「深度学习一遍过」必修10:pytorch 框架的使用
本专栏用于记录关于深度学习的笔记,不光方便自己复习与查阅,同时也希望能给您解决一些关于深度学习的相关问题,并提供一些微不足道的人工神经网络模型设计思路。
专栏地址:「深度学习一遍过」必修篇
目录
1 Tensor生成
2 Tensor基本操作
形状查看
形状更改
增加维度
压缩维度
3 Tensor其他操作
4 Pytorch网络定义与优化
4.1 基础网络定义接口
4.2 网络结构定义与前向传播
4.3 优化器定义
4.4 优化器使用流程
4.5 Tensor 的自动微分 autograd
5 pytorch数据与模型接口
5.1 数据接口
5.2 计算机视觉数据集与模型读取
5.3 数据增强接口
5.4 模型保存
1 Tensor生成
![]() 类似于
类似于 ![]() 的
的 ![]() ,可以使用
,可以使用 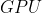 进行计算。
进行计算。
import torch构造一个默认 ![]() 型的
型的 ![]() 张量
张量
torch.Tensor(5, 3)
构造一个 ![]() 矩阵,不初始
矩阵,不初始
torch.empty(5, 3)
构造一个随机初始化的矩阵
torch.rand(5, 3)
构造一个矩阵全为 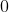 ,而且数据类型是
,而且数据类型是 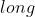
torch.zeros(5, 3, dtype=torch.long)
torch.long
基于已经存在的 ![]() 创建一个
创建一个 ![]()
x = torch.zeros(5, 3, dtype=torch.long)x.new_ones(5, 3, dtype=torch.double)
构造一个张量,为 ![]() ,从数据中推断数据类型
,从数据中推断数据类型
torch.tensor([5.5, 3])
2 Tensor基本操作
在张量做加减乘除等运算时,需要保证张量的形状一致,往往需要对某些张量进行更改
import torch构造一个默认 ![]() 型的
型的 ![]() 张量
张量
x = torch.Tensor(5, 3)
x
形状查看
x.size()![]()
x.shape![]()
x.dim() # dim维度![]()
形状更改
展为 ![]() 矩阵,共享内存
矩阵,共享内存
x.view(3,5)
展为 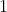 维向量
维向量
x.view(-1)
增加维度
torch.unsqueeze(x,1)
压缩维度
torch.squeeze(x,1)
3 Tensor其他操作
拼接与拆分,基本数学操作:对多个分支的张量加以融合或拆分
torch.cat() #拼接
torch.stack() #堆叠
torch.chunk() #分块
torch.split() #切分z = x + y # torch加法z = torch.add(x, y) # torch加法 y.add_(x) # 下划线版本,in-place加法,原地运算,结果存在y中4 Pytorch网络定义与优化
4.1 基础网络定义接口
通过 ![]() 包来构建网络, 包含
包来构建网络, 包含 ![]() ,
,![]()
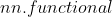 :纯函数,不包含可学习参数,如激活函数,池化层
:纯函数,不包含可学习参数,如激活函数,池化层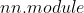 :
: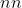 的核心数据结构,可以是一个
的核心数据结构,可以是一个 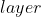 或者一个网络,其中 自动提取可学习参数,适用于卷积层,全连接层等
或者一个网络,其中 自动提取可学习参数,适用于卷积层,全连接层等
4.2 网络结构定义与前向传播
通过 ![]() 包来构建网络
包来构建网络
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__() #继承Net类,并进行初始化
self.conv1 = nn.Conv2d(1, 6, 5) #继承nn.Module的需要实例化
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x): #前向传播函数
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) #relu,max_pool2d,不需要实例化
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x- 需要实例化,可以与
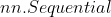 配合使用, 不行, 不需要实例化。
配合使用, 不行, 不需要实例化。 - 不需要传入
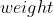 ,
, , 不行。
, 不行。 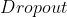 层状态自动切换,可以实现, 不行。
层状态自动切换,可以实现, 不行。
import torch.nn as nn
# 创建一个Model类, 这个模型的功能就是给输入的数加上1
class Model(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input):
output = input + 1
print(output)
model = Model() # 实例化
input = torch.tensor(1) # 输入为1
model(input) # 输出为0![]() 和
和 ![]() 都是和输入共享内存的,
都是和输入共享内存的,![]() 的好处是不用输入形状参数,直接指定维度,在这之后的都被拉平。
的好处是不用输入形状参数,直接指定维度,在这之后的都被拉平。![]() 则是更加灵活.
