深度不学习————Attention is all you need
目录
Transformer
The Motivation for Transformers
Dot-Product Attention (Extending our previous def.)
Dot-Product Attention – Matrix notation
Scaled Dot-Product Attention
Self-attention in the encoder
Multi-head attention
Complete transformer block
Encoder Input
Complete Encoder
Attention visualization in layer 5
Attention visualization: Implicit anaphora resolution
Transformer Decoder
Position-wise FFN, Embedding and Softmax
Position-wise FFN
Embedding and Softmax
Training
Warmup
Regularization
Conclusion
Tips and tricks of the Transformer
Reference
Transformer
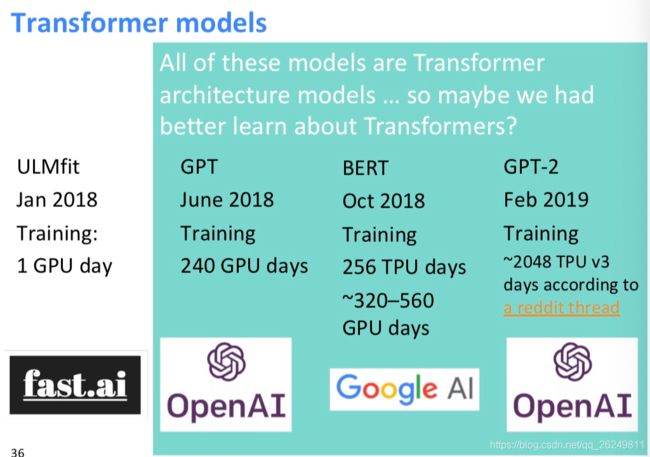
The Motivation for Transformers
- 我们想要并⾏化,但是RNNs本质上是顺序的
- 尽管有GRUs和LSTMs, RNNs仍然需要注意机制来处理⻓期依赖关系——否则状态之间的 path
- length 路径⻓度 会随着序列增⻓
- 但如果注意⼒让我们进⼊任何⼀个状态……也许我们可以只⽤注意⼒⽽不需要RNN?
Dot-Product Attention (Extending our previous def.)
- 输⼊:对于⼀个输出⽽⾔的查询 q 和⼀组键-值对 k-v
- Query, keys, values, and output 都是向量
- 输出值的加权和
- 权重的每个值是由查询和相关键的内积计算结果
- Query 和 keys 有相同维数dk ,value 的维数为dv

Dot-Product Attention – Matrix notation
- When we have multiple queries q, we stack them in a matrix Q:


Scaled Dot-Product Attention


Scaled Dot-Product Attention一般翻译做"缩放点积attention"。一般,在attention机制中,我们使用一个query和一组key做点积(dot-product),然后再对该结果套用一个softmax得到一组权重(weights),将该权重应用到一组value之上,得到的就是我们的attention。在实际使用中query有多个,为了能同时对这些query进行attention操作,将这些query拼成一个矩阵Q。我们可以把softmax公式写成:
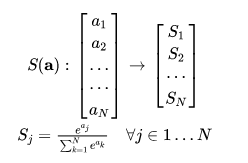 softmax公式改写
softmax公式改写  梯度
梯度
softmax函数是在定义域上是可微的,那么对其求导,就得到梯度。
显然无论是i=j还是i不等于j时, Si和Sj都会很大(Q和K的点积结果很大),那么都是负值且很小。
代码部分:
import torch
import torch.nn as nn
class ScaledDotProductAttention(nn.Module):
"""Scaled dot-product attention mechanism."""
def __init__(self, attention_dropout=0.0):
super(ScaledDotProductAttention, self).__init__()
self.dropout = nn.Dropout(attention_dropout)
self.softmax = nn.Softmax(dim=2)
def forward(self, q, k, v, scale=None, attn_mask=None):
"""前向传播.
