Spark技术内幕读书笔记:Spark核心——RDD实现详解
————Spark技术内幕读书笔记————
深入解析内核架构设计与实现原理
本书的三个核心:
RDD实现详解
Scheduler:DAGScheduler任务切分调度与TaskScheduler任务执行调度计算过程详解
性能调优详解
Spark究竟解决了什么问题?
1.背景:
在spark出现之前,hadoop的迅速发展,hadoop分布式集群,把编程简化为自动提供 位置感知性调度,容错,以及负载均衡的一种模式,用户就可以在普通的PC机上运行超大集群运算,hadoop有一个非常大的问题:hadoop是基于流处理的,hadoop会从(物理存储)hdfs中加载数据,然后处理之后再返回给物理存储hdfs中,这样不断的读取与写入,占用了大量的IO,后来hadoop出现了非循环的数据流模型,也就是DAG,但是其中任然出现了两个重大的问题:
1.任然是不断的重复写入和读取磁盘。每次操作都要完成这两步,太浪费了。
3.交互式数据查询。比如:用户不断查询具体的一个用户的子集。
2.比如,机器学习,图计算,数据挖掘方面不适用,现在要做大量的重复操作,并且下一次的开始,要依据前面计算的结果,这样对于hadoop来说就要重新的计算,从而浪费大量的资源。2.Spark到底解决了什么根本性的技术问题?
基于上述:
spak提出了分布式的内存抽象,RDD(弹性分布式数据集)支持工作集的应用,也具有数据流模型的特点,例如,自动容错,位置感知,可伸缩性和可扩展性,并且RDD支持多个查询时,显示的将工作集缓存到内存中,后续查询时能够重用工作集的结果。这样与hadoop相比,就极大的提高了速度。
RDD提供了共享内存模型,RDD本身只记录分区的集合,只能通过其他的RDD通过转换例如,map,join等操作来创建新的RDD,而RDD并不需要检查点操作,为什么?因为前后之间的RDD是有”血统”关系的,其核心原因是,每个RDD包含了从其他RDD计算出分区的所有内容,并且这个计算不是从头开始计算,而是仅仅指的是从上一步开始计算得到即可,这也就实现了工作集的复用。
Spark周围的SQL,机器学习,图计算都是基于此构建出来的,使得Spark成为一体化的大数据平台,不仅降低了各个开发,运维的成本,也提高了性能。
Spark的应用场景
DataBricks公司全面替代Hadoop中的MapReduce的分布式数据集计算框架,解决数据规模的爆炸式增长与计算场景的丰富细化,以应对MapReduce难以满足的各种计算需求而生。支持实时流计算(动态数据及时处理)、批计算(历史的离线静态数据处理)、交互查询与图计算一体。
Spark Sore内核:是spark sql(结构化数据处理模块) 、 spark streaming(实时数据流处理)、MLlib(机器学习算法库)、Graphx(图计算)的模块基础,以上的四大模块运用都是基于内核进行计算的。
掌握内核好处:开发更游刃有余、调优做到有的放矢。
设计目标:解决大数据处理的4V难题
- 海量Volume
- 快速Velocity
- 多样Variety
- 价值Value
————第一章:Spark简介与环境————
基础概念
DAG: Directed Acyclic Graph,有向无环图
数据处理方式:从分布式文件系统或HDFS存储平台是中加载记录日志,传入由一组确定性操作构成的DAG,最终再写回HDFS或指定系统中。
DAG可以在运行时自动实现任务高度与故障恢复。
RDD:弹性分布式数据集(Resilient Distributed Dataset),只读的、分区记录的集合。
为了解决MR在处理时需要把数据 输出到磁盘并在下次处理时重新加载所带来的开销,Spark引入了一种分布式内存抽象,允许我们在执行多个查询时将工作集缓存到共享的内存中,后续查询链可以重用上一个工作集,以提升查询的速度。
SparkContext:用户程序与Spark集群交互时的接口
ClusterManager:负责集群资源管理和高度的系统 ,如Yarn,Standalone,Mesos
Executor:各集群分机上的一个进程,负责运行分配到的任务以及将数据存储到内存或磁盘上
Driver:用户编写的APP数据处理逻辑程序
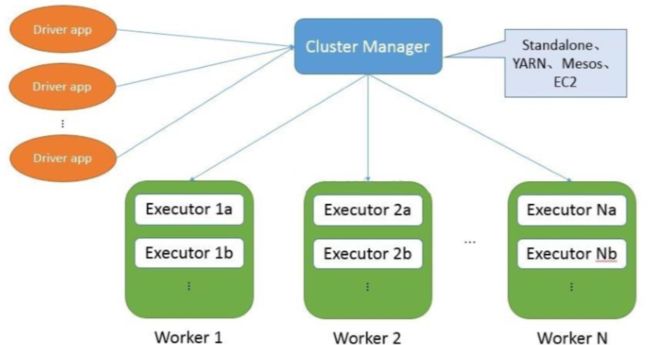
Spark数据处理执行过程
- Driver创建SparkContext时,SparkContext会连接到ClusterManager,ClusterManager再根据用户提交时所设置的CPU和内存等信息,为本次提交分配计算资源 ,启动Executor。
