Spark Machine Learning(SparkML):机器学习(部分一)
机器学习是现阶段实现人工智能应用的主要方法,它广泛应用于机器视觉、语音识别、自然语言处理、数据挖掘等领域。
MLlib是Apache Spark的可伸缩机器学习库。官网地址:[http://spark.apache.org/docs/latest/ml-guide.html]
Spark的机器学习(ML)库提供了许多分布式ML算法。这些算法包括特征选取、分类、回归、聚类、推荐等任务。ML还提供了用于构建工作流的ML管道、用于调优参数的交叉验证器以及用于保存和加载模型的模型持久性等工具。
其目标是使实用的机器学习可扩展且简单。
- ML算法:常见的学习算法,如分类、回归、聚类和协同过滤
- 特征化:特征提取、转换、降维和选择
- 管道:用于构建、评估和调整ML管道的工具
- 持久性:保存和加载算法,模型和管道
- 实用:线性代数、统计、数据处理等。
有监督学习与无监督学习:
有监督学习即对每一个自变量x都有一个因变量y与之对应(使用标记的训练数据学习输入变量(X )到输出变量(Y)的映射函数),我们希望通过拟合预测模型,更好理解预测变量与响应变量之间的关系,例如分析个人信用信息评价信用风险,企业营销费用投入与销量的关系等等。有监督学习的样本数据带有标签值,它从训练样本中学习得到一个模型,然后用该模型对新的样本进行预测推断。
按照标签值类型,可以将有监督学习算法分为分类问题和回归问题。
按照求解的方法,可以将分类算法(有监督学习)分为生成模型和判别模型。
而对于无监督学习,则只有自变量x,而没有输出变量y。例如我们能够获得零售企业当中每个会员的行为信息,我们可能希望通过无监督学习的方法(聚类)把会员划分为不同的客户细分群体(粉丝客户群,注重性价比客户群)。
对于有监督学习,响应变量属于定量变量(即连续性变量,如GDP,企业年销售额)的话,我们把它定义为回归问题,而响应变量属于定性变量的话(即分类型变量,如违约客户与不违约客户,患病与不患病),我们定义为分类问题。
1.SparkML概叙
“ Spark ML”不是官方名称,但有时用于指代基于MLlib DataFrame的API。这主要是由于org.apache.spark.ml基于DataFrame的API使用了Scala软件包名称,以及我们最初用来强调管道概念的“ Spark ML Pipelines”一词。
1.1特性:
(1).容易使用:可在Java、Scala、Python和R中使用。
MLlib适合Spark的api,并在Python (Spark 0.9)和R库(Spark 1.5)中与NumPy互操作。你可以使用任何Hadoop数据源(例如HDFS、HBase或本地文件),使插入Hadoop工作流变得很容易。
(2).性能好
高质量的算法,比MapReduce快100倍。
Spark擅长迭代计算,使MLlib能够快速运行。与此同时,MLlib包含利用迭代的高质量算法,比MapReduce中有时使用的单遍近似产生更好的结果。
(3).可以运行在各种环境中
Spark运行在Hadoop、Apache Mesos、Kubernetes、独立的或在云中,针对不同的数据源。可以在EC2、Hadoop YARN、Mesos或Kubernetes上使用Spark的独立集群模式运行Spark。访问HDFS、Apache Cassandra、Apache HBase、Apache Hive和其他数百个数据源中的数据。
1.2 ML算法包括:
生成与判别、参数与非参数、监督与非监督等等.
- 分类:逻辑回归,朴素贝叶斯,决策树,K近邻,......
- 回归:线性回归,广义线性回归,生存回归,等渗回归,......
- 决策树,随机森林和梯度提升树
- 协同过滤(推荐系统):交替最小二乘法(ALS)
- 聚类:K均值,高斯混合(GMM),......
- 主题建模:潜在Dirichlet分配(LDA)
- 频繁项目集,关联规则和顺序模式挖掘
1.3 ML工作流程工具包括:
- 特征转换:标准化,规范化,散列,......
- ML管道施工
- 模型评估和超参数调优
- ML持久性:保存和加载模型和管道
1.4其他工具包括:
- 分布式线性代数:SVD(奇异值分解),PCA(主成分分析),......
- 统计:汇总统计,假设检验,......
1.5基于DataFrame的API是主要API
基于MLlib RDD的API现在处于维护模式。
从Spark 2.0开始,软件包中基于RDD的API spark.mllib已进入维护模式。Spark的主要机器学习API现在是包中基于DataFrame的API spark.ml。
- MLlib仍将
spark.mllib通过错误修复支持基于RDD的API。 - MLlib不会为基于RDD的API添加新功能。
- 在Spark 2.x版本中,MLlib将为基于DataFrames的API添加功能,以实现与基于RDD的API的功能奇偶校验。
- MLlib同时包含基于RDD的API和基于DataFrame的API。基于RDD的API现在处于维护模式。但是既不弃用API,也不弃用MLlib。。
为什么MLlib切换到基于DataFrame的API?
- 与RDD相比,DataFrames提供了更加用户友好的API。DataFrames的许多好处包括Spark数据源,SQL / DataFrame查询,Tungsten和Catalyst优化以及跨语言的统一API。
- 用于MLlib的基于DataFrame的API为ML算法和多种语言提供了统一的API。
- DataFrame有助于实际的ML管道,特别是功能转换。有关详细信息,请参见管道指南。
示例:在这个例子中,我们取一个标签和特征向量的数据集。我们学习使用逻辑回归算法从特征向量预测标签。
org.apache.spark
spark-mllib_2.11
2.3.0
Scala代码:
// 每个记录这个DataFrame包含标签和功能由一个向量表示
val df = sqlContext.createDataFrame(data).toDF("label", "features")
val lr = new LogisticRegression().setMaxIter(10) // 为算法设置参数
val model = lr.fit(df) // 将模型与数据相匹配
val weights = model.weights // 检查模型:功能权重
model.transform(df).show() // 给定一个数据集,预测每个点的标签,并显示结果Java代码:
// 每个记录这个DataFrame包含标签和功能由一个向量表示.
StructType schema = new StructType(new StructField[]{
new StructField("label", DataTypes.DoubleType, false, Metadata.empty()),
new StructField("features", new VectorUDT(), false, Metadata.empty()),});
DataFrame df = jsql.createDataFrame(data, schema);
// 为算法设置参数. 我们将迭代次数限制为10次.
LogisticRegression lr = new LogisticRegression().setMaxIter(10);
LogisticRegressionModel model = lr.fit(df);
Vector weights = model.weights(); // 检查模型:功能权重.
model.transform(df).show(); // 给定一个数据集,预测每个点的标签,并显示结果.Python代码:
# 每个记录这个DataFrame包含标签和功能由一个向量表示.
df = sqlContext.createDataFrame(data, ["label", "features"])
lr = LogisticRegression(maxIter=10) # 为算法设置参数. 我们将迭代次数限制为10次.
model = lr.fit(df)
model.transform(df).show() # 给定一个数据集,预测每个点的标签,并显示结果.Vector(向量)
sealed trait Vector extends Serializable
表示一个数值向量,其索引类型为Int,值类型为Double。
向量是一组有序数字的数学表示.它与集合类似,但是各数是有序的.其中的数均为实数.n维向量在几何上表示为n维空间中的一个点.向量的起点(原点)从零开始.
Spark MLlib/ML使用Breeze和jblas来处理底层线性代数运算.它自定义了Vector经工厂模式来创建和表示向量.本地向量的索引为从0开始递增的整数,其中各值以双精度表示.本地向量存储在各个节点中,且不能分发到其他节点.目前支持密集型(dense)和稀疏型(sparse)两种本地向量。
在机器学习中,特征用n维向量表示。
Vectors
org.apache.spark.ml.linalg.Vector的工厂方法。我们不使用Vector这个名称,因为Scala默认导入scala.collection.immutable.Vector。
Matrices(矩阵)
org.apache.spark.ml.linalg.Matrix的工厂方法。
Spark中的本地矩阵的行列索引为整数,而元素值为双精度(Double)类型.所有值均存储在单个节点上.支持密集矩阵和稀疏矩阵.在实际的机器学习任务中,如人脸识别或文字识别、医学成像、主成分分析和数值精度等,矩阵作为数学对象来表示图像和数据集.
