Spark RDD详解与优化
Spark RDD详解与优化
-
- Spark的特性
-
- RDD的五大属性
- Spark的运行模式
- Spark提交模式
- RDD的shuffle
- RDD的广播变量
- RDD的stage及宽窄依赖和血统
- RDD的persist、cache与checkpoint
- Spark分布执行时的序列化问题
- Spark常见JDBC
-
- hbase on Spark和Spark on hbase
- Cassandra on Spark
- Spark on hive和hive on Spark
- RDD的常用算子
-
- 转换算子(其返回值为另一个RDD的算子)
- action算子(返回值非RDD或无返回值)
- 自定义算子
- Spark的优化
-
- 提交
- 参数
- 算子的优化使用
- 开启Kryo序列化
- 使用fastutil优化数据格式
Spark的特性
RDD的五大属性
1.分区列表数,每个分区对应了一个task线程,其上限不超过读取数据的分区数
2.每个分区的计算函数,即该RDD的运行函数
3.RDD对其它RDD的依赖列表,是一个Array数组,可以通过getclass方法查看以来类型,若返回OneToOneDependency则是窄依赖返回ShuffleDependency是宽依赖
4.kv型RDD的分区函数,有HashPartitioner和RangePartitioner两大类,其中HashPartitioner是对key的内容取哈希,并将一定范围内的哈希值放入同一个分区中,能够解决绝大部分分区的数据热点问题;对于RangePartitioner,要求key必须可排序,采用水塘抽样算法将key划分一定分区,再将key按照分区归类。
对于不同业务场景也可以采用自定义分区,创建一个继承自Partitioner的类,重写numPartitions和getPartition即可
5.RDD的Partition的优先位置列表,能够指定是否优先使用本地数据,减少io。可通过.preferredLocations(split: Partition)方法查看,从高至低共有PROCESS_LOCAL(同一executor)、 NODE_LOCAL(同一个worker)、NO_PREF(无位置优先)、RACK_LOCAL(同一机架)、ANY(跨机架)五个级别。TaskScheduler会按照高优先级往低依次执行发送task给executor,如果连续5次等待时间超时(默认3s)则降低优先级再次发送。该时间由SparkConf()中的Spark.locality.wait设置,可通过增加该时间提高每一个task都能拿到最好的数据本地化级别
Spark的运行模式
local模式
不启用Spark集群,只在本地运行,一般用于本地测试
standAlone
Spark自带的独立运行模式,整个任务的资源分配由Spark集群的Master负责
Spark on yarn
的cluster模式可能经常会出现bug,比如运行的jar包不在$Spark_HOME/jars下很可能报错等自身的稳定性问题
Spark on Kubernetes
通过在k8s上运行Spark从长期上来讲优势肯定高于部署于yarn,比如k8s对非jvm框架的管理要比yarn方便很多,原生yarn不支持在离线混部(听说字节的yarn改造后可将多余的线上资源分配给线下,但也不够灵活),同时yarn的耦合度较高也使得不同组件的版本管理较为严格不能灵活分配。
Spark on Mesos
Mesos是Apache的老一代资源管理架构,其在分布式资源调度上不如yarn灵活,目前少有公司使用
Spark提交模式
每种运行模式具有两种提交模式(local模式除外):client和cluster
Client模式其Spark执行入口driver模块运行在本地机器上。优点是相对较稳定,可以随时通过客户端查看运行结果与日志;但一个庞大Spark任务的提交会导致driver进行大量的DAG分解与task分解,并不停将task分配给不同worker中的executor并等待其运行结束信息返回,这个过程会消耗大量内存和io资源
Cluster模式其driver运行在某一个集群中的worker上,需要将jar包传至每个worker都能访问到的位置如hdfs。优点是不会造成流量激增;缺点是不能够直接查看日志与运行结果,同时其稳定性略逊于Client模式(例如有时jar包在hdfs上但确无法通过指定路径找到,需要将jar包移至$Spark_HOME/jars下)
依据提交模式的特色,对于大公司可以选择使用Client模式,单独将几台高配机器作为Client模式的提交端,一方面便于使用azkaban或oozie统一调度,另一方面也能够直接调取结果和日志;对于小公司或不需要查看中间结果的数据(如结果直接落盘)的情况,使用Cluster模式则能避免流量激增的问题
