PPYOLOE
PP-YOLOE是基于PP-YOLOv2的单阶段Anchor-free模型,超越了多种流行的yolo模型。PP-YOLOE有一系列的模型,即s/m/l/x,可以通过width multiplier和depth multiplier配置。PP-YOLOE避免使用诸如deformable convolution或者matrix nms之类的特殊算子,以使其能轻松地部署在多种多样的硬件上。
一、模型结构:
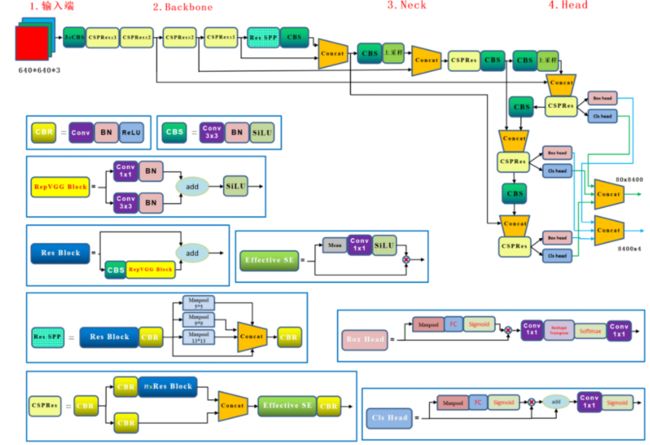
PP-YOLOE由可扩展的backbone和neck、Task Alignment Learning、Efficient Task-aligned head with DFL和VFL、SiLU激活函数构成。
(一)、Backbone
PP-YOLOE的Backbone主要是使用RepVGG模块以及CSP的模型思想对ResNet及逆行的改进,同时也使用了SiLU激活函数、Effitive SE Attention等模块。
RepVGG,是在VGG的基础上面进行改进,主要的思路包括:
在VGG网络的Block块中加入了Identity和残差分支,相当于把ResNet网络中的精华应用 到VGG网络中;模型推理阶段,通过Op融合策略将所有的网络层都转换为3×3卷积,便于网络的部署和加速。其基本结构以及合并op的主要过程如下:

其实就是一个OP融合和OP替换的过程。图A从结构化的角度展示了整个重参数化流程, 图B从模型参数的角度展示了整个重参数化流程。整个重参数化步骤如下所示:
步骤1:首先通过下式3将残差块中的卷积层和BN层进行融合,该操作在很多深度学习框架的推理阶段都会执行。图中的蓝色框中执行3×3卷积+BN层的融合,图中的黑色矩形框中执行1×1卷积+BN层的融合,图中的黄色矩形框中执行3×3卷积(卷积核设置为全1)+BN层的融合。其中表示转换前的卷积层参数,表示BN层的均值,表示BN层的方差,和分别表示BN层的尺度因子和偏移因子,W’和b’分别表示融合之后的卷积的权重和偏置。
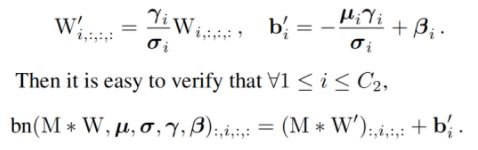
步骤2:将融合后的卷积层转换为3×3卷积,即将具体不同卷积核的卷积均转换为具有3×3大小的卷积核的卷积。由于整个残差块中可能包含1×1卷积分支和Identity两种分支,如图中的黑框和黄框所示。对于1×1卷积分支而言,整个转换过程就是利用3×3卷积核替换1×1卷积核,具体的细节如图中的紫框所示,即将1×1卷积核中的数值移动到3×3卷积核的中心点即可;对于Identity分支而言,该分支并没有改变输入的特征映射的数值,那么可以设置一个3×3的卷积核,将所有的9个位置处的权重值都设置为1,那么它与输入的特征映射相乘之后,保持了原来的数值,具体的细节如图中的褐色框所示。
步骤3:合并残差分支中的3×3卷积。即将所有分支的权重W和偏置B叠加起来,从而获得一个融合之后的3×3卷积层。
其基本代码块如下:
class RepVggBlock(nn.Layer):
def __init__(self, ch_in, ch_out, act='relu'):
super(RepVggBlock, self).__init__()
self.ch_in = ch_in
self.ch_out = ch_out
self.conv1 = ConvBNLayer(ch_in, ch_out, 3, stride=1, padding=1, act=None)
self.conv2 = ConvBNLayer(ch_in, ch_out, 1, stride=1, padding=0, act=None)
self.act = get_act_fn(act) if act is None or isinstance(act, (str, dict)) else act
def forward(self, x):
if hasattr(self, 'conv'):
y = self.conv(x)
else:
y = self.conv1(x) + self.conv2(x)
y = self.act(y)
return y
def convert_to_deploy(self):
if not hasattr(self, 'conv'):
self.conv = nn.Conv2D(in_channels=self.ch_in, out_channels=self.ch_out, kernel_size=3, stride=1, padding=1, groups=1)
kernel, bias = self.get_equivalent_kernel_bias()
self.conv.weight.set_value(kernel)
self.conv.bias.set_value(bias)
def get_equivalent_kernel_bias(self):
# 融合推理
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv1)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv2)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1), bias3x3 + bias1x1
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
kernel = branch.conv.weight
running_mean = branch.bn._mean
running_var = branch.bn._variance
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn._epsilon
std = (running_var + eps).sqrt()
t = (gamma / std).reshape((-1, 1, 1, 1))
return kernel * t, beta - running_mean * gamma / std
Swish激活函数:
Swish包含了SiLU,换句话说SiLU是Swish的一种特例.
