深度学习在NLP中的应用---技巧与资源
首先来看下NLP包含有哪些应用。
• 语言建模 (语音识别,机器翻译)
• 问答系统
语言建模主要包含
根据前面一个词,预测下一个词出现的概率,即 P(next word | previous word)
预测一个长句子出现的概率
用于语音,翻译以及压缩
这里会遇到一个问题,即计算上的瓶颈,大词汇量V就意味着计算输出的代价为隐含节点数跟词汇量的乘积,即 #hidden units x |V|。
一篇比较经典的论文出自蒙特利尔Bengio等人,Bengio et al NIPS’2000
and JMLR 2003 “A Neural Probabilistic Language Model”。其中,每个单词都是由一个基于分布的连续取值编码得到,也可以泛化到跟训练序列语义相似的词序列。
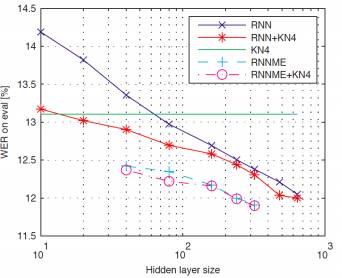
循环神经网络语言建模可以用于自动语音识别(ASR)[Mikolov et al 2011]。模型结构越大效果会更好一些。实验数据集是 Broadcast News NIST-RT04。杂乱度或称混乱度从 140 降到了 102。 这篇论文给出了几天之内利用单核训练一个循环神经网络,其中WER(word error rate)有了大于1%的绝对提升。代码见http://www.fit.vutbr.cz/~imikolov/rnnlm/
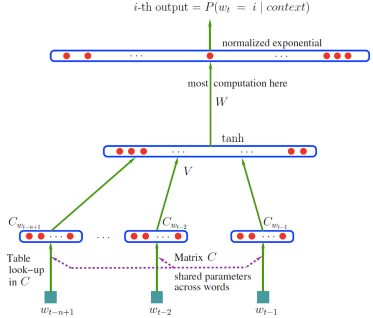
下图是WER随隐含层节点数的变化图。
模型结构示意图如下。

深度学习也可以用于统计机器翻译,比如 NAACL 2012 workshop on the future of LM中,数据集信息如下:
41M 单词,Arabic/English bitexts + 151M 来自LDC的英文。
混乱度从 71.1 降到了 56.9 (500M 内存)。这种方法可以利用长上下文的优势, 代码见:http://lium.univ-lemans.fr/cslm/
深度学习也可以用于学习多个词向量。这类方法主要用来处理多义词的情形。可以利用基于标准的tf-idf的方法来学习多个向量 [Reisinger and Mooney, NAACL 2010]。[Huang et al. ACL 2012]中的神经词向量模型可以利用局部及全局上下文学习多个原型。
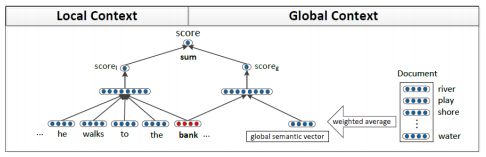
可视化结果如下:

深度学习可以基于知识库推理常识。
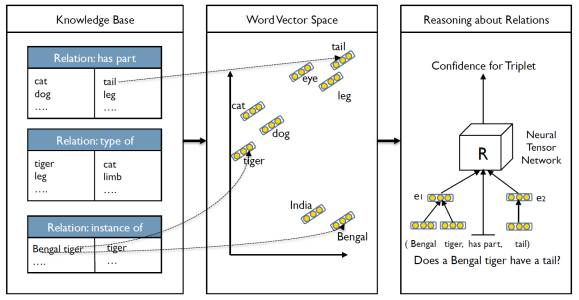
每个三元组T= (e1,R,e2)如果具有较高的打分,则表示实体之间具有的关系越强。训练过程可以类似于词向量学习,利用对比估计函数来训练。
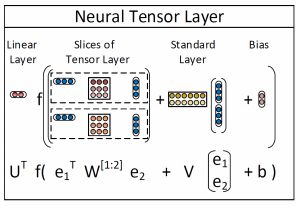
其中打分函数如下:
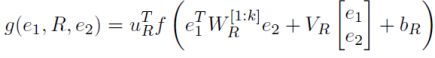
代价函数如下:

示例如下:
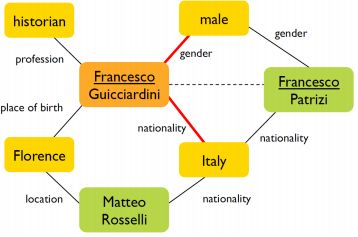
下面是实验结果
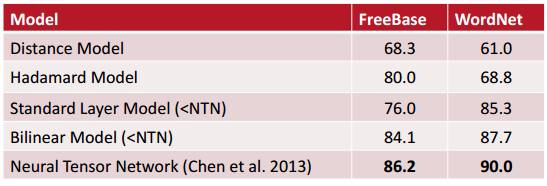

相关工作有 Bordes, Weston, Collobert & Bengio, AAAI 2011和 Bordes, Glorot, Weston & Bengio,AISTATS 2012。
下面总体上来看下通用的策略或技巧。
1. 选择适当的网络结构
结构上:单个词,固定窗口, 递归句子式,词袋
非线性结构
2. 借助梯度检查来检查执行中的bug
3. 参数初始化
4. 优化技巧
5. 模型表达能力是否够强,防止过拟合
如果表达能力不够强,改变模型结构或者增大模型结构
如果过拟合,则需要正则化方法
首先来看下非线性变换。下面是两种常用的非线性变换。
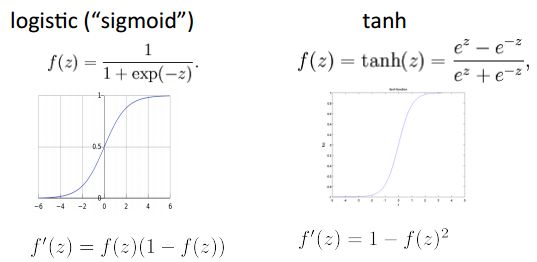
其中二者之间的关系如下:
tanh 是对sigmoid 的重缩放与偏移,tanh(z) = 2logistic(2z)−1,另外 tanh 在深度网络中最常用,并且经常表现出最好的效果。除了这两种方法还有其他一些非线性变换方法。

其中 hard tanh跟tanh相似,相对tanh计算复杂度低,但是比较难饱和。
饱和解释见:
http://stats.stackexchange.com/questions/283/what-is-a-saturated-model
[Glorot and Bengio AISTATS 2010, 2011] 讨论了softsign函数和rectifier函数。
除了以上变换函数,还有一种比较新的变换函数,maxout network。这种方法由 Goodfellow et al. (2013) 提出
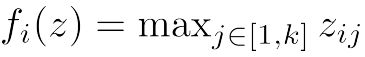
其中

这个函数也是一种通用逼近算子,具体参见
https://en.wikipedia.org/wiki/Universal_approximation_theorem
另外,这种函数在很多图像数据集上取得了不错的效果。
下面来看下梯度检查。执行梯度检查对检查神经网络是否有bug很有帮助。具体步骤如下:
1. 计算网络中的梯度
2. 利用网络中的参数,通过加减一个比较小的数(~10^-4),计算有限的差分计算,并且对导数进行估计 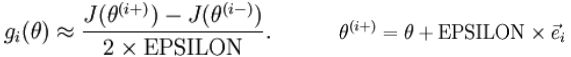
3. 比较两个梯度,确保它们相同
参数初始化
隐含层偏置初始化为0,如果权值为0,则输出(或重构)偏差初始化为最优值(比如目标值取均值或者目标值取均值后所对应sigmoid函数的逆函数)。权值初始化为服从均匀分布的形式,~ Uniform(-r,r),其中r跟fan-in (前一层节点数)和 fan-out (后一层节点数)成反比
对于 tanh 单元,权值是sigmoid单元的4倍 [Glorot AISTATS 2010]
另外, 可以利用限制性玻尔兹曼机预训练 (Restricted Boltzmann machines)。
随机梯度下降
梯度下降每次更新参数都会利用利用所有样本的总梯度,而随机梯度下降每次更新只利用一个或很少的样本:
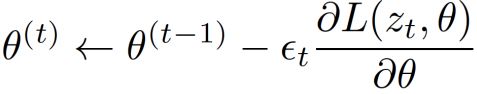
其中L是损失函数,zt 是当前样本,θ是参数向量,εt 是学习率。一般的梯度下降方法是一种批处理的方法,速度非常慢,不建议使用。可以利用二阶批处理方法,比如 LBFGS。在大数据集上,SGD 通常优于所有批处理方法。在相对较小的数据集上,LBFGS 或者共轭梯度法效果比较好。大批 LBFGS 是对LBFGS的一种扩展 [Le et al ICML’2011]。
学习率
最简单的方案是固定学习率,对所有参数利用相同的学习率。Collobert 利用每个神经元输入单元个数平方根的反比来缩放学习率。学习过程中,逐渐减小学习率通常可以取得较好的效果,缩减率通常是 O(1/t),因为有理论上有收敛的保证,
![]()
et al. 2011) ,这类方法不需要学习率。
长段依赖及裁剪技巧
对于非常深的神经网络,比如循环神经网路或者递归神经网络,梯度是雅克比矩阵的乘积,每一个梯度都跟前向计算的步骤相关联。这种梯度可能很快就变得很小或很大 [Bengio et al 1994],并且对于梯度下降的局部性假设不再有效。
Mikolov首次提出了一种解决方案,对RNNs效果很好。
防止过拟合:模型大小及正则化
首先,可以使用较少的单元数,层数,以及其他参数来缩减模型规模。也可以利用标准的 L1 和 L2 正则化方法对权值加以约束。还可以利用提前终止法,这种方法需要借助于在验证集合上的误差,可以得到验证集合上误差最佳时对应的参数。另外, 也可以对隐含层的激活加以稀疏的约束,比如损失函数中加入:

另外一种是鼻祖Hinton et al.等学者提出的 Dropout (Hinton et al. 2012),这种方法随机将每层的50%置为0。测试阶段,将权值连接数减半,可以防止协同适应。
再来看下Bengio给出的几点建议。来自 Y. Bengio (2012), “Practical Recommendations for Gradient Based Training of Deep Architectures”。主要包含了
• 无监督预训练
• 快速搜索适当的超参数
一些tutorial
• “Neural Net Language Models” Scholarpedia 词条
• Deep Learning tutorials: http://deeplearning.net/tutorials
• Stanford deep learning tutorials with simple programming assignments and
reading list http://deeplearning.stanford.edu/wiki/
• Recursive Autoencoder class project
http://cseweb.ucsd.edu/~elkan/250B/learningmeaning.pdf
• Graduate Summer School: Deep Learning, Feature Learning
http://www.ipam.ucla.edu/programs/gss2012/
• ICML 2012 Representation Learning tutorial
http://www.iro.umontreal.ca/~bengioy/talks/deep-learning-tutorial-2012.html
• More reading (including tutorial references):
http://nlp.stanford.edu/courses/NAACL2013/
一些软件
• Theano (Python CPU/GPU) mathematical and deep learning library http://deeplearning.net/software/theano
最后来看一些值得关注和待讨论的点。
未来会出现更多的算法及变形,这是快速发展的领域。
超参数,比如单元数,正则化,学习率等,利用多核机器,多集群,交叉验证中随机采样 (Bergstra & Bengio 2012)。一些比较常用的方法,比如 BM25, LDA 等。可以利用小批的 L-BFGS 代替 SGD。
目前来看,如何跟现有 NLP 结合还不太明朗。
• 简单结合:讲单词或短语作为特征,NER [Turian et al, ACL 2010]
• 跟已知问题的结构集成,递归和循环网络用于树和链条。
相对线性模型训练速度较慢
• 只借助一个常数因子,并且比非参方法更加紧致的方法,比如 n-gram 模型
• 推理或测试阶段速度较快,前向传播只涉及到一些矩阵乘积。
需要更多的训练数据
• 可以处理更多的训练数据,并且可以从中获益,适用于大数据 (Google 训练了具有十亿级别连接的网络模型 [Le et al, ICML 2012])
当前没有比较好的方式可以将语言结构中的先验知识融入深度学习模型中。虽然如此,但是
• 目标是让机器来学习
模型的可解释性
没有离散的类别或单词,都是连续的向量。希望得到一些符号特征,比如 NP,VP 等,并且探索它们之间的结合为何有意义。
• 可以利用权值和近邻法投影
非凸优化法
可以利用凸的学习方法来初始化系统
实际中,并不是一个大问题,通常借助于不同的局部最优解,性能会相对稳定
深度学习在NLP中的优势有哪些呢?
• 尽管深度学习跟NLP交叉较小,现在深度学习在很多语言任务中取得了最好的效果
• 通常,训练过程中的后向传播只需要简单的矩阵梯度,测试阶段需要矩阵乘积可以加速计算过程
• 借助多核 CPUs/GPUs 可以快速推理,并且可以基于多台机器并行计算
可以学习多层抽象特征。
深度学习的一个优势在于可以学习高层的特征表示和高层次抽象,这可以使得泛化能力更强,也有助于跨领域,跨语言,跨任务迁移。

参考资料
http://nlp.stanford.edu/courses/NAACL2013/NAACL2013-Socher-Manning-DeepLearning.pdf