【Pytorch项目实战】之强化学习:Q-Learning、SARSA、DQN
文章目录
- 强化学习(Reinforcement Learning)
-
- 算法一:Q-Learning
- 算法二:SARSA(State-Action-Reward-State-Action)
- 算法三:DQN(Deep Q-Network)
- (一)实战:基于Q-Learning算法的强化学习
- (二)实战:基于SARSA算法的强化学习
- (三)实战:基于DQN算法的深度强化学习
强化学习(Reinforcement Learning)
主要特点:没有预先给定标签或模板,在一无所知的情况下,不断尝试,从错误或惩罚中学习并找规律,达到学习的目的。
强化学习架构:环境(Environment)、主体(Agent)、状态(State)、动作(Action)、奖励(Reward)
工作流程:在当前游戏(环境)中,主人公(主体)有很多的静态行为(状态)可供选择,通过动态行为(动作)触发开关,并进行正向或负向的反馈(奖励)。
最终目的:找到最优的策略Policy,使奖励Reward最多。

常用算法:Q-Learning、SARSA、深度Q网络(Deep Q Network,DQN)、策略梯度(Policy Gradients)等。
- 经典强化学习算法(Q-Learning、SARSA)特点:
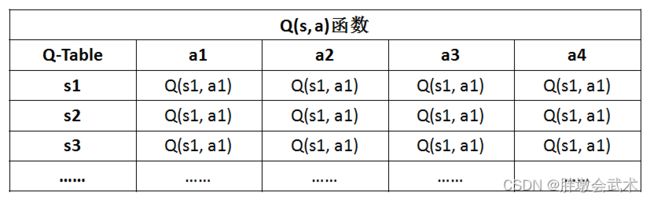
- (1)仅适用于状态和动作是离散且维数不高时,可使用Q-Table存储每一个状态动作对的Q值,但不适用于连续且高维的情况。
- (2)当状态和动作数量较少时,状态和动作需要人工预先设计的。
- (3)Q函数值需要存储在一个二维表中。
问题1:(1)在实际应用下,由于场景很复杂,很难定义出离散且有限的状态和动作。
问题2:(2)即使能够定义,数量非常大的情况下,无法用数组存储。
- 深度强化学习算法(DQN、Policy Gradients)特点:
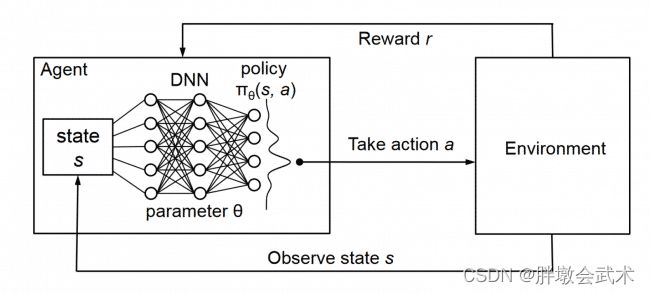
- (1)深度强化学习(Deep ReinForcement Learning,DRL)是深度学习和强化学习相结合的产物,集成了深度学习在视觉上的强大理解能力,以及强化学习的决策能力。
- (2)当状态和动作空间是连续且高维时,可以将Q-Table的Q值更新问题 -> 变成 -> 函数拟合问题。即寻找最优参数θ,使Q(s, a, θ)无限逼近最优Q值。而参数学习正是深度学习的强项。
主要应用:游戏、机器人、车载导航、工业物流等领域。
算法一:Q-Learning
Q-Learning是强化学习的开山之作。
局限性:若每次都采取
非极大值抑制(NMS)的行动策略,有些动作将始终无法选择,进而导致无法更新Q值,将不利于发现更有价值的情况。
解决方法:贪婪策略(ε-greedy)。即预先设置一个ε(epsilon)值,如果Q(s,a)>ε,则随机行动;否则取非极大值机制NMS对应的行动。
Q-Learning算法(图表理解)


算法二:SARSA(State-Action-Reward-State-Action)
强化学习 SARSA(Pytorch实战)
- 具体过程:
(1)学习特定state和特定action下的价值Q,最终建立和优化一个Q表(该表以state为行,以action为列),根据与环境交互得到的reward来更新Q表。
(2)为了更好的探索环境,采用ε-greedy方式来训练,有一定概率随机选择动作输出。- SARSA是Q-Learning的变种算法,其与Q-Learning算法非常相似,唯一不同之处就是更新Q值的计算公式不同。


算法三:DQN(Deep Q-Network)
深度强化学习 DQN (Pytorch实战)
深度强化学习 DQN (理论)
开山之作:2013年 David Silver等提出DQN,将神经网略和Q-learning结合。2015年再次优化。
深度强化学习面临的挑战:
- (挑战一)DL需要大量带标签的样本进行监督学习,而RL只需要Reward,不需要标签值。
- (挑战二)DL样本独立,而RL前后的State状态相关。
- (挑战三)DL目标分布固定,而RL分布时刻变化。
- (挑战四)使用神经网络的非线性函数表示值函数时,容易出现不稳定等问题。
解决方法:
- (1)通过Q-Learning使用Reward来构造标签。(对应挑战一)
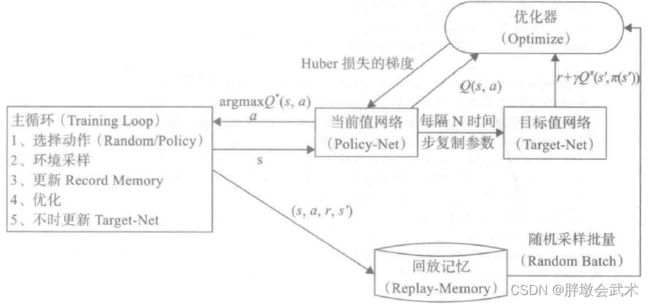
- (2)通过经验回访机制来解决样本独立及目标分布固定问题。(对应挑战二、三)
- (3)使用一个CNN(Policy-Net)产生当前Q值,使用另外一个CNN(Target-Net)产生Target Q值。(对应挑战四)
(1)定义损失函数
- 问题:参数学习通过损失函数的反向求导来实现,而构造损失函数需要预测值与目标值。如何定义预测值与目标值?
- 方法:通过神经网络的梯度下降法,计算L(θ)关于θ的梯度,不断更新求取最小值。

(2)经验回访机制(Experience Replay)
- 作用:解决相关性及非静态分布问题。
- 具体过程:
(1)把每个时间步Agent与Env交互得到的样本数据存储在回访记忆单元中(Replay Memory),每个样本是一个四元组【s(t),a(t),r(t+1),s(t+1)】。
(2)当训练时,通过经验回访机制对存储下来的样本进行随机采样(mini batch),并更新网络参数。- 优点:在一定程度上能够去除样本之间的相关性,从而更容易收敛。
(3)目标网络(Target-Net)
- 背景:2015年,DeepMind 在 Nature 上提出了目标网络,并产生目标Q值(Target Q)。
具体过程:
(1)Q(s,a;θi):当前网络MainNet的输出,用来评估当前状态动作对的值函数;
(2)Q(s,a;θi−):TargetNet的输出,代入上面求Target Q 公式中得到目标Q值。
(3)根据上面的Loss Function更新MainNet的参数;每经过N轮迭代,将 MainNet 的参数复制给TargetNet。
(4)DQN网络模型
- 备注:强化学习的数据特征比较简单,故无需池化处理,直接跟上前连接层即可。

(5)DQN算法(伪代码)

(一)实战:基于Q-Learning算法的强化学习
