【深度学习】常见的神经网络层(下)
博客首页:knighthood2001
欢迎点赞评论️
❤️ 热爱python,期待与大家一同进步成长!!❤️
给大家推荐一款很火爆的刷题、面试求职网站
【深度学习】常见的神经网络层(上)
之前的文章讲述了全连接层、二维卷积层、池化层,
接下来继续讲解常见的神经网络层(BN层、dropout层、flatten层)。
目录
1、BN层
函数定义
参数含义
2.dropout层
函数定义
参数含义
调用参数
举例
3、flatten层
函数定义
参数含义
举例
4、总结
1、BN层
BN层即Batch Normalization层,称为批量标准化层。这是一种优化深度学习神经网络层的方式。
在训练神经网络时,对输入数据进行标准化可以提高网络训练的速度。通常我们的做法就是在输入训练数据时,对输入样本进行归一化处理 ,例如min-max标准化、Z- score等。而对于神经网络结构,我们可以将其划分为3个部分,即输入层、输出层和隐藏层,其中隐藏层也就是夹杂在输入层和输出层中间的所有网络层的统称。对于输入层数据,直接在数据的预处理阶段进行归一化就可以了。 BN层的提出就是争对隐藏层的数据,将其进行标准化处理。
深度学习神经网络在训练时,是按照每个批次(batch)依次进行训练的,设定每次训练时批次大小的参数由模型的fit()方法中batch_size 参数所指定。BN层对训练中每一个批次的数据进行处理,使其平均值接近0,标准差接近1。这个数据既可以是输入,也可以是网络中某一层的输出。 例如:BN层在每一个处理批次中,将前一层的激活值(ativations) 进行标准化处理。
函数定义
keras为我们提供了BN层的实现,其定义如下:
keras.layers.BatchNormalization(axis=-1,momentum=0.99,epsilon=1e-3,center=True, scale=True,beta_initializer='zeros',gamma_initializer='ones',moving_mean_initializer='zeros',moving_variance_initializer='ones',beta_regularizer=None,gamma_regularizer=None,beta_constraint=None,gamma_constraint=None,renorm=False,renorm_clipping=None,renorm_momentum=0.99,fused=None,trainable=True,virtual_batch_size=None, adjustment=None,name=None,**kwargs)
参数含义
axis=-1:整数或整数列表,应归一化(标准化)的轴(通常是特征轴)。例如,在具有 data_format="channels_first"的Conv2D层之后,在BatchNormalization中设置axis=1。 momentum=0.99:超参数,移动均值和移动方差的动量值。 epsilon=1e-3:将小浮点数添加到方差中以避免除以零。 center=True:如果为 True,则将β的偏移量添加到归一化(标准化)张量。如果为 False,则忽略。 scale=True:缩放,如果为True,乘以γ。如果为 False,则不使用γ。当下一层是线性的(例如nn.relu)时,可以禁用此功能,因为缩放将由下一层完成。 beta_initializer='zeros':Beta (β)权重的初始化程序。 gamma_initializer='ones':gamma(γ)权重的初始化程序。 moving_mean_initializer='zeros':移动均值的初始化器。 moving_variance_initializer='ones':移动方差的初始化程序。 beta_regularizer=None:beta 权重的可选正则化器。 gamma_regularizer=None:gamma 权重的可选正则化器。 beta_constraint=None:Beta 权重的可选约束。 gamma_constraint=None:gamma 权重的可选约束。 renorm=False:是否使用[Batch Renormalization]。这在训练期间增加了额外的变量。对于此参数的任一值,推断都是相同的。 renorm_clipping=None:一个字典,可以将键 'rmax'、'rmin'、'dmax' 映射到用于裁剪 renorm 校正的标量 Tensors。校正 (r, d) 用作 corrected_value = normalized_value r + d,r被剪裁为 [rmin, rmax],而d被剪裁为 [-dmax, dmax]。缺失的rmax、rmin、dmax分别设置为inf、0、inf。 renorm_momentum=0.99:用于使用 renorm 更新移动均值和标准差的动量。与“动量”不同,这会影响训练,并且既不能太小(会增加噪音)也不能太大(会给出陈旧的估计)。请注意,“动量”仍用于获取推理的均值和方差。 fused=None:如果为“True”,则使用更快的融合实现,如果无法使用融合实现,则引发 ValueError。如果为“False”,请尽可能使用更快的实现。如果为 False,则不要使用融合实现。 trainable=True:布尔值,如果 `True` 变量将被标记为可训练。 virtual_batch_size=None:一个`int`。默认情况下,`virtual_batch_size` 为 `None`,这意味着在整个批次中执行批次标准化。当 `virtual_batch_size` 不是 `None` 时,改为执行“Ghost Batch Normalization”,这会创建每个单独标准化的虚拟子批次(具有共享的 gamma、beta 和移动统计信息)。执行过程中必须除以实际的batch size。 adjustment=None:仅在训练期间采用包含输入张量的(动态)形状的“张量”并返回一对(比例,偏差)以应用于归一化值(γ和β之前)的函数。
调用参数
inputs: 输入张量(任何等级)。training:Python 布尔值,指示层应该在训练模式还是推理模式下运行。 training=True:该层将使用当前批次输入的均值和方差对其输入进行归一化。 training=False:该层将使用在训练期间学习的移动统计数据的均值和方差对其输入进行归一化。Input shape: 随意的。将此层用作模型中的第一层时,请使用关键字参数“input_shape”(整数元组,不包括样本轴)。Output shape:与input的形状相同。