2.基本统计(Basic Statistics)
2.1关联(Correlation)
计算两个数据系列之间的相关性是统计学中的常见操作。在spark.ml 中,我们提供了灵活计算多个系列之间的两两相关性。目前Spark支持两种相关性系数:皮尔逊相关系数(pearson)和斯皮尔曼等级相关系数(spearman)。相关系数是用以反映变量之间相关关系密切程度的统计指标。简单的来说就是相关系数绝对值越大(值越接近1或者-1),当取值为0表示不相关,取值为[-1~0)表示负相关,取值为(0, 1]表示正相关。
Pearson相关系数表达的是两个数值变量的线性相关性, 它一般适用于正态分布。其取值范围是[-1, 1], 当取值为0表示不相关,取值为[-1~0)表示负相关,取值为(0, 1]表示正相关。
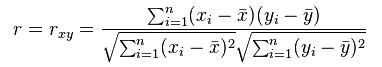
Spearman相关系数也用来表达两个变量的相关性,但是它没有Pearson相关系数对变量的分布要求那么严格,另外Spearman相关系数可以更好地用于测度变量的排序关系。其计算公式为:
![]()
根据输入类型的不同,输出的结果也产生相应的变化。如果输入的是两个Double类型的RDD或DataFrame,则输出的是一个double类型的结果;如果输入的是一个Vector向量类型的RDD或DataFrame,则对应的输出的是一个相关系数矩阵。
Correlation 使用指定的方法计算输入数据集的相关矩阵。
输出将是一个DataFrame,它包含向量列的相关矩阵。
Scala代码:
import org.apache.spark.ml.linalg.{Matrix, Vectors}
import org.apache.spark.ml.stat.Correlation
import org.apache.spark.sql.Row
val spark = SparkSession.builder.appName(this.getClass.getSimpleName).getOrCreate()
spark.sparkContext.setLogLevel("WARN")
import spark.implicits._
val data = Seq(
Vectors.sparse(4, Seq((0,1.0),(3,-2.0)) ),
Vectors.dense(4.0, 5.0, 0.0, 3.0),
Vectors.dense(6.0, 7.0, 0.0, 8.0),
Vectors.sparse(4, Seq((0,9.0),(3,1.0)) )
)
val df = data.map(Tuple1.apply).toDF("features")
val Row(coeff1: Matrix) = Correlation.corr(df, "features").head
println(s"Pearson correlation matrix:\n $coeff1")
val Row(coeff2: Matrix) = Correlation.corr(df, "features","spearman").head
println(s"Spearman correlation matrix:\n $coeff2")
Spark.stop()Java代码:
import java.util.Arrays;
import java.util.List;
import org.apache.spark.ml.linalg.Vectors;
import org.apache.spark.ml.linalg.VectorUDT;
import org.apache.spark.ml.stat.Correlation;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.types.*;
List data = Arrays.asList(
RowFactory.create(Vectors.sparse(4, new int[]{0, 3}, new double[]{1.0, -2.0})),
RowFactory.create(Vectors.dense(4.0, 5.0, 0.0, 3.0)),
RowFactory.create(Vectors.dense(6.0, 7.0, 0.0, 8.0)),
RowFactory.create(Vectors.sparse(4, new int[]{0, 3}, new double[]{9.0, 1.0}))
);
StructType schema = new StructType(new StructField[]{
new StructField("features", new VectorUDT(), false, Metadata.empty()),
});
Dataset df = spark.createDataFrame(data, schema);
Row r1 = Correlation.corr(df, "features").head();
System.out.println("Pearson correlation matrix:\n" + r1.get(0).toString());
Row r2 = Correlation.corr(df, "features", "spearman").head();
System.out.println("Spearman correlation matrix:\n" + r2.get(0).toString());
2.2假设检验(Hypothesis testing)
假设检验是统计学中一种强有力的工具,用于确定结果是否具有统计显着性,无论该结果是否偶然发生。ML目前支持Pearson的Chi-squared( χ2)独立测试。
卡方检验(ChiSquareTest)对标签的每个功能进行Pearson独立测试。对于每个特征,(特征,标签)被转换为应急矩阵,对其计算卡方统计量。所有标签和特征值必须是分类的。通常,预处理之后获得的特征有成千上万维,出于去除冗余特征、消除维数灾难、提高模型质量的考虑,需要进行选择。在此,使用卡方检验方法,利用特征与类标签之间的相关性,进行特征选取:
val chiSqSelector = new ChiSqSelector()
.setFeaturesCol("vectorFeature")
.setLabelCol("label")
.setNumTopFeatures(10)
.setOutputCol("selectedFeature");示例:Scala代码:
import org.apache.spark.ml.linalg.{Vector, Vectors}
import org.apache.spark.ml.stat.ChiSquareTest
val spark = SparkSession.builder.master("local").appName(this.getClass.getSimpleName).getOrCreate()
import spark.implicits._
val data = Seq(
(0.0, Vectors.dense(0.5, 10.0)),(0.0, Vectors.dense(1.5, 20.0)),
(1.0, Vectors.dense(1.5, 30.0)),(0.0, Vectors.dense(3.5, 30.0)),
(0.0, Vectors.dense(3.5, 40.0)),(1.0, Vectors.dense(3.5, 40.0))
)
val df = data.toDF("label", "features")
val chi = ChiSquareTest.test(df, "features", "label").head
println(s"pValues = ${chi.getAs[Vector](0)}")
println(s"degreesOfFreedom ${chi.getSeq[Int](1).mkString("[", ",", "]")}")
println(s"statistics ${chi.getAs[Vector](2)}")运行结果:

Java代码:
import java.util.Arrays;
import java.util.List;
import org.apache.spark.ml.linalg.Vectors;
import org.apache.spark.ml.linalg.VectorUDT;
import org.apache.spark.ml.stat.ChiSquareTest;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.types.*;
List data = Arrays.asList(
RowFactory.create(0.0, Vectors.dense(0.5, 10.0)),
RowFactory.create(0.0, Vectors.dense(1.5, 20.0)),
RowFactory.create(1.0, Vectors.dense(1.5, 30.0)),
RowFactory.create(0.0, Vectors.dense(3.5, 30.0)),
RowFactory.create(0.0, Vectors.dense(3.5, 40.0)),
RowFactory.create(1.0, Vectors.dense(3.5, 40.0))
);
StructType schema = new StructType(new StructField[]{
new StructField("label", DataTypes.DoubleType, false, Metadata.empty()),
new StructField("features", new VectorUDT(), false, Metadata.empty()),}
);
Dataset df = spark.createDataFrame(data, schema);
Row r = ChiSquareTest.test(df, "features", "label").head();
System.out.println("pValues: " + r.get(0).toString());
System.out.println("degreesOfFreedom: " + r.getList(1).toString());
System.out.println("statistics: " + r.get(2).toString());
2.3摘要统计(Summarizer)
(@Since Spark2.3.0)
我们通过Summarizer为Dataframe提供矢量列汇总统计。可用指标是列的最大值、最小值、平均值、方差、非零数以及总计数。
Summarizer用于对MLlib向量进行矢量化统计的工具。这个类允许用户选择他们想为给定列提取的统计信息。这个包中的方法提供了包含在数据流中的向量的各种统计信息。
以下示例演示如何使用Summarizer 计算输入数据框的矢量列的均值和方差,包括和不包含权重列。
Scala代码:
import org.apache.spark.ml.linalg.{Vector, Vectors}
import org.apache.spark.ml.stat.Summarizer
val data2 = Seq(
(Vectors.dense(2.0, 3.0, 5.0), 1.0),
(Vectors.dense(4.0, 6.0, 7.0), 2.0)
)
val df2 = data2.toDF("features", "weight")
val (meanVal, varianceVal) = df2.select(Summarizer.metrics("mean", "variance")
.summary($"features", $"weight").as("summa"))
.select("summa.mean", "summa.variance").as[(Vector, Vector)]
.first()
println(s"with weight: mean = ${meanVal}, variance = ${varianceVal}")
val (meanVal2, varianceVal2) = df2.select(Summarizer.mean($"features"), Summarizer.variance($"features")).as[(Vector, Vector)].first()
println(s"without weight: mean = ${meanVal2}, sum = ${varianceVal2}")运行结果:
![]()
Java代码:
import java.util.Arrays;
import java.util.List;
import org.apache.spark.ml.linalg.Vector;
import org.apache.spark.ml.linalg.Vectors;
import org.apache.spark.ml.linalg.VectorUDT;
import org.apache.spark.ml.stat.Summarizer;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.Metadata;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
List data = Arrays.asList(
RowFactory.create(Vectors.dense(2.0, 3.0, 5.0), 1.0),
RowFactory.create(Vectors.dense(4.0, 6.0, 7.0), 2.0));
StructType schema = new StructType(new StructField[]{
new StructField("features", new VectorUDT(), false, Metadata.empty()),
new StructField("weight", DataTypes.DoubleType, false, Metadata.empty())}
);
Dataset df = spark.createDataFrame(data, schema);
Row result1 = df.select(Summarizer.metrics("mean", "variance")
.summary(new Column("features"), new Column("weight")).as("summa"))
.select("summa.mean", "summa.variance").first();
System.out.println("with weight: mean = " + result1.getAs(0).toString() +", variance = " + result1.getAs(1).toString());
Row result2 = df.select(
Summarizer.mean(new Column("features")),
Summarizer.variance(new Column("features"))).first();
System.out.println("without weight: mean = " + result2.getAs(0).toString() + ", variance = " + result2.getAs(1).toString());
注意:目前,该接口的性能比使用RDD接口慢2 ~3倍。
def metrics(metrics: String*): SummaryBuilder
给定一个度量列表,提供一个构建器,它将从列中计算度量。接受下列指标(区分大小写):
mean:包含系数均值的向量;返回值类型:vector。
variance:包含系数方差的向量;返回值类型:vector。
count:看到的所有向量的计数;返回值类型:long。
numNonzeros:每个系数的非零个数的向量;返回值类型:vector.
max:每个系数的最大值;返回值类型:vector。
min:每个系数的最小值;返回值类型:vector。
normL2:每个系数的欧几里德范数;返回值类型:vector。
normL1:各系数的L1范数(绝对值之和);返回值类型:vector。http://spark.apache.org/docs/latest/api/java/org/apache/spark/ml/stat/Summarizer.html
3.数据源(Data sources)
数据分类:
1.传统企业数据:包括CRM系统的消费者数据、传统的ERP数据、库存数据及账目数据等.
2.机器和传感器数据:包括呼叫记录、智能仪表、工业设备传感器、设备日志、交易数据等.
3.社交数据:包括用户行为记录、反馈数据等.
