Bert: 双向预训练+微调
最近要开始使用Transformer去做一些事情了,特地把与此相关的知识点记录下来,构建相关的、完整的知识结构体系。
以下是要写的文章,文章大部分都发布在公众号【雨石记】上,欢迎关注公众号获取最新文章。
- Transformer:Attention集大成者
- GPT-1 & 2: 预训练+微调带来的奇迹
- Bert: 双向预训练+微调
- Bert与模型压缩
- Bert与模型蒸馏:PKD和DistillBert
- ALBert: 轻量级Bert
- TinyBert: 模型蒸馏的全方位应用
- MobileBert: Pixel4上只需40ms
- 更多待续
- Transformer + AutoML: 进化的Transformer
- Bert变种
- Roberta: Bert调优
- Electra: 判别还是生成,这是一个选择
- Bart: Seq2Seq预训练模型
- Transformer优化之自适应宽度注意力
- Transformer优化之稀疏注意力
- Reformer: 局部敏感哈希和可逆残差带来的高效
- Longformer: 局部attentoin和全局attention的混搭
-Linformer: 线性复杂度的Attention - XLM: 跨语言的Bert
- T5 (待续)
- 更多待续
- GPT-3
- 更多待续
背景
Bert,全称是Bidirectional Encoder Representation from Transformers。顾名思义,主要的亮点是双向编码+Transformer模型。
在上一文《GPT》中,我们知道GPT是一个标准的语言模型,即用context来预测下一个词。这样就有两个缺点:
- 限制了模型结构的选择,只有从左到右方向的模型才能够被选择。
- 对句子级别的任务不是最优的。
因此,Bert这样的双向网络应运而生,但既然是双向的网络,那么就有一个问题,那就是损失函数该如何设置?GPT的损失函数非常直观,预测下一个词正确的概率,而Bert则是见到了所有的词,如何构建损失函数来训练网络呢?这就涉及到一种称之为Masked Language Model的预训练目标函数。另外,为了使模型更适用于句子级别的任务,Bert中还采用了一种称之为Next Sentence Prediction的目标函数,来使得模型能更好的捕捉句子信息。我们在下面会一一讲到。
模型结构
Bert依然是依赖Transformer模型结构,我们知道GPT采用的是Transformer中的Decoder部分的模型结构,当前位置只能attend到之前的位置。而Bert中则没有这样的限制,因此它是用的Transformer的Encoder部分。
而Transformer是由一个一个的block组成的,其主要参数如下:
- L: 多少个block
- H: 隐含状态尺寸,不同block上的隐含状态尺寸一般相等,这个尺寸单指多头注意力层的尺寸,有一个惯例就是在Transformer Block中全连接层的尺寸是多头注意力层的4倍。所以指定了H相当于是把Transformer Block里的两层隐含状态尺寸都指定了。
- A: 多头注意力的头的个数
有了这几个参数后,就可以定义不同配置的模型了,Bert中定义了两个模型,
BertBase和BertLarge。其中:
- BertBase: L=12, H=768, A=12, 参数量110M。
- BertLarge: L=24, H=1024, A=16, 参数量340M。
输入输出
为了让Bert能够处理下游任务,Bert的输入是两个句子,中间用分隔符分开,在开头加一个特殊的用于分类的字符。即Bert的输入是: [CLS] sentence1 [SEP] sentence2。
其中,两个句子对应的词语对应的embedding还要加上位置embedding和标明token属于哪个句子的embedding。如下图所示:

在[CLS]上的输出我们认为是输入句子的编码。
输入最长是512。
Masked Language Model
一般语言模型建模的方式是从左到右或者从右到左,这样的损失函数都很直观,即预测下一个词的概率。
而Bert这种双向的网络,使得下一个词这个概念消失了,没有了目标,如何做训练呢?
答案就是完形填空,在输入中,把一些词语遮挡住,遮挡的方法就是用[Mask]这个特殊词语代替。而在预测的时候,就预测这些被遮挡住的词语。其中遮挡词语占所有词语的15%,且是每次随机Mask。
但这有一个问题:在预训练中会[Mask]这个词语,但是在下游任务中,是没有这个词语的,这会导致预训练和下游任务的不匹配。
不匹配的意思我理解就是在预训练阶段任务中,模型会学到句子中有被遮挡的词语,模型要去学习它,而在下游任务中没有,但是模型会按照预训练的习惯去做,会导致任务的不匹配。
解决的办法就是不让模型意识到有这个任务的存在,具体做法就是在所有Mask的词语中,有80%的词语继续用[Mask]特殊词语,有10%用其他词语随机替换,有10%的概率保持不变。这样,模型就不知道当前句子中有没[Mask]的词语了。
Next Sentence Prediction
在很多下游任务中,需要判断两个句子之间的关系,比如QA问题,需要判断一个句子是不是另一个句子的答案,比如NLI(Natural Language Inference)问题,直接就是两个句子之间的三种关系判断。
因此,为了能更好的捕捉句子之间的关系,在预训练的时候,就做了一个句子级别的损失函数,这个损失函数的目的很简单,就是判断第二个句子是不是第一个句子的下一句。训练时,会随机选择生成训练语料,50%的时下一句,50%的不是。
Bert微调
有了模型,输入输出,目标函数,就可以训练模型了,那么在得到模型之后,如何去微调使之适应下游任务呢?
我们以Question-Answering问题为例来解释,如下图所示:
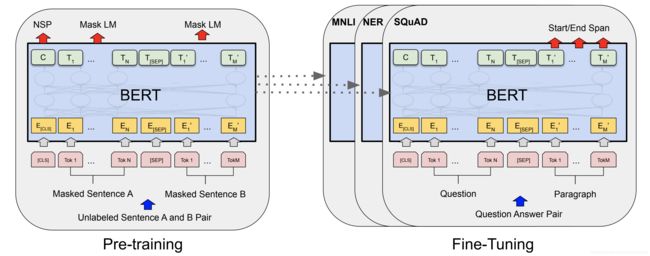
左图是Bert的预训练,输入是被遮挡的句子;右图是在Question Answer问题上微调。输入是Question和Paragraph,想要得到的是Paragraph上的答案的位置,包括起始位置和结束位置。
所以,先预定义两个embedding分别给起始位置和结束位置。然后,将paragraph在Bert上的每一个输出embedding去和这两个embedding分别做内积然后计算softmax,就得到的损失函数。有了损失函数就可以训练了。
再比如文本分类问题,文本分类和句子之间的关系无关。因而,在微调的时候,可以把Sentence B设置为空,然后把句子输入给bert,拿到[CLS]的输出再加一个全连接层去做分类。
实验结果
GLUE Task
在Glue Task上的微调的结果如下,Glue Task是一系列的任务,包括文本分类,句子关系判断等,这些问题包括:
- MNLI: 判断两个句子的关系,关系包括entailment,contradiction和neutral。
- QQP: 判断Quora上的两个问题是不是同一个语义。
- QNLI: 斯坦福QA数据集,判断下一个句子中有没有上个句子问题的答案。
- SST: 文本二分类
- CoLA: 判断一个英文句子从语言学的角度是否是accepted
- STS-B: 判断两个句子的相似程度,有1到5五个分值
- MRPC: 两个句子是否语义相似
- RTE: 跟MNLI一样,不过语料较少
- WNLI: 跟MNLI一样,语料较少。
在这些任务上的表现:

