ubuntu下Anaconda5.0.1 tensorflow-gpu1.9 cuda8.0+cudnn7.0.5+deeplab v3+训练全流程
deeplab V3+是目前比较语义分割效果比较好的主流框架之一。
利用pascal数据集以及cityscapes数据集等训练的方式这里就不介绍了,网上有很多介绍,下面介绍一下利用自己的数据训练deeplab模型的主要步骤。
一、配置deeplab v3+
此代码已经开源,具体下载地址在github上,直接下载到本地,也可以采用git的方式下载,不需要编译。
二、配置anaconda环境
anaconda 有支持python2的版本也有支持python3的版本,这里我使用的是支持python3.6的版本anaconda5.0.1,即
推荐清华大学的下载地址。
下载后直接bash命令执行即可,中间多次按enter,傻瓜式安装。
测试安装是否成功,输入conda,显示如下,即为成功。

查看当前python版本:直接输入python,显示如下:

创建conda虚拟环境,其中tf名字是自定义,即为虚拟环境的名称,python设为需要的版本即可:
conda create -n tf python==3.6进入环境
source activate tf
出现:
![]()
若想退出环境::
source deactivate在该虚拟环境下配置安装tensorflow,我这里安装的是GPU版本
pip install tensorflow-gpu==1.9这里说要说明一下,deeplab v3+ 官方要求tensorflow版本在1.6以上,但我安装1.6的时候跑deeplab的脚本总是会报参数错误,一直没找到原因,也许是版本的问题吧,换成1.9就没问题了。
另外需要注意的是,这里默认是从官网下载tensorflow,下载速度比较慢,所以需要更新源,而且是conda源,因为我们是在anaconda虚拟环境下进行操作的。更换conda源的方式:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
conda config --set show_channel_urls yes也可以修改~/.condarc文件的方式:
sudo gedit ~/.condarc
channels:
- https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
- https://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- defaults
show_channel_urls: true然后输入conda info 显示如下:
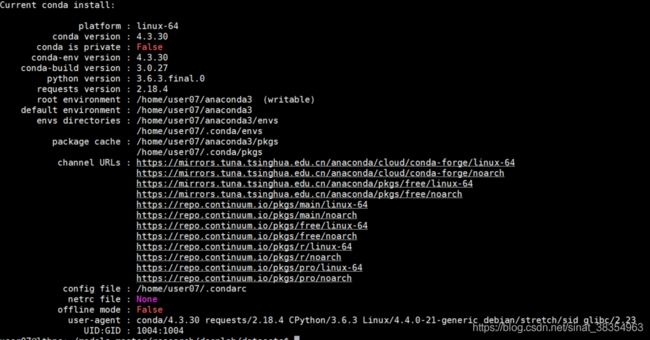
卸载tensorflow的方式:
pip uninstall tensorflow-gpu==1.9
验证tensorflow是否安装成功:

此时即成功配置tensorflow环境。
安装一些必要的依赖,都可以用pip的方式安装,以下是部分依赖,需要什么装什么:
pip install pillow
pip install numpy
pip install slim
pip install scikit-image
在该虚拟环境下进入deeplab目录,其中models-master目录为deeplab主目录:
![]()
在该目录下执行:
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim此处是把slim路径加进python路径中,不然后期执行脚本会出现找不到deeplab module的错误
此处显示python路径即为加入成功:
![]()
验证deeplab是否能够使用:

