多层感知机的反向传播算法
1 基本概念
前向传播
多层感知机中,输入信号通过各个网络层的隐节点产生输出的过程称为前向传播。
图形化表示
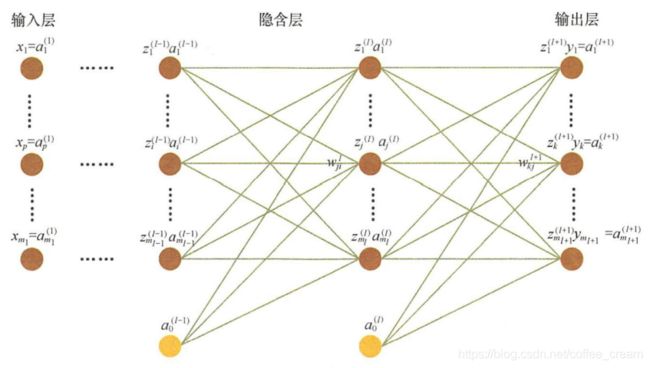
下图展示了一个典型的多层感知机
- 定义第 ( l ) (l) (l) 层的输入为 x ( l ) x^{(l)} x(l)
- 在每一层中
- 首先利用输入 x ( l ) x^{(l)} x(l) 计算仿射变换 z ( l ) = W ( l ) x ( l ) + b ( l ) z^{(l)}=W^{(l)} x^{(l)} + b^{(l)} z(l)=W(l)x(l)+b(l)
- 然后激活函数 f f f 作用于 z ( l ) z^{(l)} z(l),得到 a ( l ) = f ( z ( l ) ) a^{(l)}=f(z^{(l)}) a(l)=f(z(l))
- a ( l ) a^{(l)} a(l) 直接作为下一层的输入,即 x ( l + 1 ) x^{(l+1)} x(l+1)
设 x ( l ) x^{(l)} x(l) 为 m m m 维向量, z ( l ) z^{(l)} z(l) 和 a ( l ) a^{(l)} a(l) 为 n n n 维向量,则 W ( l ) W^{(l)} W(l) 为 m × n m\times n m×n 维的矩阵,这里分别用 z i ( l ) z^{(l)}_i zi(l) 、 a i ( l ) a^{(l)}_i ai(l) 和 W i j ( l ) W^{(l)}_{ij} Wij(l) 表示其中的一个元素。
反向传播算法
在网络训练中,前向传播最终产生一个标量损失函数。
反向传播算法( Back Propagation ) 则将损失函数的信息沿网络层向后传播用以计算梯度,达到优化网络参数的目的。反向传播算法是多层神经网络有监督训练中最简单也最一般的方法之一。
2 多层感知机的损失函数
给定包含 m m m 个样本的集合 { ( x ( 1 ) , y ( 1 ) ) , ⋯ , ( x ( m ) , y ( m ) } \{(x^{(1)},y^{(1)}),\cdots,(x^{(m)},y^{(m)}\} {(x(1),y(1)),⋯,(x(m),y(m)},假设多层感知机的层数(layer)为 N N N,在第 l l l 层的神经节点数目为 s l s_l sl
2.1 平方误差损失函数
J ( W , b ) = [ 1 m ∑ i = 1 m J ( W , b ; x ( i ) , y ( i ) ) ] + λ 2 ∑ l = 1 N − 1 ∑ i = 1 s l ∑ j = 1 s l + 1 ( W i j ( l ) ) 2 = [ 1 m ∑ i = 1 m 1 2 ∥ y ( i ) − f w , b ( x ( i ) ) ∥ 2 ] + λ 2 ∑ l = 1 N − 1 ∑ i = 1 s l ∑ j = 1 s ( l + 1 ) ( W i j ( l ) ) 2 \begin{aligned} J(W,b) &= [\frac{1}{m} \sum_{i=1}^m J(W,b;x^{(i)},y^{(i)})] + \frac{\lambda}{2} \sum_{l=1}^{N-1} \sum_{i=1}^{s_l} \sum_{j=1}^{s_l+1} (W_{ij}^{(l)})^2 \\ &= [\frac{1}{m} \sum_{i=1}^m \frac{1}{2} \| y^{(i)}-f_{w,b}(x^{(i)}) \|^2] + \frac{\lambda}{2} \sum_{l=1}^{N-1} \sum_{i=1}^{s_l} \sum_{j=1}^{s_{(l+1)}} (W_{ij}^{(l)})^2 \end{aligned} J(W,b)=[m1i=1∑mJ(W,b;x(i),y(i))]+2λl=1∑N−1i=1∑slj=1∑sl+1(Wij(l))2=[m1i=1∑m21∥y(i)−fw,b(x(i))∥2]+2λl=1∑N−1i=1∑slj=1∑s(l+1)(Wij(l))2
