神经网络入门(一):神经元与单层感知机
文章目录
-
- 神经元
- 单层感知机
- 激活函数
- 多输出感知机
- 单层感知机的几何意义
神经网络的起源是人们力图寻找或者构建一种结构来模拟人脑神经元的功能,并最终达到模拟人脑进行工作甚至达到仿真人的级别。实际上现行的神经网络已经沦为一种算法,该算法与其他算法最主要的区别是能够很好的 处理高度非线性问题。现在对于神将网络的研究主要集中在两个方面,一是挖掘算法的深度,也就是不断地优化改进算法,提出新方法以满足现有的生活实际需要,如人们常说的深度学习网络、循环神经网络等;而是提升现有算法的速度,一般都是基于硬件基础的实现,也就是人们常说的类脑神经计算等。
既然是入门,那么先从最基本的神经网络算法讲起,后期的其他文章中可能会提到一些在累脑计算中的实例。
神经元
有人说现在的神经网络实际上和神经元没有什么关系,其实不然,在现有的神经网络算法中,神经元的作用确实体现的较小,但是在硬件(材料、结构)上的实现时,神经元的深入研究可以更好的推进对材料功能实现的机理理解。那么首先来介绍一下神经元。
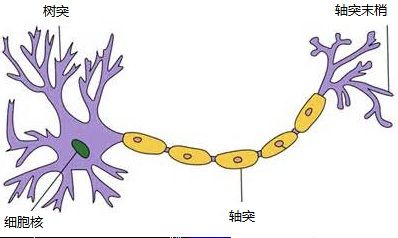
神经元
###数学模型:
下面对上面的这个模型进行抽象处理。首先考虑到神经元结构有多个树突,一个轴突可将其抽象为下图的黑箱结构:

神经元黑箱模型
但是黑箱结构有诸多不便,首先是不知道黑箱中的函数结构就不能为我们所用,其次是输入输出与黑箱的关系也无法量化。因此考虑将上述结构简化,首先把树突到细胞核的阶段简化为线性加权的过程(当然了,该过程也有可能是非线性的,但是我们可以把其非线性过程施加到后面的非线性函数以及多层网络结构中),其次把突触之间的信号传递简化为对求和结果的非线性变换,那么上述模型就变得清晰了:
神经元模型
单层感知机
上面我们介绍的神经元的基本模型实际就是一个感知机的模型,该词最早出现于1958年,计算科学家Rosenblatt提出的由两层神经元组成的神经网络。
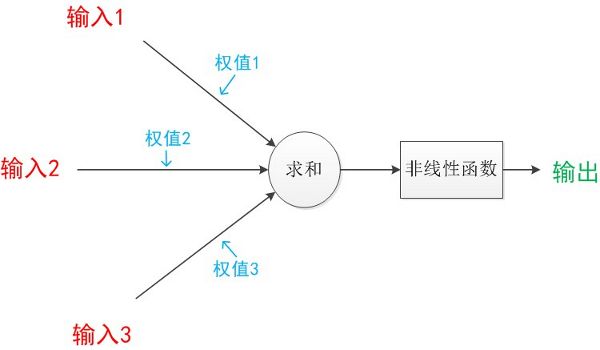
对前面的模型进一步符号化,如下图所示:

感知机模型
可以看到,感知机的基本模型包括:
- 输入: x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn,实际可能回比这更多,此处添加了一个偏置1,是为了平衡线性加权函数总是过零点的问题。
- 权值:对应于每个输入都有一个加权的权值 w 1 , w 2 , . . . , w n w_1 ,w_2,...,w_n w1,w2,...,wn
- 激活函数:激活函数f对应于一个非线性函数,其选择有很多,本文后面会详细介绍