可用于测试的公开数据集:
- UCI机器学习知识库: http://archive.ics.uci.edu/ml/index.php
- Amazon AWS公开数据集: https://registry.opendata.aws/
- Kaggel学习竞赛所用数据集: https://www.kaggle.com/datasets
- KDnuggets: https://www.kdnuggets.com/datasets/index.html
除了一些常规数据源,如Parquet,CSV,JSON和JDBC,ML还提供了一些特定的数据源:图像数据源。
图像数据源
该图像数据源用于从目录加载图像文件,它可以通过ImageIOJava库将压缩图像(jpeg,png等)加载到原始图像表示中。加载的DataFrame有一StructType列:“image”,包含存储为图像模式的图像数据。该image列的架构是:
- origin :( StringType表示图像的文件路径)
- height:( IntegerType图像的高度)
- width:( IntegerType图像的宽度)
- nChannels :( IntegerType图像频道数)
- mode:( IntegerTypeOpenCV兼容型)
- data :( BinaryTypeOpenCV兼容顺序的图像字节:大多数情况下的行式BGR)
Scala代码:
val df = spark.read.format("image")
.option("dropInvalid", true)
.load("data/mllib/images/origin/kittens")
df.select("image.origin", "image.width", "image.height").show(truncate=false)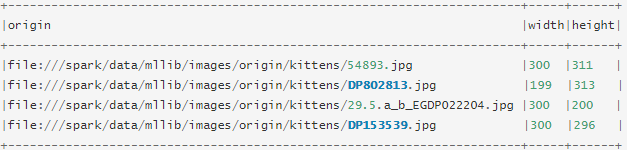
LIBSVM数据源这个LIBSVM数据源用于从一个目录加载“LIBSVM”类型的文件。加载的DataFrame有两列:label(包含存储为双精度的标签)和feature(包含存储为vector的特征向量)。列的模式是:
·label: DoubleType(表示实例标签)
·feature:VectorUDT(表示特征向量)Scala代码:
val df = spark.read.format("libsvm")
.option("numFeatures", "780")
.load("data/mllib/sample_libsvm_data.txt")
df.show(10)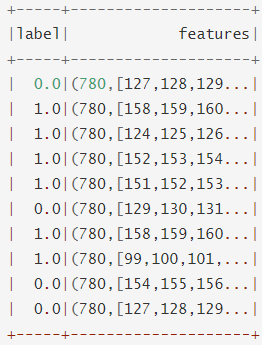
3.1 Spark ML的数据类型
本地向量(Local Vector)
首先建立一个向量(1.0,0.0,3.0),采用3种方式:
import org.apache.spark.mllib.linalg.{Vector, Vectors}
// 创建稠密矩阵
val dv: Vector = Vectors.dense(1.0, 0.0, 3.0)
// 基于索引(0,2)和值(1,3)创建稀疏向量
val sv1: Vector = Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0))
// 基于序列方式(0,1)(2,3.0)
val sv2: Vector = Vectors.sparse(3, Seq((0, 1.0), (2, 3.0)))标记点(LabeledPoint)
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.ml.regression.LabeledPoint
//通过稠密向量创建标记点
val pos = LabeledPoint(1.0, Vectors.dense(1.0, 0.0, 3.0))
println(pos.features)
println(pos.label)
//通过稀疏向量创建
val neg = LabeledPoint(0.0, Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0)))
//libSVM的数据格式(稀疏)
Label 1:value 2:value
-15 1:0.708 3:-0.3333 (标签为-15 -> 向量为(1,0,3) )
表明第2个特征值为0,从编程的角度来说,这样做可以减少内存的使用,并提高做矩阵内积时的运算速度。
import org.apache.spark.ml.regression.LabeledPoint
import org.apache.spark.ml.util.MLUtils
val examples= MLUtils.loadLibSVMFile(sc, "/sample_libsvm_data.txt")
examples.foreach(println)本地矩阵
import org.apache.spark.ml.linalg.{Matrix, Matrices}
val dm: Matrix = Matrices.dense(3, 2, Array(1.0, 3.0, 5.0, 2.0, 4.0, 6.0))
//注意:稀疏本地矩阵暗藏玄机:
val sm: Matrix =Matrices.sparse(
4,4,Array(0,1,5,6,7),Array(0,0,1,2,3,3,3),Array(9,6,8,5,1,7,10)
)3.2数据预处理:清洗与转换
大部分机器学习模型所处理的都是特征(feature).特征通常是输入变量所对应的可用于模型的数值表示.绝大部分情况下,这些原始数据都需要经过预处理才能为模型所使用.预处理的情况可能包括如下几种:
(1).数据过滤
(2).处理数据丢失、不完整或有缺陷
(3).处理可能的异常、错误和异常值
(4).合并多个数据源
(5).数据汇总
处理方法:
1.过滤掉或删除非规整或有值缺失的数据;
2.填充非规整或缺失的数据:可以根据其他的数据来填充.方法包括用零值、全局平均值或中值来填充,或是根据相邻或类似的数据点来做插值(通常针对时序数据)等.
3.对异常值做稳健处理:可被移除或填充,但存在某些统计技术(如稳健回归)可用于处理异常值或极值.
4.对可能的异常值进行转换:对那些可能存在异常值或值域覆盖过大的特征,进行对数或高斯核转换.这类转换有助于降低变量存在值跳跃的影响,并将非线性关系变为线性的.
根据数据质量的不同,数据预处理所用的技术也会有所不同,但通常会包括数据清洗、数据集成、数据规约和数据变换四个步骤,这4个步骤的效果如下图所示:
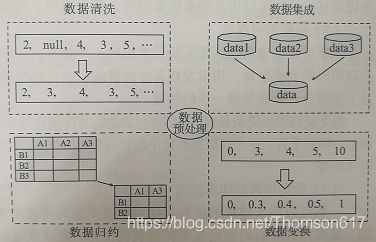
4.特征提取、转换与选择
特征(feature)指那些用于模型训练的变量。
- 提取:从“原始”数据中提取特征
- 转换:缩放,转换或修改功能
- 选择:从全部特征中选取一个特征子集,使构造出来的模型更好.
- 局部敏感哈希(LSH):这类算法将特征变换的各个方面与其他算法相结合。
特征/指标选取的原则:
(1).指标可量化:能够用数字类型表示;
(2).尽可能全面:根据底层数据尽可能多地选择可以获取的指标,这样能够从多角度进行分析和评价;
(3).线性独立:即指标间尽量保持不相关.比如:如果选择用户的购买次数和消费总额,那么一定是购买次数越多的用户总消费额越高,也就是导致了评价维度上的重合,而选择购买次数和平均每次交易额可以避免这种相关性产生的弊端.
特征向量化:
只有把原始特征转化为特征向量,才能用于机器学习模型的训练。常用特征主要有以下几种:
数值特征:主要针对数值类型。
类别特征:类别特征是可穷举的值。类别特征不能直接使用,一般需要对特征进行编号,将其转化为数值特征。
文本特征:从文本中提取出来的特征,如:电影评论。注意文本特征也不能直接使用,需要进行分词,编码等处理。
统计特征: 从原始数据中使用统计方法得到的高级特征,常用的统计特征包括:平均值、中位数、求和、最大值、最小值。
主成分分析(PCA)
主成分分析(Principal Component Analysis,PCA)是将多个变量通过线性变换(对数据进行旋转变换)以选出少数重要变量的一种多元统计分析方法,其本质是在线性空间中进行一个基变换,使得变换后的数据投影在一组新的“坐标轴”上的方差最大化,随后,裁剪掉变换后方差很小的“坐标轴”,剩下的新“坐标轴”即被称为主成分(Principal Component) ,它们可以在一个较低维度的子空间中尽可能地表示原有数据的性质。主成分分析被广泛应用在各种统计学、机器学习问题中,是最常见的降维和去除相关性方法之一。PCA有许多具体的实现方法,可以通过计算协方差矩阵,甚至是通过SVD(奇异值)分解来进行PCA变换。
在数据处理中,经常会遇到特征维度比样本数量多得多的情况,如果拿到实际工程中去跑,效果不一定好。一是因为冗余的特征会带来一些噪音,影响计算的结果;二是因为无关的特征会加大计算量,耗费时间和资源。所以我们通常会对数据重新变换一下,再跑模型。数据变换的目的不仅仅是降维,还可以消除特征之间的相关性,并发现一些潜在的特征变量。
PCA的目的:
PCA是一种在尽可能减少信息损失的情况下找到某种方式降低数据的维度的方法。通常来说,我们期望得到的结果是把原始数据的特征空间(n个d维样本)投影到一个小一点的子空间里去,并尽可能表达的很好(就是说损失信息最少)。常见的应用在于模式识别中,我们可以通过减少特征空间的维度,抽取子空间的数据来最好的表达我们的数据,从而减少参数估计的误差。注意,主成分分析通常会得到协方差矩阵和相关矩阵。这些矩阵可以通过原始数据计算出来。协方差矩阵包含平方和与向量积的和。相关矩阵与协方差矩阵类似,但是第一个变量,也就是第一列,是标准化后的数据。如果变量之间的方差很大,或者变量的量纲不统一,我们必须先标准化再进行主成分分析。
PCA的过程(通常来说有以下六步):
1.去掉数据的类别特征(label),将去掉后的d维数据作为样本
2.计算d维的均值向量(即所有数据的每一维向量的均值)
3.计算所有数据的散布矩阵(或者协方差矩阵)
4.计算特征值(e1,e2,...,ed)以及相应的特征向量(lambda1,lambda2,...,lambda d)
5.按照特征值的大小对特征向量降序排序,选择前k个最大的特征向量,组成d*k维的矩阵W(其中每一列代表一个特征向量)
6.运用d*K的特征向量矩阵W将样本数据变换成新的子空间。(用数学式子表达就是,其中x是d*1维的向量,代表一个样本,y是K*1维的在新的子空间里的向量)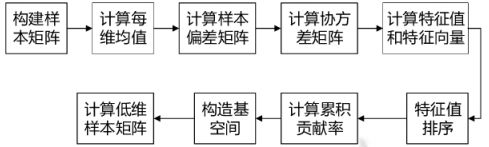
代码示例:
val spark = SparkSession.builder().master("local").appName("test").getOrCreate()
val data = spark.read.option("header", true).option("multiLine", true).csv("E:\\aa.csv")
val schema = data.schema.map(f => s"${f.name}").drop(1)
//val data2 = data.na.fill(0.0) //去null值并进行替换
//ML的VectorAssembler是一个transformer,要求数据类型不能是string,将多列数据转化为单列的向量列,比如把后六字段列合并成一个 userFea 向量列,方便后续训练
val assembler = new VectorAssembler().setInputCols(schema.toArray).setOutputCol("userFea")
val userProfile = assembler.transform(data).select("c_id", "userFea")
// 创建PCA模型,降维
val pca = new PCA().setInputCol("userFea").setOutputCol("pcaFeatures")
.setK(5).fit(userProfile )
// transform数据,生成主成分特征
val pcaResult = pca.transform(userProfile ).select("c_id", "pcaFeatures").toDF("label", "features")
//经过降维的数据就可以拿来训练分类器了,但是在此之前要将数据划分为训练集和测试集,分类器只能在训练集上进行训练,在测试集上验证其分类精度。
// Spark提供了很方便的接口,按给定的比例随机划分训练/测试集。
val Array(trainingData, testData) = pcaResult.randomSplit(Array(0.7, 0.3), seed = 20)
......示例二:
import org.apache.spark.ml.feature.PCA
import org.apache.spark.ml.linalg.Vectors
val data = Array(
Vectors.sparse(5, Seq((1, 1.0), (3, 7.0))),
Vectors.dense(2.0, 0.0, 3.0, 4.0, 5.0),
