pandas 删除列_Pandas概论
我认为,既然你点开了这个页面,你可能有大量的数据需要分析,你可能正在想最好和最有效的方法来解决你数据的一些问题。你问题的答案可以通过Pandas解决。
如何接触Pandas
由于Pandas的流行,它有自己的传统缩写,所以无论何时将Pandas导入python,请使用以下命名:
import pandas as pdPandas包的主要用途是数据框
Pandas API将Pandas数据帧定义为:
二维、大小可变、潜在的异构表格数据。数据结构还包含轴(行和列)。算术运算对行标签和列标签进行对齐。可以认为是一个类似于dict的容器,用于存储序列对象。是Pandas主要的数据结构。
基本上,这意味着你有包含在格式中的数据,如下所示。在行和列中找到的数据:
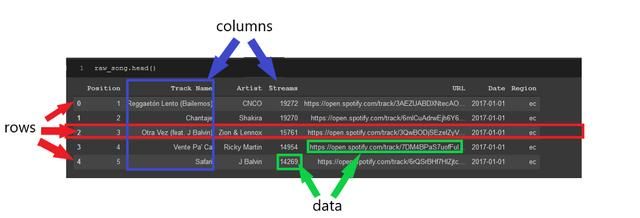
数据帧非常有用,因为它们提供了一种高效的方法来可视化数据,然后按你希望的方式操作数据。
这些行可以很容易地被索引引用,索引是数据帧最左边的数字。索引将是从零开始的编号,除非你指定每一行的名称。列也可以很容易地被列名称(例如“Track name”)或其在数据帧中的位置进行引用。我们将在本文后面详细讨论引用行和列。
创建数据帧

创建Pandas数据帧的方法有几种:
- 从.csv文件导入数据(或其他文件类型,例如Excel、SQL数据库)
- 从列表中
- 从字典里
- 从numpy数组
- 其他
通常,你将主要将.csv文件或某种类型的数据源的数据放入Pandas数据框架中,而不是从头开始,因为这将需要非常长的时间来完成,这取决于你拥有的数据量。以下是python字典中的一个快速、简单的示例:
import pandas as pddict1 = {'Exercises': ['Running','Walking','Cycling'], 'Mileage': [250, 1000, 550]}df = pd.DataFrame(dict1)df输出:

字典键(“Exercises”和“Mileage”)成为相应的列标题。字典中的值是本示例中的列表,成为数据帧中的单个数据点。Running是“Exercises”列表中的第一个,250将被列在第二列的第一个。另外,你会注意到,由于我没有为数据帧的索引指定标签,因此它会自动标记为0、1和2。
但是,就像我之前所说的,创建Pandas数据帧的最可能方法是从csv或其他类型的文件中导入,你将导入该文件来分析数据。只需以下内容即可轻松完成:
df = pd.read_csv("file_location.../file_name.csv")pd.read_csv是一种非常强大和通用的方法,根据你希望如何导入数据,它将非常有用。如果csv文件已经附带了头或索引,则可以在导入时指定。为了充分了解pd.read_csv,我建议你看看这里的PandasAPI:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html?highlight=read_csv
第一件事
现在你已经准备好了这个巨大的数据集,你必须查看它,看看它的外观。作为一个分析这些数据的人,首先必须对数据集熟悉,并真正了解数据集中发生了什么。我喜欢用四种方法来了解我的数据。
- .head() & .tail()
- .info()
- .describe()
- .sample()
raw_song.head()它显示数据帧的前5行和每个列,以便你轻松地总结数据的外观。你还可以在方法中指定一定数量的行,以显示更多行。

