TensorFlow深度学习3--汽车油耗预测实战
本节我们将利用全连接网络模型来完成汽车的效能指标 MPG(Mile Per Gallon,每加仑燃油英里数)的预测问题实战。
1、数据集
我们采用Auto MPG数据集,它记录了各种汽车效能指标与气缸数、重量、马力等其它因子的真实数据,查看数据集的前 5项,如表1所示,其中每个字段的含义列在表2中。除了产地的数字字段表示类别外,其他字段都是数值类型。对于产地地段,1表示美国,2 表示欧洲,3 表示日本。
表 1 Auto MPG 数据集前 5 项
表 2 数据集字段含义
Auto MPG数据集一共记录了398项数据,我们从UCI服务器下载并读取数据集到DataFrame对象中,代码如下:
# 在线下载汽车效能数据集
dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(dataset_path, names=column_names,
na_values = "?", comment='\t',
sep=" ", skipinitialspace=True)
dataset = raw_dataset.copy()
统计训练集的各个字段数值的均值和标准差,并完成数据的标准化,通过norm()函数实现,代码如下:
#查看训练集的输入X的统计数据
train_stats = train_dataset.describe()
train_stats.pop("MPG")
train_stats = train_stats.transpose()
# 移动MPG油耗效能这一列为真实标签Y
train_labels = train_dataset.pop('MPG')
test_labels = test_dataset.pop('MPG')
# 标准化数据
#减去每个字段的均值,并除以标准差
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
我们可以通过简单地统计数据集中各字段之间的两两分布来观察各个字段对MPG的影响,如图1所示。可以大致观察到,其中汽车排量、重量与MPG的关系比较简单,随着排量或重量的增大,汽车的MPG降低,能耗增加;气缸数越小,汽车能做到的最好MPG也越高,越可能更节能,这都是是符合我们的生活经验的。

图 1 特征之间的两两分布
2、创建网络
考虑到Auto MPG数据集规模较小,我们只创建一个3层的全连接网络来完成 MPG值的预测任务。输入X的特征共有9种,因此第一层的输入节点数为9。第一层、第二层的输出节点数设计为64和64,由于只有一种预测值,输出层输出节点设计为 1。考虑MPG ∈R+,因此输出层的激活函数可以不加,也可以添加 ReLU 激活函数。
我们将网络实现为一个自定义网络类,只需要在初始化函数中创建各个子网络层,并在前向计算函数call中实现自定义网络类的计算逻辑即可。自定义网络类继承自keras.Model基类,这也是自定义网络类的标准写法,以方便地利用keras.Model基类提供的trainable_variables、save_weights等各种便捷功能。网络模型类实现如下:
class Network(keras.Model):
# 回归网络
def __init__(self):
super(Network, self).__init__()
# 创建3个全连接层
self.fc1 = layers.Dense(64, activation='relu')
self.fc2 = layers.Dense(64, activation='relu')
self.fc3 = layers.Dense(1)
def call(self, inputs, training=None, mask=None):
# 依次通过3个全连接层
x = self.fc1(inputs)
x = self.fc2(x)
x = self.fc3(x)
return x
3、训练与测试
在完成主网络模型类的创建后,我们来实例化网络对象和创建优化器,代码如下:
model = Network() #创建网络类实例
#通过build函数完成内部张量的创建,其中4为任意设置的batch数量,9为输入特征长度
model.build(input_shape=(None, 9))
#打印网络信息
model.summary()
#创建优化器,指定学习率
optimizer = tf.keras.optimizers.RMSprop(0.001)
程序运算时记录每个Epoch结束时的训练和测试MAE数据,并绘制变化曲线,如图2所示。
#绘制MAE变化曲线
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('MAE')
plt.plot(train_mae_losses, label='Train')
plt.plot(test_mae_losses, label='Test')
plt.legend()
plt.legend()
plt.savefig('auto.png')
plt.show()
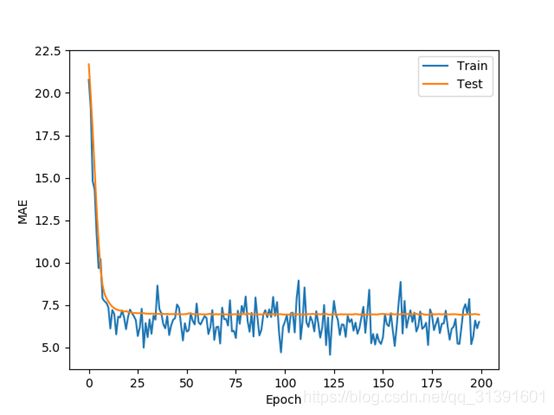
图 2 MAE 变化曲线
可以观察到,在训练到约第25 个Epoch时,MAE的下降变得较缓慢,其中训练集的MAE还在继续缓慢下降,但是测试集MAE几乎保持不变,因此可以在约第25个Epoch时提前结束训练,并利用此时的网络参数来预测新的输入样本即可。
案例源代码:https://download.csdn.net/download/qq_31391601/12559124