Vectors.dense(4.0, 0.0, 0.0, 6.0, 7.0)
)
val df = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features")
val pca = new PCA()
.setInputCol("features")
.setOutputCol("pcaFeatures")
.setK(3)
.fit(df)
val result = pca.transform(df).select("pcaFeatures")
result.show(false)
数据归一化处理
对数据进行初步预处理后,往往需要将其转换为一种适合机器学习模型的表示形式。对许多模型类型来说,这种表示就是包含数字数据的向量或矩阵。
org.apache.spark.ml.feature包中包含了4种不同的归一化方法:
Normalizer、StandardScaler、MinMaxScaler、MaxAbsScaler
数据准备
import org.apache.spark.ml.linalg.Vectors
val dataFrame = spark.createDataFrame(Seq(
(0, Vectors.dense(1.0, 0.5, -1.0)),
(1, Vectors.dense(2.0, 1.0, 1.0)),
(2, Vectors.dense(4.0, 10.0, 2.0))
)).toDF("id", "features")
dataFrame.show// 原始数据

1.Normalizer
Normalizer(规范化)将某个特征向量(由所有样本某一个特征组成的向量)计算其p-范数,然后对该每个元素除以p-范数,使每一个行向量的范数变换为一个单位范数,作用范围是每一行。将原始特征Normalizer以后可以使得机器学习算法有更好的表现。单位P-范数定义如下:
![]()
当p取1,2,∞的时候分别是以下几种最简单的情形:

其中2-范数就是通常意义下的距离。
下面的示例代码都来自spark官方文档加上少量改写和注释。
// 将每一行的规整为1阶范数为1的向量,1阶范数即所有值绝对值之和。

// 正则化每个向量到无穷阶范数
val lInfNormData = normalizer.transform(dataFrame, normalizer.p -> Double.PositiveInfinity)
println("Normalized using L^inf norm")
lInfNormData.show()// 向量的无穷阶范数即向量中所有值中的最大值

2.StandardScaler
StandardScaler(z−score规范化,又叫零均值规范化或标准差规范化)处理的对象是每一列,也就是每一维特征,将特征标准化为单位标准差或是0均值,或是0均值单位标准差。使数据均值为0,方差为1。

主要有两个参数可以设置:
- withStd: 默认为真。将数据标准化到单位标准差(即将方差缩放到1)。
- withMean: 默认为假。是否变换为0均值。(对于稀疏输入矩阵不可以用)
StandardScaler需要fit数据,获取每一维的均值和方差,然后对所有训练数据的该属性均减去该平均值(可选)后再除以方差,来缩放每一维特征。
import org.apache.spark.ml.feature.StandardScaler
val scaler = new StandardScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
.setWithStd(true)
.setWithMean(false)
// 通过拟合标准定标器计算汇总统计信息
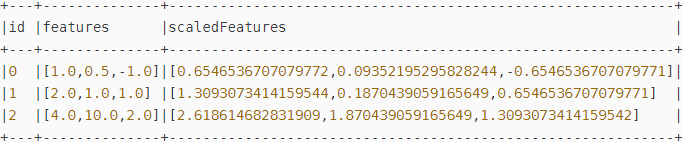
val scalerModel = scaler.fit(dataFrame)
// 将每个特征标准化,使其具有单位标准差。.
val scaledData = scalerModel.transform(dataFrame)
scaledData.show// 将每一列的标准差缩放到1:
注意:尤其是离群点左右了MinMaxScaler规范化,需要使用StandardScaler。
3.MinMaxScaler
MinMaxScaler(线性函数归一化,也称最大-最小规范化或离差标准化)作用同样是每一列,即每一维特征。将每一维特征线性地映射到指定的区间,通常是[0, 1]。归一化公式如下:
![]()
该方法实现对原始数据的等比例缩放,其中Xnorm为归一化后的数据,X为原始数据,Xmax、Xmin分别为原始数据集的最大值和最小值。
它也有两个参数可以设置:
- min: 默认为0。指定区间的下限。
- max: 默认为1。指定区间的上限。
import org.apache.spark.ml.feature.MinMaxScaler
val scaler = new MinMaxScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
.setMax(100.0).setMin(-100.0) //将数据线性变换到[-100,100]
// 计算汇总统计信息并生成MinMaxScalerModel
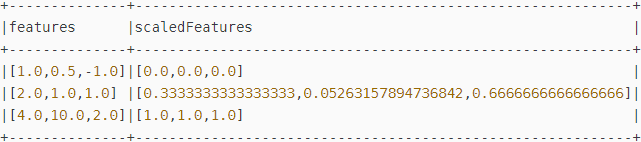
val scalerModel = scaler.fit(dataFrame)
// 将每个特征缩放到区间范围[min, max].
val scaledData = scalerModel.transform(dataFrame)
println(s"Features scaled to range: [${scaler.getMin}, ${scaler.getMax}]")
scaledData.select("features", "scaledFeatures").show// 每维特征线性地映射,最小值映射到0,最大值映射到1:
注意:(1)最大最小值可能受到离群值的左右。(2)零值可能会转换成一个非零值,因此稀疏矩阵将变成一个稠密矩阵。
4.MaxAbsScaler
MaxAbsScaler将每一维的特征变换到[-1, 1]闭区间上,通过除以每一维特征上的最大的绝对值,它不会平移整个分布,也不会破坏原来每一个特征向量的稀疏性。
import org.apache.spark.ml.feature.MaxAbsScaler
val scaler = new MaxAbsScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
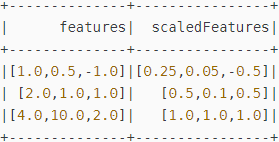
// 计算汇总统计信息并生成MaxAbsScalerModel
val scalerModel = scaler.fit(dataFrame)
// 将每个特征缩放到范围[-1, 1]
val scaledData = scalerModel.transform(dataFrame)
scaledData.select("features", "scaledFeatures").show()// 每一维的绝对值的最大值为[4, 10, 2]
所有4种归一化方法都是线性的变换,当某一维特征上具有非线性的分布时,还需要配合其它的特征预处理方法。
StringIndexer(字符串-索引变换)
StringIndexer(字符串-索引变换)将字符串的(以单词为)标签编码成标签索引(表示)。标签索引序列的取值范围是[0,numLabels(字符串中所有出现的单词去掉重复的词后的总和)],按照标签出现频率排序,出现最多的标签索引为0。如果输入是数值型,我们先将数值映射到字符串,再对字符串进行索引化。
主要作用:提高决策树或随机森林等ML方法的分类效果。
如果下游的pipeline(例如:Estimator或者Transformer)需要用到索引化后的标签序列,则需要将这个pipeline的输入列名字指定为索引化序列的名字。大部分情况下,通过setInputCol设置输入的列名。
Parameters
此算法可以接受的(超)参数键列表。用户可以分别通过setter和getter设置和获取参数值。
handleInvalid: Param[String] 用于处理无效数据(不可见的标签或空值)。选项有“skip”(过滤掉含有无效数据的行)、“error”(抛出错误)或“keep”(将无效数据放在索引号标签处的一个特殊的附加桶中)。默认值:“error”。
inputCol: Param[String] 输入列名的参数。
outputCol: Param[String] 输出列名的参数。
stringOrderType: Param[String]
示例:标签类别(category)有3种取值标签:”a”,”b”,”c”,如下所示:

使用StringIndexer将category转换成categoryIndex后可以得到如下结果:
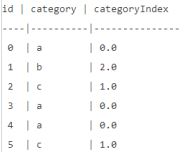
注意:StringIndexer本质上是对String类型–>index( number);如果是:数值(numeric)–>index(number),实际上是对把数值先进行了类型转换。
IndexToString(索引-字符串变换)
与StringIndexer对应,IndexToString将索引化标签还原成原始字符串。一个常用的场景是先通过StringIndexer产生索引化标签,然后使用索引化标签进行训练,最后再对预测结果使用IndexToString来获取其原始的标签字符串。
val converter : IndexToString =new IndexToString()
.setInputCol("prediction") //Spark默认预测label行
.setOutputCol("convetedPrediction") //转换回来的预测label
.setLabels(labelIndexer.labels()) //需要指定前面建好相互相互模型
val pipeline : Pipeline=new Pipeline()
.setStages(Array(labelIndexer,featureIndexer,dtClassifier,Converter))
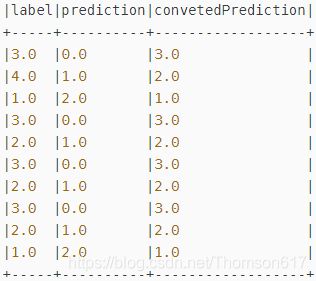
pipeline.fit(rawData).transform(rawData)
.select("label","prediction","convetedPrediction").show(20,false)// 结果:
VectorIndexer(向量索引化)
VectorIndexer是对数据集特征向量中的类别特征进行编号索引。它能够自动判断那些特征是可以重新编号的类别,并对他们进行重新编号索引,具体做法如下:
1.获得一个向量类型的输入以及maxCategories参数。
2.基于原始向量数值识别哪些特征需要被类别化:特征向量中某一个特征不重复取值个数小于等于maxCategories则认为是可以重新编号索引的。某一个特征不重复取值个数大于maxCategories,则该特征视为连续值,不会重新编号(不会发生任何改变)
3.对于每一个可编号索引的类别特征重新编号为0~K(K<=maxCategories-1)
4.对类别特征原始值用编号后的索引替换掉。索引后的类别特征可以帮助决策树等算法处理类别型特征,提高性能。
这有两种使用模式:
1.自动识别分类特性(默认行为)
(1).这有助于将未知向量的数据集处理为具有连续特征和分类特征的数据集。连续和分类之间的选择基于maxCategories参数。
(2).将maxCategories设置为任何类别特性应有的最大类别数量。
(3).例如:Feature 0有惟一的值{-1.0,0.0},和Feature 1的值{1.0,3.0,5.0}。如果maxCategories = 2,那么feature 0将被声明为分类的,并使用索引{0,1},而feature 1将被声明为连续的。
2.索引所有特性,如果所有特性都是分类的
(1).如果maxCategories设置的非常大,那么这将为所有特性构建一个惟一值索引。
(2).警告:如果特性是连续的,这可能会导致问题,因为这会收集到驱动程序的所有惟一值。
(3.)例如:Feature 0有惟一的值{-1.0,0.0},和Feature 1的值{1.0,3.0,5.0}。如果maxCategories大于或等于3,那么这两个特性都将被声明为categorical。
这将返回一个模型,该模型可以将分类特征转换为使用基于0的索引。
Parameters
此算法可以接受的(超)参数键列表。用户可以分别通过setter和getter设置和获取参数值。
handleInvalid: Param[String] 用于处理无效数据(不可见的标签或空值)。注意:这个参数只适用于分类特性,而不适用于连续特性。选项是:'skip':过滤掉无效数据行。'error':抛出一个错误。“keep”:将无效数据放入一个特殊的附加桶中,放在特性类别数量的索引处。默认值:“error”.
