Bertopology: Bert及其改进型总结
BERT自从被提出之后,因为其开源且表现及其优异,工业界开始广泛采用Bert来完成各项NLP的任务。一般来说,Bert都能给我们相当强悍的结果,唯一阻止Bert上线使用的,就是其难以接受的计算复杂度。因此各种模型压缩的方法层出不穷。本篇博客意在总结Bert及其改进型主要的特点,这也是NLP算法面试常见的问题。
Bert使用的激活函数是GELU:
正态分布下GELU(x),论文给出了近似计算公式:
G E L U ( x ) = 0.5 x ( 1 + t a n h [ 2 / π ( x + 0.044715 x 3 ) ] ) GELU(x) = 0.5x(1+tanh[\sqrt{2/\pi}(x+0.044715x^3)]) GELU(x)=0.5x(1+tanh[2/π(x+0.044715x3)])
Bert使用的版本则更为简单,源码如下:
def gelu(input_tensot):
cdf = 0.5 * (1.0 + tf.erf(input_tensor / tf.sqrt(20.)))
改进方法:
- 更大更强悍
- 瘦身,模型压缩
- 引入常识或知识
(更大更强悍) RoBERTa
RoBERTa
- More data
- Large batch size
- Traing longer
- No NSP (很多论文作者认为next sentence prediction无用)
- Large sequence length
- Dynamic masking
- Byte level BPE
static masking:
create pretraing data中,先对数据进行提前的mask,为了充分利用数据,定义dupe_factor,将数据复制dupe_factor份,同一条数据有dupe_factor份,每一份执行不同的mask,这些数据不是全部喂给同一个epoch,而是不同的epoch。
dynamic masking:
每一次将训练样本喂给模型的时候,随机进行mask。
Byte level BPE:
BERT原型使用的是 character-level BPE vocabulary of size 30K, RoBERTa使用了GPT2的 BPE 实现,使用的是byte而不是unicode characters作为subword的单位。
(瘦身,模型压缩): ALBERT
ALBERT
[1]. 对Embedding做因式分解(Factorized embedding parameterization)
一般来讲 H ≡ E H\equiv E H≡E,参数里量巨大。
O ( V × H ) → O ( V × E + E × H ) O(V \times H) \rightarrow O(V \times E + E \times H) O(V×H)→O(V×E+E×H)
使用了更小的E,H可以维持不变,显著降低参数。
[2]. 跨层的参数共享(Cross-layer parameter sharing)
Transformer有两种共享参数的方案:
- 只共享全连接层
- 只共享attention层
ALBERT结合上述两种方法,全连接层,attention层都进行参数共享。
[3]. inter-sentence coherence loss
sentence-order prediction(SOP)
BERT的NSP其实包含了两个子任务,主题一致性与关系一致性预测。主题预测(因为正样本在同一个文档中选取,负样本在不同文档中选取,主题预测很简单,并且MLM任务中也有类型的效果)。
ALBERT中,为了只保留一致性任务去除主题识别的影响,提取了sentence-order prediction。SOP是在同一个文档中选取的,所以只关注句子的顺序并没有主题的影响。
[4]. 移除Dropout
(引入知识)
ERNIE(Baidu)、ERNIE 2.0(Baidu)、ERNIE(THU)
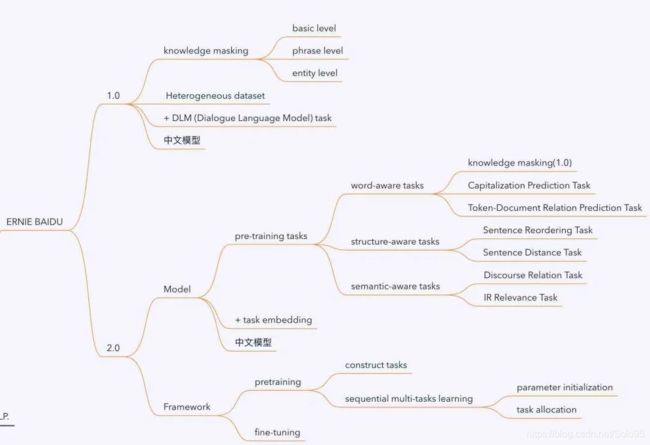
百度的详见官方博客:paddlepaddle
ERNIE(Baidu) 中文
[1]. 不同粒度的信息融合
- Basic Level Masking训练