.tail仅显示最后5行。
raw_song.tail()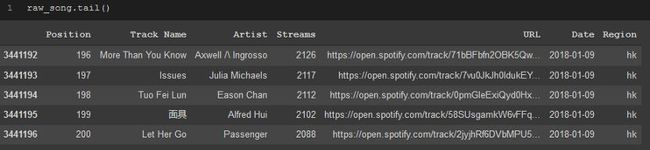
从这两个快速方法中,我对列名和数据的外观有了一个大致的了解,这只是从数据集的一个小样本中得到的。这些方法也非常有用,尤其是对于Spotify数据集这样的数据集,处理超过300万行的数据时,你可以轻松地显示数据集并快速了解数据,而且你的计算机也不会花很长时间来显示数据。
.info也很有用,它向我显示了所有列、它们的数据类型以及是否有null数据点。
raw_song.info(verbose=True, null_counts=True)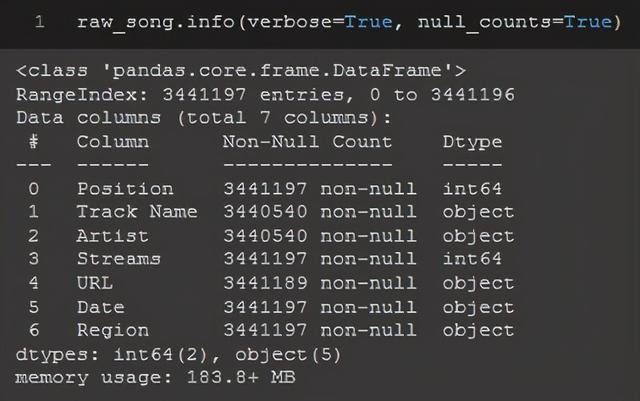
如果你有完整的整型或浮点型列(即'Position'、'Streams'),那么.describe是一个有用的方法,可以帮助你更好地了解数据集,因为它将显示关于这些列的许多描述性统计信息。
raw_song.describe()
最后,.sample将允许你随机对数据帧进行采样,并查看你所做的任何操作是否错误地更改了数据集中的某些内容,而且当你第一次探索数据集时,也可以很好地了解数据集包含哪些内容
raw_song.sample(10)
在探索和准备数据集进行分析时,我始终使用这些方法。每当我更改列中的数据、更改列名或添加/删除行/列时,我都会通过至少快速运行前面5个方法中的一些来确保所有更改都按我希望的方式进行。
选择行或列
太棒了,现在你知道如何将数据集作为一个整体来看待,但实际上你只想查看几列或几行,然后将其余部分排除在外。
.loc[]和.iloc[]
这两个方法将以不同的方式来实现这一点,这取决于你能够引用特定行或列的方式。
如果知道行或列的标签,请使用.loc[]。
如果知道行或列的索引,请使用.iloc[]。
如果你两者都知道,就选你最喜欢的。
因此,回到Spotify数据集。你可以使用.loc[]或.iloc[]查看列“Track Name”。如果知道列的标签可以使用.loc[],所以我将使用以下内容:
raw_song.loc[:,'Track Name']第一个括号后面的冒号指定我引用的行,由于我希望所有行都位于“Track Name”列中,所以我使用“:”。
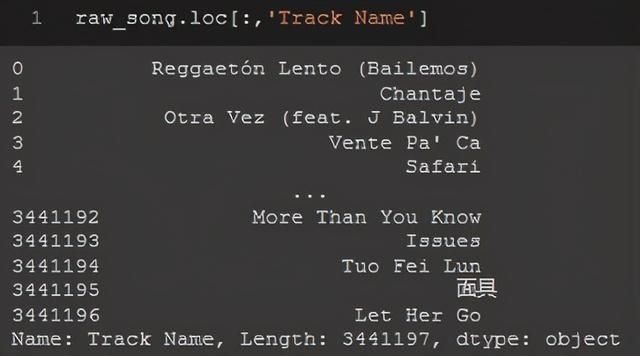
我将收到与.iloc[]相同的输出,但这次需要指定“Track Name”列的索引:
raw_song.iloc[:,1]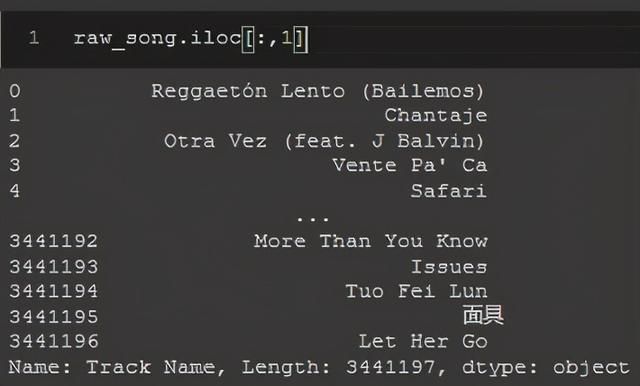
.loc[]和.iloc[]对行的作用相同,但在本例中,因为行的标签和索引都是相同的,所以它们看起来完全相同。
切片

