【Faster R-CNN】之 Dataset and Dataloader 代码精读
【Faster R-CNN】之 Dataset and Dataloader
- 1、dataset 对数据的处理细节
- 2、dataset 代码的相关说明
- 3、DataLoader 读取数据
- 4、代码
-
- Dataset
- DataLoader
1、dataset 对数据的处理细节
-
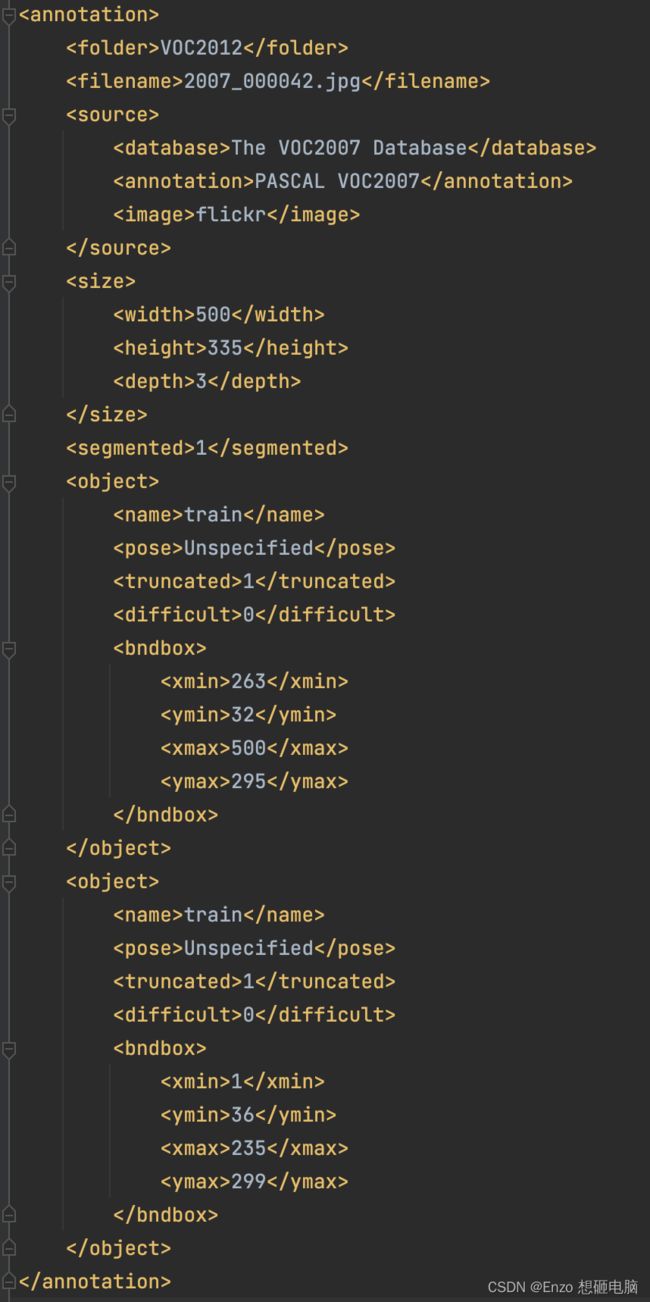
获取 训练数据集 或 测试数据集中一张图片的标注文件(annotations) 地址,并读取该文件中的标注信息。标注信息包括如下: (列出来的这些是要解析出来使用的,其他的信息在物体检测任务中用不着)
- 图片地址 filename
- 图片尺寸 (width、height、depth)
- 图片中1个或多个物体的 分类 object name
- 每个物体的坐标信息 (xmin, ymin, xmax, ymax)
- 等等。。。。
-
将标注信息从文件中解析出来,以 tensor的数据格式存储,记为 target

-
根据从标注信息中解析出来的图片地址,读取图片 (PIL 格式)
-
将 图片 和 图片ground truth box 信息进行处理,包括:
- 通过 ToTensor 函数 :
- 将图片由 PIL格式 转换为 tensor格式
- 将像素值范围从0~255 转换到 0~1
- 将图像的shape 从 (height, width, channel) 转换为 (channel, height, width)
- (仅训练数据做图像增强处理) 通过 RandomHorizontalFlip 函数,对图像进行数据增强,翻转的概率为0.5。若图像翻转了,对应的 ground truth box 的坐标也要做对应的反转。
- 对图像做 Normalize 处理,均值mean 和 标准差std 使用 ImageNet 数据集的均值和方差, mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]。
- 通过 ToTensor 函数 :
代码框架(我是真的怕了源码中的套娃,造福自己,造福大家,我把相关的文件内容,调用的子函数,一些输出结果,都如下这么标出来了:
https://img-blog.csdnimg.cn/e36ed72ffef6439eaac3a7c2ce45432f.png
2、dataset 代码的相关说明
-
为什么
torchvision库里有中tansforms.Compose、tansforms.ToTensor、tansforms.RandomHorizontalFlip、tansforms.Normalize,我们不直接调用,却要重写呢?
因为直接调用的函数,只能传 image 一个参数。 而翻转图像时,我们不仅要反转图像,还需要一并翻转 box 的坐标。也就是说,我们想给RandomHorizontalFlip传入image和 target 两个参数 (target是一个字典,其中包含 box的坐标),然后在该函数中一并处理 image 和 box 的翻转。所以,就为了 box 翻转,为了传入两个参数,就不得不重写 transform 的那一套东西了。。。 -
为什么不在自己的数据集上计算均值和方差,而是简单的使用 ImageNet 数据集的均值和方差呢?
