halcon提取数据集中指定图片并进行裁剪
0、halcon编程总结
由于halcon编程是实时编程的,并且还可以实时看到对应的变量的值,所以最好的方式就是边写边看对应的变量的变化。
一个运行位置,一个断点位置,记得把运行位置放在前面,如下图所示:
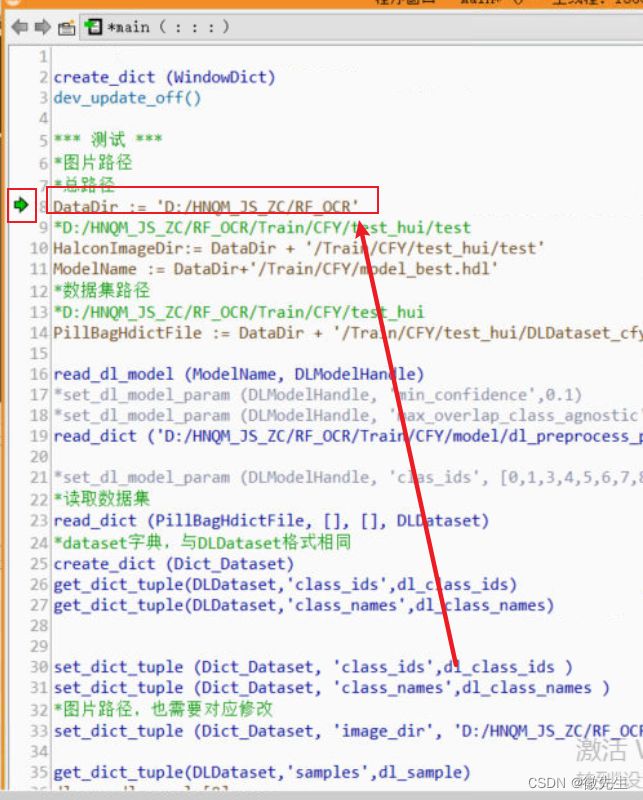
一、理清数据集的结构以及相关操作
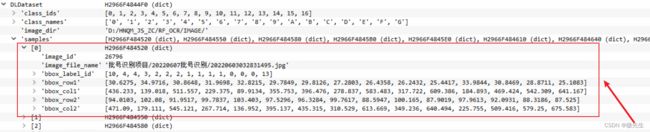
数据集例子:
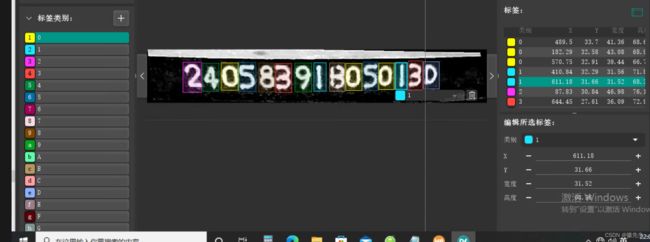
最开始的数据集包括了0-G,这里是单独提取了D的数据。
首先要清楚DLDataset的格式,然后提取相关信息:
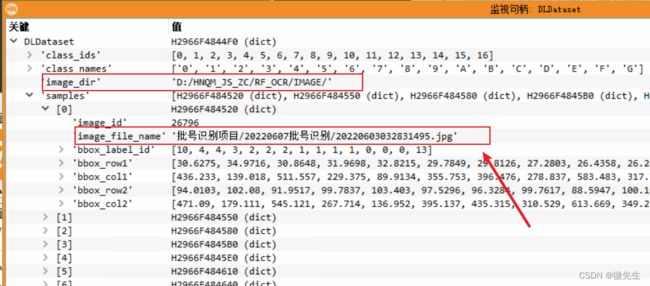
这里的两个路径,组合起来就是图片的绝对路径。——这里的缺点就是图片路径可能是不同的文件夹,因为这里是通过数组保存起来的,但是在MVTec Deep Learning Tool这个标注软件里不好指定文件的路径。
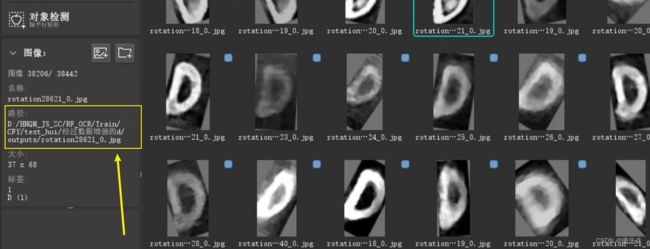
那么当得到数据集的handle之后就可以对每一个sample进行处理了,sanples就是数据集每一个样本的信息,包含了路径以及标注的框信息,尤其是这些框的信息,我们可以进行处理:
读取图像
read_image(dl_image,dl_ss_image_file_name)
写入图像
write_image (Lena, 'jpg', 0, 'D:/HNQM_JS_ZC/RF_OCR/Train/CFY/test_hui/fill_red2.jpg')
二、对图像进行裁剪
overpaint_region (Lena, Rectangle, color, 'fill')在图片的指定区域进行裁剪。color表示要使用的颜色,"fill"指使用填充方式这个一般就用这个
* read_image (Lena, 'D:/HNQM_JS_ZC/RF_OCR/Train/CFY/test_hui/fill2.jpg')
*gen_circle (Circle, 200, 200, 100.5)
* gen_rectangle1(Rectangle,0.0,0.0,100.0,100.0)

代码
* read_image (Lena, 'D:/HNQM_JS_ZC/RF_OCR/Train/CFY/test_hui/fill2.jpg')
*gen_circle (Circle, 200, 200, 100.5)
* gen_rectangle1(Rectangle,0.0,0.0,100.0,100.0)
*用红色填充
* color := [0,0,0]
* overpaint_region (Lena, Rectangle, color, 'fill')
* write_image (Lena, 'jpg', 0, 'D:/HNQM_JS_ZC/RF_OCR/Train/CFY/test_hui/fill_red2.jpg')
create_dict (WindowDict)
*** 测试 ***
*图片路径
*总路径
DataDir := 'D:/HNQM_JS_ZC/RF_OCR'
* D:/HNQM_JS_ZC/RF_OCR/Train/CFY/test_hui
* HalconImageDir:= DataDir + '/IMAGE/POS/0915_2'
HalconImageDir:= DataDir + '/Train/CFY/test_hui'
*数据集路径