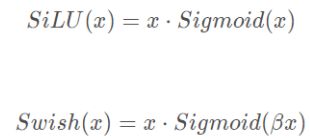
其图像如下:

β是个常数或可训练的参数。Swish 具备无上界有下界、平滑、非单调的特性。Swish 在深层模型上的效果优于 ReLU。
基本CBS的结构以及代码如下:

class ConvBNLayer(nn.Layer):
def __init__(self, ch_in, ch_out, filter_size=3, stride=1, groups=1, padding=0, act=None):
super(ConvBNLayer, self).__init__()
self.conv = nn.Conv2D(in_channels=ch_in, out_channels=ch_out, kernel_size=filter_size, stride=stride, padding=padding, groups=groups, bias_attr=False)
self.bn = nn.BatchNorm2D(ch_out, weight_attr=ParamAttr(regularizer=L2Decay(0.0)), bias_attr=ParamAttr(regularizer=L2Decay(0.0)))
self.act = get_act_fn(act) if act is None or isinstance(act, (str, dict)) else act
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.act(x)
return x
Effective SE Attention:
该模块主要是来自于《CenterMask:Real-Time Anchor-Free Instance Segmentation》中的eSE模块:
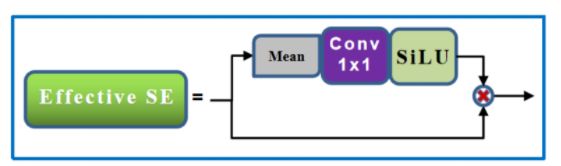
其基本代码块如下:
class EffectiveSELayer(nn.Layer):
def __init__(self, channels, act='hardsigmoid'):
super(EffectiveSELayer, self).__init__()
self.fc = nn.Conv2D(channels, channels, kernel_size=1, padding=0)
self.act = get_act_fn(act) if act is None or isinstance(act, (str, dict)) else act
def forward(self, x):
x_se = x.mean((2, 3), keepdim=True)
x_se = self.fc(x_se)
return x * self.act(x_se)
CSPNet结构:
CSPNet的主要思想还是Partial Dense Block,设计Partial Dense Block的目的是:
增加梯度路径:通过分裂合并策略,可以使梯度路径的数目翻倍。由于采用了跨阶段的策略,可以减轻使用显式特征映射复制进行连接的缺点;
平衡各层的计算:通常情况下,DenseNet底层的信道数远远大于增长率。由于部分dense block中的dense layer操作所涉及的底层信道只占原始信道的一半,因此可以有效地解决近一半的计算瓶颈;
减少内存流量:假设dense block在DenseNet中的基本特征映射大小为 w × h × c w×h×c w×h×c,增长率为d,并且共m层。然后,该dense block的CIO为 ( c ∗ m ) + ( ( m 2 + m ) ∗ d ) = 2 (c * m)+((m^2+m) * d) = 2 (c∗m)+((m2+m)∗d)=2,部分dense block的CIO为 ( ( c ∗ m ) + ( m 2 + m ) ∗ d ) = 2 ((c * m)+(m^2+m) * d) = 2 ((c∗m)+(m2+m)∗d)=2。虽然m和d通常比c小得多,但部分dense block最多可以节省网络内存流量的一半。

其代码如下:
class CSPResStage(nn.Layer):
def __init__(self, block_fn, ch_in, ch_out, n, stride, act='relu', attn='eca'):
super(CSPResStage, self).__init__()
ch_mid = (ch_in + ch_out) // 2
if stride == 2:
self.conv_down = ConvBNLayer(ch_in, ch_mid, 3, stride=2, padding=1, act=act)
else:
self.conv_down = None
self.conv1 = ConvBNLayer(ch_mid, ch_mid // 2, 1, act=act)
self.conv2 = ConvBNLayer(ch_mid, ch_mid // 2, 1, act=act)
self.blocks = nn.Sequential(* [block_fn(ch_mid // 2, ch_mid // 2, act=act, shortcut=True) for i in range(n)])
if attn:
self.attn = EffectiveSELayer(ch_mid, act='hardsigmoid')
else:
self.attn = None
self.conv3 = ConvBNLayer(ch_mid, ch_out, 1, act=act)
def forward(self, x):
if self.conv_down is not None:
x = self.conv_down(x)
y1 = self.conv1(x)
y2 = self.blocks(self.conv2(x))
y = paddle.concat([y1, y2], axis=1)
if self.attn is not None:
y = self.attn(y)
y = self.conv3(y)
return y
SPP结构:
SPP有效避免了R-CNN算法对图像区域剪裁、缩放操作导致的图像物体剪裁不全以及形状扭曲等问题。
解决了卷积神经网络对图像重复特征提取的问题,大大提高了产生候选框的速度,且节省了计算成本。
SPP 显著特点
1、不管输入尺寸是怎样,SPP 可以产生固定大小的输出
2、使用多个窗口(pooling window)
3、SPP 可以使用同一图像不同尺寸(scale)作为输入, 得到同样长度的池化特征。
其它特点
1、由于对输入图像的不同纵横比和不同尺寸,SPP同样可以处理,所以提高了图像的尺度不变(scale-invariance)和降低了过拟合(over-fitting)
2、实验表明训练图像尺寸的多样性比单一尺寸的训练图像更容易使得网络收敛(convergence)
3、SPP 对于特定的CNN网络设计和结构是独立的。(也就是说,只要把SPP放在最后一层卷积层后面,对网络的结构是没有影响的, 它只是替换了原来的pooling层)
4、不仅可以用于图像分类而且可以用来目标检测
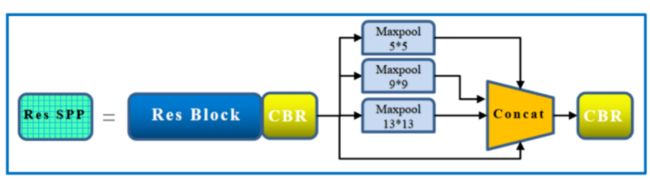
通过spp模块实现局部特征和全局特征(所以空间金字塔池化结构的最大的池化核要尽可能的接近等于需要池化的featherMap的大小)的featherMap级别的融合,丰富最终特征图的表达能力,从而提高MAP。
其代码如下:
class SPP(nn.Layer):
def __init__(self, ch_in, ch_out, k, pool_size, act='swish', data_format='NCHW'):
super(SPP, self).__init__()
self.pool = []
self.data_format = data_format
for i, size in enumerate(pool_size):
pool = self.add_sublayer('pool{}'.format(i), nn.MaxPool2D(kernel_size=size, stride=1, padding=size // 2, data_format=data_format, ceil_mode=False))
self.pool.append(pool)
self.conv = ConvBNLayer(ch_in, ch_out, k, padding=k // 2, act=act)
def forward(self, x):
outs = [x]
for pool in self.pool:
outs.append(pool(x))
if self.data_format == 'NCHW':
y = paddle.concat(outs, axis=1)
else:
y = paddle.concat(outs, axis=-1)
y = self.conv(y)