链接:https://pan.baidu.com/s/1d0HY1MD2qCJKPdIWzAuNDg?pwd=2n2u
提取码:2n2u

import time
import numpy as np
import tkinter as tk
from PIL import ImageTk, Image
import random
from collections import defaultdict
########################################################
# (1)参数初始化
np.random.seed(1) # 固定随机初始化参数
PhotoImage = ImageTk.PhotoImage # 图像实例化
UNIT = 100 # 一个state的图形化显示大小(需和图像大小同时更改)
HEIGHT = 5 # 界面显示的高度
WIDTH = 5 # 界面显示的宽度
########################################################
# (2)定义Q-Learning主函数
class Env(tk.Tk):
"""环境实例化"""
def __init__(self):
super(Env, self).__init__()
self.action_space = ['u', 'd', 'l', 'r'] # 上下左右
self.n_actions = len(self.action_space)
self.title('Q Learning')
self.geometry('{0}x{1}'.format(HEIGHT * UNIT, HEIGHT * UNIT))
self.shapes = self.load_images() # 加载图像
self.canvas = self._build_canvas() # 搭建图形化界面
self.texts = []
def _build_canvas(self):
"""搭建图形化界面"""
canvas = tk.Canvas(self, bg='white', height=HEIGHT * UNIT, width=WIDTH * UNIT)
# 创建网格
for c in range(0, WIDTH * UNIT, UNIT): # 网格的宽度
x0, y0, x1, y1 = c, 0, c, HEIGHT * UNIT
canvas.create_line(x0, y0, x1, y1)
for r in range(0, HEIGHT * UNIT, UNIT): # 网格的高度
x0, y0, x1, y1 = 0, r, HEIGHT * UNIT, r
canvas.create_line(x0, y0, x1, y1)
# 把图标加载到环境的对应位置中
self.rectangle = canvas.create_image(50, 50, image=self.shapes[0])
self.tree1 = canvas.create_image(250, 150, image=self.shapes[1])
self.tree2 = canvas.create_image(150, 250, image=self.shapes[1])
self.star = canvas.create_image(250, 250, image=self.shapes[2])
canvas.pack() # 对环境进行打包封装
return canvas
def load_images(self):
"""加载图像"""
rectangle = PhotoImage(
Image.open("img/bob.png").resize((65, 65)))
tree = PhotoImage(
Image.open("img/tree.png").resize((65, 65)))
star = PhotoImage(
Image.open("img/star.jpg").resize((65, 65)))
return rectangle, tree, star
def text_value(self, row, col, contents, action, font='Helvetica', size=10, style='normal', anchor="nw"):
"""更新当前动作对应的图像位置"""
if action == 0:
origin_x, origin_y = 7, 42
elif action == 1:
origin_x, origin_y = 85, 42
elif action == 2:
origin_x, origin_y = 42, 5
else:
origin_x, origin_y = 42, 77
x, y = origin_y + (UNIT * col), origin_x + (UNIT * row)
font = (font, str(size), style)
text = self.canvas.create_text(x, y, fill="black", text=contents, font=font, anchor=anchor)
return self.texts.append(text)
def print_value_all(self, q_table):
"""打印所有状态对应动作的奖励值"""
for i in self.texts:
self.canvas.delete(i)
self.texts.clear()
# 循环遍历所有状态对应的动作,并计算奖励值
for i in range(HEIGHT):
for j in range(WIDTH):
for action in range(0, 4): # 上下左右四个动作
state = [i, j]
if str(state) in q_table.keys():
temp = q_table[str(state)][action] # Q(s,a)
self.text_value(j, i, round(temp, 2), action)
def coords_to_state(self, coords):
"""坐标到状态的图像大小转换"""
x = int((coords[0] - 50) / 100)