- 输出y:由激活激活函数进行处理后的结果,往往是区分度较大的非连续值用于分类。
y = f ( w 0 + x 1 ∗ w 1 + x 2 ∗ w 2 + ⋯ + x n ∗ w n ) y=f(w_0+x_1*w_1+x_2*w_2+⋯+x_n*w_n) y=f(w0+x1∗w1+x2∗w2+⋯+xn∗wn)
考虑向量的点乘过程,上式又可以简化为:
y = f ( W ∙ x + w 0 ) y=f(W∙x+w_0) y=f(W∙x+w0)
激活函数
首先我们来了解一下激活函数有什么意义,我们前面提到,我们把权重加权的过程看作线性加权,此时该系统为一线性系统,能够解决的问题有限,其非线性部分在激活函数中体现。使用激活函数能够使神经网络更加适应生活实际中的非线性问题。
激活函数通常包括:
- 阶跃函数:
- 优点:输出结构二值化,缺点:0处不可导
f ( x ) = { 1 , x > 0 0 , o t h e r w i s e f(x)=\left\{ \begin{aligned} 1, x>0\\ 0 ,otherwise\\ \end{aligned} \right. f(x)={1,x>00,otherwise

阶跃函数
-
Sigmoid函数
-
优点:可以将很大的数值归一到0-1 缺点:在深度神经网络中会产生梯度消失或梯度爆炸
f ( x ) = 1 1 + e − x f(x)=\frac{1}{1+e^{-x}} f(x)=1+e−x1
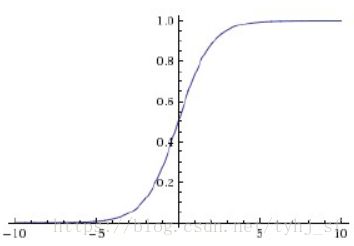
Sigmoid函数
- tanh函数
- 优点:中心对称输出 缺点:梯度消失的问题
t a n h ( x ) = e x − e − x e x + e − x tanh(x) = \frac {e^x - e^{-x}}{e^x + e^{-x}} tanh(x)=ex+e−xex−e−x
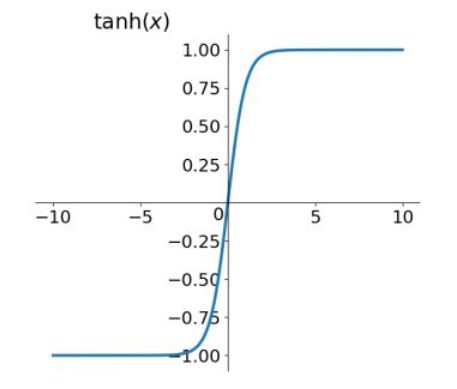
tanh函数
- Relu函数
- 优点:解决了梯度消失问题(只在正区间),且收敛速度快 缺点:非中心对称,且存在某些神经元不会被激活(Dead ReLU Problem)
R e l u = m a x ( 0 , x ) Relu = max(0,x) Relu=max(0,x)
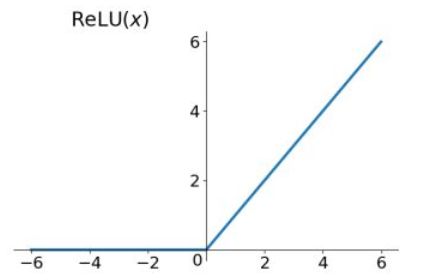
Relu函数
多输出感知机
上面介绍了一个多输入单输出的感知机结构,单输出感知机会很大成都的影响到神经元的级联。实际上在人的大脑中,细胞核通常会通过多个树突与多个神经元相连,这就要考虑到如下的结构了:
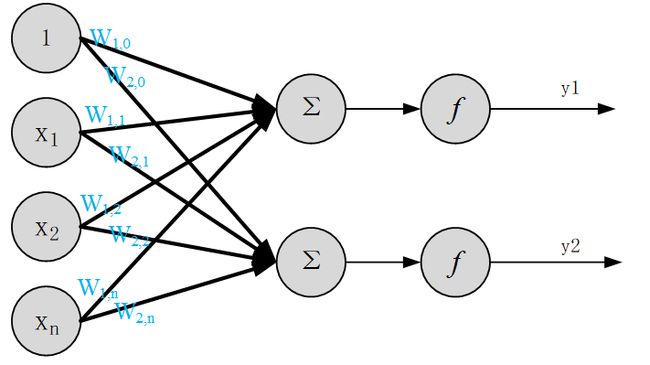
