05_PyTorch 模型训练[常见损失函数]
1.class torch.nn.L1Loss(size_average=None, reduce=None)
功能:
计算 output 和 target 之差的绝对值,可选返回同维度的 tensor 或者是一个标量。
计算公式:
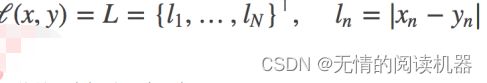
参数:
reduce(bool)- 返回值是否为标量,默认为 True
size_average(bool)- 当 reduce=True 时有效。为 True 时,返回的 loss 为平均值;为 False
时,返回的各样本的 loss 之和。
代码:
# ----------------------------------- L1 Loss
# 生成网络输出 以及 目标输出
output = torch.ones(2, 2, requires_grad=True)*0.5
target = torch.ones(2, 2)
# 设置三种不同参数的L1Loss
reduce_False = nn.L1Loss(size_average=True, reduce=False)
size_average_True = nn.L1Loss(size_average=True, reduce=True)
size_average_False = nn.L1Loss(size_average=False, reduce=True)
o_0 = reduce_False(output, target)
o_1 = size_average_True(output, target)
o_2 = size_average_False(output, target)
print('\nreduce=False, 输出同维度的loss:\n{}\n'.format(o_0))
print('size_average=True,\t求平均:\t{}'.format(o_1))
print('size_average=False,\t求和:\t{}'.format(o_2))输出:
![05_PyTorch 模型训练[常见损失函数]_第1张图片](http://img.e-com-net.com/image/info8/b85ff443ce724d988e85df2df6b07d01.jpg)
2.classtorch.nn.MSELoss(size_average=None,reduce=None)
功能:
计算 output 和 target 之差的平方,可选返回同维度的 tensor 或者是一个标量。
计算公式:
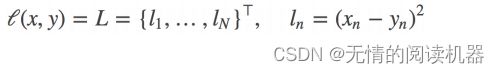
参数:
reduce(bool)- 返回值是否为标量,默认为 True
size_average(bool)- 当 reduce=True 时有效。为 True 时,返回的 loss 为平均值;为 False
时,返回的各样本的 loss 之和。
代码:
# ----------------------------------- MSE loss
# 生成网络输出 以及 目标输出
output = torch.ones(2, 2, requires_grad=True) * 0.5
target = torch.ones(2, 2)
# 设置三种不同参数的L1Loss
reduce_False = nn.MSELoss(size_average=True, reduce=False)
size_average_True = nn.MSELoss(size_average=True, reduce=True)
size_average_False = nn.MSELoss(size_average=False, reduce=True)
o_0 = reduce_False(output, target)
o_1 = size_average_True(output, target)
o_2 = size_average_False(output, target)
print('\nreduce=False, 输出同维度的loss:\n{}\n'.format(o_0))
print('size_average=True,\t求平均:\t{}'.format(o_1))
print('size_average=False,\t求和:\t{}'.format(o_2))输出:
![05_PyTorch 模型训练[常见损失函数]_第2张图片](http://img.e-com-net.com/image/info8/c31978e9da3a4f5d8ba884b6dc2c6ed1.jpg)
3.class torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=100, reduce=None, reduction='elementwise_mean')
功能:
在多分类任务中,经常采用 softmax 激活函数+交叉熵损失函数,因为交叉熵描述了两个概 率分布的差异,然而神经网络输出的是向量,并不是概率分布的形式。所以需要 softmax 激活函数将一个向量进行“归一化”成概率分布的形式,再采用交叉熵损失函数计算 loss。
计算公式:
![05_PyTorch 模型训练[常见损失函数]_第3张图片](http://img.e-com-net.com/image/info8/2f88b733f38a471fa2e2582d2d6d237e.jpg)
参数:
weight(Tensor)- 为每个类别的 loss 设置权值,常用于类别不均衡问题。weight 必须是 float
类型的 tensor ,其长度要于类别 C 一致,即每一个类别都要设置有 weight 。
reduce(bool)- 返回值是否为标量,默认为 True
size_average(bool)- 当 reduce=True 时有效。为 True 时,返回的 loss 为平均值;为 False
时,返回的各样本的 loss 之和。
ignore_index(int)- 忽略某一类别,不计算其 loss ,其 loss 会为 0 ,并且,在采用
size_average 时,不会计算那一类的 loss ,除的时候的分母也不会统计那一类的样本
代码与输出:
# ----------------------------------- CrossEntropyLoss
loss_f = nn.CrossEntropyLoss(weight=None, size_average=True, reduce=False)