y = int((coords[1] - 50) / 100)
return [x, y]
def state_to_coords(self, state):
"""状态到坐标的图像大小转换"""
x = int(state[0] * 100 + 50)
y = int(state[1] * 100 + 50)
return [x, y]
def reset(self):
"""重置按钮"""
self.update()
time.sleep(0.5)
x, y = self.canvas.coords(self.rectangle)
self.canvas.move(self.rectangle, UNIT / 2 - x, UNIT / 2 - y)
self.render() # 渲染环境
return self.coords_to_state(self.canvas.coords(self.rectangle))
def step(self, action):
"""计算当前动作的下一个状态的奖励值"""
state = self.canvas.coords(self.rectangle)
base_action = np.array([0, 0])
self.render() # 渲染环境
if action == 0: # up
if state[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if state[1] < (HEIGHT - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # left
if state[0] > UNIT:
base_action[0] -= UNIT
elif action == 3: # right
if state[0] < (WIDTH - 1) * UNIT:
base_action[0] += UNIT
self.canvas.move(self.rectangle, base_action[0], base_action[1])
self.canvas.tag_raise(self.rectangle)
next_state = self.canvas.coords(self.rectangle)
# 判断得分条件
if next_state == self.canvas.coords(self.star):
reward = 100
done = True # 游戏继续
elif next_state in [self.canvas.coords(self.tree1), self.canvas.coords(self.tree2)]:
reward = -100
done = True # 游戏继续
else:
reward = 0
done = False # 游戏结束
next_state = self.coords_to_state(next_state)
return next_state, reward, done
def render(self):
"""渲染环境"""
time.sleep(0.03)
self.update()
########################################################
# (3)执行Q-Learning:参数初始化 - 更新Q表 - 获取动作 - NMS
class QLearningAgent:
"""主体Q表学习"""
def __init__(self, actions):
self.actions = actions # 四种动作分别用序列表示:[0, 1, 2, 3]
self.learning_rate = 0.01 # 学习率
self.discount_factor = 0.9
self.epsilon = 0.1 # 贪婪策略参数
self.q_table = defaultdict(lambda: [0.0, 0.0, 0.0, 0.0])
def learn(self, state, action, reward, next_state):
"""更新Q表"""
current_q = self.q_table[state][action] # 获取当前状态采取动作的奖励值
new_q = reward + self.discount_factor * max(self.q_table[next_state]) # 下一个状态对应的最大奖励值
self.q_table[state][action] += self.learning_rate * (new_q - current_q) # 更新Q表(公式)
def get_action(self, state):
"""获取动作"""
if np.random.rand() < self.epsilon: # 贪婪策略随机探索动作
action = np.random.choice(self.actions)
else:
state_action = self.q_table[state] # 提取Q表中所有状态对应的动作
action = self.arg_max(state_action) # 采取最大奖励对应的动作
return action
@staticmethod
def arg_max(state_action):
"""最大奖励"""
max_index_list = [] # 最大值对应的索引
max_value = state_action[0] # 最大值初始化
for index, value in enumerate(state_action):
if value > max_value: # 只找到一个最大值:清空列表,并保存奖励值和索引
max_index_list.clear()
max_value = value
max_index_list.append(index)
elif value == max_value: # 有多个最大值,保存索引
max_index_list.append(index)
return random.choice(max_index_list) # 随机返回一个最大值的索引
########################################################
