第三章.逻辑回归—正确率/召回率/F1指标,非线性逻辑回归代码
第三章.逻辑回归
3.2 正确率/召回率/F1指标
正确率(Precision)和召回率(Recall)广泛应用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量。
1.概念:
1).正确率:
- 检索出来的条目有多少是正确的
2).召回率:
- 所有正确的条目有多少被检索出来
3).F1:
- 综合上面两个指标的评估指标,用于综合反映整体指标:
F1=2*((正确率*召回率)/(正确率+召回率))
4).取值范围:
- 这几个指标的取值都在0-1之间,数值越接近于1,效果越好。
5).举例:
- 某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的,撒一大网,逮着了700条鲤鱼,200只虾,100只鳖,那么这些指标如下:
①.正确率:700/(700+200+100)=70%
②.召回率:700/1400=50%
③.F值:2*((70*50)/(70+50))=58.3%
2.两个指标的平衡
- 我们希望检索结果Precision和Recall越高越好,但事实上这两者在某些情况下是矛盾的
- 比如极端情况下,我们只搜索出了一个结果,且是准确的,那个Precision就是100%,但是Recall就很低,而我们把所有结果都返回,那么比如Recall是100%,但是Precision就会很低。
- 在不同的场合中需要自己判断是希望Precision比较高还是Recall比较高
3.综合评价指标
正确率与召回率指标有时候会出现矛盾的情况,这就需要综合考虑他们,最常见的方法就是F-Measure(又称F-Score)
1).公式:

2).当β=1时,就是常见的F1指标:

4.实战1:梯度下降法—非线性逻辑回归:
1).CSV中的数据:
- LR-testSet2.csv
2).代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report
from sklearn import preprocessing
from sklearn.preprocessing import PolynomialFeatures # 产生多项式的
# 数据是否是要标准化
scale = False
# 加载数据
data = np.genfromtxt('D:\\Data\\LR-testSet2.csv', delimiter=',')
# 数据切片
x_data = data[:, :-1]
y_data = data[:, -1, np.newaxis]
# 绘制散点图
def plot():
x0 = []
y0 = []
x1 = []
y1 = []
# 切分不同类别的数据
for i in range(len(x_data)):
if y_data[i] == 0:
x0.append(x_data[i, 0])
y0.append(x_data[i, 1])
else:
x1.append(x_data[i, 0])
y1.append(x_data[i, 1])
scatter0 = plt.scatter(x0, y0, c='b', marker='o')
scatter1 = plt.scatter(x1, y1, c='r', marker='x')
plt.legend(handles=[scatter0, scatter1], labels=['label1', 'label2'])
plot()
plt.show()
# sigmoid函数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 代价函数
def cost(xMat, yMat, ws):
value1 = np.multiply(yMat, np.log(sigmoid(xMat * ws)))
value2 = np.multiply(1 - yMat, np.log(1 - sigmoid(xMat * ws)))
return np.sum(value1 + value2) / -(len(xMat))
# 梯度下降法
def gradAscent(xArr, yArr):
if scale == True:
xArr = preprocessing.scale(xArr)
xMat = np.mat(xArr)
yMat = np.mat(yArr)
lr = 0.03
epochs = 50000
costList = []
# 计算数据列数,有几列就有几个权值
m, n = np.shape(xMat)
# 初始化权值
ws = np.mat(np.ones((n, 1)))
for i in range(epochs + 1):
h = sigmoid(xMat * ws)
# 计算误差
ws_grad = xMat.T * (h - yMat) / m
ws = ws - lr * ws_grad
if i % 50 == 0:
costList.append(cost(xMat, yMat, ws))
return ws, costList
# 定义多项式回归,degree的值可以调节多项式的特征
poly_reg = PolynomialFeatures(degree=3)
# 特征处理
x_poly = poly_reg.fit_transform(x_data)
# 训练模型
ws, costList = gradAscent(x_poly, y_data)
# 获取数据值所在的范围
x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1
y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1
# 生出网格矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), np.arange(y_min, y_max, 0.02))
# 特征处理+维度转换
z = sigmoid(poly_reg.fit_transform(np.c_[xx.ravel(), yy.ravel()]).dot(np.array(ws)))
for i in range(len(z)):
if z[i] >= 0.5:
z[i] = 1
else:
z[i] = 0
z = z.reshape(xx.shape)
# 等高线图
cs = plt.contourf(xx, yy, z)
plot()
plt.show()
# 预测
def predict(x_data, ws):
if scale == True:
x_data = preprocessing(x_data)
xMat = np.mat(x_data)
ws = np.mat(ws)
return [1 if x >= 0.5 else 0 for x in sigmoid(xMat * ws)]
predictions = predict(x_poly, ws)
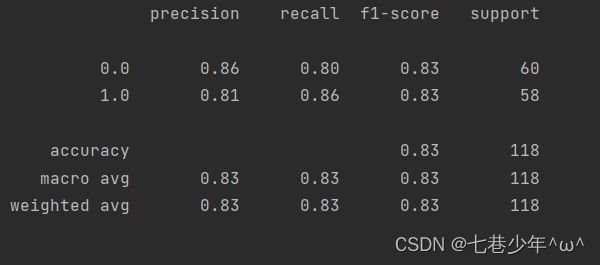
print(classification_report(y_data, predictions))
3).结果展示:
①.数据
②.图像