英文而言,粒度为word;中文而言,粒度为字。 - Phrase-Level Masking
对短语也进行mask。 - Entity-level Masking
对句子中的实体也进行mask。
[2]. 多源数据
中文维基百科,百度百科,百度新闻,百度贴吧。其中,百度贴吧由于其社区的特性,里面的内容是对话形式的,而 ERNIE 中对于 Segement Embedding 预训练与 Bert 的 NSP 不同的是,其采用 DLM 来获得这种句子粒度级别的信息,而这对于句子语义的把握更佳准确
[3]. DLM: Dialog Language Model
DLM更能把握句子的语义信息,并且用于对话、问答这种形式的任务效果更好。
为了能够表示多轮对话,其输入采用QRQ、QQR、QRR的形式。
ERNIE 2.0(Baidu)
- Continual Learning(持续学习)
- Multi-task Learning(多任务学习)
- Sequential Multi-task Learing(顺序多任务学习)
模型的预训练任务:
[1]. 词汇级别任务(word-aware pretraining task):获取词法知识
- 知识掩码任务(同ERNIE)
- 大小写预测任务
[2]. 结构级别任务(structure-aware pretraining task):获取句法知识
- 句子排序任务
- 句子距离任务(判断两个句子是否相邻、是否属于同一文章,来判断两句的语义关系是否紧密,是否属于同一话题。)
一个三分类的问题:
0: 代表两个句子相邻 1: 代表两个句子在同个文章但不相邻 2: 代表两个句子在不同的文章中
[3]. 文档级别的任务(Token-Document Relation Prediction Task):
Token-Document Relation Prediction Task
判断在文档的segment中出现的一个token会不会在同文档另外一个segment中出现
一般来讲,出现在文档多个部分的token和topic是强相关的
[4]. 语义级别的任务(semantic-aware pretraining task)
Discourse Relation Task
判断句子的语义关系,无监督的逻辑关系分类(因果、假设、递进、转折)
[5]. 信息检索关系任务(IR Relevance Task)
一个三分类的问题,预测query和网页标题的关系:
0: 代表了提问和标题强相关(出现在搜索的界面且用户点击了)
1: 代表了提问和标题弱相关(出现在搜索的界面但用户没点击)
2: 代表了提问和标题不相关(未出现在搜索的界面)
ERNIE(THU)
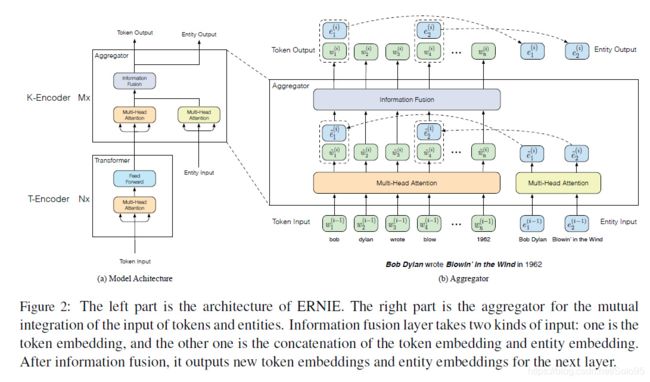
清华+诺亚方舟,做法是,使用知识图谱和知识图谱嵌入来引入知识。
T-Encoder: 即普通的Transformer。
![]()
TransE:encode 知识图谱编码的一种算法
![]()
K-Encoder
![]()
具体计算过程如下:
首先经过一个多层的多头注意力层:

接下来将entity embedding和token embedding融合,entity和token之间存在对应关系,文中采用第一个token作为对应方式,有无对应entity计算分为如下两种情况:
- 有对应实体

- 无对应实体

激活函数GELU,本文开头有介绍和源码。
融合的过程可以认为是一个aggregator。
![]()
dEA: denoising entity auto-encoder

对于token序列与entity序列,计算每个token所对应的 entity 序列概率分布,以此来进行预训练。这是为了将 K-Encoder 输出的信息结合,毕竟不是每一个 token 都有对应的实体信息的。
dAE的预训练过程考虑了token和entity之间的对齐误差,采用了一些mask的策略,:
- 5% 的情况下,对于给定的 token-entity 对,我们将实体替换为其他随机实体, 旨在减轻对齐过程所带来的误差。
- 15% 情况下,mask token-entity 对, 旨在减轻对于新 token-entity 所带来的误差
- 剩下80% , 保持不变。