if __name__ == '__main__':
env = Env() # 环境实例化
agent = QLearningAgent(actions=list(range(env.n_actions))) # 主体实例化
# 共进行 200 次游戏
for Episode in range(200):
state = env.reset() # 环境重置
while True:
env.render() # 渲染环境
action = agent.get_action(str(state)) # Agent获取动作
next_state, reward, done = env.step(action) # 计算当前动作的下一个状态的奖励值
agent.learn(str(state), action, reward, str(next_state)) # 更新Q表
state = next_state # 更新动作
env.print_value_all(agent.q_table) # 在界面上,显示当前四个状态的奖励值
if done: # 判断当前游戏是否结束
break
(二)实战:基于SARSA算法的强化学习
链接:https://pan.baidu.com/s/1d0HY1MD2qCJKPdIWzAuNDg?pwd=2n2u
提取码:2n2u

import time
import numpy as np
import tkinter as tk
from PIL import ImageTk, Image
import random
from collections import defaultdict
######################################################
np.random.seed(1)
PhotoImage = ImageTk.PhotoImage
UNIT = 100
HEIGHT = 5
WIDTH = 5
class Env(tk.Tk):
def __init__(self):
super(Env, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.title('SARSA')
self.geometry('{0}x{1}'.format(HEIGHT * UNIT, HEIGHT * UNIT))
self.shapes = self.load_images()
self.canvas = self._build_canvas()
self.texts = []
def _build_canvas(self):
canvas = tk.Canvas(self, bg='white', height=HEIGHT * UNIT, width=WIDTH * UNIT)
for c in range(0, WIDTH * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, HEIGHT * UNIT
canvas.create_line(x0, y0, x1, y1)
for r in range(0, HEIGHT * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, HEIGHT * UNIT, r
canvas.create_line(x0, y0, x1, y1)
self.rectangle = canvas.create_image(50, 50, image=self.shapes[0])
self.tree1 = canvas.create_image(250, 150, image=self.shapes[1])
self.tree2 = canvas.create_image(150, 250, image=self.shapes[1])
self.star = canvas.create_image(250, 250, image=self.shapes[2])
canvas.pack()
return canvas
def load_images(self):
rectangle = PhotoImage(Image.open("img/bob.png").resize((65, 65)))
tree = PhotoImage(Image.open("img/tree.png").resize((65, 65)))
star = PhotoImage(Image.open("img/star.jpg").resize((65, 65)))
return rectangle, tree, star
def text_value(self, row, col, contents, action, font='Helvetica', size=10, style='normal', anchor="nw"):
if action == 0:
origin_x, origin_y = 7, 42
elif action == 1:
origin_x, origin_y = 85, 42
elif action == 2:
origin_x, origin_y = 42, 5
else:
origin_x, origin_y = 42, 77
x, y = origin_y + (UNIT * col), origin_x + (UNIT * row)
font = (font, str(size), style)
text = self.canvas.create_text(x, y, fill="black", text=contents, font=font, anchor=anchor)
return self.texts.append(text)
def print_value_all(self, q_table):
for i in self.texts:
self.canvas.delete(i)
self.texts.clear()
for i in range(HEIGHT):
for j in range(WIDTH):
for action in range(0, 4):
state = [i, j]
if str(state) in q_table.keys():