则是更加灵活.
4.3 优化器定义
通过 ![]() 包来构建(优化目标与方法定义)
包来构建(优化目标与方法定义)
import torch.optim as
optim criterion = nn.CrossEntropyLoss() #交叉熵损失
optimizer_ft = optim.SGD(modelclc.parameters(), lr=0.1, momentum=0.9) #SGD优化方法
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=100, gamma=0.1) #学习率4.4 优化器使用流程
三个步骤:清空梯度、反向传播、更新参数
for input, target in dataset:
optimizer.zero_grad() #清空梯度
output = model(input) #自动执行forward函数
loss = loss_fn(output, target) #计算损失
loss.backward() #反向传播
optimizer.step() #更新参数前向计算
out = net(img) #自动执行forward函数
loss = criterion(out,label) #计算损失反向传播
loss.backward() #反向传播
optimizer.step() #更新参数4.5 Tensor 的自动微分 autograd
![]() 和
和 ![]() 互相连接并构建一个非循环图,它保存完整计算过程。
互相连接并构建一个非循环图,它保存完整计算过程。
完成自动求导的步骤:
- 将
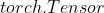 的属性
的属性 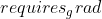 设置为
设置为 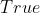 ,开始跟踪针对
,开始跟踪针对 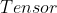 的所有操作。
的所有操作。 - 完成计算后调用
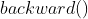 自动计算所有梯度。
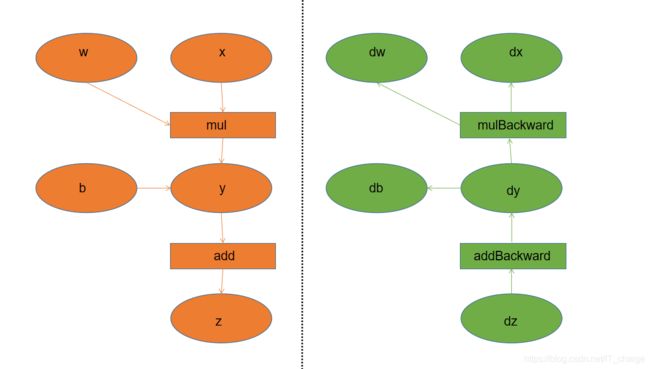
自动计算所有梯度。 - 将该张量的梯度将累积到
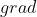 属性中。
属性中。
![]() ,
, ,
, ,
, 是输入叶子结点, 和 需要进行参数更新。
是输入叶子结点, 和 需要进行参数更新。
import torch
import numpy as np
x=torch.Tensor([2]) #定义输入张量x
#初始化权重参数W,偏移量b、并设置require_grad为True, 为自动求导
w=torch.randn(1,requires_grad=True)
b=torch.randn(1,requires_grad=True)
y=torch.mul(w,x)
z=torch.add(y,b) #等价于y+b
z.backward() #标量进行反向传播,向量则需要构建梯度矩阵
print("x,w,b,y,z的require_grad属性分别为:{},{},{},{},{}".format(x.requires_grad, w.requires_grad,b.requires_grad,y.requires_grad,z.requires_grad)) 
如何取消求导?