Args:
q: Queries张量,形状为[B, L_q, D_q]
k: Keys张量,形状为[B, L_k, D_k]
v: Values张量,形状为[B, L_v, D_v],一般来说就是k
scale: 缩放因子,一个浮点标量
attn_mask: Masking张量,形状为[B, L_q, L_k]
Returns:
上下文张量和attetention张量
"""
attention = torch.bmm(q, k.transpose(1, 2))
if scale:
attention = attention * scale
if attn_mask:
# 给需要mask的地方设置一个负无穷
attention = attention.masked_fill_(attn_mask, -np.inf)
# 计算softmax
attention = self.softmax(attention)
# 添加dropout
attention = self.dropout(attention)
# 和V做点积
context = torch.bmm(attention, v)
return context, attention
Self-attention in the encoder
- 输⼊单词向量是queries, keys and values
- 换句话说:这个词向量⾃⼰选择彼此
- 词向量堆栈= Q = K = V
- 我们会通过解码器明⽩为什么我们在定义中将他们分开
Multi-head attention

- 简单self-attention的问题
- 单词只有⼀种相互交互的⽅式
- 解决⽅案:多头注意⼒
- ⾸先通过矩阵 W 将 Q, K, V 映射到 h = 8 的许多低维空间
- 然后应⽤注意⼒,然后连接输出,通过线性层
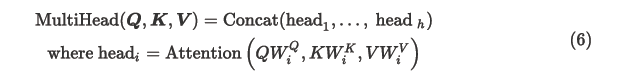
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, model_dim=512, num_heads=8, dropout=0.0):
super(MultiHeadAttention, self).__init__()
self.dim_per_head = model_dim // num_heads
self.num_heads = num_heads
self.linear_k = nn.Linear(model_dim, self.dim_per_head * num_heads)
self.linear_v = nn.Linear(model_dim, self.dim_per_head * num_heads)
self.linear_q = nn.Linear(model_dim, self.dim_per_head * num_heads)
self.dot_product_attention = ScaledDotProductAttention(dropout)
self.linear_final = nn.Linear(model_dim, model_dim)
self.dropout = nn.Dropout(dropout)
# multi-head attention之后需要做layer norm
self.layer_norm = nn.LayerNorm(model_dim)
def forward(self, key, value, query, attn_mask=None):
# 残差连接
residual = query
dim_per_head = self.dim_per_head
num_heads = self.num_heads
batch_size = key.size(0)
# linear projection
key = self.linear_k(key)
value = self.linear_v(value)
query = self.linear_q(query)
# split by heads
key = key.view(batch_size * num_heads, -1, dim_per_head)
value = value.view(batch_size * num_heads, -1, dim_per_head)
query = query.view(batch_size * num_heads, -1, dim_per_head)
if attn_mask:
attn_mask = attn_mask.repeat(num_heads, 1, 1)
# scaled dot product attention
scale = (key.size(-1) // num_heads) ** -0.5
context, attention = self.dot_product_attention(
query, key, value, scale, attn_mask)
# concat heads
context = context.view(batch_size, -1, dim_per_head * num_heads)
# final linear projection
output = self.linear_final(context)
# dropout
output = self.dropout(output)
# add residual and norm layer
output = self.layer_norm(residual + output)
return output, attention
Complete transformer block
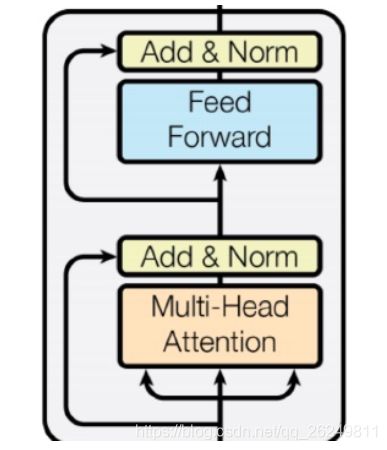 每个 block 都有两个“⼦层”