另一种获取DataFrame部分的简单方法是使用[]并在方括号内指定列名。
raw_song[['Artist','Streams']].head()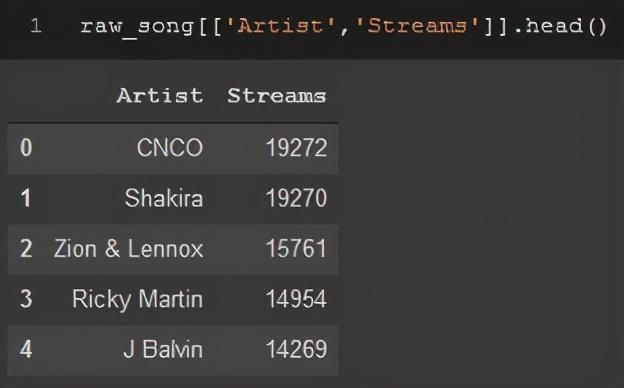
如果你只使用一列和一组括号,你将得到Pandas Series。
raw_song['Streams']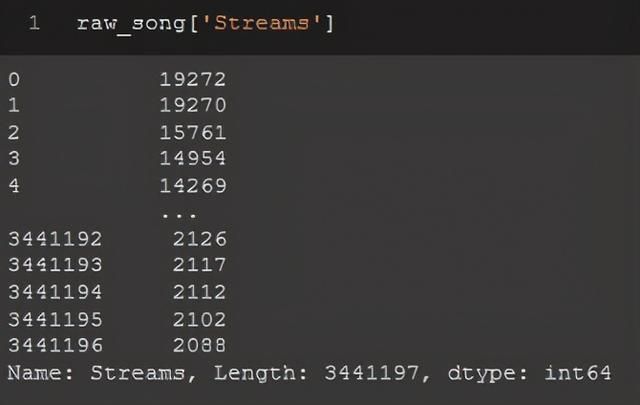
从数据帧添加行、列
利用我们已经从.loc[]获得的信息,我们可以使用this或.insert将行或列添加到数据帧中。
添加行
如果决定使用.loc[]将行添加到dataframe,则只能将其添加到dataframe的底部。指定dataframe中的任何其他索引,删除当前在该行中的数据,并用要插入的数据替换它。
raw_song.loc[3441197] = [0,'hello','bluemen',1,"https://open.spotify.com/track/notarealtrack", '2017-02-05','ec']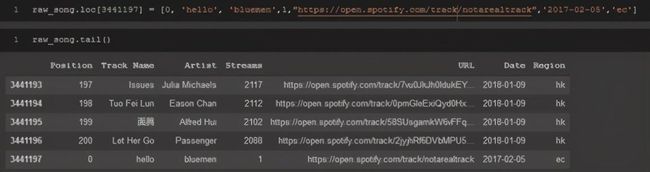
你也可以使用.loc[]将列添加到数据帧中。
raw_song.loc[:,'new_col'] = 0raw_song.tail()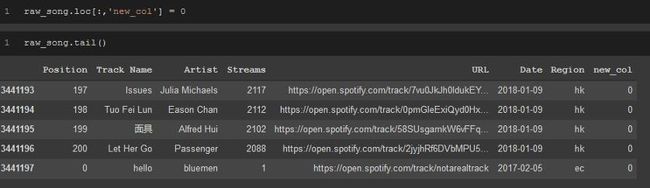
除了在末尾之外,还有两种方法可以将新列插入数据帧中。
insert方法允许你指定要将列放入数据帧的位置。它接受3个参数、要放置它的索引、新列的名称以及要作为列数据放置的值。
raw_song.insert(2,'new_col',0)raw_song.tail()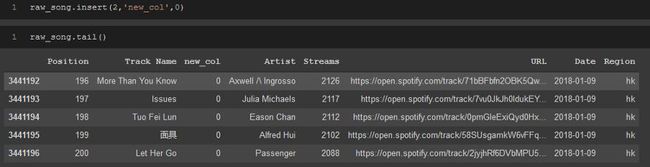
将列添加到dataframe的第二种方法是通过使用[]命名新列并使其与新数据相等,从而使其成为dataframe的一部分。
raw_song['new_col'] = 0raw_song.tail()
通过这种方式,我无法指定新列的位置,但这是执行该操作的另一种有用方法。
从数据帧中删除行、列

如果你想删除一些行或列,这很简单,只需删除它们。
只需指定要删除的轴(行为0,列为1)和要删除的行或列的名称,就可以开始了!
raw_song.drop(labels='new_col',axis=1)
重命名索引或列
如果要将dataframe的索引更改为dataframe中的其他列,请使用.set_index并在括号中指定列的名称。但是,如果你确切知道要为索引命名的内容,请使用.rename方法。
raw_song.rename(index={0:'first'}).head()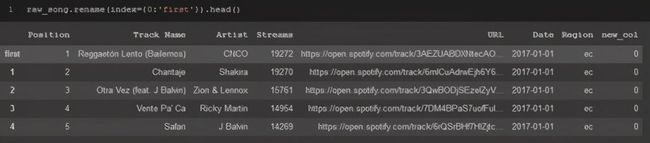
要重命名列,请在.rename方法中指定要重命名的列以及在{}中要为其命名的名称,类似于重命名索引。
raw_song.rename(columns={'Position':'POSITION_RENAMED'}).head()
如何迭代数据帧
很多时候,当你处理数据帧中的数据时,你需要以某种方式更改数据并迭代数据帧中的所有值。最简单的方法是在pandas中内置for循环:
for index, col in raw_song.iterrows(): # 在此处操作数据如何将数据帧写入文件
在完成对数据帧的所有操作之后,现在是导出数据帧的时候了,以便可以将其发送到其他地方。与从文件导入数据集类似,现在正好相反。Pandas有多种不同的文件类型,你可以将数据帧写入其中,但最常见的是将其写入csv文件。
pd.to_csv('file_name.csv')现在你知道Pandas和数据帧的基本知识了。这些是数据分析工具箱中非常强大的工具。