temp = q_table[str(state)][action]
self.text_value(j, i, round(temp, 2), action)
def coords_to_state(self, coords):
x = int((coords[0] - 50) / 100)
y = int((coords[1] - 50) / 100)
return [x, y]
def state_to_coords(self, state):
x = int(state[0] * 100 + 50)
y = int(state[1] * 100 + 50)
return [x, y]
def reset(self):
self.update()
time.sleep(0.5)
x, y = self.canvas.coords(self.rectangle)
self.canvas.move(self.rectangle, UNIT / 2 - x, UNIT / 2 - y)
self.render()
return self.coords_to_state(self.canvas.coords(self.rectangle))
def step(self, action):
state = self.canvas.coords(self.rectangle)
base_action = np.array([0, 0])
self.render()
if action == 0: # up
if state[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if state[1] < (HEIGHT - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # left
if state[0] > UNIT:
base_action[0] -= UNIT
elif action == 3: # right
if state[0] < (WIDTH - 1) * UNIT:
base_action[0] += UNIT
self.canvas.move(self.rectangle, base_action[0], base_action[1])
self.canvas.tag_raise(self.rectangle)
next_state = self.canvas.coords(self.rectangle)
if next_state == self.canvas.coords(self.star):
reward = 100
done = True
elif next_state in [self.canvas.coords(self.tree1), self.canvas.coords(self.tree2)]:
reward = -100
done = True
else:
reward = 0
done = False
next_state = self.coords_to_state(next_state)
return next_state, reward, done
def render(self):
time.sleep(0.03)
self.update()
######################################################
class QLearningAgent:
def __init__(self, actions):
self.actions = actions
self.learning_rate = 0.01
self.discount_factor = 0.9
self.epsilon = 0.1
self.q_table = defaultdict(lambda: [0.0, 0.0, 0.0, 0.0])
def learn(self, state, action, reward,next_action,next_state):
"""与Q-Learning不同之处"""
current_q = self.q_table[state][action]
new_q = reward + self.discount_factor * (self.q_table[next_state][next_action])
self.q_table[state][action] += self.learning_rate * (new_q - current_q)
def get_action(self, state):
if np.random.rand() < self.epsilon:
action = np.random.choice(self.actions)
else:
state_action = self.q_table[state]
action = self.arg_max(state_action)
return action
@staticmethod
def arg_max(state_action):
max_index_list = []
max_value = state_action[0]
for index, value in enumerate(state_action):
if value > max_value:
max_index_list.clear()
max_value = value
max_index_list.append(index)
elif value == max_value:
max_index_list.append(index)
return random.choice(max_index_list)
######################################################
if __name__ == '__main__':
env = Env()
agent = QLearningAgent(actions=list(range(env.n_actions)))
for episode in range(200):
state = env.reset()
action = agent.get_action(str(state))
while True:
env.render()