每个 block 都有两个“⼦层”
1. 多头 attention
2. 两层的前馈神经⽹络,使⽤ ReLU 这两个⼦层都:
* 残差连接以及层归⼀化
* LayerNorm(x+Sublayer(x))
*层归⼀化将输⼊转化为均值是 0,⽅差是 1 ,每⼀层和每⼀个训练点(并且添加了两个参数)
Encoder Input
到目前为止,模型中并没有可以准确学习到序列位置信息的神经网络组件。为了能学习到序列中相对或者绝对的位置信息,实际上有两种选择:positional encoding和learned positional embedding。这里采取了前者。
- 实际的词表示是 byte-pair 编码
- 还添加了⼀个 positional encoding 位置编码,相同的词语在不同的位置有不同的整体表征

在实际使用过程中,positional encoding的维度和embeddings的维度大小均设置为d(model),然后会将两者相加(sum)。其中,即position,意为token在句中的位置,设句子长度为L.Positional Encoding的每一维对应一个正弦曲线,其波长形成一个从到10000*的等比级数。这样做的理由是,作者认为这样可以使模型更易学习到相对位置,因为对于某个任意确定的偏移值k,PE(pos+k) 可被表示为PE(pos)的一个线性变换结果。
import torch
import torch.nn as nn
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_len):
"""初始化。
Args:
d_model: 一个标量。模型的维度,论文默认是512
max_seq_len: 一个标量。文本序列的最大长度
"""
super(PositionalEncoding, self).__init__()
# 根据论文给的公式,构造出PE矩阵
position_encoding = np.array([
[pos / np.pow(10000, 2.0 * (j // 2) / d_model) for j in range(d_model)]
for pos in range(max_seq_len)])
# 偶数列使用sin,奇数列使用cos
position_encoding[:, 0::2] = np.sin(position_encoding[:, 0::2])
position_encoding[:, 1::2] = np.cos(position_encoding[:, 1::2])
# 在PE矩阵的第一行,加上一行全是0的向量,代表这`PAD`的positional encoding
# 在word embedding中也经常会加上`UNK`,代表位置单词的word embedding,两者十分类似
# 那么为什么需要这个额外的PAD的编码呢?很简单,因为文本序列的长度不一,我们需要对齐,
# 短的序列我们使用0在结尾补全,我们也需要这些补全位置的编码,也就是`PAD`对应的位置编码
pad_row = torch.zeros([1, d_model])
position_encoding = torch.cat((pad_row, position_encoding))
# 嵌入操作,+1是因为增加了`PAD`这个补全位置的编码,
# Word embedding中如果词典增加`UNK`,我们也需要+1。看吧,两者十分相似
self.position_encoding = nn.Embedding(max_seq_len + 1, d_model)
self.position_encoding.weight = nn.Parameter(position_encoding,
requires_grad=False)
def forward(self, input_len):
"""神经网络的前向传播。
Args:
input_len: 一个张量,形状为[BATCH_SIZE, 1]。每一个张量的值代表这一批文本序列中对应的长度。
Returns:
返回这一批序列的位置编码,进行了对齐。
"""
# 找出这一批序列的最大长度
max_len = torch.max(input_len)
tensor = torch.cuda.LongTensor if input_len.is_cuda else torch.LongTensor
# 对每一个序列的位置进行对齐,在原序列位置的后面补上0
# 这里range从1开始也是因为要避开PAD(0)的位置
input_pos = tensor(
[list(range(1, len + 1)) + [0] * (max_len - len) for len in input_len])
return self.position_encoding(input_pos)
Complete Encoder
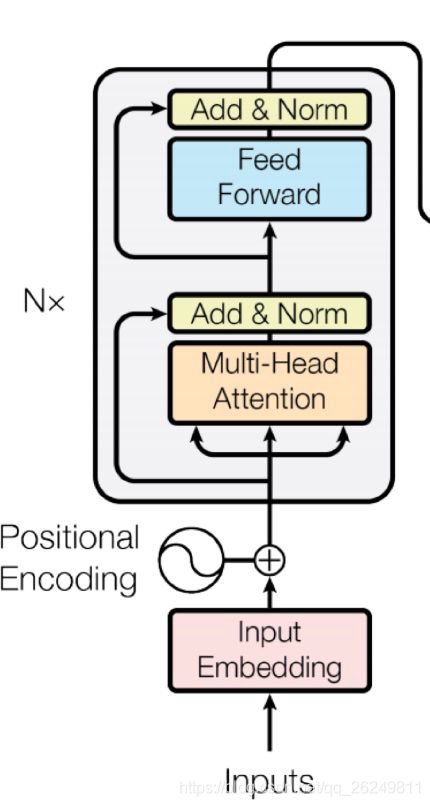 * encoder 中,每个 block 都是来⾃前⼀层的 Q, K, V * Blocks 被重复 6 次(垂直⽅向) * 在每个阶段,你可以通过多头注意⼒看到句⼦中的各个地⽅,累积信息并将其推送到下⼀层。在任⼀⽅向上的序列逐步推送信息来计算感兴趣的值 。 * ⾮常善于学习语⾔结构 * encoder由6层相同的层组成,每一层分别由两部分组成: * 第一部分是一个multi-head self-attention mechanism * 第二部分是一个position-wise feed-forward network,是一个全连接层 两个部分,都有一个残差连接(residual connection),然后接着一个Layer Normalization。