inputCol: Param[String] 输入列名的参数。
maxCategories: IntParam 一个分类特征可以接受的值的阈值。如果发现某个特性具有> maxCategories值,则将其声明为连续的。必须大于等于2。(默认= 20)
outputCol: Param[String] 输出列名的参数。示例:
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.classification. LogisticRegression
import org.apache.spark.ml.feature.{IndexToString, StringIndexer, VectorIndexer}
import org.apache.spark.ml.linalg.Vectors
val labelIndexer=new StringIndexer().setInputCol("label").setOutputCol("indexedLabel").fit(data)
//在特征向量中建类别索引
val featureIndexer=new VectorIndexer().setInputCol("features").setOutputCol("indexedFeatures").fit(data)
// 随机划分训练集与测试集
val Array(trainData,testData)=df_data.randomSplit(Array(0.7,0.3))
//setFamily("multinomial"):设置为多项逻辑回归,不设置则为二项逻辑回归
val lr=new LogisticRegression()
.setLabelCol("indexedLabel")
.setFeaturesCol("indexedFeatures")
.setMaxIter(10)
.setRegParam(0.5) //设置正则化项系数
.setElasticNetParam(0.8) //设置正则化范式比
val labelConverter=new IndexToString()
.setInputCol("prediction")
.setOutputCol("predictionLabel")
.setLabels(labelIndexer.labels)
val lrPipeline=new Pipeline().setStages(Array(labelIndexer,featureIndexer,lr,labelConverter))
val lrPipeline_Model=lrPipeline.fit(trainData)
val lrPrediction=lrPipeline_Model.transform(testData)
lrPrediction.show(10,false)//显示如下的结果:
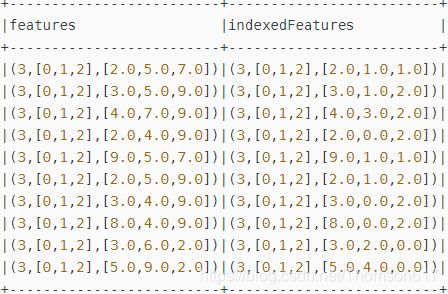
结果分析:特征向量包含3个特征,即特征0,特征1,特征2。如Row=1,对应的特征分别是2.0,5.0,7.0.被转换为2.0,1.0,1.0。我们发现只有特征1,特征2被转换了,特征0没有被转换。这是因为特征0有6中取值(2,3,4,5,8,9),多于前面的设置setMaxCategories(5),因此被视为连续值了,不会被转换。
特征1中,(4,5,6,7,9)-->(0,1,2,3,4,5)
特征2中, (2,7,9)-->(0,1,2)
VectorAssembler(特征合并)
ML的VectorAssembler是一个transformer,要求数据类型不能是string,将多列数据转化为单列的向量列.
data1.createTempView("tmp1")
// 过滤空值并转换成0.0
val data2 = data1.na.fill(0.0)
//元数据剔除非向量列
val schema = data2.schema.map(f => s"${f.name}").drop(1)
// 比如把后几字段列合并成一个userFea 向量列,方便后续训练
val assembler = new VectorAssembler().setInputCols(schema.toArray).setOutputCol("userFea")
val userProfile = assembler.transform(data2).select("cid", "userFea").toDF("cid", "features")OneHotEncoder(独热编码)
独热编码(One-hot encoding)将类别特征映射为二进制向量,其中只有一个有效值(为1,其余为0)。这样在诸如Logistic回归这样需要连续数值作为特征输入的分类器中也可以使用类别(离散)特征.
例如,对于5个类别,输入值2.0将映射到输出向量 [0.0, 0.0, 1.0, 0.0]。默认情况下不包含最后一个类别(可通过'OneHotEncoder!.dropLast'配置),因为它使得向量项之和为1,因此是线性相关的。因此输入值4.0映射到 [0.0,0.0,0.0,0.0]。
注意,这与scikit-learn的OneHotEncoder不同,后者保存所有类别。输出向量是稀疏的。不推荐的'OneHotEncoderEstimator'将被重命名为'OneHotEncoder'而这个'OneHotEncoder'将在'2.3.0','3.0.0'中移除。
TF-IDF(词频-逆文档频率)
词条频率 - 逆文档频率(TF-IDF)(Term frequency-inverse document frequency) 是在文本挖掘中广泛使用的特征向量化方法,以反映词条对语料库中的文档的重要性。
用t表示词条,用d表示文档,用D表示语料库。词频TF(t, d)是该词条出现在文档d中的次数,而文档频率DF(t, D)是包含词条t的文档的数量。如果我们仅使用词条频率来衡量重要性,则过于强调非常经常出现但很少提供有关文档的信息的词条非常容易,例如“a”,“the”和“of”。如果一个词条经常出现在语料库中,这意味着它不包含关于特定文档的特殊信息。逆文档频率是一个词条提供多少信息的数值度量:
![]()
其中|D|为语料库中的文档总数。由于使用对数,如果一个词条出现在所有文档中,它的IDF值变为0。
注意,使用平滑项来避免对语料库之外的词条除0。TF-IDF测度仅为TF与IDF的乘积: TFIDF(t,d,D)=TF(t,d)·IDF(t,D)
词条频率和文档频率的定义有几种变体。在MLlib中,我们将TF和IDF分开以使其灵活。
TF:HashingTF与CountVectorizer两个均可用于生成词频向量。
HashingTF是一个转换器,它可以将特征词组转换成给定长度的(词频)特征向量组。在文本处理中,“一组词条”可能是一包单词。 HashingTF利用散列技巧。通过应用散列函数将原始特征映射到索引(词条)。这里使用的哈希函数是MurmurHash 3。然后,基于映射的指数计算词条频率。这种方法避免了计算全局词条到索引映射的需要,这对于大型语料库来说可能是昂贵的,但是它遭受潜在的哈希冲突,其中不同的原始特征可能在散列之后变成相同的词条。为了减少冲突的可能性,我们可以增加目标要素维度,即哈希表的桶数。由于散列值的简单模数用于确定向量索引,因此建议使用2的幂作为要素维度,否则要素将不会均匀映射到向量索引上。默认要素尺寸为2的18次方(即262,144)。可选的二进制切换参数控制词条频率计数。设置为true时,所有非零频率计数都设置为1.这对于模拟二进制而非整数计数的离散概率模型特别有用。CountVectorizer将文本文档转换为词条计数向量。
IDF:(逆文档频率)是权重评估器(Estimator),用于对数据集产生相应的IDFModel(不同的词频对应不同的权重)。IDFModel对特征向量集(一般由HashingTF或CountVectorizer产生)做取对数(log)处理。直观地看,特征词出现的文档越多,权重越低(down-weights colume)。所述 IDFModel需要的特征向量(通常从创建HashingTF或CountVectorizer)和缩放每个特征。直观地,它降低了在语料库中频繁出现的特征。
注意: spark.ml不提供文本分段工具。
在下面的代码段中,我们从一组句子开始。我们将每个句子分成单词使用Tokenizer。对于每个句子(单词包),我们使用HashingTF将句子散列为特征向量。我们IDF用来重新缩放特征向量; 这通常会在使用文本作为功能时提高性能。然后我们的特征向量可以传递给学习算法。
Scala代码:
import org.apache.spark.ml.feature.{HashingTF, IDF, Tokenizer}
val sentenceData = spark.createDataFrame(Seq(
(0.0, "Hi I heard about Spark"),
(0.0, "I wish Java could use case classes"),
(1.0, "Logistic regression models are neat"))
).toDF("label", "sentence")
val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words")
val wordsData = tokenizer.transform(sentenceData)
val hashingTF = new HashingTF()
.setInputCol("words")
.setOutputCol("rawFeatures")
.setNumFeatures(20)
val featurizedData = hashingTF.transform(wordsData)
// 另外,还可以使用CountVectorizer来获得项频向量
val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
val idfModel = idf.fit(featurizedData)
val rescaledData = idfModel.transform(featurizedData)
rescaledData.select("label", "features").show()Java代码:
import java.util.Arrays;
import java.util.List;
import org.apache.spark.ml.feature.HashingTF;
import org.apache.spark.ml.feature.IDF;
import org.apache.spark.ml.feature.IDFModel;
import org.apache.spark.ml.feature.Tokenizer;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.Metadata;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
List data = Arrays.asList(
RowFactory.create(0.0, "Hi I heard about Spark"),
RowFactory.create(0.0, "I wish Java could use case classes"),
RowFactory.create(1.0, "Logistic regression models are neat")
);
StructType schema = new StructType(new StructField[]{
new StructField("label", DataTypes.DoubleType, false, Metadata.empty()),
new StructField("sentence", DataTypes.StringType, false, Metadata.empty())
});
Dataset sentenceData = spark.createDataFrame(data, schema);
Tokenizer tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words");
Dataset wordsData = tokenizer.transform(sentenceData);
int numFeatures = 20;
HashingTF hashingTF = new HashingTF()
.setInputCol("words")
.setOutputCol("rawFeatures")
.setNumFeatures(numFeatures);
Dataset featurizedData = hashingTF.transform(wordsData);
//另外,还可以使用CountVectorizer来获得项频向量
IDF idf = new IDF().setInputCol("rawFeatures").setOutputCol("features");
IDFModel idfModel = idf.fit(featurizedData);
Dataset rescaledData = idfModel.transform(featurizedData);
rescaledData.select("label", "features").show();
Word2Vec(词向量)
Word2Vec是一个获取表示文档的单词序列和训练Word2VecModel的估计量.通过词向量来表示文档语义上相似度的Estimator(模型评估器),它会训练出Word2VecModel模型。该模型将(文本的)每个单词映射到一个单独的大小固定的词向量(该文本对应的)上。Word2VecModel通过文本单词的平均数(条件概率)将每个文档转换为词向量; 此向量可以用作特征预测、文档相似度计算等。该模型将每个单词映射到一个唯一的固定大小的向量。
有关更多详细信息,请参阅Word2Vec上的MLlib用户指南:
示例:在下面的代码段中,我们从一组文档开始,每个文档都表示为一系列单词。对于每个文档,我们将其转换为特征向量。然后可以将该特征向量传递给学习算法。
Scala代码:
import org.apache.spark.ml.feature.Word2Vec
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
// 输入数据:每行是一个句子或文档中的单词包.