5.实战2: sklearn—非线性逻辑回归:
1).代码
import matplotlib.pyplot as plt
import numpy as np
from sklearn import linear_model
from sklearn.preprocessing import PolynomialFeatures
from sklearn.datasets import make_gaussian_quantiles
# 生成二维正态分布,生成的数据按分位数分为两类,500个样本,2个样本特征
# 可以生成两类或多类数据
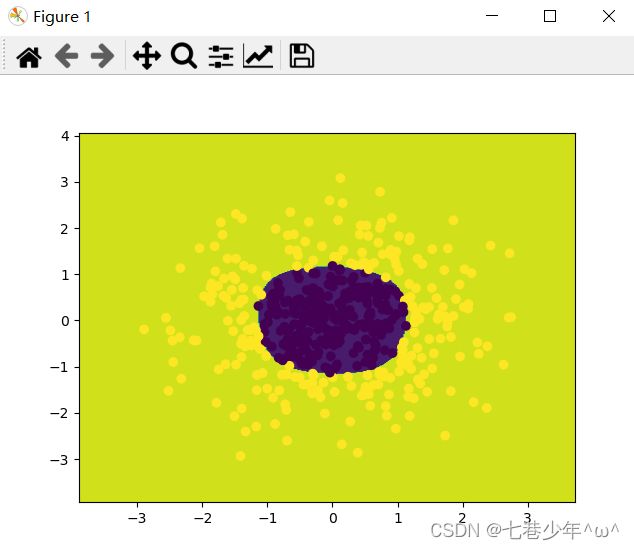
x_data, y_data = make_gaussian_quantiles(n_samples=500, n_features=2, n_classes=2)
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()
# 定义多项式回归,degree的值可以调节多形式的特征
poly_reg = PolynomialFeatures(degree=5)
# 特征处理
x_poly = poly_reg.fit_transform(x_data)
# 定义并训练模型
logistic = linear_model.LogisticRegression()
logistic.fit(x_poly, y_data)
# 获取数值所在范围
x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1
y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1
# 生成网络矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), np.arange(y_min, y_max, 0.02))
z = logistic.predict(poly_reg.fit_transform(np.c_[xx.ravel(), yy.ravel()]))
z = z.reshape(xx.shape)
# 绘制等高线
cs = plt.contourf(xx, yy, z)
# 样本散点图
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()
print('score:', logistic.score(x_poly, y_data))
2).结果展示:
①.数据
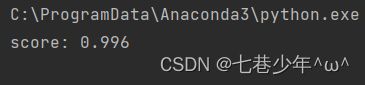
②.图像