* encoder 中,每个 block 都是来⾃前⼀层的 Q, K, V * Blocks 被重复 6 次(垂直⽅向) * 在每个阶段,你可以通过多头注意⼒看到句⼦中的各个地⽅,累积信息并将其推送到下⼀层。在任⼀⽅向上的序列逐步推送信息来计算感兴趣的值 。 * ⾮常善于学习语⾔结构 * encoder由6层相同的层组成,每一层分别由两部分组成: * 第一部分是一个multi-head self-attention mechanism * 第二部分是一个position-wise feed-forward network,是一个全连接层 两个部分,都有一个残差连接(residual connection),然后接着一个Layer Normalization。
import torch
import torch.nn as nn
class EncoderLayer(nn.Module):
"""Encoder的一层。"""
def __init__(self, model_dim=512, num_heads=8, ffn_dim=2018, dropout=0.0):
super(EncoderLayer, self).__init__()
self.attention = MultiHeadAttention(model_dim, num_heads, dropout)
self.feed_forward = PositionalWiseFeedForward(model_dim, ffn_dim, dropout)
def forward(self, inputs, attn_mask=None):
# self attention
context, attention = self.attention(inputs, inputs, inputs, padding_mask)
# feed forward network
output = self.feed_forward(context)
return output, attention
class Encoder(nn.Module):
"""多层EncoderLayer组成Encoder。"""
def __init__(self,
vocab_size,
max_seq_len,
num_layers=6,
model_dim=512,
num_heads=8,
ffn_dim=2048,
dropout=0.0):
super(Encoder, self).__init__()
self.encoder_layers = nn.ModuleList(
[EncoderLayer(model_dim, num_heads, ffn_dim, dropout) for _ in
range(num_layers)])
self.seq_embedding = nn.Embedding(vocab_size + 1, model_dim, padding_idx=0)
self.pos_embedding = PositionalEncoding(model_dim, max_seq_len)
def forward(self, inputs, inputs_len):
output = self.seq_embedding(inputs)
output += self.pos_embedding(inputs_len)
self_attention_mask = padding_mask(inputs, inputs)
attentions = []
for encoder in self.encoder_layers:
output, attention = encoder(output, self_attention_mask)
attentions.append(attention)
return output, attentions
Attention visualization in layer 5
- 词语开始以合理的⽅式关注其他词语

- 不同的颜⾊对应不同的注意⼒头
Attention visualization: Implicit anaphora resolution

- 对于代词,注意⼒头学会了如何找到其指代物
- 在第五层中,从 head 5 和 6 的单词“its”中分离出来的注意⼒。请注意,这个词的注意⼒是⾮常鲜明的。
Transformer Decoder
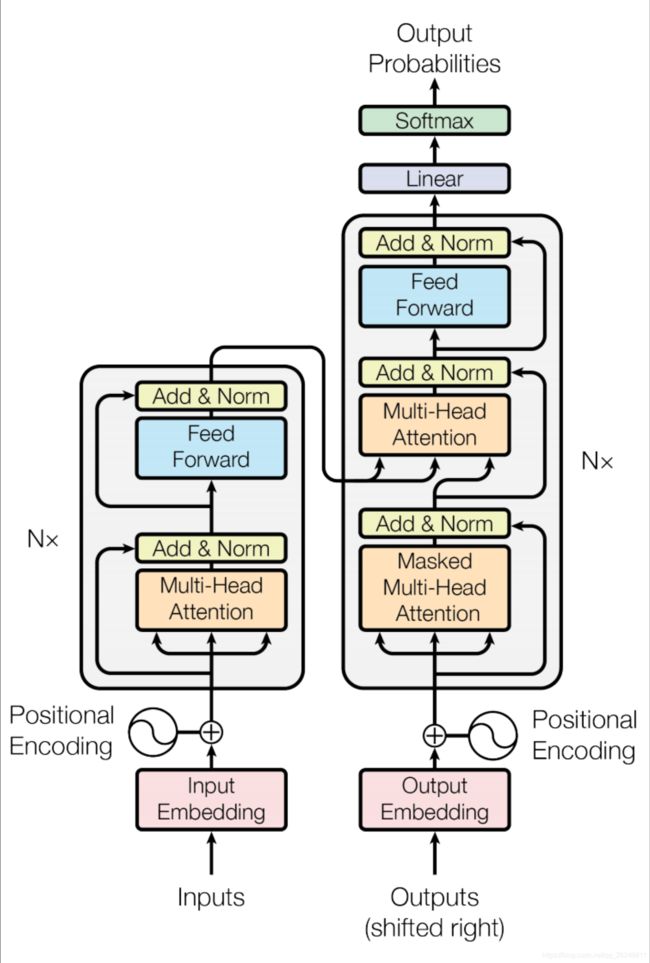 decoder 中有两个稍加改变的⼦层 对之前⽣成的输出进⾏ Masked decoder self-attention
decoder 中有两个稍加改变的⼦层 对之前⽣成的输出进⾏ Masked decoder self-attention- Encoder-Decoder Attention,queries 来⾃于前⼀个 decoder 层,keys 和 values 来⾃于encoder 的输出;Blocks 同样重复 6 次
Decoder
和encoder类似,decoder由6个相同的层组成,每一个层包括以下3个部分:
第一个部分是multi-head self-attention mechanism
第二部分是multi-head context-attention mechanism
第三部分是一个position-wise feed-forward network
还是和encoder类似,上面三个部分的每一个部分,都有一个残差连接,后接一个Layer Normalization。
import torch
import torch.nn as nn
class DecoderLayer(nn.Module):