val documentDF = spark.createDataFrame(Seq(
"Hi I heard about Spark".split(" "),
"I wish Java could use case classes".split(" "),
"Logistic regression models are neat".split(" ")).map(Tuple1.apply)
).toDF("text")
// 学习从单词到向量的映射.
val word2Vec = new Word2Vec()
.setInputCol("text")
.setOutputCol("result")
.setVectorSize(3)
.setMinCount(0)
val model = word2Vec.fit(documentDF)
val result = model.transform(documentDF)
result.collect().foreach { case Row(text: Seq[_], features: Vector) =>
println(s"Text: [${text.mkString(", ")}] => \nVector: $features\n")
}Java代码:
import java.util.Arrays;
import java.util.List;
import org.apache.spark.ml.feature.Word2Vec;
import org.apache.spark.ml.feature.Word2VecModel;
import org.apache.spark.ml.linalg.Vector;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
List data = Arrays.asList(
RowFactory.create(Arrays.asList("Hi I heard about Spark".split(" "))),
RowFactory.create(Arrays.asList("I wish Java could use case classes".split(" "))),
RowFactory.create(Arrays.asList("Logistic regression models are neat".split(" ")))
);
StructType schema = new StructType(new StructField[]{
new StructField("text", new ArrayType(DataTypes.StringType, true),false,Metadata.empty())
});
Dataset documentDF = spark.createDataFrame(data, schema);
Word2Vec word2Vec = new Word2Vec()
.setInputCol("text")
.setOutputCol("result")
.setVectorSize(3)
.setMinCount(0);
Word2VecModel model = word2Vec.fit(documentDF);
Dataset result = model.transform(documentDF);
for (Row row : result.collectAsList()) {
List text = row.getList(0);
Vector vector = (Vector) row.get(1);
System.out.println("Text: " + text + " => \nVector: " + vector + "\n");
}
CountVectorizer(计数向量)
CountVectorizer和CountVectorizerModel旨在将一组文本文档转换为令牌计数的向量。当a-priori字典不可用时,CountVectorizer可以用作Estimator提取词汇表,并生成一个CountVectorizerModel。该模型为词汇表上的文档生成稀疏表示,然后可以将其传递给其他算法,如LDA。
在拟合过程中,CountVectorizer将选择vocabSize按语料库中的词条频率排序的顶部单词。可选参数minDF通过指定词条必须出现在文档中的最小数量(或<1)(如果<1.0)来包含在词汇表中,从而影响拟合过程。另一个可选的二进制切换参数控制输出向量。如果设置为true,则所有非零计数都设置为1.这对于模拟二进制而非整数计数的离散概率模型尤其有用。
假设我们有列如下数据帧id,并texts:
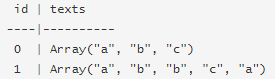
每行texts都是Array [String]类型的文档。调用拟合CountVectorizer产生CountVectorizerModel词汇(a,b,c)。然后转换后的输出列“vector”包含:

每个向量表示文档在词汇表中的令牌计数。
Scala代码:
import org.apache.spark.ml.feature.{CountVectorizer, CountVectorizerModel}
val df = spark.createDataFrame(Seq(
(0, Array("a", "b", "c")),
(1, Array("a", "b", "b", "c", "a")))
).toDF("id", "words")
// fit a CountVectorizerModel from the corpus
val cvModel: CountVectorizerModel = new CountVectorizer()
.setInputCol("words")
.setOutputCol("features")
.setVocabSize(3) //设定词汇表的最大容量为3
.setMinDF(2) //设定词汇表中的词至少要在2个文档中出现过
.fit(df)
// 或者使用a-priori词汇表定义CountVectorizerModel
val cvm = new CountVectorizerModel(Array("a", "b", "c"))
.setInputCol("words")
.setOutputCol("features")
cvModel.transform(df).show(false)Java代码:
import java.util.Arrays;
import java.util.List;
import org.apache.spark.ml.feature.CountVectorizer;
import org.apache.spark.ml.feature.CountVectorizerModel;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
List data = Arrays.asList(
RowFactory.create(Arrays.asList("a", "b", "c")),
RowFactory.create(Arrays.asList("a", "b", "b", "c", "a"))
);
StructType schema = new StructType(new StructField [] {
new StructField("text", new ArrayType(DataTypes.StringType, true), false,Metadata.empty())
});
Dataset df = spark.createDataFrame(data, schema);
//从corpus(语料库)中拟合CountVectorizerModel
CountVectorizerModel cvModel = new CountVectorizer()
.setInputCol("text")
.setOutputCol("feature")
.setVocabSize(3)
.setMinDF(2)
.fit(df);
// 或者,使用a-priori词汇表定义CountVectorizerModel
CountVectorizerModel cvm = new CountVectorizerModel(new String[]{"a", "b", "c"})
.setInputCol("text")
.setOutputCol("feature");
cvModel.transform(df).show(false);
更多详细信息,请参阅CountVectorizer Scala文档 和CountVectorizerModel Scala文档。
FeatureHasher
FeatureHasher是将一组分类或数字特征投影到指定尺寸的特征向量中(通常远小于原始特征空间的特征向量)。这是使用散列技巧 将要素映射到特征向量中的索引来完成的。该FeatureHasher变压器上多列运行。每列可能包含数字或分类功能。列数据类型的行为和处理如下:
- 数字列:对于数字要素,列名称的哈希值用于将要素值映射到要素向量中的索引。默认情况下,数字要素不被视为分类(即使它们是整数)。要将它们视为分类,请使用categoricalCols参数指定相关列。
- 字符串列:对于分类功能,字符串“column_name = value”的哈希值用于映射到矢量索引,指示符值为1.0。因此,类别特征是“一热”编码(类似于使用OneHotEncoder用 dropLast=false)。
- 布尔列:布尔值的处理方式与字符串列相同。也就是说,布尔特征表示为“column_name = true”或“column_name = false”,指示符值为1.0。
忽略空(缺失)值(在结果特征向量中隐式为零)。
这里使用的哈希函数也是HashingTF中 使用的MurmurHash 3。由于散列值的简单模数用于确定向量索引,因此建议使用2的幂作为numFeatures参数; 否则,特征将不会均匀地映射到矢量索引。
例子:假设我们有4个输入列的数据帧real,bool,stringNum,和string。这些不同的数据类型作为输入将说明变换的行为以产生一列特征向量。
real| bool|stringNum|string
----|-----|---------|------
2.2| true| 1| foo
3.3|false| 2| bar
4.4|false| 3| baz
5.5|false| 4| foo那么FeatureHasher.transform这个DataFrame 的输出是:

然后可以将得到的特征向量传递给学习算法。
Scala代码:
import org.apache.spark.ml.feature.FeatureHasher
val dataset = spark.createDataFrame(Seq(
(2.2, true, "1", "foo"),
(3.3, false, "2", "bar"),
(4.4, false, "3", "baz"),
(5.5, false, "4", "foo"))
).toDF("real", "bool", "stringNum", "string")
val hasher = new FeatureHasher()
.setInputCols("real", "bool", "stringNum", "string")
.setOutputCol("features")
val featurized = hasher.transform(dataset)
featurized.show(false)Java代码:
import java.util.Arrays;
import java.util.List;
import org.apache.spark.ml.feature.FeatureHasher;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.Metadata;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
List data = Arrays.asList(
RowFactory.create(2.2, true, "1", "foo"),
RowFactory.create(3.3, false, "2", "bar"),
RowFactory.create(4.4, false, "3", "baz"),
RowFactory.create(5.5, false, "4", "foo")
);
StructType schema = new StructType(new StructField[]{
new StructField("real", DataTypes.DoubleType, false, Metadata.empty()),
new StructField("bool", DataTypes.BooleanType, false, Metadata.empty()),
new StructField("stringNum", DataTypes.StringType, false, Metadata.empty()),
new StructField("string", DataTypes.StringType, false, Metadata.empty())
});
Dataset dataset = spark.createDataFrame(data, schema);
FeatureHasher hasher = new FeatureHasher()
.setInputCols(new String[]{"real", "bool", "stringNum", "string"})
.setOutputCol("features");
Dataset featurized = hasher.transform(dataset);
featurized.show(false);
有关API的更多详细信息,请参阅FeatureHasher Scala文档。
Tokenizer(分词器)
Tokenization(文本符号化)是将文本(如一个句子)拆分成单词的过程。(在Spark ML中)Tokenizer(分词器)提供此功能。
RegexTokenizer提供了(更高级的)基于正则表达式 (regex) 匹配的(对句子或文本的)单词拆分。默认情况下,参数"pattern"(默认的正则表达式: "\\s+") 作为分隔符用于拆分输入的文本。或者,用户可以将参数“gaps”设置为 false ,指定正则表达式"pattern"表示"tokens",而不是分隔符,这样作为分词结果找到的所有匹配项。
Scala代码示例:(将句子拆分为词的序列)
StopWordsRemover (停用字清除)
import org.apache.spark.ml.feature._
import org.apache.spark.ml.Pipeline
// a DataFrame with three columns: id (integer), text (string), and rating (double).