return y
二、Neck
yoloe的neck结构采用的依旧是FPN+PAN结构模式,这里就不再介绍。
三、Head
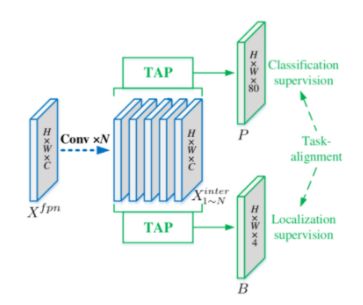
对于PP-YOLOE的head部分,其依旧是TOOD的head,也就是T-Head,主要是包括了Cls Head和Loc Head。具体来说,T-head首先在FPN特征基础上进行分类与定位预测;然后TAL基于所提任务对齐测度计算任务对齐信息;最后T-head根据从TAL传回的信息自动调整分类概率与定位预测。
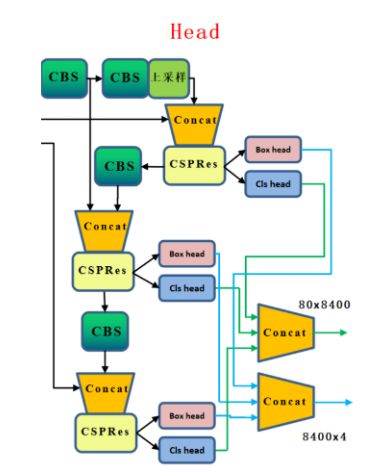
由于2个任务的预测都是基于这个交互特征来完成的,但是2个任务对于特征的需求肯定是不一样的,因为作者设计了一个layer attention来为每个任务单独的调整一下特征,这个部分的结构也很简单,可以理解为是一个channel-wise的注意力机制。这样的话就得到了对于每个任务单独的特征,然后再利用这些特征生成所需要的类别或者定位的特征图。
class PPYOLOEHead(nn.Layer):
__shared__ = ['num_classes', 'trt', 'exclude_nms']
__inject__ = ['static_assigner', 'assigner', 'nms']
def __init__(self,
in_channels=[1024, 512, 256],
num_classes=80,
act='swish',
fpn_strides=(32, 16, 8),
grid_cell_scale=5.0,
grid_cell_offset=0.5,
reg_max=16,
static_assigner_epoch=4,
use_varifocal_loss=True,
static_assigner='ATSSAssigner',
assigner='TaskAlignedAssigner',
nms='MultiClassNMS',
eval_input_size=[],
loss_weight={'class': 1.0, 'iou': 2.5, 'dfl': 0.5,},
trt=False,
exclude_nms=False):
super(PPYOLOEHead, self).__init__()
assert len(in_channels) > 0, "len(in_channels) should > 0"
self.in_channels = in_channels
self.num_classes = num_classes
self.fpn_strides = fpn_strides
self.grid_cell_scale = grid_cell_scale
self.grid_cell_offset = grid_cell_offset
self.reg_max = reg_max
self.iou_loss = GIoULoss()
self.loss_weight = loss_weight
self.use_varifocal_loss = use_varifocal_loss
self.eval_input_size = eval_input_size
self.static_assigner_epoch = static_assigner_epoch
self.static_assigner = static_assigner
self.assigner = assigner
self.nms = nms
self.exclude_nms = exclude_nms
# stem
self.stem_cls = nn.LayerList()
self.stem_reg = nn.LayerList()
act = get_act_fn(act, trt=trt) if act is None or isinstance(act, (str, dict)) else act
for in_c in self.in_channels:
self.stem_cls.append(ESEAttn(in_c, act=act))
self.stem_reg.append(ESEAttn(in_c, act=act))
# pred head
self.pred_cls = nn.LayerList()
self.pred_reg = nn.LayerList()
for in_c in self.in_channels:
self.pred_cls.append(nn.Conv2D(in_c, self.num_classes, 3, padding=1))
self.pred_reg.append(nn.Conv2D(in_c, 4 * (self.reg_max + 1), 3, padding=1))
# projection conv
self.proj_conv = nn.Conv2D(self.reg_max + 1, 1, 1, bias_attr=False)
self._init_weights()
@classmethod
def from_config(cls, cfg, input_shape):
return {'in_channels': [i.channels for i in input_shape], }
def forward_train(self, feats, targets):
anchors, anchor_points, num_anchors_list, stride_tensor = generate_anchors_for_grid_cell(feats, self.fpn_strides, self.grid_cell_scale, self.grid_cell_offset)
cls_score_list, reg_distri_list = [], []
for i, feat in enumerate(feats):
avg_feat = F.adaptive_avg_pool2d(feat, (1, 1))
cls_logit = self.pred_cls[i](self.stem_cls[i](feat, avg_feat) + feat)
reg_distri = self.pred_reg[i](self.stem_reg[i](feat, avg_feat))
# cls and reg
cls_score = F.sigmoid(cls_logit)
cls_score_list.append(cls_score.flatten(2).transpose([0, 2, 1]))
reg_distri_list.append(reg_distri.flatten(2).transpose([0, 2, 1]))
cls_score_list = paddle.concat(cls_score_list, axis=1)
reg_distri_list = paddle.concat(reg_distri_list, axis=1)
return self.get_loss([cls_score_list, reg_distri_list, anchors, anchor_points, num_anchors_list, stride_tensor], targets)
def forward_eval(self, feats):
if self.eval_input_size:
anchor_points, stride_tensor = self.anchor_points, self.stride_tensor
else:
anchor_points, stride_tensor = self._generate_anchors(feats)
cls_score_list, reg_dist_list = [], []
for i, feat in enumerate(feats):
b, _, h, w = feat.shape
l = h * w
avg_feat = F.adaptive_avg_pool2d(feat, (1, 1))
cls_logit = self.pred_cls[i](self.stem_cls[i](feat, avg_feat) + feat)
reg_dist = self.pred_reg[i](self.stem_reg[i](feat, avg_feat))
reg_dist = reg_dist.reshape([-1, 4, self.reg_max + 1, l]).transpose([0, 2, 1, 3])
reg_dist = self.proj_conv(F.softmax(reg_dist, axis=1))
# cls and reg
cls_score = F.sigmoid(cls_logit)
cls_score_list.append(cls_score.reshape([b, self.num_classes, l]))