RDD的shuffle
RDD对shuffle的方式在不同版本经过了多次衍变
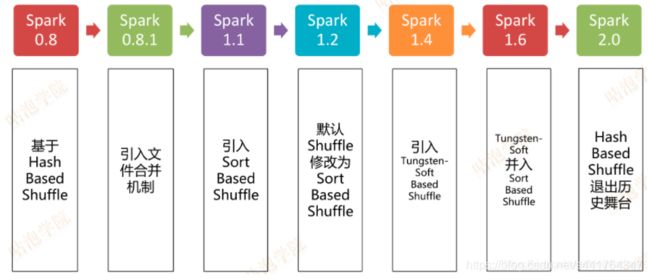
其中HashBasedShuffle,每一个mapper会为reducer生成一个文件来保存计算的信息,并按hash划分至不同的task中去,这样会产生m*r个小文件,数量过大且io、gc频繁
引入File Consolidation文件合并机制,即在mapper后将同一个executor指向同一个reducer的文件合并,只会产生e*r个文件,仍会产生较多文件
进一步SortShuffleManager,其有两种模式,如果shuffle read task小于200且为非aggregate类算子会采用bypass模式,否则使用一般模式
一般模式,在内存写满并准备落盘前会首先数据进行排序,将排序后的数据多次溢写,整个map阶段完成后会将溢写的小文件合并生成一个大文件以及一个提供给task的数据起始结束start offset/end offset索引,最后由reducer去依据索引拉取该大文件中的数据
bypass模式则针对小数据场景,跳过了数据排序阶段,直接对数据取hash来进行task的分配,再溢写入小文件最后合并大文件并生成索引
Tungsten的优化,针对非aggregate算子提供更高效的内存和缓存,减少存储空间,提高缓存命中
RDD的广播变量
对于非大量数据的复用(例如频繁业务大表join逻辑小表),就可以将这些数据(RDD中的数据需要collect或collectAsMap)广播至每个executor的内存中,减少了数据的传输。使用Broadcast类的broadcast方法即可。合理使用能够减少shuffle的使用
RDD的stage及宽窄依赖和血统
stage(也叫taskset)的划分,首先对任务最后一个RDD创建finalStage,然后对其的父RDD依次做getShuffleDependencies判断是否有shuffle发生,如果发生,生成一个新的stage,如果没有,则该RDD和父RDD按顺序压栈,这样的话同一个stage的RDD就会在EventLoop里按顺序一起执行
而shuffle的发生则是触发了combineByKeyWithClassTag,所有PairRDDFunctions类下的方法都会触发shuffle,从用法上来说所有RDD聚合操作都会产生shuffle
进而Spark将是否触发stage划分的操作划为两类:宽依赖wide depencency和窄依赖narrow dependency,凡是触发shuffle及stage划分的都是宽依赖,反之则是窄依赖
整个任务的依赖关系图被称为血统lineage,它的作用是依据依赖关系在编译阶段就生成并为DAG提供stage划分点以及Spark的数据自动容错机制
当某一节点挂掉或数据丢失时,Spark会自动在其它可用节点计算丢失的数据部分即可,而依据血统则不需要重新跑一整遍程序。对于窄依赖只需重新计算其父RDD,对于宽依赖,则需要重新计算其每一个父分区
RDD的persist、cache与checkpoint
Spark能够手动将计算过程的数据进行保存,对于任何一个RDD,都能直接调用persist、cache与checkpoint方法
persist与cache会在触发action算子后缓存至指定位置,persist能够选择缓存至内存、磁盘及它们的混合策略(1.6+支持堆外缓存),而cache则是调用了persist只缓存至内存的方法。一般使用在某RDD被下游RDD多次使用时或一行RDD代码进行了多次操作(常见于mlib以及一行代码写太长的人)的场景时使用,其即便序列化后也会在Spark程序执行完成后自动删除,也可使用unpersist方法手动清理缓存
checkpoint则不同于上述缓存的临时性数据保存,可以落盘或存储在hdfs上,即便程序结束依旧存在,可以随时再运行恢复。同时该操作会清空checkpoint之前的血统依赖,且是启动另一个相同内容的job重新计算,故建议在checkpoint操作前先缓存。值得注意的是用户自定义的RDD及算子也会被保存至checkpoint中下次再运行,所以如果改变这些内容再次用checkpoint运行会导致不一样的结果
Spark分布执行时的序列化问题
在RDD的分布式运行中自然伴随着多次序列化/反序列化,而使用外部变量/类/函数若没继承自Serializable,在Spark运行中便会经常报org.apache.Spark.SparkException: Task not serializable这个错
所以解决办法就是让这些类都继承自Serializable,且成员变量也要序列化,而对于jdbc连接之类无需序列化的,可以用@transient注解跳过序列化
Spark常见JDBC
hbase on Spark和Spark on hbase
hbase on Spark