- 调用
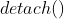 修改
修改 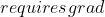 为
为  ,它将其与计算历史记录分离
,它将其与计算历史记录分离 - 调用
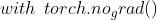 停止
停止 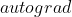 模块的工作
模块的工作
# 推理案例
torch.no_grad() #停止autograd模块的工作,加速和节省显存
image = Image.open(imagepath)
imgblob = data_transforms(img).unsqueeze(0) #填充数据维度
imgblob = Variable(imgblob)
predict = F.softmax(net(imgblob))
index = np.argmax(predict.detach().numpy())5 pytorch数据与模型接口
5.1 数据接口
通过 ![]() 包来构建数据集
包来构建数据集
读取数据的 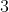 个必须实现的函数:
个必须实现的函数:
- __init__:相关参数定义
- __len __:获取数据集样本总数
- __getitem __:读取每个样本及标签
class TestDataset(torch.utils.data.Dataset):
#继承Dataset
def __init__(self):
self.Data=np.asarray([[1,2],[3,4],[2,1],[3,4],[4,5]])#数据
self.Label=np.asarray([0,1,0,1,2])#标签
def __getitem__(self, index):
data=torch.from_numpy(self.Data[index]) #把numpy转换为Tensor
label=torch.tensor(self.Label[index])
return data,label
def __len__(self):
return len(self.Data)# 使用index取数据
Test=TestDataset()
print(Test[2]) #结果是(tensor([2, 1]), tensor(0))
print(Test.__len__()) #结果是5使用 ![]() 迭代器提取数据(实现批量读取,打乱数据等)
迭代器提取数据(实现批量读取,打乱数据等)
# 获得数据指针
test_loader = data.DataLoader(Test, batch_size=2,shuffle=False, num_workers=2) - batch_size:batch大小
- shuffle=False:是否打乱
- num_workers=2:加载数据线程数
![]() 参数:
参数:
- 当加载
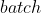 的时间
的时间 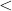 数据训练的时间, 每次训练完都可以直接从
数据训练的时间, 每次训练完都可以直接从 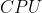 中取到
中取到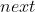 的数据 无需额外的等待,不需要多余的
的数据 无需额外的等待,不需要多余的 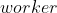 ,即使增加 也不会影响训练速度
,即使增加 也不会影响训练速度 - 当加载 的时间
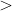 数据训练的时间, 每次训练完都需要等待 完成数据的载入,若增加 , 即使 个 还未就绪, 也可以取其他 的数据来训练
数据训练的时间, 每次训练完都需要等待 完成数据的载入,若增加 , 即使 个 还未就绪, 也可以取其他 的数据来训练
5.2 计算机视觉数据集与模型读取
通过 ![]() 包来读取已有的数据集和模型
包来读取已有的数据集和模型
![]() (
(![]() 等,
等,![]() )
)
# 数据集读取
import torchvision.dataset as dataset
data_dir = './data/'
data = datasets.ImageFolder('./data',data_transform)
dataloader = data.DataLoader(data)5.3 数据增强接口
每一次训练时,需要输入同样大小的图片进行训练,一般使用裁剪  缩放操作。
缩放操作。
torchvision 数据增强接口
通过 ![]() 包的
包的 ![]() 进行数据预处理和增强:包括缩放,裁剪等数据增强函数,标准化等预处理函数
进行数据预处理和增强:包括缩放,裁剪等数据增强函数,标准化等预处理函数
data_transforms = {
'train': transforms.Compose([
transforms.Scale(64), # 缩放的图像大小:64*64
transforms.RandomSizedCrop(48), # 实际用于训练的图像大小:48*48,采用随机裁剪与缩放操作(此时Scale为冗余操作)
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5]) ]),
'val': transforms.Compose([
transforms.Scale(64),
transforms.CenterCrop(48), # 实际用于测试的图像大小:48*48,采用中心裁剪操作
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5]) ]), }常见的数据预处理与增强相关的操作
CenterCrop,ColorJitter,FiveCrop,Grayscale,Pad,RandomAffine,RandomApply, RandomCrop,RandomGrayscale, RandomHorizontalFlip,RandomPerspective,RandomResizedCrop,RandomRotation, RandomSizedCrop, RandomVerticalFlip, Resize,Scale,TenCrop,GaussianBlur,RandomChoice,RandomOrder, LinearTransformation,Normalize,RandomErasing,ConvertImageDtype, ToPILImage,ToTensor,Lambda
通过 ![]() 包的
包的 ![]() 接口,自定义数据增强函数
接口,自定义数据增强函数
import torchvision.transforms.functional as TF
import random
def my_segmentation_transforms(image, segmentation):
if random.random() > 0.5:
angle = random.randint(-30, 30)
image = TF.rotate(image, angle)
segmentation = TF.rotate(segmentation, angle)