reg_dist_list.append(reg_dist.reshape([b, 4, l]))
cls_score_list = paddle.concat(cls_score_list, axis=-1)
reg_dist_list = paddle.concat(reg_dist_list, axis=-1)
return cls_score_list, reg_dist_list, anchor_points, stride_tensor
def forward(self, feats, targets=None):
assert len(feats) == len(self.fpn_strides), "The size of feats is not equal to size of fpn_strides"
if self.training:
return self.forward_train(feats, targets)
else:
return self.forward_eval(feats)
样本匹配
ATSS Assigner:
ATSS论文指出One-Stage Anchor-Based和Center-Based Anchor-Free检测算法间的差异主要来自于正负样本的选择,基于此提出ATSS(Adaptive Training Sample Selection)方法,该方法能够自动根据GT的相关统计特征选择合适的Anchor Box作为正样本,在不带来额外计算量和参数的情况下,能够大幅提升模型的性能。
ATSS选取正样本的方法如下:其简要流程为:
1、计算每个 gt bbox 和多尺度输出层的所有 anchor 之间的 IoU
2、计算每个 gt bbox 中心坐标和多尺度输出层的所有 anchor 中心坐标的 l2 距离
3、遍历每个输出层,遍历每个 gt bbox,找出当前层中 topk (超参,默认是 9 )个最小 l2 距离的 anchor 。假设一共有 l 个输出层,那么对于任何一个 gt bbox,都会挑选出 topk×l 个候选位置
4、对于每个 gt bbox,计算所有候选位置 IoU 的均值和标准差,两者相加得到该 gt bbox 的自适应阈值
5、遍历每个 gt bbox,选择出候选位置中 IoU 大于阈值的位置,该位置认为是正样本,负责预测该 gt bbox
如果 topk 参数设置过大,可能会导致某些正样本位置不在 gt bbox 内部,故需要过滤掉这部分正样本,设置为背景样本
ATSS主要2大特性:
1、保证了所有的正样本Anchor都是在Ground Truth的周围。
2、最主要是根据不同层的特性对不同层的正样本的阈值进行了微调。
ATSS的贡献:
1、指出Anchor-Base检测器和Anchor-Free检测器之间的本质区别实际上是如何定义正训练样本和负训练样本;
2、提出自适应训练样本选择,以根据目标的统计特征自动选择正负样本;
3、证明了在图像上的每个位置上平铺多个Anchor来提升检测的性能是没效果的;
其代码如下:
class ATSSAssigner(nn.Layer):
"""Bridging the Gap Between Anchor-based and Anchor-free Detection
via Adaptive Training Sample Selection
"""
__shared__ = ['num_classes']
def __init__(self, topk=9, num_classes=80, force_gt_matching=False, eps=1e-9):
super(ATSSAssigner, self).__init__()
self.topk = topk
self.num_classes = num_classes
self.force_gt_matching = force_gt_matching
self.eps = eps
def _gather_topk_pyramid(self, gt2anchor_distances, num_anchors_list, pad_gt_mask):
pad_gt_mask = pad_gt_mask.tile([1, 1, self.topk]).astype(paddle.bool)
gt2anchor_distances_list = paddle.split(gt2anchor_distances, num_anchors_list, axis=-1)
num_anchors_index = np.cumsum(num_anchors_list).tolist()
num_anchors_index = [0, ] + num_anchors_index[:-1]
is_in_topk_list = []
topk_idxs_list = []
for distances, anchors_index in zip(gt2anchor_distances_list, num_anchors_index):
num_anchors = distances.shape[-1]
topk_metrics, topk_idxs = paddle.topk(distances, self.topk, axis=-1, largest=False)
topk_idxs_list.append(topk_idxs + anchors_index)
topk_idxs = paddle.where(pad_gt_mask, topk_idxs, paddle.zeros_like(topk_idxs))
is_in_topk = F.one_hot(topk_idxs, num_anchors).sum(axis=-2)
is_in_topk = paddle.where(is_in_topk > 1, paddle.zeros_like(is_in_topk), is_in_topk)
is_in_topk_list.append(is_in_topk.astype(gt2anchor_distances.dtype))
is_in_topk_list = paddle.concat(is_in_topk_list, axis=-1)
topk_idxs_list = paddle.concat(topk_idxs_list, axis=-1)
return is_in_topk_list, topk_idxs_list
@paddle.no_grad()
def forward(self, anchor_bboxes, num_anchors_list, gt_labels, gt_bboxes, pad_gt_mask, bg_index, gt_scores=None, pred_bboxes=None):
"""
ATSS匹配步骤如下:
1. 计算所有预测bbox与GT之间的IoU
2. 计算所有预测bbox与GT之间的距离
3. 在每个pyramid level上,对于每个gt,选择k个中心距离gt中心最近的bbox,总共选择k*l个bbox作为每个gt的候选框
4. 获取这些候选框对应的iou,计算mean和std,设 mean + std为 iou 阈值
5. 选择iou大于或等于阈值的样本为正样本
6. 将正样本的中心限制在gt内
7. 如果Anchor框被分配到多个gts,则选择具有最高的IoU的那个。
Args:
anchor_bboxes (Tensor, float32): pre-defined anchors, shape(L, 4),
"xmin, xmax, ymin, ymax" format
num_anchors_list (List): num of anchors in each level
gt_labels (Tensor, int64|int32): Label of gt_bboxes, shape(B, n, 1)
gt_bboxes (Tensor, float32): Ground truth bboxes, shape(B, n, 4)
pad_gt_mask (Tensor, float32): 1 means bbox, 0 means no bbox, shape(B, n, 1)
bg_index (int): background index
gt_scores (Tensor|None, float32) Score of gt_bboxes,
shape(B, n, 1), if None, then it will initialize with one_hot label
pred_bboxes (Tensor, float32, optional): predicted bounding boxes, shape(B, L, 4)
Returns:
assigned_labels (Tensor): (B, L)
assigned_bboxes (Tensor): (B, L, 4)
assigned_scores (Tensor): (B, L, C), if pred_bboxes is not None, then output ious