val df = spark.createDataFrame(Seq(
(0, "Hi I heard about Spark", 3.0),
(1, "I wish Java could use case classes", 4.0),
(2, "Logistic regression models are neat", 4.0)
)).toDF("id", "text", "rating")
// define feature transformers
val tok = new RegexTokenizer().setInputCol("text").setOutputCol("words")
val sw = new StopWordsRemover().setInputCol("words").setOutputCol("filtered_words")
val tf = new HashingTF().setInputCol("filtered_words").setOutputCol("tf").setNumFeatures(10000)
val idf = new IDF().setInputCol("tf").setOutputCol("tf_idf")
val assembler = new VectorAssembler()
.setInputCols(Array("tf_idf", "rating")).setOutputCol("features")
val pipeline = new Pipeline().setStages(Array(tok, sw, tf, idf, assembler))
val model = pipeline.fit(df)
model.transform(df).select("id", "text", "rating", "features")
.write.format("parquet").save("/output/path")Binarizer(二元化方法)
二元化(Binarization)是通过(选定的)阈值将数值化的特征转换成二进制(0/1)特征表示的过程。
Binarizer(ML提供的二元化方法)二元化涉及的参数有inputCol(输入)、outputCol(输出)以及threshold(阀值)。(输入的)特征值大于阀值将映射为1.0,特征值小于等于阀值将映射为0.0。(Binarizer)支持向量(Vector)和双精度(Double)类型的输出。
import org.apache.spark.ml.feature.Binarizer
val data = Array((0, 0.1), (1, 0.8), (2, 0.2))
val dataFrame = spark.createDataFrame(data).toDF("id", "feature")
val binarizer: Binarizer = new Binarizer()
.setInputCol("feature")
.setOutputCol("binarized_feature")
.setThreshold(0.5)
val binarizedDataFrame = binarizer.transform(dataFrame)
println(s"Binarizer output with Threshold = ${binarizer.getThreshold}")
binarizedDataFrame.show()
5.ML管道(ML Pipelines)
ML Pipelines提供了一组基于DataFrame构建的统一的高级API ,可帮助用户创建和调优实际的机器学习管道。它可以将模型和transforming串联起来,并输出一个完成的模型。
管道中的主要概念
MLlib标准化用于机器学习算法的API,以便更轻松地将多个算法组合到单个管道或工作流程中。下面介绍Pipelines API引入的关键概念,其中管道概念主要受到scikit-learn项目的启发。
数据集(DataFrame)
机器学习可以应用于各种数据类型,例如矢量,文本,图像和结构化数据。此ML API使用来自Spark SQL的DataFrame作为ML数据集,它可以包含各种数据类型。例如:一个 DataFrame可以具有存储文本,特征向量,真实标签和预测的不同列。
DataFrame支持许多基本和结构化类型。除了Spark SQL指南中列出的类型之外,DataFrame还可以使用ML Vector类型。可以隐式或显式地从常规RDD创建一个DataFrame。一个 DataFrame中的列被命名。下面的代码示例使用诸如“text”,“features”和“label”之类的名称。
管道组件
Transformer(转换器)
Transformer是一种抽象,包括特征变换器和学习模型,它可以将一个DataFrame变换为另一个DataFrame。从技术上讲,Transformer实现了一种方法transform(),DataFrame通常通过附加一个或多个列来将一个方法转换为另一个方法。例如:
- 特征变换器可以采用一个 DataFrame,读取列(例如,文本),将其映射到新列(例如,特征向量),并输出附加了映射列的DataFrame新列。
- 学习模型可以采用a DataFrame,读取包含特征向量的列,预测每个特征向量的标签,并输出DataFrame带有作为列附加的预测标签的新元素。
Estimator(估计器)
Estimator是一种可以被固定在DataFrame生成一个Transformer的算法。从技术上讲,一个Estimator实现一个方法fit(),它接受DataFrame并生成一个 Model,这是一个Transformer。例如,学习算法例如LogisticRegression是a Estimator,并且呼叫fit()训练一个 LogisticRegressionModel,它是一个 Model,因此是一个 Transformer。
管道组件的属性
Transformer.transform()s和Estimator.fit()s都是没有状态的。将来可以通过替代概念支持有状态算法。每个Transformer或Estimator实例具有唯一ID,这在指定参数(下面讨论)时很有用。
管道(Pipeline)
一个Pipeline和多个Transformers、Estimators 链在一起以指定ML工作流。
在机器学习中,通常运行一系列算法来处理和挖掘数据。例如,简单的文本文档处理工作流程可能包括几个阶段:
- 将每个文档的文本拆分为单词。
- 将每个文档的单词转换为数字特征向量。
- 使用特征向量和标签挖掘预测模型。
MLlib将这样的工作流表示为一个 Pipeline(管道),它由一系列按特定顺序运行的PipelineStages(Transformers和Estimators)组成 。
这个怎么运作?
一个Pipeline被指定为阶段序列,每个阶段是一个Transformer或一个 Estimator。这些阶段按顺序运行,DataFrame输入 在通过每个阶段时进行转换。对于Transformer阶段,该transform()方法在DataFrame上被调用。对于Estimator阶段,fit()方法被调用,以产生Transformer(它成为PipelineModel的部分,或装配Pipeline),以及Transformer的transform()方法在DataFrame上被调用。
下图是一个Pipeline针对训练时间的使用情况。
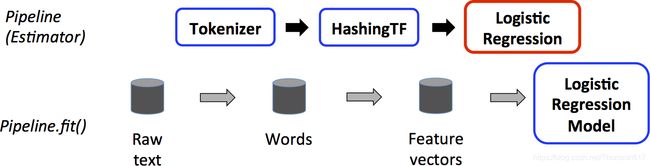
上图的顶行表示Pipeline三个阶段。前两个(Tokenizer和HashingTF)是Transformers(蓝色),第三个(LogisticRegression)是Estimator(红色)。底行表示流经管道的数据,其中柱面表示DataFrames。Pipeline.fit()方法在原始DataFrame上调用,原始DataFrame包含文本文档和标签。Tokenizer.transform()方法将原始文本文档拆分为单词,向DataFrame添加一个包含单词的新列。HashingTF.transform()方法将单词列转换为特征向量,将具有这些向量的新列添加到DataFrame。现在,由于LogisticRegression是一个估计器,管道首先调用LogisticRegression.fit()来生成一个LogisticRegressionModel。如果Pipeline有更多的Estimators,它会调用LogisticRegressionModel在传递到下一阶段之前对数据集调用LogisticRegressionModel的transform()方法。
一个Pipeline是一个Estimator。因此,之后Pipeline的fit()方法运行时,它产生一个PipelineModel,这是一个 转换器。这个管道模型在测试时使用;下图说明了这种用法:

在上图中,它PipelineModel具有与原始相同的阶段数Pipeline,但原始中的所有Estimators Pipeline都变为Transformers。当PipelineModel的transform()方法被称为上的测试数据集,该数据是为了通过拟合管道传递。每个阶段的transform()方法都会更新数据集并将其传递到下一个阶段。
Pipelines和PipelineModels有助于确保训练和测试数据经过相同功能处理步骤。
细节:DAG Pipeline小号:甲Pipeline的级被指定为一个有序阵列。这里给出的例子都是线性Pipelines,即Pipelines,其中每个阶段使用前一阶段产生的数据。Pipeline只要数据流图形成有向无环图(DAG),就可以创建非线性s。目前,此图基于每个阶段的输入和输出列名称(通常指定为参数)隐式指定。如果Pipeline形成DAG,则必须按拓扑顺序指定阶段。
运行时检查:由于Pipelines可以在DataFrame具有不同类型的s上运行,因此它们不能使用编译时类型检查。 Pipelines和PipelineModels代替在实际运行之前进行运行时检查Pipeline。这种类型检查是使用DataFrame 模式完成的,模式中的列的数据类型的描述DataFrame。
独特的管道阶段:A Pipeline的阶段应该是唯一的实例。例如,myHashingTF不应将同一实例 插入Pipeline两次,因为Pipeline阶段必须具有唯一ID。但是,不同的实例myHashingTF1和myHashingTF2(两种类型HashingTF)都可以放在同一个Pipeline实例中,因为将使用不同的ID创建不同的实例。
参数(Parameter)
MLlib Estimator和Transformers使用统一的API来指定参数。
Param是带有自包含文档的命名参数。 ParamMap是一组(参数,值)对。
将参数传递给算法有两种主要方法:
1.设置实例的参数。此API类似于spark.mllib包中使用的API 。
2.传递ParamMap到fit()或transform()。在任何参数ParamMap将覆盖以前通过setter方法指定的参数。
参数属于Estimators和Transformers的特定实例。例如,如果我们有两个LogisticRegression实例lr1和lr2,然后我们可以建立一个ParamMap与两个maxIter指定的参数:ParamMap(lr1.maxIter -> 10, lr2.maxIter -> 20)。如果有两个算法的maxIter参数在a中,这很有用Pipeline。
ML持久性:保存和加载管道
通常,将模型或管道保存到磁盘以供以后使用是值得的。在Spark 1.6中,模型导入/导出功能已添加到Pipeline API中。在Spark2.3中,spark.ml和pyspark.ml的DataFrame-based API中已经完成覆盖。
ML持久性适用于Scala,Java和Python。但是,R当前使用的是修改后的格式,因此保存在R中的模型只能加载回R; 这应该在将来修复,并在SPARK-15572中进行跟踪。
ML持久性的向后兼容性
通常,MLlib保持ML持久性的向后兼容性。即,如果你在一个版本的Spark中保存ML模型或Pipeline,那么你应该能够将其加载回来并在将来的Spark版本中使用它。但是,极少数例外情况如下所述。
模型持久性:Spark版本Y可以加载Spark版本X中使用Apache Spark ML持久性保存模型或管道吗?