def __init__(self, model_dim, num_heads=8, ffn_dim=2048, dropout=0.0):
super(DecoderLayer, self).__init__()
self.attention = MultiHeadAttention(model_dim, num_heads, dropout)
self.feed_forward = PositionalWiseFeedForward(model_dim, ffn_dim, dropout)
def forward(self,
dec_inputs,
enc_outputs,
self_attn_mask=None,
context_attn_mask=None):
# self attention, all inputs are decoder inputs
dec_output, self_attention = self.attention(
dec_inputs, dec_inputs, dec_inputs, self_attn_mask)
# context attention
# query is decoder's outputs, key and value are encoder's inputs
dec_output, context_attention = self.attention(
enc_outputs, enc_outputs, dec_output, context_attn_mask)
# decoder's output, or context
dec_output = self.feed_forward(dec_output)
return dec_output, self_attention, context_attention
class Decoder(nn.Module):
def __init__(self,
vocab_size,
max_seq_len,
num_layers=6,
model_dim=512,
num_heads=8,
ffn_dim=2048,
dropout=0.0):
super(Decoder, self).__init__()
self.num_layers = num_layers
self.decoder_layers = nn.ModuleList(
[DecoderLayer(model_dim, num_heads, ffn_dim, dropout) for _ in
range(num_layers)])
self.seq_embedding = nn.Embedding(vocab_size + 1, model_dim, padding_idx=0)
self.pos_embedding = PositionalEncoding(model_dim, max_seq_len)
def forward(self, inputs, inputs_len, enc_output, context_attn_mask=None):
output = self.seq_embedding(inputs)
output += self.pos_embedding(inputs_len)
self_attention_padding_mask = padding_mask(inputs, inputs)
seq_mask = sequence_mask(inputs)
self_attn_mask = torch.gt((self_attention_padding_mask + seq_mask), 0)
self_attentions = []
context_attentions = []
for decoder in self.decoder_layers:
output, self_attn, context_attn = decoder(
output, enc_output, self_attn_mask, context_attn_mask)
self_attentions.append(self_attn)
context_attentions.append(context_attn)
return output, self_attentions, context_attentions
Position-wise FFN, Embedding and Softmax
Position-wise FFN
和其他所有的全连接层类似,这里的全连接包含了两次变化,使用的是ReLU激活函数。形式化描述如下公式:
![]()
Embedding and Softmax
作者使用了预训练的向量(learned embeddings)来表示输入和输出tokens,维度大小为dmodel。在Decoder输出的最后,使用了一个线性映射变化和一个softmax来将输出转换为概率。此外,两个embeddings层和线性变化使用的都是同一个权重矩阵。
Training
Warmup
本文在这里的做法是:先在模型初始训练的时候,把学习率设在一个很小的值,然后warmup到一个大学习率,后面再进行衰减。所以,刚开始是warmup的热身过程,是一个线性增大的过程,到后面才开始衰减。
Regularization
1). Residual Dropout
在前面已经叙述过,在每个网络子层处,都使用了残差连接;另外,前面没有提过的是,在Encoder和Decoder中将embeddings和positional encodings相加后的和也使用了dropout。
2). Label Smoothing
即标签平滑,目的是防止过拟合。论文中说,标签平滑虽会影响ppl(perplexity),但能提高模型的准确率和BLEU分数。
Conclusion