next_action = agent.get_action(str(state))
next_state, reward, done = env.step(action)
agent.learn(str(state), action, reward, next_action, str(next_state))
state = next_state
action = next_action # 与Q-Learning不同之处
env.print_value_all(agent.q_table)
if done:
break
(三)实战:基于DQN算法的深度强化学习
强化学习笔记:Gym入门–从安装到第一个完整的代码示例
openAI开发的python第三方库gym,是一个现阶段主流的强化学习入门的环境。可以为强化学习算法提供许多游戏或者控制场景的接口,让开发者更多关注在算法的研究上而不是环境的设计。
gym安装(pip install gym)。若安装失败就多试几次。

DQN(Deep Q Network)及其代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import gym
###################################################################################
# 定义Net类 (定义网络)
class Net(nn.Module):
def __init__(self): # 定义Net的一系列属性
# nn.Module的子类函数必须在构造函数中执行父类的构造函数
super(Net, self).__init__() # 等价与nn.Module.__init__()
self.fc1 = nn.Linear(N_STATES, 50) # 设置第一个全连接层(输入层到隐藏层): 状态数个神经元到50个神经元
self.fc1.weight.data.normal_(0, 0.1) # 权重初始化 (均值为0,方差为0.1的正态分布)
self.out = nn.Linear(50, N_ACTIONS) # 设置第二个全连接层(隐藏层到输出层): 50个神经元到动作数个神经元
self.out.weight.data.normal_(0, 0.1) # 权重初始化 (均值为0,方差为0.1的正态分布)
def forward(self, x): # 定义forward函数 (x为状态)
x = F.relu(self.fc1(x)) # 连接输入层到隐藏层,且使用激励函数ReLU来处理经过隐藏层后的值
actions_value = self.out(x) # 连接隐藏层到输出层,获得最终的输出值 (即动作值)
return actions_value # 返回动作值
# 定义DQN类 (定义两个网络)
class DQN(object):
def __init__(self): # 定义DQN的一系列属性
self.eval_net, self.target_net = Net(), Net() # 利用Net创建两个神经网络: 评估网络和目标网络
self.learn_step_counter = 0 # for target updating
self.memory_counter = 0 # for storing memory
self.memory = np.zeros((MEMORY_CAPACITY, N_STATES * 2 + 2)) # 初始化记忆库,一行代表一个transition
self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=LR) # 使用Adam优化器 (输入为评估网络的参数和学习率)
self.loss_func = nn.MSELoss() # 使用均方损失函数 (loss(xi, yi)=(xi-yi)^2)
def choose_action(self, x): # 定义动作选择函数 (x为状态)
x = torch.unsqueeze(torch.FloatTensor(x), 0) # 将x转换成32-bit floating point形式,并在dim=0增加维数为1的维度
if np.random.uniform() < EPSILON: # 生成一个在[0, 1)内的随机数,如果小于EPSILON,选择最优动作
actions_value = self.eval_net.forward(x) # 通过对评估网络输入状态x,前向传播获得动作值
action = torch.max(actions_value, 1)[1].data.numpy() # 输出每一行最大值的索引,并转化为numpy ndarray形式
action = action[0] # 输出action的第一个数
else: # 随机选择动作
action = np.random.randint(0, N_ACTIONS) # 这里action随机等于0或1 (N_ACTIONS = 2)
return action # 返回选择的动作 (0或1)
def store_transition(self, s, a, r, s_): # 定义记忆存储函数 (这里输入为一个transition)
transition = np.hstack((s, [a, r], s_)) # 在水平方向上拼接数组
# 如果记忆库满了,便覆盖旧的数据
index = self.memory_counter % MEMORY_CAPACITY # 获取transition要置入的行数
self.memory[index, :] = transition # 置入transition
self.memory_counter += 1 # memory_counter自加1
def learn(self): # 定义学习函数(记忆库已满后便开始学习)
# 目标网络参数更新
if self.learn_step_counter % TARGET_REPLACE_ITER == 0: # 一开始触发,然后每100步触发
self.target_net.load_state_dict(self.eval_net.state_dict()) # 将评估网络的参数赋给目标网络
self.learn_step_counter += 1 # 学习步数自加1