Bert在当时取得了最好的成绩。
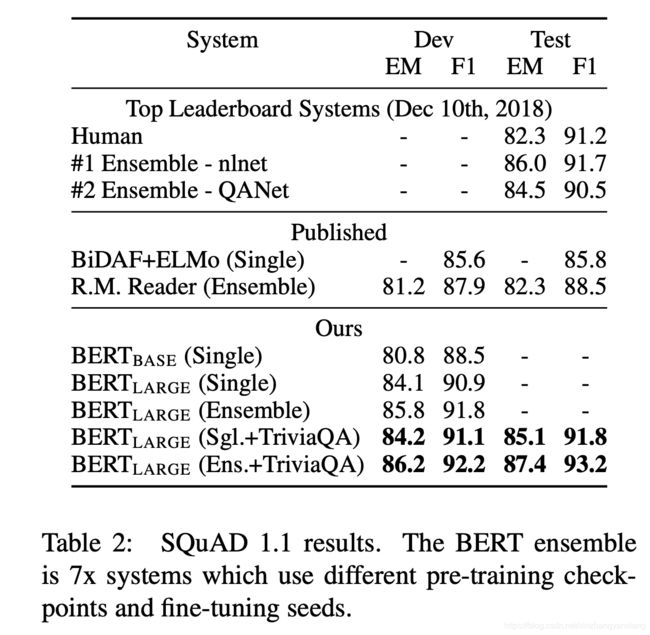
SQuAD Task
SQuAD就是上面微调那一节中描述的在Paragraph中找位置的问题。
在两个版本的SquAD上取得的结果如下图,两个版本的区别在于SQuAD中有的样本没有答案。

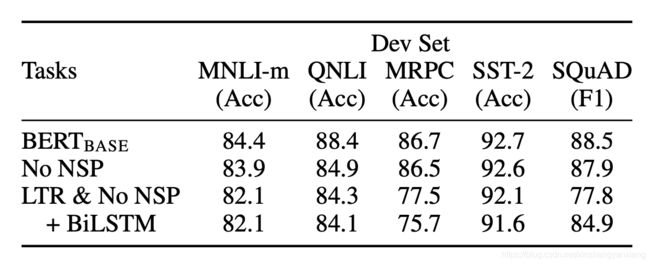
消融实验
把一些必备要素去掉或者换掉后的效果。可见,不管是去掉NSP,还是把Transformer替换掉,都会带来效果的降低。
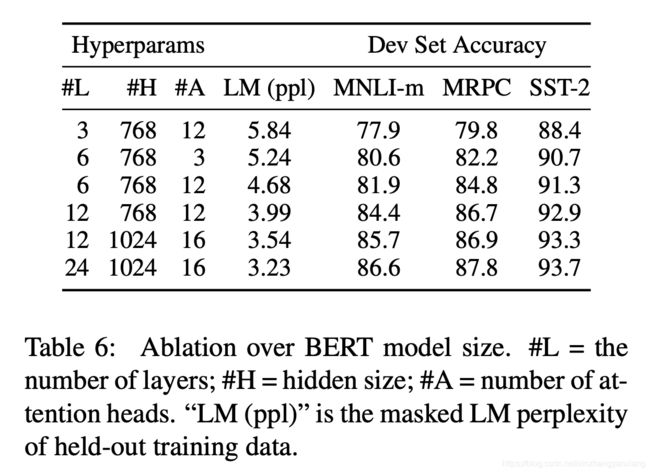
模型大小的影响
自然是大力出奇迹。
思考
勤思考, 多提问是Engineer的良好品德。
提问如下:
- Bert中的Mask有没有更好的策略
- Next Sentence Prediction看起来很不直观,有没有更好的loss?
- 现在的长度限制是512,因为Transformer是N^2复杂度,所以增大长度会出现性能问题,那么问题就是,增大长度后,效果会不会有提升?如何解决性能问题。
回答后续公布,欢迎关注公众号【雨石记】

参考
- [1]. Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).