语音识别工具kaldi简介
1.简介
Kaldi 是一个语音识别工具。使用 C++ 开发,基于 Apache 许可证。目的是为语音识别研究者提供。
Kaldi集成了多种语音识别模型,包括隐马尔可夫和最新的深度学习神经网络,自 2011 年发布以来下载量超过了两万多次。无论是工业界还是学术界,几乎所有的语音团队都在使用Kaldi引擎来开发智能解决方案,包括MIT、哈佛、清华、微软、谷歌、Facebook等等。
2.Kaldi之父
Daniel Povey是语音识别领域的执牛耳者,他主要开发和维护的开源工具Kaldi,是业界公认的语音识别框架的基石,他也被称为Kaldi之父。
Daniel在2012年加入约翰斯·霍普金斯大学,担任语言和语音处理中心任副教授。在此之前,他在IBM研究院、微软研究院从事计算机语音识别研究。2019年10月,Daniel正式加入小米公司,担任小米集团首席语音科学家。
3.Kaldi架构

最上面是外部的工具,包括用于线性代数库BLAS/LAPACK和OpenFst。中间是Kaldi的库,包括HMM和GMM等代码,下面是编译出来的可执行程序,最下面则是脚本,用于实现语音识别的不同步骤(比如特征提取,比如训练单因子模型等等)。
对应大部分Kaldi的用户来说,我们只需要使用脚本和配置文件就可以完成语音识别系统的训练和预测了
3.1.OpenFst
OpenFst是一个用于构造,组合,优化和搜索加权有限状态转换器(FST)的库。
FST在语音识别和合成,机器翻译,光学字符识别,模式匹配,字符串处理,机器学习,信息提取和检索等方面具有关键应用。
通常,加权转换器用于表示概率模型(例如,n元语法模型,发音模型)。可以通过确定和最小化来优化FST,可以将模型应用于假设集(也表示为自动机)或通过有限状态组成进行级联,并且可以通过最短路径算法选择最佳结果。
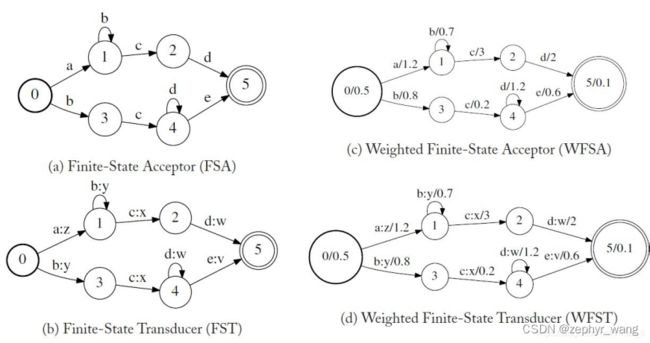
有限自动机(Finite Automata, FA) 是由一组有限的状态和状态转移的集合组成,其每一个转移都至少有一个标签。最基本的FA是有限状态接收器(Finite State Acceptor,FSA)。对于给定的输入序列,FSA返回“接收”或者“不接收”两种状态。
图1(a)是一个FSA的示例,其节点和弧分别对应状态与状态的转移。例如,FSA可通过0,1,1,2,5接收一个符号序列“a,b,c,d”,但是无法接收到“a,b,d”序列,因此FSA表示了一组能被接收到的符号序列集合。图1(a)的FSA对应于正则表达式abcd|bcd。我们假设状态0代表初始状态,状态5代表终止状态,如果不特别指出,本文中粗线单线圆代表初始状态,细线双线圆代表终止状态。
有限状态转移器(Finite State Transducers, FST)
是FSA的扩展,其每一次状态转移时都有一个输出标签,叫做输入输出标签对,如图1(b)就是一个FST的例子。通过这样的标签对,FST可描述一组规则的转换或一组符号序列到另一组符号序列的转换。图1(b)的FST将符号序列“a,b,c,d”转换为另一个符号序列“z,y,x,w”。
加权有限状态接收机(Weighted Finite-State Acceptors, WFSA)
在每一次状态转移时都有一个权重,在每次的初始状态都有初始权重,在每次的终止状态都有终止权重,权重一般是转移或初始/终止状态的概率或损失,权重会延每条路径进行累积,并在不同路径进行累加。图1(c)是一个WFSA的例子,每次状态转移的权重表示为“输入-标签/权重”,而初始和终止状态的权重表示为“状态 数量/权重”,在上图中,初始状态0的初始权重为0.5,终止状态5的终止权重为0.1。例如,上图中的WFSA沿着转移状态“0,1,1,2,5”以累积权重0.51.20.732*0.1=0.252接收到一个序列“a,b,c,d”。
加权有限状态转移器(Weighted Finite-State Transducers, WFST)
在每次状态转移时同时具有输出标签和权重,同时具有FST和WFSA的特性,图1(d)是一个WFST的例子,这里每次的状态转移标签都以“输入-标签: 输出-标签/权重”的形式进行转移,初始和终止状态也相应的分类了权重。在该图中的WFST,将符号序列“a,b,c,d”以0.252的累积权重转换为序列“z,y,x,w”。