- 第一项为平方误差项;
- 第二项为 L2 正则化项,在功能上可以称作权重衰减项,目的是减少权重的幅度,防止过拟合,其中 W i j ( l ) W_{ij}^{(l)} Wij(l) 指的是第 l l l 层神经网络上的第 i i i 节点到第 l + 1 l+1 l+1 层神经网络上的第 j j j 个节点的权重;
- 第二项前面的系数 λ \lambda λ 为权重衰减参数,用于控制损失函数中两项的相对权重。
2.2 交叉熵损失函数
以二分类场景为例,交叉熵损失函数定义为:
J ( W , b ) = − [ 1 m ∑ i = 1 m J ( W , b ; x ( i ) , y ( i ) ) ] + λ 2 ∑ l = 1 N − 1 ∑ i = 1 s l ∑ j = 1 s l + 1 ( W i j ( l ) ) 2 = − [ 1 m ∑ i = 1 m { y ( i ) ln o ( i ) + ( 1 − y ( i ) ) ln ( 1 − o ( i ) ) } ] + λ 2 ∑ l = 1 N − 1 ∑ i = 1 s l ∑ j = 1 s ( l + 1 ) ( W i j ( l ) ) 2 \begin{aligned} J(W,b) &= -[\frac{1}{m} \sum_{i=1}^m J(W,b;x^{(i)},y^{(i)})] + \frac{\lambda}{2} \sum_{l=1}^{N-1} \sum_{i=1}^{s_l} \sum_{j=1}^{s_l+1} (W_{ij}^{(l)})^2 \\ &= -[\frac{1}{m} \sum_{i=1}^m \{ y^{(i)} \ln{o^{(i)}} + (1-y^{(i)}) \ln{(1-o^{(i)})}\}] + \frac{\lambda}{2} \sum_{l=1}^{N-1} \sum_{i=1}^{s_l} \sum_{j=1}^{s_{(l+1)}} (W_{ij}^{(l)})^2 \end{aligned} J(W,b)=−[m1i=1∑mJ(W,b;x(i),y(i))]+2λl=1∑N−1i=1∑slj=1∑sl+1(Wij(l))2=−[m1i=1∑m{y(i)lno(i)+(1−y(i))ln(1−o(i))}]+2λl=1∑N−1i=1∑slj=1∑s(l+1)(Wij(l))2
- 正则项与平方误差损失函数中的相同;
- 第一项衡量了预测 o ( i ) o^{(i)} o(i) 与真实类别 y ( i ) y^{(i)} y(i) 之间的交叉熵,当 y ( i ) y^{(i)} y(i) 与 o ( i ) o^{(i)} o(i) 相同时,损失函数达到最小
在多分类中,其相应的损失函数为:
J ( W , b ) = − [ 1 m ∑ i = 1 m ∑ k = 1 n y k ( i ) ln o k ( i ) ] + λ 2 ∑ l = 1 N − 1 ∑ i = 1 s l ∑ j = 1 s l + 1 ( W i j ( l ) ) 2 J(W,b) =-[\frac{1}{m} \sum_{i=1}^m \sum_{k=1}^n y_k^{(i)} \ln{o_k^{(i)}} ] + \frac{\lambda}{2} \sum_{l=1}^{N-1} \sum_{i=1}^{s_l} \sum_{j=1}^{s_l+1} (W_{ij}^{(l)})^2 J(W,b)=−[m1i=1∑mk=1∑nyk(i)lnok(i)]+2λl=1∑N−1i=1∑slj=1∑sl+1(Wij(l))2
- o k ( i ) o_k^{(i)} ok(i) 代表第 i i i 个样本的预测属于类别 k k k 的概率