- 主要版本:没有保证,但是尽力而为。
- 次要和补丁版本:是的; 这些是向后兼容的。
- 关于格式的注意事项:不保证稳定的持久性格式,但模型加载本身设计为向后兼容。
模型行为:Spark版本X中的模型或管道在Spark版本Y中的行为是否相同?
- 主要版本:没有保证,但是尽力而为。
- 次要和补丁版本:相同的行为,除了错误修复。
对于模型持久性和模型行为,在Spark版本发行说明中报告了次要版本或修补程序版本的任何重大更改。
代码示例:
Scala代码:
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.linalg.{Vector, Vectors}
import org.apache.spark.ml.param.ParamMap
import org.apache.spark.sql.Row
// 从(标签、特性)元组列表中准备训练数据
val training = spark.createDataFrame(Seq(
(1.0, Vectors.dense(0.0, 1.1, 0.1)),
(0.0, Vectors.dense(2.0, 1.0, -1.0)),
(0.0, Vectors.dense(2.0, 1.3, 1.0)),
(1.0, Vectors.dense(0.0, 1.2, -0.5)))
).toDF("label", "features")
// 创建一个逻辑回归实例。这个实例是一个Estimator估计器.
val lr = new LogisticRegression()
// 打印出参数、文档和任何缺省值.
println(s"LogisticRegression parameters:\n ${lr.explainParams()}\n")
// 我们可以使用setter方法设置参数.
lr.setMaxIter(10).setRegParam(0.01)
// 学习逻辑回归模型。这将使用存储在lr中的参数.
val model1 = lr.fit(training)
// 因为model1 是一个Model (即,Transformer 产生的Estimator),我们可以查看它在fit()期间使用的参数。这将打印参数(name: value),其中名称是惟一的id
// LogisticRegression实例.
println(s"Model1 was fit using parameters: ${model1.parent.extractParamMap}")
// 我们也可以使用ParamMap指定参数,支持多种指定参数的方法.
val paramMap = ParamMap(lr.maxIter -> 20)
.put(lr.maxIter, 30) // 指定1参数。这将覆盖原来的maxIter
.put(lr.regParam -> 0.1, lr.threshold -> 0.55) // 指定多个参数
// 你也可以组合ParamMaps.
val paramMap2 = ParamMap(lr.probabilityCol -> "myProbability")
// 更改输出列名.
val paramMapCombined = paramMap ++ paramMap2
// 现在学习一个使用paramMapCombined参数的新模型。paramMapCombined覆盖之前通过lr设置的所有参数set*方法.
val model2 = lr.fit(training, paramMapCombined)
println(s"parameters: ${model2.parent.extractParamMap}")示例二:
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.feature.{IndexToString, StringIndexer, VectorIndexer}
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.{SparkSession, functions}
val spark = SparkSession.builder.master("local").appName(this.getClass.getSimpleName).getOrCreate()
spark.sparkContext.setLogLevel("WARN")
import spark.implicits._ //支持把一个RDD隐式转换为一个DataFrame
val df = spark.sparkContext.textFile("/binomial_data.txt")
.map(_.split(",")).map(x => (Vectors.dense(x(0).toDouble, x(1)
.toDouble, x(2).toDouble, x(3).toDouble), x(4))).toDF("features","label")
df.createOrReplaceTempView("data_schema")
val df_data = spark.sql("select * from data_schema where label !='soyo2'")
val labelIndexer = new StringIndexer()
.setInputCol("label").setOutputCol("indexedLabel").fit(df_data)
val featureIndexer = new VectorIndexer() //在特征向量中创建类别索引
.setInputCol("features").setOutputCol("indexedFeatures").fit(df_data)
// 随机划分训练集与测试集
val Array(trainData, testData) = df_data.randomSplit(Array(0.7, 0.3))
val lr = new LogisticRegression()
.setLabelCol("indexedLabel") // 设置Label索引标签(默认读取“label”列)
.setFeaturesCol("indexedFeatures") // 设置特征列(默认读取“features”列)
.setMaxIter(30) // 设置最大迭代次数(默认值为100)
.setTol(1E-7) // 设置容错(默认1E-6),每次迭代会计算一个误差值,误差值会随着迭代次数的增加逐渐减小,如果误差值小于设置的容错值,则停止迭代优化
.setRegParam(0.5) // 设置回归参数(正则化项系数)(默认0.0)
.setElasticNetParam(0.8) //正则化范式比(默认0.0)
val labelConverter = new IndexToString()
.setInputCol("prediction")
.setOutputCol("predictionLabel")
.setLabels(labelIndexer.labels)
val lrPipeline = new Pipeline().setStages(Array(labelIndexer, featureIndexer, lr, labelConverter))
val lrPipeline_Model = lrPipeline.fit(trainData)
val lrPrediction = lrPipeline_Model.transform(testData)
lrPrediction.show(10,false)// 运行结果:

注意事项:
在使用spark MLlib的pipeline做训练,然后他把这个pipeline放到了Java服务(spring boot服务)中时,效率可能会特别低。
比如word2vec的transform方法:
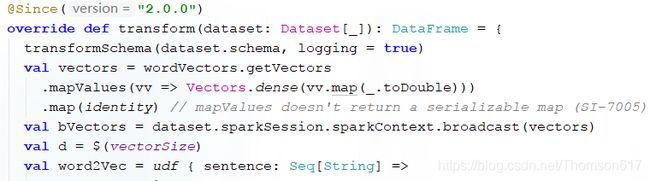
来一条数据,它需要先获得vectors(词到vector的映射)对象:

每次请求他都要做如上调用和计算。接着还需要把这些东西(这个可能就比较大了,几百M或者几个G都有可能)广播出去。
把model集成到Java 服务里实例:
假设你使用贝叶斯训练了一个模型,你需要保存下这个模型,保存的方式如下:

接着,在你的Java/scala程序里,引入spark core,spark mllib等包。加载模型:
![]()
这个时候因为要做预测,我们为了性能,不能直接调用model的transform方法。仔细观察发现,我们需要通过反射调用两个方法,就能实现分类。第一个是predictRaw方法,该方法输入一个向量,输出也为一个向量。我们其实不需要向量,我们需要的是一个分类的id。predictRaw 方法在model里,但是没办法直接调用,因为是私有的:
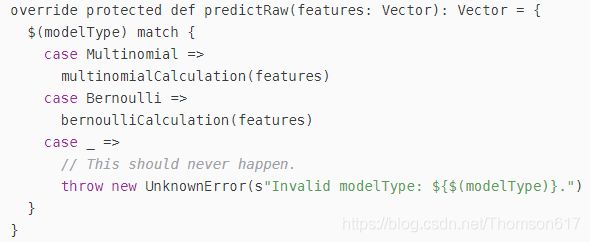
所以需要通过反射来完成:
此时已经得到了predctRaw的结果,接着我们要用raw2probability 把向量转化为一个概率分布,因为spark 版本不同,可能要做版本适配:
val raw2probabilityMethod = if (sparkSession.version.startsWith("2.3"))
"raw2probabilityInPlace" else "raw2probability"
val raw2probability = model.getClass.getMethod(raw2probabilityMethod, classOf[Vector]).invoke(model, predictRaw).asInstanceOf[Vector]raw2probability 其实也还是一个向量,这个向量的长度是分类的数目,每个位置的值是概率。所以所以我们只要拿到最大的那个概率值所在的位置就行:
val categoryId = raw2probability.argmax
这个时候categoryId 就是我们预测的分类了。Spark MLlib学习了SKLearn里的transform和fit的概念,但是因为设计上还是遵循批处理的方式,实际部署后会有很大的性能瓶颈,不适合那种数据一条一条过来需要快速响应的预测流程,所以需要调用一些内部的API来完成最后的预测。