# 生成网络输出 以及 目标输出
output = torch.ones(2, 3, requires_grad=True) * 0.5 # 假设一个三分类任务,batchsize=2,假设每个神经元输出都为0.5
target = torch.from_numpy(np.array([0, 1])).type(torch.LongTensor)
print(output)
print(target)
loss = loss_f(output, target)
print('--------------------------------------------------- CrossEntropy loss: base')
print('loss: ', loss)
print('由于reduce=False,所以可以看到每一个样本的loss,输出为[1.0986, 1.0986]')
# 熟悉计算公式,手动计算第一个样本
output = output[0].detach().numpy()
output_1 = output[0] # 第一个样本的输出值
target_1 = target[0].numpy()
print("第一个样本的输出值",output_1)
print("第一个样本的类别",target_1)
# 第一项
x_class = output[target_1]
print("正确类别的概率",x_class)
# 第二项
exp = math.e
sigma_exp_x = pow(exp, output[0]) + pow(exp, output[1]) + pow(exp, output[2])
print("分母",sigma_exp_x)
#法1 :两项相加
log_sigma_exp_x = math.log(sigma_exp_x)
loss_1 = -x_class + log_sigma_exp_x
print('--------------------------------------------------- 法1手动计算')
print('第一个样本的loss:', loss_1)
#法2:两项相除
exp_x_class = pow(exp,x_class)
loss_1 = -math.log(exp_x_class/sigma_exp_x)
print('--------------------------------------------------- 法2手动计算')
print('第一个样本的loss:', loss_1)
# ----------------------------------- CrossEntropy loss: weight
weight = torch.from_numpy(np.array([0.6, 0.2, 0.2])).float()
loss_f = nn.CrossEntropyLoss(weight=weight, size_average=True, reduce=False)
output = torch.ones(2, 3, requires_grad=True) * 0.5 # 假设一个三分类任务,batchsize为2个,假设每个神经元输出都为0.5
target = torch.from_numpy(np.array([0, 1])).type(torch.LongTensor)
loss = loss_f(output, target)
print('\n\n--------------------------------------------------- CrossEntropy loss: weight')
print('loss: ', loss) #
print('原始loss值为1.0986, 第一个样本是第0类,weight=0.6,所以输出为1.0986*0.6 =', 1.0986*0.6)
4.class torch.nn.NLLLoss(weight=None, size_average=None, ignore_index=100, reduce=None, reduction='elementwise_mean')
功能:
举个例,三分类任务,input=[-1.233, 2.657, 0.534] , 真实标签为 2 ( class=2 ),则 loss 为 -0.534 。就是对应类别上的输出,取一个负号!
参数:
weight(Tensor)- 为每个类别的 loss 设置权值,常用于类别不均衡问题。 weight 必须是 float
类型的 tensor ,其长度要于类别 C 一致,即每一个类别都要设置有 weight 。
size_average(bool)- 当 reduce=True 时有效。为 True 时,返回的 loss 为除以权重之和的平均
值;为 False 时,返回的各样本的 loss 之和。
reduce(bool)- 返回值是否为标量,默认为 True 。
ignore_index(int)- 忽略某一类别,不计算其 loss ,其 loss 会为 0 ,并且,在采用
size_average 时,不会计算那一类的 loss ,除的时候的分母也不会统计那一类的样本。
代码与输出:
# ----------------------------------- log likelihood loss
# 各类别权重
weight = torch.from_numpy(np.array([0.6, 0.2, 0.2])).float()
# 生成网络输出 以及 目标输出
output = torch.from_numpy(np.array([[0.7, 0.2, 0.1], [0.4, 1.2, 0.4]])).float()
output.requires_grad = True
target = torch.from_numpy(np.array([0, 0])).type(torch.LongTensor)
loss_f = nn.NLLLoss(weight=weight, size_average=True, reduce=False)
loss = loss_f(output, target)
print('\nloss: \n', loss)
print('\n第一个样本是0类,loss = -(0.6*0.7)={}'.format(loss[0]))
print('\n第二个样本是0类,loss = -(0.6*0.4)={}'.format(loss[1]))![05_PyTorch 模型训练[常见损失函数]_第4张图片](http://img.e-com-net.com/image/info8/71f34e2eeaa24ffbaed436264a269a44.jpg)