- y k ( i ) y_k^{(i)} yk(i) 为实际概率(如果第 i i i 个样本的真实类别为 k k k,则 y k ( i ) = 1 y_k^{(i)}=1 yk(i)=1,否则为 0)
2.3 平方误差损失函数和交叉熵损失函数分别适合什么场景
一般来说:
- 平方误差损失函数更适合输出为连续、并且最后一层不含 Sigmoid 或 Softmax 函数的神经网络;
- 交叉熵损失则更适合二分类或多分类的场景。
想正确回答出答案也许并不难, 但是要想给出具有理论依据的合理原因,还需要对它们的梯度推导熟悉掌握,并且具备一定的灵活分析能力。(推导见下一节)
为何平方损失函数不适合最后一层含有 Sigmoid Sofmax 激活函数的神经网络呢?
平方误差损失函数相对于输出层的导数为:
δ ( L ) = − ( y − a ( L ) ) f ′ ( z ( L ) ) \delta^{(L)} = -(y-a^{(L)})f'(z^{(L)}) δ(L)=−(y−a(L))f′(z(L))
其中最后一项 f ′ ( z ( L ) ) f'(z^{(L)}) f′(z(L)) 为激活函数的导数。
当激活函数为 Sigmoid 函数时,如果 z ( L ) z^{(L)} z(L) 的绝对值较大,函数的梯度会趋于饱和,即 f ′ ( z ( L ) ) f'(z^{(L)}) f′(z(L)) 的绝对值非常小,导致 δ ( L ) \delta^{(L)} δ(L) 的取值也非常小,使得基于梯度的学习速度非常缓慢。
而当使用交叉摘损失函数时,相对于输出层的导数(也可以被认为是残差)为
δ ( L ) = f ( z k ^ ( L ) ) − 1 = a k ^ ( L ) − 1 \delta^{(L)} = f(z_{\hat{k}}^{(L)})-1=a_{\hat{k}}^{(L)}-1 δ(L)=f(zk^(L))−1=ak^(L)−1
此时的导数是线性的,因此不会存在学习速度过慢的问题。
3 推导各层参数更新的梯度计算公式
令:
- 第 ( l ) (l) (l) 层的参数为 W ( l ) W^{(l)} W(l) 和 b ( l ) b^{(l)} b(l)
- 每层的线性变换为 z ( l ) = W ( l ) x ( l ) + b ( l ) z^{(l)}=W^{(l)} x^{(l)} + b^{(l)} z(l)=W(l)x(l)+b(l)
- 输出为 a ( l ) = f ( z ( l ) ) a^{(l)}=f(z^{(l)}) a(l)=f(z(l)),其中 f f f 为非线性激活函数(如 Sigmod、Tanh、ReLU 等)
- a ( l ) a^{(l)} a(l) 直接作为下一层的输入,即 x ( l + 1 ) = a ( l ) x^{(l+1)}=a^{(l)} x(l+1)=a(l)
我们可以用批量梯度下降法来优化网络参数,梯度下降法中每次对参数 W W W(网络连接权重)和 b b b(偏置)进行更新:
W i j ( l ) = W i j ( l ) − α ∂ ∂ W i j ( l ) J ( W , b ) b i ( l ) = b i ( l ) − α ∂ ∂ b i ( l ) J ( W , b ) \begin{aligned} W_{ij}^{(l)} &= W_{ij}^{(l)}-\alpha \frac{\partial}{\partial W_{ij}^{(l)}} J(W,b) \\ b_{i}^{(l)} &= b_{i}^{(l)} - \alpha \frac{\partial}{\partial b_{i}^{(l)}} J(W,b) \end{aligned} Wij(l)bi(l)=Wij(l)−α∂Wij(l)∂J(W,b)=bi(l)−α∂bi(l)∂J(W,b)
其中, α \alpha α 为学习率,控制每次迭代中梯度变化的幅度。