- Driver会将用户程序划分为不同的执行阶段,每个阶段Stage由一组完全相同的Task组成,这些Task分别作用于待处理数据的不同分区上。在阶段划分完成后和Task创建后,Driver会向Executor发送Task。
- Executor接收到Task后,会下载Task运行时的依赖,在准备好Task的执行环境后,开始执行Task,并将Task的运行状态汇报给Driver。
- Driver会根据收到的Task的运行状态来处理不同的状态更新。Task分为两种:
- Shuffle MapTask:实现数据的重新洗牌,洗牌的结果保存到Executor所在的节点的文件系统中
- Result Task:负责生成结果 数据
- Driver会不断调用Task,将Task发送到Executor执行,在所有的Task都正确执行或者超过执行次数限制仍然没有执行成功时停止。
————第二章:RDD实现详解————
RDD之所以为“弹性”的特点
- 基于Lineage的高效容错(第n个节点出错,会从第n-1个节点恢复,血统容错);
- Task如果失败会自动进行特定次数的重试(默认4次);
- Stage如果失败会自动进行特定次数的重试(可以值运行计算失败的阶段),只计算失败的数据分片;
- 数据调度弹性:DAG TASK 和资源管理无关;
- checkpoint;
- 自动的进行内存和磁盘数据存储的切换;
RDD的特点
- 一到多个有序的Partition分片的集合: 每个分片会被 一个计算任务处理,决定了并行计算的粒度。用户在创建RDD时可以选择指定RDD的分区个数。分区是由BlockManager实现的,BlockManager将文件映射成一个个的Block块,每个Block会被一个Task负责计算
- 函数是针对每个RDD上的分片进行计算的,当一个函数对具体的分区进行计算时,由于RDD中的分区是并行的,所以是分布式并行计算。
- RDD有前后依赖关系,遇到宽依赖时,如reduceByKey操作时划分为不同的Stage阶段,在一个Stage内部的操作是通过Pipeline进行处理的,也就是说当没有执行宽依赖时,它在一个或多个节点间是会形成类似流水线Pipeline进行处理的,因为RDD之间在的关系是很明确的。但一旦进行Shuffle,宽依赖后,所有RDD分片内的数据就打乱了,所以就无法再进行
- k-v的RDD使用默认的HashPartitioner分片策略。分片内容很多很杂,不再展开讲,有根据hashcode, Range……
- Partition优先位置原则:【移动数据不如移动计算】理念,spark在进行调度时,它可以利用HDFS的设计方式,通过Namenode拿到数据块所在的位置后会尽量将计算任务分配到其所要处理数据块所在的存储位置的Executor上。
疑问1:Shuffle就一定写盘吗?
在Spark 0.6和0.7时,Shuffle的结果都需要先存储到内存中(有可能要写入磁盘),因此对于大数据量的情况下,发生GC和OOM的概率非常大。因此在Spark 0.8的时候,Shuffle的每个record都会直接写入磁盘,并且为下游的每个Task都生成一个单独的文件。这样解决了Shuffle解决都需要存入内存的问题,但是又引入了另外一个问题:生成的小文件过多,尤其在每个文件的数据量不大而文件特别多的时候,大量的随机读会非常影响性能。Spark 0.8.1为了解决0.8中引入的问题,引入了FileConsolidation机制,在一定程度上解决了这个问题。由此可见,Hash Based Shuffle在Scalability方面的确有局限性。而Spark1.0中引入的Shuffle Pluggable Framework,为加入新的Shuffle机制和引入第三方的Shuffle机制奠定了基础。在Spark1.1的时候,引入了Sort Based Shuffle;并且在Spark1.2.0时,Sort Based Shuffle已经成为Shuffle的默认选项。但是,随着内存成本的不断下降和容量的不断上升,Spark Core会在未来重新将Shuffle的过程全部是in memory的吗?我认为这个不太可能也没太大必要,如果用户对于性能有比较苛刻的要求而Shuffle的过程的确是性能优化的重点,那么可以尝试以下实现方式:
Worker的节点采用固态硬盘
Woker的Shuffle结果保存到RAMDisk上
根据自己的应用场景,实现自己的Shuffle机制
疑问2:Partitioner的几种策略以及它们都在解决什么问题?