"""
assert gt_labels.ndim == gt_bboxes.ndim and gt_bboxes.ndim == 3
num_anchors, _ = anchor_bboxes.shape
batch_size, num_max_boxes, _ = gt_bboxes.shape
# 1. 计算所有预测bbox与GT之间的IoU, [B, n, L]
ious = iou_similarity(gt_bboxes.reshape([-1, 4]), anchor_bboxes)
ious = ious.reshape([batch_size, -1, num_anchors])
# 2. 计算所有预测bbox与GT之间的距离, [B, n, L]
gt_centers = bbox_center(gt_bboxes.reshape([-1, 4])).unsqueeze(1)
anchor_centers = bbox_center(anchor_bboxes)
gt2anchor_distances = (gt_centers - anchor_centers.unsqueeze(0)).norm(2, axis=-1).reshape([batch_size, -1, num_anchors])
# 3. 在每个pyramid level上,对于每个gt,选择k个中心距离gt中心最近的bbox,总共选择k*l个bbox作为每个gt的候选框
# based on the center distance, [B, n, L]
is_in_topk, topk_idxs = self._gather_topk_pyramid(gt2anchor_distances, num_anchors_list, pad_gt_mask)
# 4. 获取这些候选框对应的iou,计算mean和std,设 mean + std为 iou 阈值
iou_candidates = ious * is_in_topk
iou_threshold = paddle.index_sample(iou_candidates.flatten(stop_axis=-2), topk_idxs.flatten(stop_axis=-2))
iou_threshold = iou_threshold.reshape([batch_size, num_max_boxes, -1])
iou_threshold = iou_threshold.mean(axis=-1, keepdim=True) + iou_threshold.std(axis=-1, keepdim=True)
is_in_topk = paddle.where(iou_candidates > iou_threshold.tile([1, 1, num_anchors]), is_in_topk, paddle.zeros_like(is_in_topk))
# 6. 将正样本的中心限制在gt内, [B, n, L]
is_in_gts = check_points_inside_bboxes(anchor_centers, gt_bboxes)
# 选择正样本, [B, n, L]
mask_positive = is_in_topk * is_in_gts * pad_gt_mask
# 7. 如果Anchor框被分配到多个gts,则选择具有最高的IoU的那个。
mask_positive_sum = mask_positive.sum(axis=-2)
if mask_positive_sum.max() > 1:
mask_multiple_gts = (mask_positive_sum.unsqueeze(1) > 1).tile([1, num_max_boxes, 1])
is_max_iou = compute_max_iou_anchor(ious)
mask_positive = paddle.where(mask_multiple_gts, is_max_iou, mask_positive)
mask_positive_sum = mask_positive.sum(axis=-2)
# 8. 确认每个gt_bbox 都匹配到了 anchor
if self.force_gt_matching:
is_max_iou = compute_max_iou_gt(ious) * pad_gt_mask
mask_max_iou = (is_max_iou.sum(-2, keepdim=True) == 1).tile([1, num_max_boxes, 1])
mask_positive = paddle.where(mask_max_iou, is_max_iou, mask_positive)
mask_positive_sum = mask_positive.sum(axis=-2)
assigned_gt_index = mask_positive.argmax(axis=-2)
# 匹配目标
batch_ind = paddle.arange(end=batch_size, dtype=gt_labels.dtype).unsqueeze(-1)
assigned_gt_index = assigned_gt_index + batch_ind * num_max_boxes
assigned_labels = paddle.gather(gt_labels.flatten(), assigned_gt_index.flatten(), axis=0)
assigned_labels = assigned_labels.reshape([batch_size, num_anchors])
assigned_labels = paddle.where(mask_positive_sum > 0, assigned_labels, paddle.full_like(assigned_labels, bg_index))
assigned_bboxes = paddle.gather(gt_bboxes.reshape([-1, 4]), assigned_gt_index.flatten(), axis=0)
assigned_bboxes = assigned_bboxes.reshape([batch_size, num_anchors, 4])
assigned_scores = F.one_hot(assigned_labels, self.num_classes)
if pred_bboxes is not None:
# assigned iou
ious = batch_iou_similarity(gt_bboxes, pred_bboxes) * mask_positive
ious = ious.max(axis=-2).unsqueeze(-1)
assigned_scores *= ious
elif gt_scores is not None:
gather_scores = paddle.gather(gt_scores.flatten(), assigned_gt_index.flatten(), axis=0)
gather_scores = gather_scores.reshape([batch_size, num_anchors])
gather_scores = paddle.where(mask_positive_sum > 0, gather_scores, paddle.zeros_like(gather_scores))
assigned_scores *= gather_scores.unsqueeze(-1)
return assigned_labels, assigned_bboxes, assigned_scores
Task-aligned Assigner思想(TOOD)
TOOD提出了Task Alignment Learning (TAL) 来显式的把2个任务的最优Anchor拉近。这是通过设计一个样本分配策略和任务对齐loss来实现的。样本分配计算每个Anchor的任务对齐度,同时任务对齐loss可以逐步将分类和定位的最佳Anchor统一起来。
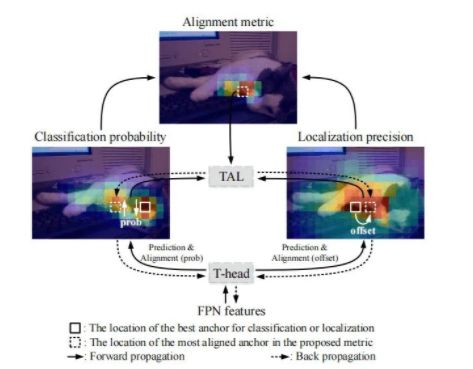
本文所提TOOD采用了类似的架构:Backbone-FPN-Head。考虑到效率与简单性,与类似ATSS, TOOD在每个位置放置一个Anchor。正如所讨论的,由于分类与定位任务的发散性,现有One-Stage检测器存在任务不对齐(Task Mis-Alignment)约束问题。本文提出通过显式方式采用T-head+TAL对2个任务进行对齐,见上图。T-head与TAL通过协同工作方式改善2个任务的对齐问题;
TOOD选取样本的方法具体来说:
1、首先,T-head在FPN特征基础上进行分类与定位预测;
2、然后,TAL基于所提任务对齐测度计算任务对齐信息;
3、最后,T-head根据从TAL传回的信息自动调整分类概率与定位预测
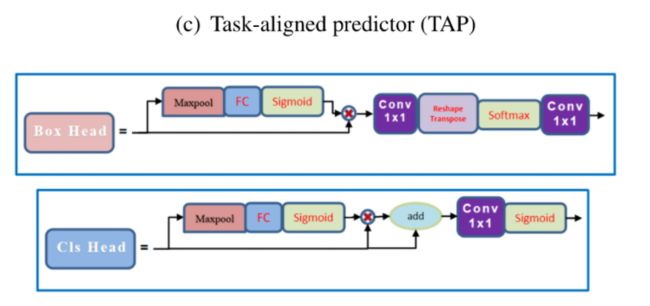