- 它本质上是一个seq2seq的结构,仅仅依赖self-attention,完全摒弃CNN和RNN;
- Encoder中包含两个子层,第一个子层是Multi-Head Self-Attention,第二个子层是一个全连接层;
- Decoder中包含三个子层,第一个子层是Masked Multi-Head Self-Attention,第二个子层是Encoder-Decoder Attention,第三个子层是一个全连接层;
- 值得注意的是,上述的每个子层中,都用到了残差连接和Layer Normalizatoin;
Tips and tricks of the Transformer
- Byte-pair encodings
- Checkpoint averaging
- Adam 优化器控制学习速率变化
- 训练时,在每⼀层添加残差之前进⾏ Dropout
- 标签平滑
- 带有束搜索和⻓度惩罚的 Auto-regressive decoding
- 因为 transformer 正在蔓延,但他们很难优化并且不像LSTMs那样开箱即⽤,他们还不能很好与
- 其他任务的构件共同⼯作
import torch
import torch.nn as nn
class Transformer(nn.Module):
def __init__(self,
src_vocab_size,
src_max_len,
tgt_vocab_size,
tgt_max_len,
num_layers=6,
model_dim=512,
num_heads=8,
ffn_dim=2048,
dropout=0.2):
super(Transformer, self).__init__()
self.encoder = Encoder(src_vocab_size, src_max_len, num_layers, model_dim,
num_heads, ffn_dim, dropout)
self.decoder = Decoder(tgt_vocab_size, tgt_max_len, num_layers, model_dim,
num_heads, ffn_dim, dropout)
self.linear = nn.Linear(model_dim, tgt_vocab_size, bias=False)
self.softmax = nn.Softmax(dim=2)
def forward(self, src_seq, src_len, tgt_seq, tgt_len):
context_attn_mask = padding_mask(tgt_seq, src_seq)
output, enc_self_attn = self.encoder(src_seq, src_len)
output, dec_self_attn, ctx_attn = self.decoder(
tgt_seq, tgt_len, output, context_attn_mask)
output = self.linear(output)
output = self.softmax(output)
return output, enc_self_attn, dec_self_attn, ctx_attn
这里推荐一些超棒的适合进阶的Transformer相关博文和知乎讨论:
博文:
-
碎碎念:Transformer的细枝末节(https://zhuanlan.zhihu.com/p/60821628)
-
[整理] 聊聊 Transformer(https://zhuanlan.zhihu.com/p/47812375)
-
《Attention is All You Need》浅读(简介+代码)(https://kexue.fm/archives/4765)
-
香侬读 | Transformer中warm-up和LayerNorm的重要性探究(https://zhuanlan.zhihu.com/p/84614490)
知乎讨论:
-
为什么Transformer 需要进行 Multi-head Attention?(https://www.zhihu.com/question/341222779/answer/814111138)
-
Transformer使用position encoding会影响输入embedding的原特征吗?(https://www.zhihu.com/question/350116316/answer/863151712)
-
如何理解Transformer论文中的positional encoding,和三角函数有什么关系?(https://www.zhihu.com/question/347678607/answer/835053468)
-
神经网络中 warmup 策略为什么有效;有什么理论解释么?(https://www.zhihu.com/question/338066667/answer/771252708)
Reference
https://mp.weixin.qq.com/s?__biz=MjM5ODkzMzMwMQ==&mid=2650412310&idx=3&sn=a9b611408e7ab4c20a55b9632e78ce9a&utm_source=tuicool&utm_medium=referral
Attention Is All You Need(https://arxiv.org/abs/1706.03762)
CS224n
https://blog.csdn.net/stupid_3/article/details/83184691
jadore801120/attention-is-all-you-need-pytorch
JayParks/transformer