关于Paddle Paddle训练过程的个人理解--以线性回归为例
经过一段时间对于PaddlePaddle文档的阅读,在一定程度上对Paddle的训练过程有了初步的认知。为了加强对Paddle的理解,于是乎将最近学习感悟分享出来,供大家评判。
本文会以线性回归为例,以大白话方式来说明,如何在PaddlePaddle实现的训练过程,我们以如下一张图片进入所要阐述的内容。
1、训练模块概括

训练模块概述
从图中我们可以看出,训练的实质就是将数据和已经设计好的算法模型和初始化的参数集合扔到一个容器里面进行反复的迭代(Run),最终得到(Return)一组最佳的参数集合,参数集合可以像骨架一样,将算法模型丰满起来,进而能够让训练数据//预测数据在这个丰满的模型上得到的预测值到底我们的预期。下面会将上述内容依次分开讲解,向读者一步步说明,在paddle中的实现过程。
2、各模块阐述
2.1 配置数据(Dataset)
Paddle线性回归项目采用波士顿房价数据集进行模型的训练和预测,在paddle中已经内置了此数据集,只需要通过调用dataset函数,运行dataset.uci_housing.train()即可进行数据下载,获取我们想要的数据。如下图为下载的数据:
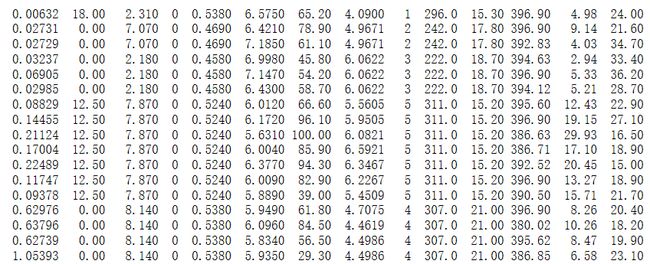
uci数据示例
具体实现代码如下:
BATCH_SIZE =20
train_reader = paddle.batch(
paddle.reader.shuffle(
paddle.dataset.uci_housing.train(), buf_size=500),
batch_size=BATCH_SIZE)在讲解代码之前,说一下关于对Batch、Batch_size的理解,在训练过程中,由于电脑的硬件性能如内存、显存问题,我们不会将数据一次性导入训练,而是分批次,批次就是batch,每个批次里面的数据大小就是Batch_size。
在这段代码中,将paddle.batch获取的数据赋值给train_reader,通过查batch这个API,batch(reader, batch_size),batch有两个变量,reader和batch size,reader作用为得到符合batch格式的数据,batch_size表示每读取一个batch中有多少数据;在读取过程中又遇到了一个新的函数shuffle。shuffle的意思是创建一个特殊的数据读取器,它的输出数据会被重洗,通过查询API中得到shuffle(reader, buffer_size),即shuffle是将reader进一步加上限制条件。应用shuffle函数会将原始读取器创建的迭代器得到的输出被暂存到shuffle缓存区,其后会对其进行重洗运算,而buffer_size表示shuffer缓存区的大小。
上述步骤总结实际就是用一个batch(reader,batch_size)函数获取训练需要的数据。
在看查询这个代码时候,其实遇到一个疑惑,比如,代码上写的是paddle.batch。实际去查询API时候发现实际给出的是paddle.fluid.layers.batch,实际二者是没有区别。
2.2 训练主函数(Main_program)
在Paddle中,将设计好的模型、损失函数、优化函数都会装在一个主函数(Main_program)中,这里也可将program可以理解为一个口袋。我们分别介绍一个这个口袋里面的东西。其实可以比喻为一个容器,为了和下文中的容器区别,因此将program比喻为口袋。
2.2.1 模型(model)
在这案例中涉及到的模型比较简单,通过一个全连接实现预测回归。
x=fluid.layers.data(name='x',shape=[13],dtype='float32')
y = fluid.layers.data(name='y', shape=[1], dtype='float32')