从上面的式子可以看出,问题的核心就是求解 ∂ ∂ W i j ( l ) J ( W , b ) \frac{\partial}{\partial W_{ij}^{(l)}} J(W,b) ∂Wij(l)∂J(W,b) 和 ∂ ∂ b i ( l ) J ( W , b ) \frac{\partial}{\partial b_{i}^{(l)}} J(W,b) ∂bi(l)∂J(W,b)。
损失函数对隐含层的偏导
为了得到递推公式,我们需要计算损失函数对隐含层的偏导
∂ ∂ z i ( l ) J ( W , b ) = ∑ j = 1 s l + 1 ( ∂ J ( W , b ) ∂ z j ( l + 1 ) ∂ z j ( l + 1 ) ∂ z i ( l ) ) \frac{\partial}{\partial z_{i}^{(l)}} J(W,b)=\sum_{j=1}^{s_{l+1}} (\frac{\partial J(W,b)}{\partial z_{j}^{(l+1)}} \frac{\partial z_{j}^{(l+1)}}{\partial z_{i}^{(l)}}) ∂zi(l)∂J(W,b)=j=1∑sl+1(∂zj(l+1)∂J(W,b)∂zi(l)∂zj(l+1))
其中, s l + 1 s_{l+1} sl+1 为第 l + 1 l+1 l+1 层的节点数,而
∂ z j ( l + 1 ) ∂ z i ( l ) = ∂ ( W i j ( l ) x ( l + 1 ) + b j ( l + 1 ) ) ∂ z i ( l ) ) \frac{\partial z_{j}^{(l+1)}}{\partial z_{i}^{(l)}} = \frac{\partial (W_{ij}^{(l)} x^{(l+1)} + b_j^{(l+1)})}{\partial z_{i}^{(l)}}) ∂zi(l)∂zj(l+1)=∂zi(l)∂(Wij(l)x(l+1)+bj(l+1)))
其中, b ( l ) b^{(l)} b(l) 与 z i ( l ) z_{i}^{(l)} zi(l) 无关可以省去, x l + 1 = a l = f ( z ( l ) ) x^{l+1}=a^l=f(z^{(l)}) xl+1=al=f(z(l)),因此,上式可以写作:
∂ z j ( l + 1 ) ∂ z i ( l ) = W i j ( l ) f ′ ( z i ( l ) ) \frac{\partial z_{j}^{(l+1)}}{\partial z_{i}^{(l)}} = W_{ij}^{(l)} f'(z_i^{(l)}) ∂zi(l)∂zj(l+1)=Wij(l)f′(zi(l))
∂ ∂ z i ( l ) J ( W , b ) \frac{\partial}{\partial z_{i}^{(l)}} J(W,b) ∂zi(l)∂J(W,b) 可以看作是损失函数在第 l l l 层第 i i i 个节点产生的残差值,记为 δ i ( l ) \delta_{i}^{(l)} δi(l),推导公式就可以表示为:
δ i ( l ) = ( ∑ j = 1 s l + 1 W i j ( l ) δ j ( l + 1 ) ) f ′ ( z i ( l ) ) \delta_{i}^{(l)}=(\sum_{j=1}^{s_{l+1}} W_{ij}^{(l)} \delta_{j}^{(l+1)})f'(z_i^{(l)}) δi(l)=(j=1∑sl+1Wij(l)δj(l+1))f′(zi(l))
损失函数对参数函数的梯度就可以写为:
