcount选项告诉编译器每个线程使用的寄存器数量不能超过NUM个。使用这个
编译器标志,可以得到占用率计算器推荐的寄存器数量,同时使用这个数值可以改善应用
程序的性能。
为了提高占用率,还需要调整线程块配置或重新调整资源的使用情况,以允许更多的线程束同时处于活跃状态和提高计算资源的利用率。极端地操纵线程块会限制资源的利用:
- 小线程块:每个块中线程太少,会在所有资源被充分利用之前导致硬件达到每个SM的线程束数量的限制。
- 大线程块:每个块中有太多的线程,会导致在每个SM中每个线程可用的硬件资源较少。
使用这些准则可以使应用程序适用于当前和将来的设备:
-
保持每个块中线程数量是线程束大小(32)的倍数
-
避免块太小:每个块至少要有128或256个线程
-
根据内核资源的需求调整块大小
-
块的数量要远远多于SM的数量,从而在设备中可以显示有足够的并行
-
通过实验得到最佳执行配置和资源使用情况
尽管在每种情况下会遇到不同的硬件限制,但它们都会导致计算资源未被充分利用,阻碍隐藏指令和内存延迟的并行的建立。
占用率唯一注重的是在每个SM中并发线程或线程束的数量。
然而,充分的占用率不是性能优化的唯一目标。内核一旦达到一定级别的占用率,进一步增加占用率可能不会改进性能。
为了提高性能,可以调整很多其他因素。在后续章节中将详细介绍这些内容。
3.2.6 同步
在CUDA中,同步可以在两个级别执行:
- 系统级:等待主机和设备完成所有的工作
- 块级:在设备执行过程中等待一个线程块中所有线程到达同一点
3.2.6.1 全局
对于主机来说,许多CUDA API调用和所有内核启动都是异步的,cudaDeviceSynchronize函数可以用来阻塞主机应用程序,直到所有CUDA操作(复制、核函数等)完成。
cudaError_t cudaDeviceSynchronize(void);
这个函数可能会从先前异步CUDA操作返回错误。
3.2.6.2 局部
因为在一个线程块中线程束以一个未定义的顺序执行,CUDA提供了一个块局部栅栏来同步它们的执行功能,可以使用__device__ void __syncthreads(void)函数在内核中标记同步点。
当__syncthreads被调用时,在同一个线程块中每个线程都必须等待直至该线程块中所有其他线程都达到这个同步点。
在栅栏之前所有线程产生的所有全局内存和共享内存访问,将会在栅栏之后对线程块中所有其他线程可见。该函数可以协调同一个块中线程之间的通信,但它强制线程束空闲,因此可能对性能产生负面影响。
3.2.6.3 竞争条件或危险
竞争条件或危险,是指多个线程无序地访问相同的内存位置。
线程块中的线程可以通过共享内存和寄存器来共享数据,当线程之间共享数据时,要避免竞争条件。
块内
当线程块中的线程在逻辑上并行运行时,在物理上并不是所有的线程都可以在同一时间执行。如果线程A试图读取由线程B在不同的线程束中写的数据,若使用了适当的同步,只需确定线程B已经写完就可以了。否则,会出现竞争条件。
块间
在不同块之间没有没有线程同步,块间同步唯一安全的方法是在每个内核执行结束端使用全局同步点,即在全局同步后,终止当前核函数,开始执行新核函数。
不同块中线程不允许相互同步,因此GPU可以任意顺序执行块,这使得CUDA程序在大规模并行GPU上是可扩展的。
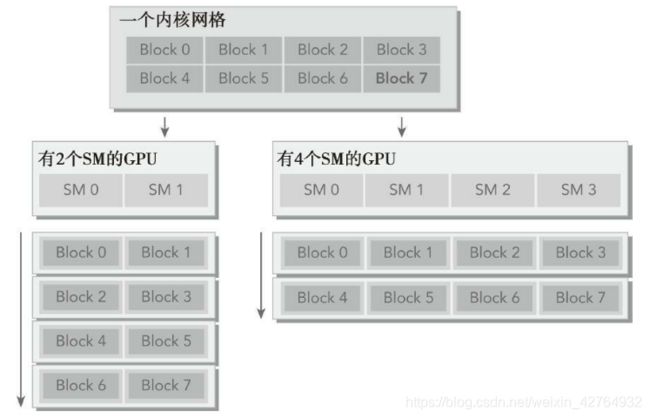
3.2.7 可扩展性
对任何并行程序而言,可扩展性是一个理想特性。
可扩展性意味着为并行应用程序提供了额外的硬件资源,相对于增加的资源,并行应用程序会产生加速。例如,若一个CUDA程序在两个SM中是可扩展的,则与在一个SM中运行相比,在两个SM中运行会
使运行时间减半。
一个可扩展的并行程序可以高效地使用所有的计算资源以提高性能。
可扩展性意味着增加的计算核心可以提高性能,串行代码本身是不可扩展的,并行代码有可扩展的潜能,但真正的可扩展性取决于算法设计和硬件特性。
能够在可变数量的计算核心上执行相同应用程序代码的能力被称为透明可扩展性。
一个透明可扩展平台拓宽了现有应用程序的应用范围,并减少了开发人员的负担,因为它们可以避免新的或不同的硬件产生的变化。
可扩展性比效率重要,一个可扩展但效率很低的系统可以通过简单添加硬件核心来处理更大的工作负载。一个效率很高但不可扩展的系统可能很快会达到可实现性能的上限。
CUDA内核启动时,线程块分布在多个SM中,网格中的线程块以并行或连续或任意的顺序被执行,这种独立性使得CUDA程序在任意数量的计算核心间可以扩展。
下图展示了CUDA架构可扩展性的一个例子。左侧的GPU有两个SM,可以同时执行两个块;右侧的GPU有4个SM,可以同时执行4个块。不修改任何代码,一个应用程序可以在不同的GPU配置上运行,并且所需的执行时间根据可用的资源而改变。