y_predict = fluid.layers.fc(input=x, size=1, act=None) 首先用data函数对数据类型进行命名和定义,关于data不做详细解释。在线性回归的案例中,模型实际只有一句话fluid.layers.fc,即“fc”为全连接层,本模型应用一个全连接层实现回归预测。从API中得到:
paddle.fluid.layers.fc(input, size, num_flatten_dims=1, param_attr=None, bias_attr=None, act=None, is_test=False, name=None)其中size为输入模型的数据、size为输出结果的大小、act为激活函数的类型。在示例的代码中,输入x,输出结果数据格式为1,act=None表示没有使用激活函数。具体模型阐述如下图所示。
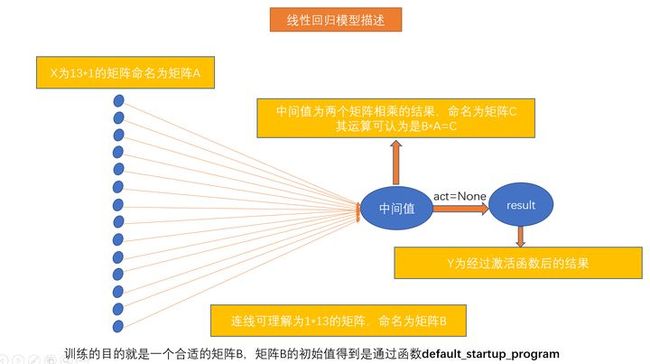
线性回归模型阐述
2.2.2 损失函数(loss)
损失函数定义了拟合结果和真实结果之间的差异,作为优化的目标直接关系模型训练的好坏,本案例采用平均均方差作为损失函数。其代码如下:
cost = fluid.layers.square_error_cost(input=y_predict, label=y)
avg_loss = fluid.layers.mean(cost) 在代码中square_error_cost分别由两个参数,一个是预测值(y_predict),一个是实际值(label),通过获取两个参数的平方差并用mean函数做平均处理,得到最终的损失函数。
2.2.3 优化器(optimizer)
神经网络最终是一个最优化问题在经过前向计算和反向传播后, Optimizer 使用反向传播梯度,优化神经网络中的参数。
sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.001)
sgd_optimizer.minimize(avg_loss)案例中采用的SGD是实现随机梯度下降的一个 Optimizer子类,是梯度下降大类中的一种方法。当需要训练大量样本的时候,往往选择 SGD 来使损失函数更快的收敛。
设置好网络结构、损失函数、优化器之后,整个网络的脉络应该是比较清晰,下一步就是要参数初始化。
2.3 设置初始化参数
在本案例中定义两个program,一个是叫做default_mian_program,一个叫做default_startup_program。前文中我们谈到,我们的模型、模型的前向后向计算都是在mian_program中,但是模型要运行,必须由初始化参数,例如我们在前面介绍模型结构时候,谈到的初始参数矩阵B就是由startup_program 运行先得到的。
同时,当我们同样条件下去训练模型,得到的结果是有一定的差别的。例如小明用同样的数据、模型去训练模型;小张也用同样的数据模型和训练去模型,得到的结果是不一样的,是因为我们初始化参数时候是随机的,这就导致我们训练的步数和准确率会有一定的偏差。
那么我们通过什么手段实现初始化参数呢?我们在下一章中介绍如何开始训练时候说这个操作的代码。
2.4 训练容器(Executor)
在谈到训练容器之前,我们说两个内容,第一个是训练场所(Place)第二个是我们获取得数据如何传输给模型。
训练场所(place):训练场所即为我的容器要在计算机上哪个地方运行,CPU或者是GPU。
在案例中对应的代码是:
use_cuda = False
place = fluid.CUDAPlace(0)if use_cuda else fluid.CPUPlace() 这句话的意思就是不使用cuda,也就是使用CPU作为运行的场所,顺便吐槽一下,百度写文档的人难道就不能把代码写的详细一点吗?公开的文档写的这么简便是对用户是不友好的。
将数据标签如何传入容器中:从前面内容我们利用paddle.batch读取了我们想要的数据,也用fluid.data定义了x,y.但是如何将提取的数据对应以及传输到容器中和program一起运算,需要做一定的处理,处理代码如下:
feeder = fluid.DataFeeder(place=place, feed_list=[x, y]) DataFeeder 负责将reader(读取器)返回的数据转成一种特殊的数据结构,使它们可以输入到 Executor。
在了解上述内容以后,我们正式来说Executor。
当我们配置好program、Data,我们需要一个环境来让这些东西Run起来,所以,我们用一个Executor来接受这些东西。如代码:
exe = fluid.Executor(place)即为我们创建的一个接收训练所需要东西的容器。
在随后,我们通过了解exe.run()的参数可进一步的了解到在关于容器运行的机制。如下代码为案例中executor在run时候传输进去的参数:
exe.run(main_program,feed=feeder.feed(data_train),fetch_list=[avg_loss])Executor可以接收传入的program、feeder数据,最终返回想要得到的fetch_list列表。
在各模块参数这一章里面,我们谈到了数据配置、设置训练主函数、设置初始化参数、设置训练容器四个进行阐述,接下来,我们将如何进一步的说明如何让这些东西在Executor中实现Run。
3训练操作说明
在训练之前要进行第一步:全局参数初始化。在上一章节-----设置初始化参数中谈到,如何设置初始化参数时候,我们放在这一章节来说明。在训练之前,我们通过如下代码,让全局参数初始化。
exe.run(startup_program)在进行参数初始化之后,我们通过一个for循环开始训练,训练就是不断的迭代,那么就涉及到了你要“迭”几“代”或者可以说是“迭”几“轮”,谈到这里,再说一个概念叫做Epoch。这个单词就是表示轮的意思,一轮代表遍历所有图片,遍历的方式是将每个batch里面的图片遍历一遍。举一个小例子,数据总数为200条,batch_size=40,则这批图片就是有200/40=5个batch,也就是遍历一轮图片会遍历5个batch。同时num_epochs = 100代表不断迭代100次,
训练即为设设定一种迭代的规则。如下代码即为设置我们在Executor中运行的规则:该代码表示,针对每一轮中的每一个batch的数据以及Program运行在Executor里面,同时返回损失。与此同时,每训练10轮,打印输出一次损失情况。
for pass_id in range(num_epochs):
for data_train in train_reader():
avg_loss_value, = exe.run(main_program,
feed=feeder.feed(data_train),
fetch_list=[avg_loss])
if step % 10 == 0:
plot_prompt.append(train_prompt, step, avg_loss_value[0])
plot_prompt.plot()
print("%s, Step %d, Cost %f" %
(train_prompt, step, avg_loss_value[0]))当设置好训练规则,就能实现了传说中所谓的训练模型了。最后,用一张图来作为整体脉络的梳理。
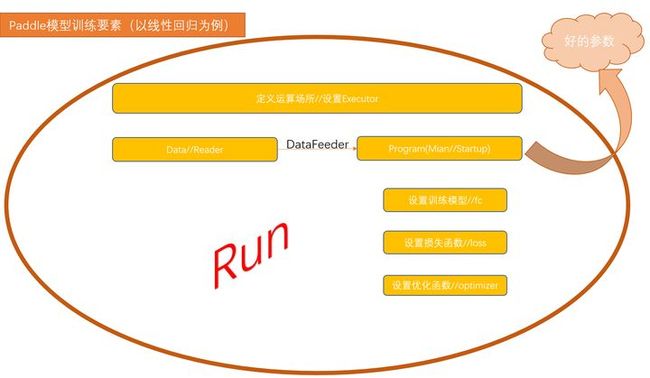
文章总述
总结说明
说明1
本文的书写记录是按照个人理解,侧重于方式的总结,总结一种使用paddle的个人使用套路,本篇文章与PaddlePaddle官方文档顺序不一致,同时省略了一些内容,如:定义测试函数,如何保存训练后的模型以及如何调用模型进行测试等。
说明2
本文整体结构为,先将训练需要的各个模块进行总体阐述,然后分别展开各个模块进行说明,接着在说训练的规则,也就是如何训练。文章引用了PaddlePaddle官网API内容,同时感谢李思远、王晨宇同学提供的帮助。