TOP 100值得读的图神经网络----自监督学习与预训练
清华大学的Top 100 GNN papers,其中分了十个方向,每个方向10篇。此篇为自监督学习与预训练方向的阅读笔记。
Top100值得一读的图神经网络| 大家好,我是蘑菇先生,今天带来Top100 GNN Papers盘点文。此外,公众号技术交流群开张啦!可 https://mp.weixin.qq.com/s?__biz=MzIyNDY5NjEzNQ==&mid=2247491631&idx=1&sn=dfa36e829a84494c99bb2d4f755717d6&chksm=e809a207df7e2b1117578afc86569fa29ee62eb883fd35428888c0cc0be750faa5ef091f9092&mpshare=1&scene=23&srcid=1026NUThrKm2Vioj874F3gqS&sharer_sharetime=1635227630762&sharer_shareid=80f244b289da8c80b67c915b10efd0a8#rd
https://mp.weixin.qq.com/s?__biz=MzIyNDY5NjEzNQ==&mid=2247491631&idx=1&sn=dfa36e829a84494c99bb2d4f755717d6&chksm=e809a207df7e2b1117578afc86569fa29ee62eb883fd35428888c0cc0be750faa5ef091f9092&mpshare=1&scene=23&srcid=1026NUThrKm2Vioj874F3gqS&sharer_sharetime=1635227630762&sharer_shareid=80f244b289da8c80b67c915b10efd0a8#rd

架构篇连接:TOP 100值得读的图神经网络----架构_tagagi的博客-CSDN博客 https://blog.csdn.net/tagagi/article/details/121318308
https://blog.csdn.net/tagagi/article/details/121318308
同时推荐一个很好的博客: 图对比学习的最新进展_模型GCC以及我们提出的GRACE和同期GraphCL的工作采用了local-local的思路,即直接利用两个经过增强的view中节点的embedding特征,巧妙地绕开了设计一个单射读出函数的需求。 …https://www.sohu.com/a/496046127_121124371论文列表
- Strategies for pre-training graph neural networks. Weihua Hu, Bowen Liu, Joseph Gomes, Marinka Zitnik, Percy Liang, Vijay Pande, Leskovec Jure. ICLR 2020.
- Deep graph infomax. Velikovi Petar, Fedus William, Hamilton William L, Li Pietro, Bengio Yoshua, Hjelm R Devon. ICLR 2019.
- Inductive representation learning on large graphs. Hamilton Will, Zhitao Ying, Leskovec Jure. NeurIPS 2017.
- Infograph: Unsupervised and semi-supervised graph-level representation learning via mutual information maximization. Sun Fan-Yun, Hoffmann Jordan, Verma Vikas, Tang Jian. ICLR 2020.
- GCC: Graph contrastive coding for graph neural network pre-training. Jiezhong Qiu, Qibin Chen, Yuxiao Dong, Jing Zhang, Hongxia Yang, Ming Ding, Kuansan Wang, Jie Tang. KDD 2020.
- Contrastive multi-view representation learning on graphs. Hassani Kaveh, Khasahmadi Amir Hosein. ICML 2020.
- Graph contrastive learning with augmentations. Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, Yang Shen. NeurIPS 2020.
- GPT-GNN: Generative pre-training of graph neural networks. Ziniu Hu, Yuxiao Dong, Kuansan Wang, Kai-Wei Chang, Yizhou Sun. KDD 2020.
- When does self-supervision help graph convolutional networks?. Yuning You, Tianlong Chen, Zhangyang Wang, Yang Shen. ICML 2020.
- Deep graph contrastive representation learning. Yanqiao Zhu, Yichen Xu, Feng Yu, Qiang Liu, Shu Wu, Liang Wang. GRL+@ICML 2020.
目录
一、图神经网络预训练的策略 STRATEGIES FORPRE-TRAININGGRAPHNEURAL NETWORKS
二、DGI DEEP GRAPH INFOMAX
三、GraphSAGE大型图的归纳表示学习 Inductive Representation Learning on Large Graphs
四、INFOGRAPH: UNSUPERVISED ANDSEMI-SUPERVISED GRAPH-LEVEL REPRESENTATION LEARNING VIA MUTUAL INFORMATION MAXIMIZATION
五、GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training
六、多视图对比学习 Contrastive multi-view representation learning on graphs
七、GraphCL Graph Contrastive Learning with Augmentations
八、GPT-GNN: Generative Pre-Training of Graph Neural Networks
九、When Does Self-Supervision Help Graph Convolutional Networks?
十、GRACE Deep Graph Contrastive Representation Learning
一、图神经网络预训练的策略 STRATEGIES FORPRE-TRAININGGRAPHNEURAL NETWORKS
主要内容:提出了一种图神经网络的预训练方法,在ROC-AUC曲线上得到了11.7%的绝对值提升
1 INTRODUCTION
- 预训练是迁移学习的一种十分有效的方法,可有效解决
- 特定于任务的标签十分稀少
- 现实世界应用通常含有分布外(out-of-distribution)的样例,也就是说在训练集和测试集的图在结构上十分不一样
- 挑战:现有地模型没有系统地研究图上的预训练操作,因而我们不知道什么样的预训练操作有效,以及在实际应用中效果如何
- 贡献:
- 提出了首个系统的大型预训练模型
- 放出了两个大型的预训练图数据集
- 证明了现有的小数据量的benchmark不能够在统计上可靠地评估预训练
- 提出了预训练策略原则(principled pre-training strategy),并证明其的有效性以及在硬迁移学习(hard transfer learning)问题上的分布外泛化能力
- 提出了首个系统的大型预训练模型
- 预训练GNN不总是有效,很多都会导致下游任务的负迁移
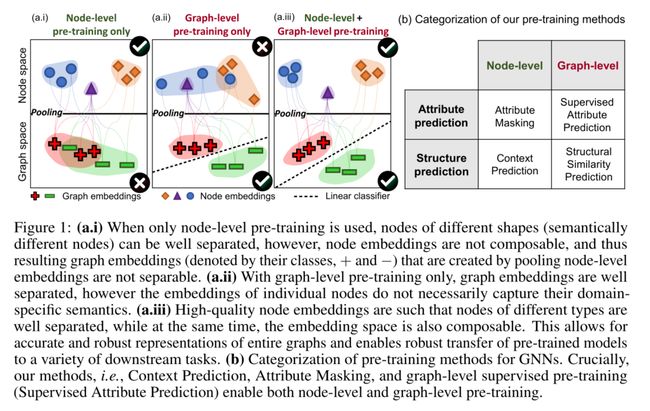
- 预训练GNN的有效方法:使用简单可达的节点级信息,然后鼓励模型学习关于节点和边的领域特定的知识
- 这一思想对于生成健壮且可转移到不同下游任务的图级表示(通过池化节点表示获得)至关重要
2 PRELIMINARIES ONGRAPHNEURALNETWORKS