# 抽取记忆库中的批数据
sample_index = np.random.choice(MEMORY_CAPACITY, BATCH_SIZE) # 在[0, 2000)内随机抽取32个数,可能会重复
b_memory = self.memory[sample_index, :] # 抽取32个索引对应的32个transition,存入b_memory
b_s = torch.FloatTensor(b_memory[:, :N_STATES])
# 将32个s抽出,转为32-bit floating point形式,并存储到b_s中,b_s为32行4列
b_a = torch.LongTensor(b_memory[:, N_STATES:N_STATES+1].astype(int))
# 将32个a抽出,转为64-bit integer (signed)形式,并存储到b_a中 (之所以为LongTensor类型,是为了方便后面torch.gather的使用),b_a为32行1列
b_r = torch.FloatTensor(b_memory[:, N_STATES+1:N_STATES+2])
# 将32个r抽出,转为32-bit floating point形式,并存储到b_s中,b_r为32行1列
b_s_ = torch.FloatTensor(b_memory[:, -N_STATES:])
# 将32个s_抽出,转为32-bit floating point形式,并存储到b_s中,b_s_为32行4列
# 获取32个transition的评估值和目标值,并利用损失函数和优化器进行评估网络参数更新
q_eval = self.eval_net(b_s).gather(1, b_a)
# eval_net(b_s)通过评估网络输出32行每个b_s对应的一系列动作值,然后.gather(1, b_a)代表对每行对应索引b_a的Q值提取进行聚合
q_next = self.target_net(b_s_).detach()
# q_next不进行反向传递误差,所以detach;q_next表示通过目标网络输出32行每个b_s_对应的一系列动作值
q_target = b_r + GAMMA * q_next.max(1)[0].view(BATCH_SIZE, 1)
# q_next.max(1)[0]表示只返回每一行的最大值,不返回索引(长度为32的一维张量);.view()表示把前面所得到的一维张量变成(BATCH_SIZE, 1)的形状;最终通过公式得到目标值
loss = self.loss_func(q_eval, q_target)
# 输入32个评估值和32个目标值,使用均方损失函数
self.optimizer.zero_grad() # 清空上一步的残余更新参数值
loss.backward() # 误差反向传播, 计算参数更新值
self.optimizer.step() # 更新评估网络的所有参数
###################################################################################
# 超参数
BATCH_SIZE = 32 # 样本数量
LR = 0.01 # 学习率
EPSILON = 0.9 # greedy policy
GAMMA = 0.9 # reward discount
TARGET_REPLACE_ITER = 100 # 目标网络更新频率
MEMORY_CAPACITY = 2000 # 记忆库容量
env = gym.make('CartPole-v0').unwrapped # 使用gym库中的环境:CartPole,且打开封装
N_ACTIONS = env.action_space.n # 杆子动作个数 (2个)
N_STATES = env.observation_space.shape[0] # 杆子状态个数 (4个)
###################################################################################
dqn = DQN() # 令dqn=DQN类
for i in range(400): # 400个episode循环
print('<<<<<<<< % i)
s = env.reset() # 重置环境
episode_reward_sum = 0 # 初始化该循环对应的episode的总奖励
while True: # 开始一个episode (每一个循环代表一步)
env.render() # 显示实验动画
a = dqn.choose_action(s) # 输入该步对应的状态s,选择动作
s_, r, done, info = env.step(a) # 执行动作,获得反馈
# 修改奖励 (不修改也可以,修改奖励只是为了更快地得到训练好的摆杆)
x, x_dot, theta, theta_dot = s_
r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8
r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5
new_r = r1 + r2
dqn.store_transition(s, a, new_r, s_) # 存储样本
episode_reward_sum += new_r # 逐步加上一个episode内每个step的reward
s = s_ # 更新状态
if dqn.memory_counter > MEMORY_CAPACITY: # 如果累计的transition数量超过了记忆库的固定容量2000
# 开始学习 (抽取记忆,即32个transition,并对评估网络参数进行更新,并在开始学习后每隔100次将评估网络的参数赋给目标网络)
dqn.learn()
if done: # 如果done为True
# round()方法返回episode_reward_sum的小数点四舍五入到2个数字
print('episode%s---reward_sum: %s' % (i, round(episode_reward_sum, 2)))
break # 该episode结束
env.close()