多输出感知机
y 1 = f ( w 1 , 0 + x 1 ∗ w 1 , 1 + x 2 ∗ w 1 , 2 + ⋯ + x n ∗ w 1 , n ) y_1=f(w_{1,0}+x_1*w_{1,1}+x_2*w_{1,2}+⋯+x_n*w_{1,n}) y1=f(w1,0+x1∗w1,1+x2∗w1,2+⋯+xn∗w1,n)
y 2 = f ( w 2 , 0 + x 1 ∗ w 2 , 1 + x 2 ∗ w 2 , 2 + ⋯ + x n ∗ w 2 , n ) y_2=f(w_{2,0}+x_1*w_{2,1}+x_2*w_{2,2}+⋯+x_n*w_{2,n}) y2=f(w2,0+x1∗w2,1+x2∗w2,2+⋯+xn∗w2,n)
那么上式可以简化为矩阵向量相称的形式,即:
y = f ( W ∙ x + w 0 ) y=f(W∙x + w_0) y=f(W∙x+w0)
注意,此时式中
W = [ w 1 , 1 w 1 , 2 . . . w 1 , n w 2 , 1 w 2 , 2 . . . w 2 , n ] W= \left[ \begin{matrix} w_{1,1} & w_{1,2}& ...&w_{1,n} \\ w_{2,1} &w_{2,2}&...&w_{2,n}\\ \end{matrix} \right] W=[w1,1w2,1w1,2w2,2......w1,nw2,n]
x = [ x 1 x 2 . . . x n ] x= \left[ \begin{matrix} x_1 \\ x_2\\ ...\\ x_n \\ \end{matrix} \right] x=⎣⎢⎢⎡x1x2...xn⎦⎥⎥⎤
单层感知机的几何意义
下面我们来考虑单层感知机的几何意义。以二维平面为例, f ( x ) = w 0 + w 1 x 1 + w 2 x 2 f(x)=w_0+w_1 x_1+w_2 x_2 f(x)=w0+w1x1+w2x2在二维平面中是一条直线,而样本点是在二位平面上的点,通过训练权重,可以在二维平面上找到一个合适的权重系数w使直线将样本点划分为两类,以解决传统意义上的是非问题。
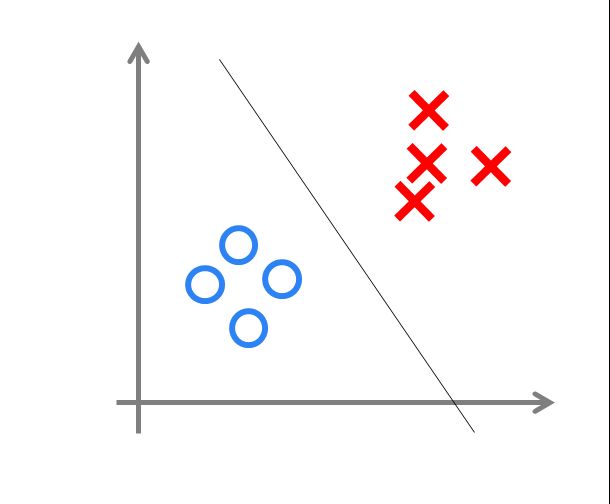
感知器只能做简单的线性分类任务。但是当时的人们热情太过于高涨,并没有人清醒的认识到这点。于是,当人工智能领域的巨擘Minsky指出这点时,事态就发生了变化。
Minsky在1969年出版了一本叫《Perceptron》的书,里面用详细的数学证明了感知器的弱点,尤其是感知器对XOR(异或)这样的简单分类任务都无法解决。这使得神经网络的研究一度低迷长达二十年。
下一节将会介绍多层感知机的内容,戳这可以联系我。