如上图所示,即为配置成功。
-----------------------------------------------------------------------分割线------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
下面介绍一下如何训练自己的数据
1.数据标注
(1)用labelme标注数据,这里我是在win10上进行的标注,具体怎么配置环境其实很简单,上面已经介绍如何配置Anaconda的虚拟环境,只要进入虚拟环境后,输入
pip install pyqt5
pip install labelme
然后输入
labelme即可打开如下界面,进行后续标注工作。
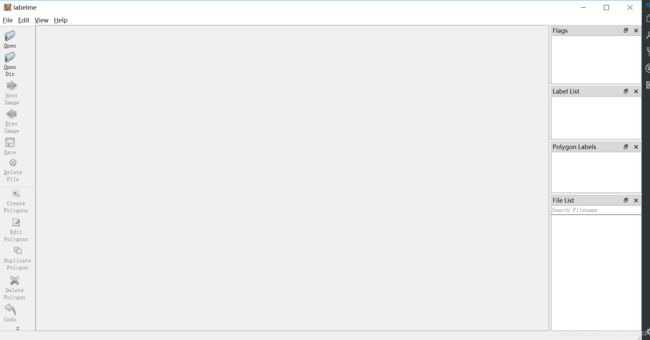
每张图片生成一个json文件,json存放位置不重要, 可以和原图在一起也可以单独一个文件夹,这都可以在labelme里面进行设置
(2)批量将标注后的json文件转化为VOC格式的数据集,我这里用以下脚本直接转换数据,绕开了用labelme自带的脚本转换,代码如下:
#!/usr/bin/env python
from __future__ import print_function
import argparse
import glob
import json
import os
import os.path as osp
import sys
import numpy as np
import PIL.Image
import labelme
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument('input_dir', help='input annotated directory')
parser.add_argument('output_dir', help='output dataset directory')
parser.add_argument('--labels', help='labels file', required=True)
args = parser.parse_args()
if osp.exists(args.output_dir):
print('Output directory already exists:', args.output_dir)
sys.exit(1)
os.makedirs(args.output_dir)
os.makedirs(osp.join(args.output_dir, 'JPEGImages'))
os.makedirs(osp.join(args.output_dir, 'SegmentationClass'))
os.makedirs(osp.join(args.output_dir, 'SegmentationClassPNG'))
os.makedirs(osp.join(args.output_dir, 'SegmentationClassVisualization'))
print('Creating dataset:', args.output_dir)
class_names = []
class_name_to_id = {}
for i, line in enumerate(open(args.labels).readlines()):
class_id = i - 1 # starts with -1
class_name = line.strip()
class_name_to_id[class_name] = class_id
if class_id == -1:
assert class_name == '__ignore__'
continue
elif class_id == 0:
assert class_name == '_background_'
class_names.append(class_name)
class_names = tuple(class_names)
print('class_names:', class_names)
out_class_names_file = osp.join(args.output_dir, 'class_names.txt')
with open(out_class_names_file, 'w') as f:
f.writelines('\n'.join(class_names))
print('Saved class_names:', out_class_names_file)
colormap = labelme.utils.label_colormap(255)
for label_file in glob.glob(osp.join(args.input_dir, '*.json')):
print('Generating dataset from:', label_file)
with open(label_file) as f:
base = osp.splitext(osp.basename(label_file))[0]
out_img_file = osp.join(
args.output_dir, 'JPEGImages', base + '.jpg')
out_lbl_file = osp.join(
args.output_dir, 'SegmentationClass', base + '.npy')
out_png_file = osp.join(
args.output_dir, 'SegmentationClassPNG', base + '.png')
out_viz_file = osp.join(
args.output_dir,
'SegmentationClassVisualization',
base + '.jpg',
)
data = json.load(f)
img_file = osp.join(osp.dirname(label_file), data['imagePath'])
img = np.asarray(PIL.Image.open(img_file))
PIL.Image.fromarray(img).save(out_img_file)
lbl = labelme.utils.shapes_to_label(
img_shape=img.shape,
shapes=data['shapes'],
label_name_to_value=class_name_to_id,
)
labelme.utils.lblsave(out_png_file, lbl)
np.save(out_lbl_file, lbl)
viz = labelme.utils.draw_label(
lbl, img, class_names, colormap=colormap)
PIL.Image.fromarray(viz).save(out_viz_file)
if __name__ == '__main__':
main()转化后的格式跟VOC2012的格式一样,我们所需要的就是转化后的SegmentationClass中的png图像,但是此文件夹下的图像是附带colormap的单通道图(可以通过matlab检验),我们还需要进一步将colormap去掉,变成单通道的灰度图,可以使用deeplab自带的remove_gt_colormap.py进一步处理成我们需要的png图像,remove_gt_colormap.py在deeplab/datasets下。
(3)将原始数据转化成tfrecord格式:
python deeplab/datasets/build_voc2012_data.py \
--image_folder="deeplab/datasets/railway/image" \
--semantic_segmentation_folder="deeplab/datasets/railway/mask" \
--list_folder="deeplab/datasets/railway/index" \
--image_format="jpg" \
--output_dir="deeplab/datasets/railway/tfrecord"其中,image_folder为原始图像的目录,semantic_segmentation_folder为标记后的单通道png图像目录,list_folder为train.txt、val.txt,trainval.txt的存放目录,output_dir为tfrecord的目录,自己创建。附train.txt、val.txt,trainval.txt生成方式,不带文件扩展名。
import os
path = 'image/'
filelist = os.listdir(path)
print(filelist)
#训练集保存方法
with open("./index/train.txt","a") as f:
i = 0
for item in filelist:
i += 1
#print('item name is ',item)
if i%10 != 0:
name = item.split('.',2)[0]
f.write(name + '\n')
with open("./index/val.txt","a") as f:
i = 0
for item in filelist:
i += 1
#print('item name is ',item)
if i%10 == 0:
name = item.split('.',2)[0]
f.write(name + '\n')
with open("./index/trainval.txt","a") as f:
i = 0
for item in filelist:
#print('item name is ',item)
name = item.split('.',2)[0]
f.write(name + '\n')
2.训练前修改操作
(1)修改segmentation_dataset.py
参照自己的目录去寻找相应路径