*/Train/CFY/dl_dataset/DLDataset_cfy_0915.hdict
PillBagHdictFile := DataDir + '/Train/CFY/test_hui/DLDataset_cfy_0915_child.hdict'
*读取数据集
read_dict (PillBagHdictFile, [], [], DLDataset)
*dataset字典,与DLDataset格式相同
create_dict (Dict_Dataset)
get_dict_tuple(DLDataset,'image_dir',image_dir)
get_dict_tuple(DLDataset,'class_ids',dl_class_ids)
get_dict_tuple(DLDataset,'class_names',dl_class_names)
get_dict_tuple(DLDataset,'samples',dl_sample)
*单个文件的路径
for i:=0 to |dl_sample|-1 by 1
dl_ss:=dl_sample[i]
*获取D对应的13所在的位置
get_dict_tuple(dl_ss,'bbox_label_id',bbox_label_id)
D:=[]
for Index := 0 to |bbox_label_id|-1 by 1
if(bbox_label_id[Index]==13)
D:=[D,Index]
endif
endfor
*提取框的数组
get_dict_tuple(dl_ss,'image_file_name',image_file_name)
dl_ss_image_file_name:=image_dir+image_file_name
read_image(dl_image,dl_ss_image_file_name)
*将画框提取然后进行裁剪
get_dict_tuple(dl_ss,'bbox_row1',row1)
get_dict_tuple(dl_ss,'bbox_row2',row2)
get_dict_tuple(dl_ss,'bbox_col1',col1)
get_dict_tuple(dl_ss,'bbox_col2',col2)
*对每个框进行分割并保存
get_dict_tuple(dl_ss,'image_id',image_id)
*len:=|D|
for j:=0 to |D|-1 by 1
if(|D|==1)
width:=col2[D]-col1[D]
hight:=row2[D]-row1[D]
crop_part (dl_image, ImagePart, row1[D], col1[D], width, hight)
write_image(ImagePart,'jpeg',0,'D:/HNQM_JS_ZC/RF_OCR/Train/CFY/test_hui/d_img/'+image_id+'_'+j+'.jpg')
break
endif
width:=row2[D[i]]-row1[D[i]]
hight:=col2[D[i]]-col1[D[i]]
crop_part (dl_image, ImagePart, row1[D[i]], col1[D[i]], width, hight)
write_image(ImagePart,'jpeg',0,'D:/HNQM_JS_ZC/RF_OCR/Train/CFY/test_hui/d_img/'+image_id+'_'+j+'.jpg')
endfor
endfor
*提取对应字符的图片
********************************************