∂ ∂ W i j ( l ) J ( W , b ) = ∂ J ( W , b ) ∂ z j ( l + 1 ) ∂ z j ( l + 1 ) ∂ W i j ( l ) = δ i ( l + 1 ) x j ( l + 1 ) = δ i ( l + 1 ) a j ( l ) ∂ ∂ b i ( l ) J ( W , b ) = δ i ( l + 1 ) \begin{aligned} \frac{\partial}{\partial W_{ij}^{(l)}} J(W,b) &= \frac{\partial J(W,b)}{\partial z_{j}^{(l+1)}} \frac{\partial z_{j}^{(l+1)}}{\partial W_{ij}^{(l)}} \\ &= \delta_{i}^{(l+1)} x_j^{(l+1)} \\ &= \delta_{i}^{(l+1)} a_j^{(l)} \\ \frac{\partial}{\partial b_{i}^{(l)}} J(W,b) &=\delta_{i}^{(l+1)} \end{aligned} ∂Wij(l)∂J(W,b)∂bi(l)∂J(W,b)=∂zj(l+1)∂J(W,b)∂Wij(l)∂zj(l+1)=δi(l+1)xj(l+1)=δi(l+1)aj(l)=δi(l+1)
从上式中可以看出,利用 ( l + 1 ) (l+1) (l+1) 层在第 i i i 个节点产生的残差值 δ i ( l + 1 ) \delta_{i}^{(l+1)} δi(l+1),就可以对第 l l l 层的 W i j ( l ) W_{ij}^{(l)} Wij(l) 与 b i ( l ) b_{i}^{(l)} bi(l) 进行更新。
因此,反向传播算法的步骤可以写为:
- 利用前向传到公式,得到从第 1 层到第 L L L 层的输出值
- for l = L → 1 l = L \rightarrow 1 l=L→1
- 计算第 l l l 层的残差 δ i ( l ) \delta_{i}^{(l)} δi(l)
- 得到 ∂ ∂ W i j ( l ) J ( W , b ) \frac{\partial}{\partial W_{ij}^{(l)}} J(W,b) ∂Wij(l)∂J(W,b) 与 ∂ ∂ b i ( l ) J ( W , b ) \frac{\partial}{\partial b_{i}^{(l)}} J(W,b) ∂bi(l)∂J(W,b)
- 对 W i j ( l ) W_{ij}^{(l)} Wij(l) 与 b i ( l ) b_{i}^{(l)} bi(l) 进行更新
其中,根据选择的损失函数不同, δ i ( L ) \delta_{i}^{(L)} δi(L) 的计算也不相同,为了简化,这里忽略 Batch 样本集合和正则化项的影响,重点关注两种损失函数产生的梯度
-
平方误差损失函数
J ( W , b ) = 1 2 ∥ y − a ( L ) ∥ 2 = 1 2 ∥ y − f ( z ( L ) ) ∥ 2 δ ( L ) = − ( y − a ( L ) ) f ′ ( z ( L ) ) \begin{aligned} J(W,b) &= \frac{1}{2} \| y-a^{(L)} \|^2 \\ &= \frac{1}{2} \| y-f(z^{(L)}) \|^2 \\ \delta^{(L)} &= -(y-a^{(L)})f'(z^{(L)}) \end{aligned} J(W,b)δ(L)=21∥y−a(L)∥2=21∥y−f(z(L))∥2=−(y−a(L))f′(z(L)) -
交叉熵损失函数
J ( W , b ) = − ∑ k = 1 n y k ln a k ( L ) = − ∑ k = 1 n y k ln f ( z k ( L ) ) \begin{aligned} J(W,b) &= -\sum_{k=1}^{n} y_k \ln a_k^{(L)} \\ &= -\sum_{k=1}^{n} y_k \ln f(z_k^{(L)}) \end{aligned} J(W,b)=−k=1∑nyklnak(L)=−k=1∑nyklnf(zk(L))
在分类问题中, y k y_k yk 仅在一个类别 k k k 时取1,其余为 0,令实际的类别为 k ^ \hat{k} k^,则
