pytorch模型 推理部分的实现
记录完整实现他人模型的训练部分的过程
实现模型推理部分
- 项目场景
- 问题描述
- 报错记录
- 解决方案
项目场景
训练完深度学习模型之后,对于模型推理部分的实现
问题描述
在学习NER模型,下载学习使用别人的模型,完成了训练部分,但是不知道具体的使用方法,即实现如何推理,对于模型的感知和理解处在一个黑盒的状态。
报错记录
在实现推理时报了太多太多的错,以至于接近崩溃
报错情景如下:
stri="改善人民生活水平,建设社会主义政治经济。"
sen=[word_to_idx[word] for word in stri]
train_xs = torch.from_numpy(sen).int()
label=model(train_xs)
print(label)
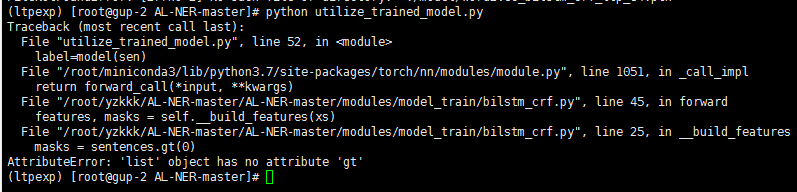
这里说明我们的输入不能是list,后面查看了torch.from_numpy接口传入的参数必须是ndarray类型的,所以这里,需要对sen进行处理
stri="改善人民生活水平,建设社会主义政治经济。"
sen=[word_to_idx[word] for word in stri]
train_xs = torch.from_numpy(np.ndarray(sen)).int()
label=model(train_xs)
print(label)

感觉还是数据格式不对,去看看训练的代码
sen=[word_to_idx[word] for word in stri]
if(len(sen)<64):
sen=sen+[0]*(64-len(sen))
vecarray=np.array(sen,dtype='int64')#把格式设置成符合训练时的int64,并重新传入数据
train_xs = torch.from_numpy(vecarray).int()
又产生了新的错误

而且此时搭建的虚拟环境,也出了问题,代码突然无法运行,又调整了/root/miniconda3/lib/python3.7/site-packages/torch/nn/utils/rnn.py
File "/root/miniconda3/lib/python3.7/site-packages/torch/nn/utils/rnn.py", line 249, in pack_padded_sequence
_VF._pack_padded_sequence(input, lengths, batch_first)
RuntimeError: 'lengths' argument should be a 1D CPU int64 tensor, but got 1D cuda:0 Long tensor
把lengths-->lengths.cpu()
解决方案
考虑到不能这样无脑的去硬改,回去读了模型训练的源码,观察其读取训练集的格式,梳理清楚接口使用逻辑
训练集的数据处理
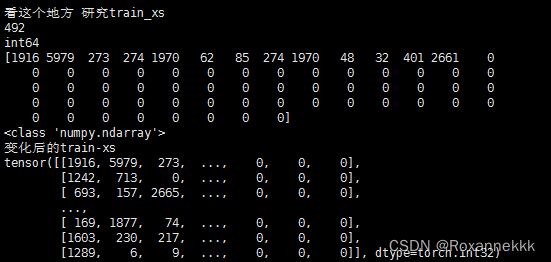
自己写的数据
确定了数据输入格式的正确性,考虑是否是输入的方法问题
是不是我需要把数据转化成句子列表?检查训练数据是怎么加载的得到的
结合调用逻辑,去梳理了代码思路
#Word2VecBiLSTMCRFALPipeline.py
train_xs, train_ys = self.datapool.get_annotated_data()
#Datapool.py
def get_annotated_data(self) -> Tuple[np.ndarray, np.ndarray]:
return self.annotated_texts, self.annotated_labels
self.annotated_texts = np.array(annotated_texts)
def __init__(self, annotated_texts: list, annotated_labels: list,
unannotated_texts: list, unannotated_labels: list) -> None:
#所以train_xs 源于 init的时候赋值,是一个列表
# 追溯到data_loader.py
datapool = DataPool(annotated_texts=annotated_texts, annotated_labels=annotated_labels,
unannotated_texts=[], unannotated_labels=[])
annotated_labels, train_statistics, annotated_texts = self._load_from_file(entity_type, name + "-train",
train_path, max_seq_len)
#检查self._load_from_file annotated_texts是第三个参数
# trainpath=../datasets/BosonNLP_NER_6C/ 数据集的位置 使用的时候加了"train.txt",访问的是训练集
def _load_from_file(self, entity_type, name, train_path, max_seq_len):
lines = open(train_path, 'r', encoding='utf8').readlines()
texts, labels = [], []
text, label = [], []
statistics = {"corpus_name": name, "#E": entity_type, "#S": 0, "#T": 0,
"ASL": 0, "AEL": 0, "%PT": 0, "%AC": 0, "%DAC": 0, "TE": 0}
for line in lines:
if len(line) < 2:#如果碰到某一行长度<2 说明是空行?但不是应该==0?
if len(text) < 2: # To avoid empty lines
text, label = [], []
continue
texts.append(self.sentences_to_vec(text, max_seq_len))
labels.append(self.tags_to_vec(label, max_seq_len))
statistics = self.update_statistics(statistics, label)
text, label = [], []
continue
char, tag = line.strip().split()
text.append(char)
label.append(tag)
return labels, statistics, texts
#观察源码可知,是一个二维列表
最后得到了输入的结论,成功运行起代码,得到结果
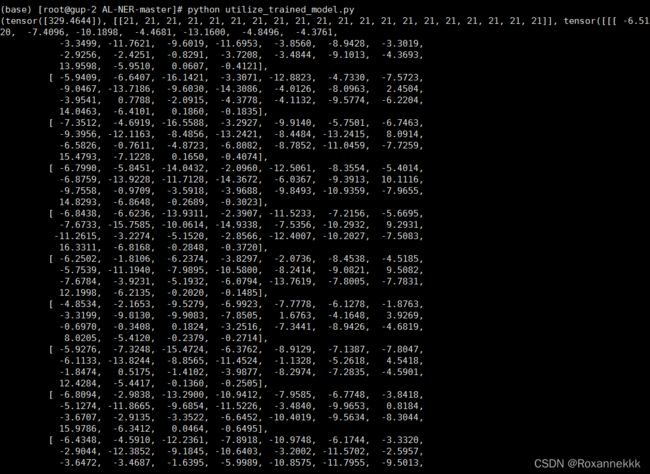
解码后,得到了我们想要的结果,进行一定的处理,完善了推理的实现,以及展示
把需要标注的语句存放的txt中,返回每一个句子的实体和其标签–元组形式

重点在于:
- 梳理接口调用逻辑(结合编译器去查看)
- 确定数据的输入格式,输入情况(查看生成训练集调用的接口方法,比如datapool,train等)
- 得到结果后的整理,展示