2.dropout层
在前面我们提到过,对于全连接层来讲,它有一个非常大的弊端,那就是参数量会很大,非常容易造成过拟合现象。因此提出了dropout层,即在深度学习网络的训练过程中,对于每一个全连接层的神经网络单元,按照一定的概率将其暂时从网络中丢弃。由于是随机地丢弃,故而每一个批次(mini-batch)都在训练不同的网络,从而增加了网络的健壮性,减少了过拟合现象的发生。
值得一提的是, dropout 层是随机选择断开全连接层中每个神经网络单元之间的连接的,即每次断开的连接都是不一样的。我们能够设置dropout 层的参数,来选择断开连接的比例。Keras为我们实现了dropout层。Keras的实现机制是在神经网络训练中每次数据更新时,将全连接层的输入单元按比率随机地设置为0,这样就相当于断开了神经网络单元之间的连接。
函数定义
Keras 的dropout层的定义如下:
keras.layers.Dropout(rate, noise_shape=None, seed=None)
参数含义
rate: 0~1 的浮点数。要删除的输入单位的分数(指定需要断开连接的比例)。 noise_shape:表示将与输入数据相乘的二进制dropout掩层的形状,一般默认即可。例如,如果您的输入具有形状 (batch_size, timesteps, features),并且您希望所有时间步的 dropout 掩码都相同,则可以使用 noise_shape=(batch_size, 1, features)。 seed:生成随机数的随机数种子数。
函数讲解:Dropout 层在训练期间的每一步以“rate”的频率将输入单元随机设置为 0,这有助于防止过度拟合。未设置为 0 的输入按 1(1 - 比率)按比例放大,以使所有输入的总和保持不变。请注意,Dropout 层仅在 `training` 设置为 True 时适用,这样在推理过程中不会丢弃任何值。使用 `model.fit` 时,`training` 会自动适当地设置为 True,而在其他情况下,您可以在调用层时将 kwarg 显式设置为 True。 (这与为 Dropout 层设置 `trainable=False` 形成对比。`trainable` 不会影响层的行为,因为 Dropout 没有任何可以在训练期间冻结的变量权重。)
调用参数
inputs: 输入张量(任何等级)。 training:Python 布尔值,指示层应该在训练模式(添加 dropout)还是在推理模式(什么都不做)下运行。
举例
import numpy as np
import tensorflow as tf
tf.random.set_seed(0)
layer = tf.keras.layers.Dropout(.2, input_shape=(2,))
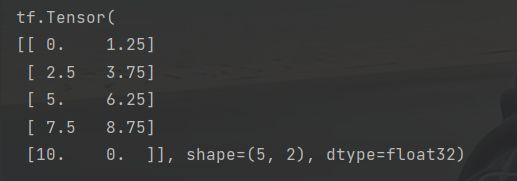
data = np.arange(10).reshape(5, 2).astype(np.float32)
print(data)
outputs = layer(data, training=True)
print(outputs)结果如下:

3、flatten层
flatten层比较容易理解,就是将输入数据展平,它不影响批量的大小 。我们一般将flatten层放置在卷积层和全连接层中间,起到一个转换的作用。因为卷积层输出结果时二维张量,经过卷积层后会输出多个特征图,需要将这些特征图转换成向量序列的形式, 才能与全连接层一一对应。
函数定义
keras为我们提供了flatten层的定义:
keras.layers.Flatten(data_format=None)
参数含义
data_format: 字符串,`channels_last`(默认)或`channels_first`之一。输入中维度的排序。 `channels_last` 对应于形状为 `(batch, ..., channels)` 的输入,而 `channels_first` 对应于形状为 `(batch, channels, ...)` 的输入。它默认为您的 Keras 配置文件 `~.keraskeras.json` 中的 `image_data_format` 值。如果您从未设置它,那么它将是“channels_last”。
这里讲解一下channel_last和channel_first的区别,channel翻译过来就是通道的意思, channel_last则表示通道放最后, channel_first则表示通道放最前。举个例子:如果输入的图像是32 x32大小的RCB图像,输入数据的格式(即image_data_format参数)是channels_first,所以图像通道数值3位于channel元组的第1个位置处。
举例
import tensorflow as tf
from keras.layers import Flatten
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(64, 3, 3, input_shape=(3, 32, 32), padding='same'))
print(model.output_shape)
model.add(Flatten())
print(model.output_shape)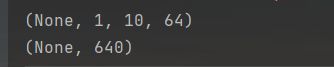
在这个例子中我们能够看到,输入的图像是32 x32大小的RCB图像,输入数据的格式(即image_data_format 参数)是channels_first,所以图像通道数值3位于元组的第1个位置处。由于这个卷积层的padding参数是same(补零),因此输出结果的尺寸是(None, 64, 32, 32),其中None代表训练模型时批次的大小,即batch_ size 参数的大小,这个参数由训练时指定,并不固定,故此处不需要考虑。这个输出结果表明,由64 个卷积核生成了64个特征图,接下来的flatten层将这些特征图进行转换,将其向量化(也可以类比为把这些特征图中的数值加入一个数组中),因此经过flatten 层输出后的向量尺寸是65356,即64x32x32的结果。
4、总结
至此,常见的神经网络层就讲完了,感谢大家的支持。❤️❤️❤️