在构建SparkContext后可通过newAPIHadoopRDD方法来创建从hdfs中读取数据源的RDD,配合hbase的参数配置即可直接读取hfile中的数据。也可将RDD通过saveAsNewAPIHadoopDataset的方法写入hbase
Spark on hbase
比起利用hdfs作为中间层的方法,该方法提供了Spark与hbase无缝连接的方法,并可以使用hbase的bulkload方法(但实现都是社区库与第三方方法,稳定性值得考量)
通过构建HBaseContext类来创建hbaseRDD,直接使用scan、bulkPut方法来读写数据(以华为Spark-SQL-on-HBase)为例
Cassandra on Spark
C*在外企较火,在连接C*时需要依赖Spark-cassandra-connector,其sql风格写法是在构建SparkSession后直接使用write/read方法,并添加C*的连接属性
Spark on hive和hive on Spark
Spark on hive,通过脚本写入sql语句操作RDD算子,通过数据库驱动改变hive元数据,再读取/写入hive中
hive on Spark,将hive的mr运算替换为Spark运算,需要Spark编译去包含hive jar的版本,并配置hive及yarn的驱动即可
RDD的常用算子
转换算子(其返回值为另一个RDD的算子)
| 操作类 | 描述 |
|---|---|
| map | 对RDD中的每一个元素都执行一个指定的函数l来产生一个新的RDD(任何原RDD中的元素在新RDD中有且只有一个对应) |
| mapPartitions | 与map功能类似,一次函数调用会处理一个partition所有的数据,而不是一次函数调用处理一条,性能相对高一些(易导致oom) |
| mapPartitionsWithIndex | 相比于上一个多了分区索引的输入参数 |
| flatmap | 对RDD每个元素执行函数,并合并为一个元素 |
| 键值转换类 | 描述 |
|---|---|
| mapValues | 原RDD中的Key保持不变,与新的Value一起组成新的RDD中的元素 |
| flatMapValues | 针对flapmap使用的key不变,value改变,可多输出 |
| cogroup(1到3个RDD) | 相当于对RDD进行全外连接,关联不到为空 |
| join类 | 描述(实质是先做cogroup,再flatmapvalues) |
|---|---|
| join | 相当于左内连接 |
| leftOuterJoin | 左外连接 |
| rightOuterJoin | 右外连接 |
| fullOuterJoin | 全连接 |
| 运算类 | 描述 |
|---|---|
| foreach | 每个元素做运算 |
| foreachPartition | 每个分区做运算 |
| reduce | 每个元素做判断并剔除并减去空分区 |
| 去重类 | 描述 |
|---|---|
| distinct | 全部分区去重(实际上是RDD做了一个reduceByKey的操作将key聚合,再取key值) |
| distinct(numPartitions: Int) | 指定分区去重 |
| 重分区类 | 描述 |
|---|---|
| coalesce | 采用HashPartitioner重新设置有几个分区,如果false则无法超过原分区,true才可以 |
| repartition | 上述参数为ture的简化方法 |
| partitionBy | 采用指定方法(可自定义)重分区,只能用于PairRDD |
| 拆分/合并类 | 描述 |
|---|---|
| randomSplit | 将一个RDD按数组权重(加起来可不为1)重新分配成多个RDD,返回一个RDD数组 |
| glom | 将RDD内的所有同一泛型元素放到一个数组里 |
| union | 合并两RDD,元素不去重,不能合并不同类型的RDD |
| intersection | 返回两个RDD的交集,去重 |
| subtract | 返回第一个RDD与第二个的差集 |
| 组合类 | 描述 |
|---|---|
| zip | 将两个相同分区数,元素数量的RDD组成(k,v)对形式,自身是key,另一个是value如果长度不同会抛异常 |
| zipPartitions | 方法里需要完成一个迭代器,通过迭代器输出多个RDD的组合结果 |
| zipWithIndex | 将RDD中的元素逐个与其id(索引号)组成键值对,例RDD1(“a”,“b”).zipWithIndex() -> (a,0),(b,1) |