# more transforms ...
return image, segmentationtorchvision 模型接口
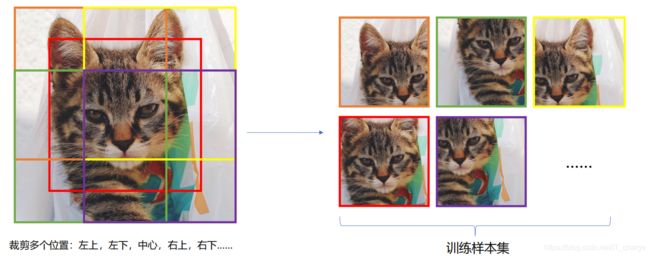
通过 ![]() 包来读取已有的模型,
包来读取已有的模型,![]() (
( 等)
等)
# 模型读取、导出
import torchvision.models as models
model = models.alexnet(pretrained=True).cuda()
torch.save(model.state_dict(),'models/model.ckpt')
dummy_input = torch.randn(10, 3, 224, 224).cuda()
torch.onnx.export(model, dummy_input, "alexnet.proto", verbose=True)5.4 模型保存
保存或加载整个模型
#保存
torch.save(model, '\model.pkl’)
#加载
model = torch.load('\model.pkl’)保存或加载模型参数
# 保存
torch.save(model.state_dict(), '\parameter.pkl')
# 加载
model = TheModelClass(...)
model.load_state_dict(torch.load('\parameter.pkl’)) _
_![]() 是一个
是一个 ![]() 字典对象,将每个图层映射到其参数
字典对象,将每个图层映射到其参数 ![]() 。
。
只有具有可学习参数的层(卷积层,线性层等)和已注册的缓冲区(![]() 的
的 ![]() )才存在。
)才存在。
实例解析
保存方式一:模型结构+模型参数
import torch
import torchvision
# 保存模型
vgg16 = torchvision.models.vgg16(pretrained=False)
torch.save(vgg16, 'vgg16_method1.pth')
# 加载模型
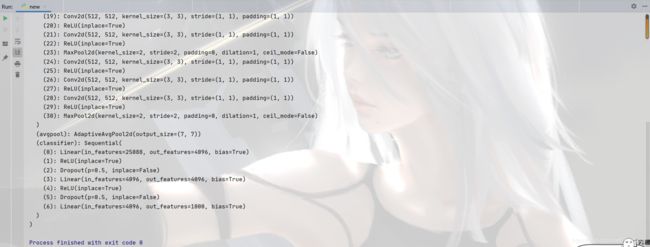
model = torch.load('vgg16_method1.pth')
print(model)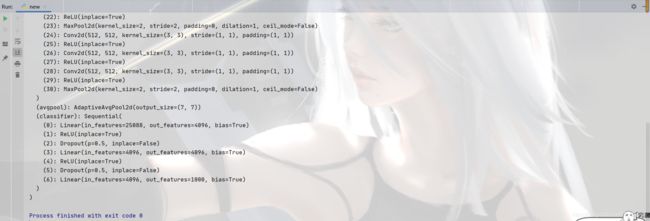
保存方式二:模型参数(官方推荐)
import torch
import torchvision
# 保存模型
vgg16 = torchvision.models.vgg16(pretrained=False)
torch.save(vgg16.state_dict(), 'vgg16_method2.pth')
# 加载模型
model = torch.load('vgg16_method2.pth')
print(model)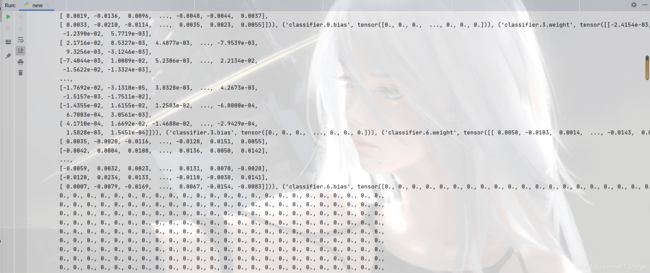
若想通过保存的模型参数加载出原模型,可以执行如下代码:
import torch
import torchvision
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.state_dict(torch.load('vgg16_method2.pth'))
print(vgg16)