Task-Aligned Head
其结构图如下:它具有非常简单的结构:特征提取器+TAP。

为增强分类与定位之间的相互作用,作者通过特征提取器学习任务交互(Task-Interactive)特征,如中蓝色框部分。这种设计不仅有助于任务交互,同时可以为2个任务提供多级多尺度特征。
假设X表示FPN特征,特征提取器采用N个连续卷积计算任务交互特征:

因此,通过特征提取器可以得到丰富的多尺度特征并用于送入到后续2个TAP模块中进行分类与定位对齐。
Task-Aligned Sample Assignment
为与NMS搭配,训练样例的Anchor分配需要满足以下规则:
1、正常对齐的Anchor应当可以预测高分类得分,同时具有精确定位;
2、不对齐的Anchor应当具有低分类得分,并在NMS阶段被抑制。
基于上述两个规则,作者设计了一种新的Anchor对齐度量以显式度量Anchor层面的对齐度。该对齐度量将集成到样本分配与损失函数中以动态提炼每个Anchor的预测。
Anchor Alignment metric 考虑到分类得分与IoU表征了预测质量,作者采用2者的高阶组合度量任务对齐度,公式定义如下:
![]()
其中,s与u分别表示分类得分与IoU值,而 α , β \alpha,\beta α,β用于控制两者的影响。因此,t在联合优化中起着非常重要的作用,它激励网络动态的聚焦于高质量的Anchor上。训练样例分配对于检测器的训练非常重要。
为提升两个任务的对齐性,TOOD聚焦于任务对齐Anchor,采用一种简单的分配规则选择训练样本:对每个实例,选择m个具有最大t值的Anchor作为正样例,选择其余的Anchor作为负样例。然后,通过新的损失函数(针对分类与定位的对齐而设计的损失函数)任务进行训练。
其代码如下:
class TaskAlignedAssigner(nn.Layer):
def __init__(self, topk=13, alpha=1.0, beta=6.0, eps=1e-9):
super(TaskAlignedAssigner, self).__init__()
self.topk = topk
self.alpha = alpha
self.beta = beta
self.eps = eps
@paddle.no_grad()
def forward(self, pred_scores, pred_bboxes, anchor_points, num_anchors_list, gt_labels, gt_bboxes, pad_gt_mask, bg_index, gt_scores=None):
"""
Task-Aligned Assigner计算步骤如下:
1. 计算所有 bbox与 gt 之间的对齐度
2. 选择 top-k bbox 作为每个 gt 的候选项
3. 将正样品的中心限制在 gt 内(因为Anchor-Free检测器只能预测大于0的距离)
4. 如果一个Anchor被分配给多个gt,将选择IoU最高的那个。
Args:
pred_scores (Tensor, float32): predicted class probability, shape(B, L, C)
pred_bboxes (Tensor, float32): predicted bounding boxes, shape(B, L, 4)
anchor_points (Tensor, float32): pre-defined anchors, shape(L, 2), "cxcy" format
num_anchors_list (List): num of anchors in each level, shape(L)
gt_labels (Tensor, int64|int32): Label of gt_bboxes, shape(B, n, 1)
gt_bboxes (Tensor, float32): Ground truth bboxes, shape(B, n, 4)
pad_gt_mask (Tensor, float32): 1 means bbox, 0 means no bbox, shape(B, n, 1)
bg_index (int): background index
gt_scores (Tensor|None, float32) Score of gt_bboxes, shape(B, n, 1)
Returns:
assigned_labels (Tensor): (B, L)
assigned_bboxes (Tensor): (B, L, 4)
assigned_scores (Tensor): (B, L, C)
"""
assert pred_scores.ndim == pred_bboxes.ndim
assert gt_labels.ndim == gt_bboxes.ndim and gt_bboxes.ndim == 3
batch_size, num_anchors, num_classes = pred_scores.shape
_, num_max_boxes, _ = gt_bboxes.shape
# 计算GT与预测box之间的iou, [B, n, L]
ious = iou_similarity(gt_bboxes, pred_bboxes)
# 获取预测bboxes class score
pred_scores = pred_scores.transpose([0, 2, 1])
batch_ind = paddle.arange(end=batch_size, dtype=gt_labels.dtype).unsqueeze(-1)
gt_labels_ind = paddle.stack([batch_ind.tile([1, num_max_boxes]), gt_labels.squeeze(-1)], axis=-1)
bbox_cls_scores = paddle.gather_nd(pred_scores, gt_labels_ind)
# 计算bbox与 gt 之间的对齐度, [B, n, L]
alignment_metrics = bbox_cls_scores.pow(self.alpha) * ious.pow(self.beta)
# check the positive sample's center in gt, [B, n, L]
is_in_gts = check_points_inside_bboxes(anchor_points, gt_bboxes)
# 选择 top-k 预测 bbox 作为每个 gt 的候选项
is_in_topk = gather_topk_anchors(alignment_metrics * is_in_gts, self.topk, topk_mask=pad_gt_mask.tile([1, 1, self.topk]).astype(paddle.bool))
# select positive sample, [B, n, L]
mask_positive = is_in_topk * is_in_gts * pad_gt_mask
# 如果一个Anchor被分配给多个gt,将选择IoU最高的那个, [B, n, L]
mask_positive_sum = mask_positive.sum(axis=-2)
if mask_positive_sum.max() > 1:
mask_multiple_gts = (mask_positive_sum.unsqueeze(1) > 1).tile([1, num_max_boxes, 1])
is_max_iou = compute_max_iou_anchor(ious)
mask_positive = paddle.where(mask_multiple_gts, is_max_iou, mask_positive)
mask_positive_sum = mask_positive.sum(axis=-2)
assigned_gt_index = mask_positive.argmax(axis=-2)
# assigned target
assigned_gt_index = assigned_gt_index + batch_ind * num_max_boxes
assigned_labels = paddle.gather(gt_labels.flatten(), assigned_gt_index.flatten(), axis=0)
assigned_labels = assigned_labels.reshape([batch_size, num_anchors])
assigned_labels = paddle.where(mask_positive_sum > 0, assigned_labels, paddle.full_like(assigned_labels, bg_index))