疑问3:Shuffle与钨丝计划究竟差在哪里,用在什么场景?
疑问4:Spark Shuffle的发展历程?
RDD创建的两种方式
- 从已有Scala集合在处理过程中创建
- 由外部存储系统 的数据集中创建:本地文件系统 ,HDFS,Cassandra、HBase、S3等
RDD支持的两种操作函数
- 转换:Transformation 从现有数据集创建一个新的数据集,RDD的转换都是Lazy的,延迟加载,只有当需要Action即返回结果给Driver的动作时才会一起执行,这样更利于Spark做优化,函数见表3-1
- 动作:Action 在数据集上进行运算,计算后得出结果,并返回一个值给Driver程序 。每一个转换过的RDD在它一个Action时都会被重新计算,可以用实用persist或cache方法,在内存中持久化一个RDD,这样Spark会在集群中保存相关元素,下次查询这个RDD时可以更快去访问它。也可以存储到所在节点的磁盘上,或在集群间复制数据集。函数见表3-2
常用的转换与动作函数:
RDD的缓存:cache()
因为RDD的Transformation 都是Lazy的,这就意味着在调用Action操作之前Spark是不会计算的,Spark会在内部记录所要求的执行步骤的全部流程,构建一个有向无环图(DAG)。同样在把数据读入到RDD的操作也是惰性的。由于这个特性,有时候需要能够多次使用同一个RDD时,如果简单地对RDD调用action操作,Spark每次都会重算RDD和它的所有依赖,这样子消耗很大。利用缓存可以让action计算速度加快(通常会加速10倍),并将此数据集(或衍生出的新数据集)提供给其它Action中重用,使得后续的Action变得更加快,缓存是Spark构建出迭代式算法和快速交互式查询的关键。
方法:persist()设置缓存级别,cache()开始缓存,其中cache()是Lazy的,也就是遇到Action才会被触发执行
/** Persist this RDD with the default storage_level('MEMORY_ONLY') */
def persist():this.type = persist(StorageLevel.MEMORY_ONLY)
def cache():this.type = persist()
如:从RDD0–>RDD1–>RDD2–>RDD3–>RDD4–>RDD5–>RDD7
若RDD3已经缓存在系统中了,在进行0-7的计算时,0-3就不会重复进行计算,所以速度就有所提升。rdd3.cache 触发:rdd3.collect
也就是说针对一些计算复杂的Task,可以分步缓存以加快下一次的计算速度。

缓存有可能会丢失,或者存储在内存中的数据会因内存不足而被删除,RDD的容错机制使得RDD即使丢失也可以通过DAG的lineage血缘关系对丢失部分数据进行重算,且RDD的各分片是相对独立的,只需要计算丢失的分片即可。
为了避免缓存丢失重新计算带来的开销,Spark又设计了checkpoint检查点机制,类似于快照。
检查步骤:
- 设置存储目录:sc.setCheckpointDir(“hdfs://master:9000/rdd-ck”),如果没有会自动创建。千万不能用本地文件系统,如果有多个分区时,每个Executor只能把缓存自己的数据,恢复也只能恢复属于自己的数据,而不是全部数据
- 对指定rdd进行缓存:rdd3.checkpoint
- 触发: rdd3.collect 将rdd3中的数据存储到hdfs中去
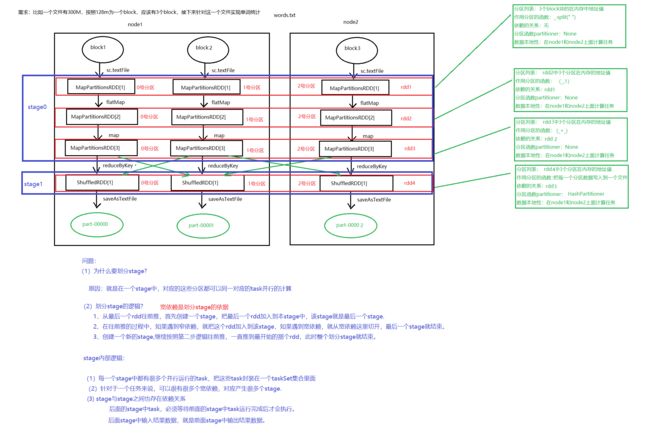
以WC为例看RDD的转换过程与DAG生成.

