深度学习tricks——学习率策略
参考文章:Bag of Tricks for Image Classification with Convolutional Neural Networks
学习率的递减:
在训练初期,我们希望以较大的学习率对模型参数进行调整,以加快训练速度;在训练末期,我们希望以较小的学习率对模型参数进行微调,以确保收敛至最优点。因此,学习率一般采用递减(多次递减/循环递减)的策略,递减方式有线性(Linear)、余弦(Cosine)、步进(Step)等。
学习率的热身:
网络在开始训练时,以一个较小的学习率经过少量的epoch后递增到设定学习率(lr0)的阶段称为热身(warm-up)阶段。warm-up策略可以解决训练初期的数值不稳定的问题和动量历史值不准确的问题。

学习率曲线:
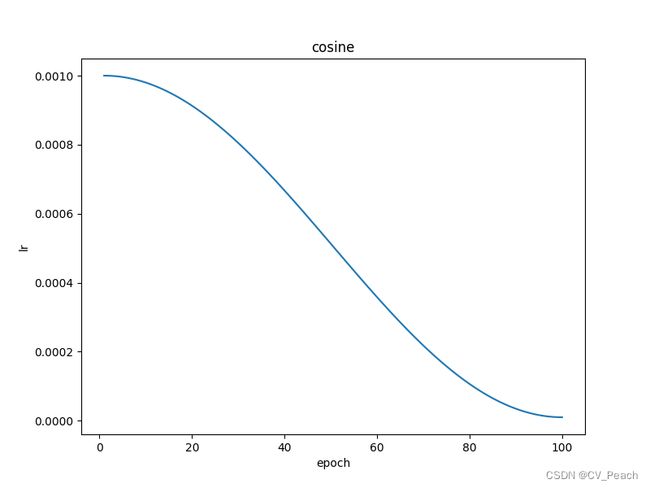

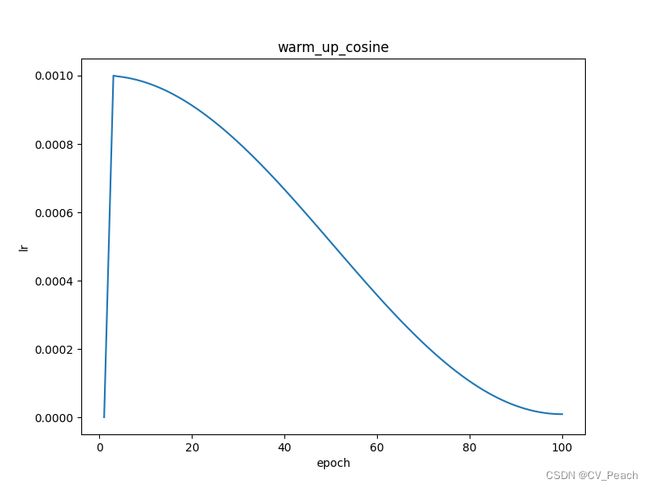

(代码实现warm up时,实际上是将原始学习率策略的前几个epoch替换成warm up学习率策略,所以在warm up linear lr中存在一处拐点,影响不大)
代码仅实现warm-up策略和Linear、Cosine学习率策略
import numpy as np
import torch.nn as nn
from functools import partial
from torch.optim import lr_scheduler, Adam
import math
import matplotlib.pyplot as plt
def get_cosine_lr_scheduler(lr_max_ratio, lr_min_ratio, num_epochs, epoch): # 余弦学习率
return (math.cos(epoch * math.pi / (num_epochs - 1)) / 2) * (lr_max_ratio - lr_min_ratio) + \
lr_min_ratio + (lr_max_ratio - lr_min_ratio) / 2
def get_linear_lr_scheduler(lr_max_ratio, lr_min_ratio, num_epochs, epoch): # 线性学习率
return (1 - epoch / (num_epochs - 1)) * (lr_max_ratio - lr_min_ratio) + lr_min_ratio
def get_warm_up_scheduler(warmup_epochs, lr_init_ratio, lr_max_ratio, epoch): # 热身阶段学习率,默认为线性
return epoch / (warmup_epochs - 1) * (lr_max_ratio - lr_init_ratio) + lr_init_ratio
def get_warm_up_cosine_lr_scheduler(warmup_epochs, lr_init_ratio, lr_max_ratio, lr_min_ratio, num_epochs,
epoch): # 热身-余弦学习率
if epoch < warmup_epochs:
return get_warm_up_scheduler(warmup_epochs, lr_init_ratio, lr_max_ratio, epoch)
else:
return get_cosine_lr_scheduler(lr_max_ratio, lr_min_ratio, num_epochs, epoch)
def get_warm_up_linear_lr_scheduler(warmup_epochs, lr_init_ratio, lr_max_ratio, lr_min_ratio, num_epochs,
epoch): # 热身-线性学习率
if epoch < warmup_epochs:
return get_warm_up_scheduler(warmup_epochs, lr_init_ratio, lr_max_ratio, epoch)
else:
return get_linear_lr_scheduler(lr_max_ratio, lr_min_ratio, num_epochs, epoch)
def get_lr_func(lr_type, num_epochs): # 获得学习率函数
lr_max_ratio = 1. # 最大学习率的倍数,默认为1.,即最大学习率为lr0
lr_min_ratio = 0.01 # 最小学习率的倍数,默认为0.01,即最小学习率为0.01lr0(这里最小学习率不包括热身阶段,仅包括正式训练阶段)
warmup_epochs = 3 # 热身epochs数,默认为3
lr_init_ratio = lr_min_ratio * 0.1 # 热身的初始学习率,默认为最小学习率的0.1倍
if lr_type == "cosine":
lf = partial(get_cosine_lr_scheduler, lr_max_ratio, lr_min_ratio, num_epochs)
elif lr_type == "warm_up_cosine":
lf = partial(get_warm_up_cosine_lr_scheduler, warmup_epochs, lr_init_ratio, lr_max_ratio, lr_min_ratio,
num_epochs)
elif lr_type == "linear":
lf = partial(get_linear_lr_scheduler, lr_max_ratio, lr_min_ratio, num_epochs)
elif lr_type == "warm_up_linear":
lf = partial(get_warm_up_linear_lr_scheduler, warmup_epochs, lr_init_ratio, lr_max_ratio, lr_min_ratio,
num_epochs)
return lf
if __name__ == "__main__":
lr0 = 1e-3 # lr0(基准)
num_epochs = 100 # 训练epochs总数
model = nn.Sequential(nn.Linear(1, 1)) # 构建一个示例模型
optimizer = Adam(model.parameters(), lr=lr0) # 优化器,并传入基准lr0
lr_type_list = ["cosine", "linear", "warm_up_cosine", "warm_up_linear"] # 可选择的lr策略
for lr_type in lr_type_list:
lf = get_lr_func(lr_type, num_epochs)
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # 构建lr scheduler,并传入优化器和lr变化策略(函数)
lr_list = [] # 存放lr
for e in range(num_epochs): # 循环epochs
lr_list.append(optimizer.param_groups[0]["lr"]) # 获取当前epoch的lr,并存入列表
scheduler.step() # 调整lr
# 绘图显示lr曲线
plt.figure(figsize=(8, 6))
x = np.linspace(1, num_epochs, num_epochs)
plt.plot(x, lr_list)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title(lr_type)
plt.show()