assigned_bboxes = paddle.gather(gt_bboxes.reshape([-1, 4]), assigned_gt_index.flatten(), axis=0)
assigned_bboxes = assigned_bboxes.reshape([batch_size, num_anchors, 4])
assigned_scores = F.one_hot(assigned_labels, num_classes)
# rescale alignment metrics
alignment_metrics *= mask_positive
max_metrics_per_instance = alignment_metrics.max(axis=-1, keepdim=True)
max_ious_per_instance = (ious * mask_positive).max(axis=-1, keepdim=True)
alignment_metrics = alignment_metrics / (max_metrics_per_instance + self.eps) * max_ious_per_instance
alignment_metrics = alignment_metrics.max(-2).unsqueeze(-1)
assigned_scores = assigned_scores * alignment_metrics
return assigned_labels, assigned_bboxes, assigned_scores
四、损失函数
分类损失varifocal loss
Focal loss定义:
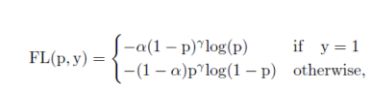
其中 α \alpha α是前景背景的损失权重,p的 Υ \Upsilon Υ次是不同样本的权重,难分样本的损失权重会增大。当训练一个密集的物体检测器使连续的IACS回归时,本文从focal loss中借鉴了样本加权思想来解决类不平衡问题。但是,与focal loss同等对待正负样本的损失不同,而varifocal loss选择不对称地对待它们。varifocal loss定义如下:
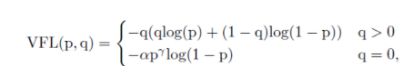
其中p是预测的IACS得分,q是目标IoU分数。对于训练中的正样本,将q设置为生成的bbox和gt box之间的IoU(gt IoU),而对于训练中的负样本,所有类别的训练目标q均为0。
备注:Varifocal Loss会预测Iou-aware Cls_score(IACS)与分类两个得分,通过p的y次来有效降低负样本损失的权重,正样本选择不降低权重。此外,通过q(Iou感知得分)来对Iou高的正样本损失加大权重,相当于将训练重点放在高质量的样本上面。
@staticmethod
def _varifocal_loss(pred_score, gt_score, label, alpha=0.75, gamma=2.0):
weight = alpha * pred_score.pow(gamma) * (1 - label) + gt_score * label
loss = F.binary_cross_entropy(pred_score, gt_score, weight=weight, reduction='sum')
return loss
回归损失
本文用的giou的回归方式,其计算细节不再介绍,代码如下:
@register
@serializable
class GIoULoss(object):
"""
Generalized Intersection over Union, see https://arxiv.org/abs/1902.09630
Args:
loss_weight (float): giou loss weight, default as 1
eps (float): epsilon to avoid divide by zero, default as 1e-10
reduction (string): Options are "none", "mean" and "sum". default as none
"""
def __init__(self, loss_weight=1., eps=1e-10, reduction='none'):
self.loss_weight = loss_weight
self.eps = eps
assert reduction in ('none', 'mean', 'sum')
self.reduction = reduction
def bbox_overlap(self, box1, box2, eps=1e-10):
"""calculate the iou of box1 and box2
Args:
box1 (Tensor): box1 with the shape (..., 4)
box2 (Tensor): box1 with the shape (..., 4)
eps (float): epsilon to avoid divide by zero
Return:
iou (Tensor): iou of box1 and box2
overlap (Tensor): overlap of box1 and box2
union (Tensor): union of box1 and box2
"""
x1, y1, x2, y2 = box1
x1g, y1g, x2g, y2g = box2
xkis1 = paddle.maximum(x1, x1g)
ykis1 = paddle.maximum(y1, y1g)
xkis2 = paddle.minimum(x2, x2g)
ykis2 = paddle.minimum(y2, y2g)
w_inter = (xkis2 - xkis1).clip(0)
h_inter = (ykis2 - ykis1).clip(0)
overlap = w_inter * h_inter
area1 = (x2 - x1) * (y2 - y1)
area2 = (x2g - x1g) * (y2g - y1g)
union = area1 + area2 - overlap + eps
iou = overlap / union
return iou, overlap, union
def __call__(self, pbox, gbox, iou_weight=1., loc_reweight=None):
x1, y1, x2, y2 = paddle.split(pbox, num_or_sections=4, axis=-1)
x1g, y1g, x2g, y2g = paddle.split(gbox, num_or_sections=4, axis=-1)
box1 = [x1, y1, x2, y2]
box2 = [x1g, y1g, x2g, y2g]
iou, overlap, union = self.bbox_overlap(box1, box2, self.eps)
xc1 = paddle.minimum(x1, x1g)
yc1 = paddle.minimum(y1, y1g)
xc2 = paddle.maximum(x2, x2g)
yc2 = paddle.maximum(y2, y2g)
area_c = (xc2 - xc1) * (yc2 - yc1) + self.eps
miou = iou - ((area_c - union) / area_c)
if loc_reweight is not None:
loc_reweight = paddle.reshape(loc_reweight, shape=(-1, 1))
loc_thresh = 0.9
giou = 1 - (1 - loc_thresh) * miou - loc_thresh * miou * loc_reweight
else:
giou = 1 - miou
if self.reduction == 'none':
loss = giou
elif self.reduction == 'sum':
loss = paddle.sum(giou * iou_weight)
else:
loss = paddle.mean(giou * iou_weight)
return loss * self.loss_weight
L1 loss
均绝对误差(Mean Absolute Error,MAE) 是指模型预测值f(x)和真实值y之间距离的均值,其公式如下:
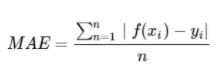
忽略下标i ,设n=1,以f(x)−y为横轴,MAE的值为纵轴,得到函数的图形如下:
MAE曲线连续,但是在y−f(x)=0处不可导。而且 MAE 大部分情况下梯度都是相等的,这意味着即使对于小的损失值,其梯度也是大的。这不利于函数的收敛和模型的学习。但是,无论对于什么样的输入值,都有着稳定的梯度,不会导致梯度爆炸问题,具有较为稳健性的解。相比于MSE,MAE有个优点就是,对于离群点不那么敏感。因为MAE计算的是误差y−f(x)的绝对值,对于任意大小的差值,其惩罚都是固定的。其接口如下:
loss_l1 = F.l1_loss(pred_bboxes_pos, assigned_bboxes_pos)
DF Loss
对于任意分布来建模框的表示,它可以用积分形式嵌入到任意已有的和框回归相关的损失函数上,例如最近比较流行的GIoU Loss。这个实际上也就够了,不过涨点不是很明显,如果分布过于任意,网络学习的效率可能会不高,原因是一个积分目标可能对应了无穷多种分布模式。如下图所示: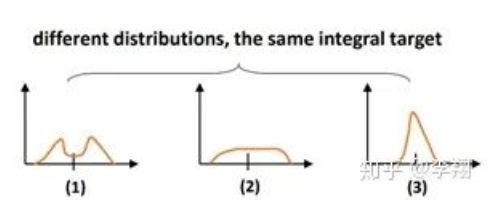
虑到真实的分布通常不会距离标注的位置太远,所以又额外加了个loss,希望网络能够快速地聚焦到标注位置附近的数值,使得他们概率尽可能大。基于此,Distribution Focal Loss (DFL):
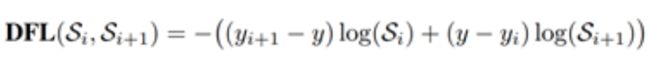
其形式上与QFL的右半部分很类似,含义是以类似交叉熵的形式去优化与标签y最接近的一左一右两个位置的概率,从而让网络快速地聚焦到目标位置的邻近区域的分布中去。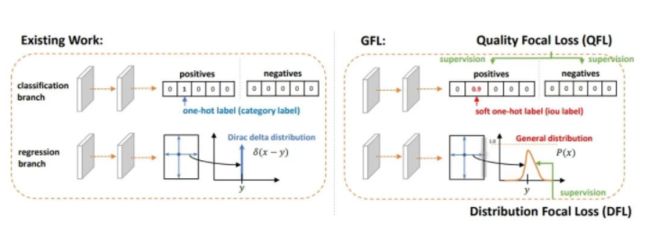
QFL和DFL的作用是正交的,他们的增益互不影响
def _df_loss(self, pred_dist, target):
target_left = paddle.cast(target, 'int64')
target_right = target_left + 1
weight_left = target_right.astype('float32') - target
weight_right = 1 - weight_left
loss_left = F.cross_entropy(pred_dist, target_left, reduction='none') * weight_left
loss_right = F.cross_entropy(pred_dist, target_right, reduction='none') * weight_right
return (loss_left + loss_right).mean(-1, keepdim=True)
总损失
其中,a表示分类损失的权重系数,b表示回归损失的权重系数,c表示DFL损失的权重系数。
def get_loss(self, head_outs, gt_meta):
pred_scores, pred_distri, anchors, anchor_points, num_anchors_list, stride_tensor = head_outs
anchor_points_s = anchor_points / stride_tensor
pred_bboxes = self._bbox_decode(anchor_points_s, pred_distri)
gt_labels = gt_meta['gt_class']
gt_bboxes = gt_meta['gt_bbox']
pad_gt_mask = gt_meta['pad_gt_mask']
# Epoch小于100使用ATSS匹配
if gt_meta['epoch_id'] < self.static_assigner_epoch:
assigned_labels, assigned_bboxes, assigned_scores = \
self.static_assigner(
anchors,
num_anchors_list,
gt_labels,
gt_bboxes,
pad_gt_mask,
bg_index=self.num_classes,
pred_bboxes=pred_bboxes.detach() * stride_tensor)
alpha_l = 0.25
else:
# Epoch大于100使用TAL匹配
assigned_labels, assigned_bboxes, assigned_scores = \
self.assigner(
pred_scores.detach(),
pred_bboxes.detach() * stride_tensor,
anchor_points,
num_anchors_list,
gt_labels,
gt_bboxes,
pad_gt_mask,
bg_index=self.num_classes)
alpha_l = -1
# rescale bbox
assigned_bboxes /= stride_tensor
# cls loss
if self.use_varifocal_loss:
one_hot_label = F.one_hot(assigned_labels, self.num_classes)
loss_cls = self._varifocal_loss(pred_scores, assigned_scores, one_hot_label)
else:
loss_cls = self._focal_loss(pred_scores, assigned_scores, alpha_l)
assigned_scores_sum = assigned_scores.sum()
if paddle_distributed_is_initialized():
paddle.distributed.all_reduce(assigned_scores_sum)
assigned_scores_sum = paddle.clip(assigned_scores_sum / paddle.distributed.get_world_size(), min=1)
loss_cls /= assigned_scores_sum
loss_l1, loss_iou, loss_dfl = self._bbox_loss(pred_distri, pred_bboxes, anchor_points_s, assigned_labels, assigned_bboxes, assigned_scores, assigned_scores_sum)
loss = self.loss_weight['class'] * loss_cls + self.loss_weight['iou'] * loss_iou + self.loss_weight['dfl'] * loss_dfl
out_dict = {
'loss': loss,
'loss_cls': loss_cls,
'loss_iou': loss_iou,
'loss_dfl': loss_dfl,
'loss_l1': loss_l1,
}
return out_dict
五、模型推理与部署
# inference single image
CUDA_VISIBLE_DEVICES=0 python tools/infer.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams --infer_img=demo/000000014439_640x640.jpg
# inference all images in the directory
CUDA_VISIBLE_DEVICES=0 python tools/infer.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams --infer_dir=demo
导出ONNX
# export inference model
python tools/export_model.py configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml --output_dir=output_inference -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams
# install paddle2onnx
pip install paddle2onnx
# convert to onnx
paddle2onnx --model_dir output_inference/ppyoloe_crn_l_300e_coco --model_filename model.pdmodel --params_filename model.pdiparams --opset_version 11 --save_file ppyoloe_crn_l_300e_coco.onnx
导出TensorRT Engine
python tools/export_model.py configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams -o trt=True
原文为:https://www.eet-china.com/mp/a120559.html。感谢作者的分享!