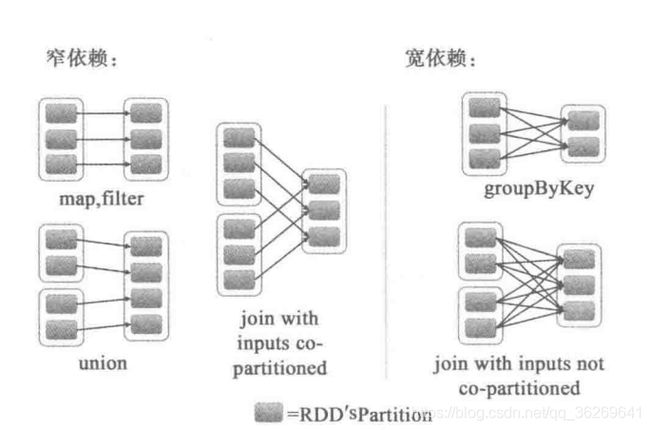
RDD宽依赖与窄依赖
- 宽依赖: ShuffleDependency 即子RDD依赖于parent RDD 的所有Partition
- 窄依赖: 分两种依赖
- 一对一依赖:OneToOneDependency 子RDD仅依赖parentRDD相同的Partition
- 范围依赖:RangeDependency 一对多,即把多个RDD合成一个RDD。一定范围的RDD直接对应,最典型的是Union。
- parent RDD的某个分区的partitions对应到child RDD中某个区间的partitions;
- union:多个parent RDD合并到一个chind RDD,故每个parent RDD都对应到child RDD中的一个区间;
注意:union不会把多个partition合并成一个partition,而是简单的把多个RDD的partitions放到一个RDD中,partition不会发生变化。
我们就根据宽依赖将DAG中Stage划分为不同的阶段,在每一个Stage内部中都会包含一个窄依赖,里面的每个Partition都会被分配给一个Task计算任务,分布式的多个Partition之间是并行运行的。而Stage之间的依赖就变成一个粗粒度的DAG,执行顺序从前一直往后,必须等父stage执行完成,才可以开始执行当前的Stage。
RDD的转换:

Spark HadoopRDD读取HDFS文件的过程
如有此文本文件:a b k l j
c a n m o
细节如下图:



RDD逻辑关系转换的过程
细节如下图:
在进行reduceByKey()时会触发一个Shuffle的过程。在Shuffle开始之前,有一个本地聚合的过程,会将第三个RDD分片中的(c,1)(c,1)–>(c,2), (e,1)(e,1)–>(e,2)在Partition内部事先进行一个小合成。
RDD计算
如下图: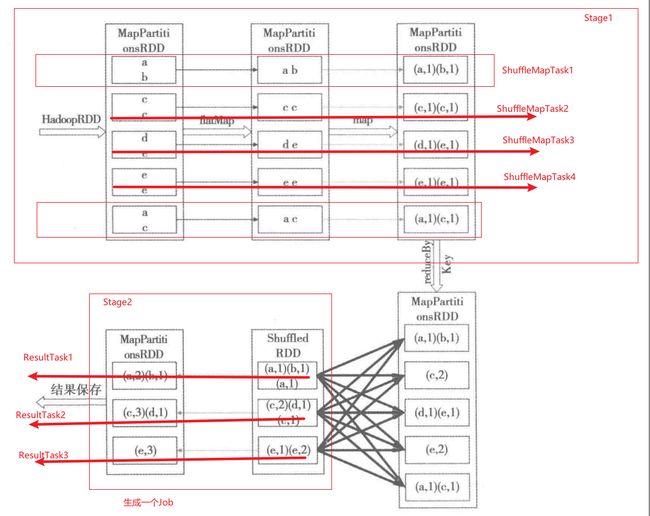
Task执行源码与CheckPoint过程
参考:
Spark HadoopRDD读取HDFS文件