| zipWithUniqueId | 将RDD中的元素诸葛与其分区id组成键值对,分区id排列规则:从第一个分区第一个到最后一个分区第一个再到第一分区第二个。例RDD1(“a”,“b”,“c”,2).zipWithUniqueId() -> (a,0)(b,2),(c,1) |
action算子(返回值非RDD或无返回值)
| action算子类 | 描述 |
|---|---|
| aggregateByKey | 在初始值基础上,先对分区内元素运算,再对分区间运算 |
| combineByKey | 用于将(k,v)类型聚合为(k,c),key不变,对value进行处理 |
| foldByKey | 用于将(k,v)类型折叠、聚合。需要输入一个int,与一个函数,先将v与int进行函数,再将相同key按函数聚合 |
| reduceByKey | 用于将(k,v)类型每一个相同key的value经过函数互相计算 |
| groupByKey | 用于将(k,v)类型的每一个相同key的value组成一个集合 |
自定义算子
当Spark已有算子无法满足需求或可以将固定业务场景优化成一个算子时,可以使用自定义算子。定义一个具有隐式转行伴生对象的工具类即可,在伴生类中实现算子的操作方法
Spark的优化
提交
高可用模式的提交
在Spark-submit阶段指定一个以上master节点,这样一旦某个master挂掉会立马自动启用备用节点
job的提交
默认DAGScheduler采用submitJob方法,以非阻塞的形式提交作业,并返回JobWaiter,用户可以调用JobWaiter中的awaitResult方法等待作业完成,并取得结果,或者调用cancel方法来取消作业的运行
但也可指定runApproximateJob方法,以阻塞的形式提交作业,并设定等待时间,当等待时间到达时用户会得到近似或完整(作业运行完)的结果,在高峰时非核心业务提交时可采用该方法,防止占用资源过多
参数
spark-defaults.conf的调优
参数的修改建议在任务提交的时候以下述行式修改,这样是只针对本次任务,也可以修改Spark-defaults.conf或代码中SparkConf.set(“参数名”,“数值”)的形势修改
-submit --conf 参数名=数值
spark.locality.wait
本地化级别的响应等待时间(默认3s),建议增加,一般可减少io
spark.reducer.maxSizeInFlight
shuffle read task的缓冲大小(默认48m),如果会产生大量小文件建议调小,减少内存压力如24m
spark.shuffle.file.buffer
shuffle write task的缓冲输出流大小(默认32k),如果内存足够可以调大为64k,能够减少溢写次数提高io
spark.shuffle.io.maxRetries
shuffle reduce阶段拉取数据的尝试次数(默认3),超过该次数会导致任务失败,故运算大的任务可增大此参数如50,提高稳定性
spark.shuffle.io.retryWait
上述情况的等待间隔(默认5s),同样对于大任务增加此值如30s
spark.shuffle.memoryFraction
在executor中分配给shuffle read task的内存比例(默认0.2),如果持久化内容较少,可提高该比例,加速运算
spark.shuffle.sort.bypassMergeThreshold
SortShuffleManager触发bypass的阈值(默认200),如数据不需要排序,可提高,但可能会导致小文件较多
spark.defalut.parallelism
可提高task的数量,建议设为cpu核数的2-3倍
spark.memory.offHeap.enabled
可开启堆外内存(Spark1.6+),减少内存消耗
spark.memory.offHeap.size
设置堆外内存大小,建议10G起步
spark.executor.memoryOverhead
Spark向资源调度(如yarn)申请的堆外内存大小,需大于spark.memory.offHeap.size
算子的优化使用
reduceByKey和aggregateByKey相比groupByKey能够预聚合减少io
mapPartitions相比map能够减少调用,但可能会导致OOM
foreachPartitions相比foreach同上
repartitionAndSortWithinPartitions相比repartition与sort能够在重分区的同时进行排序,如需重分区并排序优先使用前者
开启Kryo序列化
SparkConf的Spark.serializer设置为org.apache.Spark.serializer.KryoSerializer,同时使用registerKryoClasses方法注册需要Kryo序列化的自定义类型
使用fastutil优化数据格式
加入fastutil依赖并用IntList替代List