添加:
_RAILROAD_INFORMATON = DatasetDescriptor(
splits_to_sizes={
'train': 741, # num of samples in images/training
'trainval': 823,
'val': 82,
},
num_classes=4, #background、ignore_label、ignore_label,即label数+2
ignore_label=255,
)
_DATASETS_INFORMATION = {
'cityscapes': _CITYSCAPES_INFORMATION,
'pascal_voc_seg': _PASCAL_VOC_SEG_INFORMATION,
'ade20k': _ADE20K_INFORMATION,
'railway':_RAILROAD_INFORMATON,
}railway是自定义数据集,同样把以上内容添加到data_generator.py文件中:
不然后续会报错,训练时提示找不到自定义的数据集。
注释deeplab/train.py中第490行

不然训练时也会报错,提示参数不对。
修改deeplab/train.py中的bool值
initialize_last_layer=False
last_layers_contain_logits_only=True3.开始训练
/home/user07/tensorflow/models/research目录下(deeplab主目录)执行:
python deeplab/train.py \
--logtostderr \
--train_split="train" \
--model_variant="xception_65" \
--atrous_rates=6 \
--atrous_rates=12 \
--atrous_rates=18 \
--output_stride=16 \
--decoder_output_stride=4 \
--train_crop_size=513 \
--train_crop_size=513 \
--train_batch_size=4 \
--dataset="railway" \
--training_number_of_steps=30000 \
--fine_tune_batch_norm=false \
--tf_initial_checkpoint="deeplab/datasets/railway/init_models/deeplabv3_pascal_train_aug/model.ckpt" \
--train_logdir="deeplab/datasets/railway/train" \
--dataset_dir="/deeplab/datasets/railway/tfrecord" 其中tf_initial_checkpoint为预训练模型,github官方下载地址,下载下来的文件格式如下:

此文件夹下虽没有model.cpkt文件,但在加载模型的时候默认加载该目录下data文件以及index文件,会默认加载,不需要修改,这个也是一大坑,不知道的估计会搞半天。
训练完之后,导出模型:
在自己的数据集下写一个export_model.sh脚本,内容如下:
python /home/user07/tensorflow/models/research/deeplab/export_model.py --logtostderr --checkpoint_path="train/model.ckpt-$1" --export_path="export/frozen_inference_graph-$1.pb" --model_variant="xception_65" --atrous_rates=6 --atrous_rates=12 --atrous_rates=18 --output_stride=16 --decoder_output_stride=4 --num_classes=4 --crop_size=513 --crop_size=513 --inference_scales=1.0调用时需要的主目录下(/home/user07/tensorflow/models/research)调用,调用格式如下:
sh deeplab/datasets/railway/export_model.sh 30000