(很多地方都是这么直接使用的)我理解的是 ImageNet 是一个超大型数据集,在其上计算得出的均值和方差,应该就是绝大部分图像所服从的分布了,是满足需求的,而且自己计算自己数据集的均值和方差的话,耗时耗资源。
3、DataLoader 读取数据
1、pytorch 源码中,在使用 DataLoader 读取batch的时候,不是打乱后随机读取的。其为了节省内存,将图像按照尺寸大小进行了排序,尺寸小的和尺寸小的batch, 尺寸大的和尺寸大的batch,这样在之后padding的时候,小尺寸的就不用因为batch中有大尺寸的而padding 的太多。
这里我懒了,我就直接 batch_size=batch_size , shuffle=True 了,不考虑节省内存问题了,现在的我,搞懂算法主框架才是第一位
2、自己定义了 batch 的打包方式 collate_fn 。
为啥要自己定义,不用默认的呢? 使用默认的会有类似如下报错
stack expects each tensor to be equal size, but got [3, 375, 500] at entry 0 and [3, 500, 375] at entry 5
这是因为 默认的 batch 的打包方式是 stack,需要图像有相同的尺寸才能stack,我们这个时候的 image 的尺寸不是相同的(在之后的 Generalized RCNN Transform 的阶段,才会将 Batch 中的图像处理为相同尺寸),所以这里没法使用默认的 stack 的方式打包batch,而是把 batch_size 个图像 tuple 在一起。
# 自己定义 batch 的打包方式
def collate_fn(batch):
return tuple(zip(*batch))
3、迭代读取batch,并把数据放到 device 上
for images, targets in train_loader:
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
4、代码
Dataset
from torch.utils.data import Dataset
import os
import torch
import json
from PIL import Image
from lxml import etree
from torchvision.transforms import functional as F
import random
class VOCDataSet(Dataset):
def __init__(self, voc_root, train_set=True):
self.root = voc_root
self.img_root = os.path.join(self.root, 'JPEGImages')
self.annotations_root = os.path.join(self.root, 'Annotations')
# read train.txt or val.txt file
if train_set:
txt_list = os.path.join(self.root, 'ImageSets', 'Main', 'train.txt') # 5717
else:
txt_list = os.path.join(self.root, 'ImageSets', 'Main', 'val.txt') # 5823
with open(txt_list) as f:
self.xml_list = [os.path.join(self.annotations_root, line.strip()+'.xml') for line in f.readlines()]
# read class_indict
with open('./pascal_voc_classes.json', 'r') as json_file:
self.class_dict = json.load(json_file)
if train_set:
self.trans = Compose([ToTensor(),
RandomHorizontalFlip(0.5),
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
else:
self.trans = Compose([ToTensor(),
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
def __len__(self):
return len(self.xml_list)
def __getitem__(self, idx):
xml_path = self.xml_list[idx]
filename, target = self.parse_xml(xml_path)
target['image_id'] = torch.tensor([idx])
img_path = os.path.join(self.img_root, filename)
image = Image.open(img_path)
image, target = self.trans(image, target)
return image, target
def parse_xml(self, xml_path):
data_dict = {}
tree_root = etree.parse(xml_path)
# file name
filename = tree_root.find("filename").text
class_list = []
coord_list = []
area_list = []
for object in tree_root.findall("object"):
# class
obj_class = self.class_dict[object.find("name").text]
class_list.append(obj_class)
# bounding box
bbox = object.find("bndbox")
xmin = float(bbox.find("xmin").text)
ymin = float(bbox.find("ymin").text)
xmax = float(bbox.find("xmax").text)
ymax = float(bbox.find("ymax").text)
coord_list.append([xmin, ymin, xmax, ymax])
# area
area = (ymax - ymin) * (xmax - xmin)
area_list.append(area)
data_dict['labels'] = torch.as_tensor(class_list, dtype=torch.int64)
data_dict['boxes'] = torch.as_tensor(coord_list, dtype=torch.float32)
data_dict['area'] = torch.as_tensor(area_list, dtype=torch.float32)
return filename, data_dict
@staticmethod
def collate_fn(batch):
return tuple(zip(*batch))
class Compose(object):
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, image, target):
for t in self.transforms:
image, target = t(image, target)
return image, target
class ToTensor(object):
def __call__(self, image, target):
image = F.to_tensor(image)
return image, target
class RandomHorizontalFlip(object):
def __init__(self, prop=0.5):
self.prop = prop
def __call__(self, image, target):
if random.random() < self.prop:
height, width = image.shape[-2:]
image = image.flip(-1)
bbox = target['boxes']
# bbox: xmin, ymin, xmax, ymax
bbox[:, [0, 2]] = width - bbox[:, [2, 0]]
target['boxes'] = bbox
return image, target
class Normalize(object):
def __init__(self, mean, std, inplace=False):
self.mean = mean
self.std = std
self.inplace = inplace
def __call__(self, image, target):
image = F.normalize(image, self.mean, self.std, self.inplace)
return image, target
DataLoader
voc_root = './VOC2012'
train_dataset = VOCDataSet(voc_root)
valid_dataset = VOCDataSet(voc_root, train_set=False)
batch_size = 8
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])
print('nw:', nw)
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=nw,
collate_fn=train_dataset.collate_fn)
valid_loader = torch.utils.data.DataLoader(valid_dataset,
batch_size=1,
shuffle=False,
pin_memory=True,
num_workers=nw,
collate_fn=valid_dataset.collate_fn)