J ( W , b ) = − ln a k ^ ( L ) δ ( L ) = − f ′ ( z k ^ ( L ) ) f ( z k ^ ( L ) ) \begin{aligned} J(W,b) &= - \ln a_{\hat{k}}^{(L)} \\ \delta^{(L)} &= -\frac{f'(z_{\hat{k}}^{(L)})}{f(z_{\hat{k}}^{(L)})} \end{aligned} J(W,b)δ(L)=−lnak^(L)=−f(zk^(L))f′(zk^(L))
当 f f f 取 SoftMax 激活函数时, f ′ ( x ) = f ( x ) ( 1 − f ( x ) ) f'(x)=f(x)(1-f(x)) f′(x)=f(x)(1−f(x)),则有:
δ ( L ) = f ( z k ^ ( L ) ) − 1 = a k ^ ( L ) − 1 \delta^{(L)} = f(z_{\hat{k}}^{(L)})-1=a_{\hat{k}}^{(L)}-1 δ(L)=f(zk^(L))−1=ak^(L)−1
4 反向传播算法中最重要的四个公式
根据上一节的推导,可以得到下面几个公式
(1)损失函数在第 L L L 层第 i i i 个节点的误差
δ i ( L ) = ∂ ∂ z i L J ( W , b ) = ∑ k = 1 s L ∂ J ( W , b ) ∂ a k L ∂ a k L ∂ z i L = ∂ J ( W , b ) ∂ a i L ∂ a i L ∂ z i L = ∂ J ( W , b ) ∂ a i L f ′ ( z i ( L ) ) \begin{aligned} \delta^{(L)}_i &= \frac{\partial}{\partial z_i^L} J(W,b) \\ &= \sum_{k=1}^{s_L} \frac{\partial J(W,b)}{\partial a_k^L} \frac{\partial a_k^L}{\partial z_i^L} \\ &= \frac{\partial J(W,b)}{\partial a_i^L} \frac{\partial a_i^L}{\partial z_i^L} \\ &= \frac{\partial J(W,b)}{\partial a_i^L} f'(z_i^{(L)}) \end{aligned} δi(L)=∂ziL∂J(W,b)=k=1∑sL∂akL∂J(W,b)∂ziL∂akL=∂aiL∂J(W,b)∂ziL∂aiL=∂aiL∂J(W,b)f′(zi(L))
(2)根据第 l + 1 l+1 l+1 层的误差来计算第 l l l 层的误差
δ i ( l ) = ( ∑ j = 1 s l + 1 W i j ( l ) δ j ( l + 1 ) ) f ′ ( z i ( l ) ) \delta_{i}^{(l)}=(\sum_{j=1}^{s_{l+1}} W_{ij}^{(l)} \delta_{j}^{(l+1)})f'(z_i^{(l)}) δi(l)=(j=1∑sl+1Wij(l)δj(l+1))f′(zi(l))
(3)根据每层上每个神经元上的误差来计算参数偏置 b i l b_i^l bil 的梯度下降方向
∂ ∂ b i ( l ) J ( W , b ) = δ i ( l + 1 ) \frac{\partial}{\partial b_{i}^{(l)}} J(W,b) = \delta_{i}^{(l+1)} ∂bi(l)∂J(W,b)=δi(l+1)
(4)根据每层上每个神经元上的误差来计算参数权重 w i l w_i^l wil 的梯度下降方向
∂ ∂ W i j ( l ) J ( W , b ) = δ i ( l + 1 ) a j ( l ) \frac{\partial}{\partial W_{ij}^{(l)}} J(W,b) = \delta_{i}^{(l+1)} a_j^{(l)} ∂Wij(l)∂J(W,b)=δi(l+1)aj(l)