- GNNs:

- 为了获取图级表征,在最后一次迭代()中添加一个READOUT层,该层是空间不相关的(permutation-invariant function),比如是聚合或者更加复杂的图级的池化函数
- 节点表征学习,两类方法
- 基于随机游走的方法
- 向DEEP GRAPH INFOMAX这类最大化节点和全局表示互信息
- 这两类都是次优的,因为 捕获本地社区的结构相似性通常比位置信息更重要

3 STRATEGIES FOR PRE-TRAINING GRAPH NEURAL NETWORKS
- 核心策略:同时在节点级和图级进行预训练
3.1 NODE-LEVEL PRE-TRAINING
- 使用没有标签的数据,使用自然图(nature graph distribution)分布在图中捕获特定于领域的知识/规则
- 两个互补的预训练方法:Context Prediction 和 Attribute Masking
3.1.1 CONTEXT PREDICTION: EXPLOITING DISTRIBUTION OF GRAPH STRUCTURE
- Context Prediction目的:研究图结构分布
- 使用子图,预测它们的surrounding graph structures
- 目标:训练GNN将具有类似surrounding structures的映射到相近的嵌入
- Neighborhood and context graphs
- 对于节点v
- 邻居:选取K-hop的所有节点和边
- 包围v邻居的图结构(context graph):

- Encoding context into a fixed vector using an auxiliary GNN
- 因为图的组合性质,直接预测context graph是很难的
- 将context graph编码为一个固定长度的向量便于context prediction
- 首先让context GNN获得context graph的节点嵌入

- 将context graph编码为一个固定长度的向量便于context prediction
- 因为图的组合性质,直接预测context graph是很难的
- Learning via negative sampling
- 使用负采样同时学习
- main GNN:编码邻居以获得结点嵌入
- context GNN:编码context graph获得上下文嵌入
- Context Prediction目标:判断上述两个嵌入是否来自同一个节点

- 负样本来自于随机采样
- 正负样本五五开
- 损失函数:负对数似然
- 预训练后,main GNN被作为预训练模型保存
- 使用负采样同时学习
- Relation to existing methods
- 很多相关工作探究了如何跨任务生成结点嵌入,但是,所有这些方法都对不同的社区/上下文使用不同的嵌入,并且不共享任何参数。因此,它们本质上是直推式的,无法在数据集之间传输,无法以端到端的方式进行微调,并且由于数据稀疏性,无法捕获大型和多样的社区/上下文
- 另一条工作线使用随机游走,并将上下文定义为周围节点,而不是周围结构。因此,现有方法捕获节点的位置信息而不是其相邻结构信息,后者更适合于图级预测
3.1.2 ATTRIBUTE MASKING: EXPLOITING DISTRIBUTION OF GRAPH ATTRIBUTES
- 目的:研究图和边属性是如何在图结构中分布的
- Masking node and edges attributes
- mask一些节点和边,然后让GNN通过领域结构来预测这些属性

- 边嵌入可以作为边的端点节点的节点嵌入的总和获得
- 最后在嵌入的顶层使用线性模型预测节点/边的属性
- 节点和边掩蔽策略在科学领域的丰富注释图中特别有用
- 在分子图中,节点属性对应于原子类型,捕获它们在图中的分布方式使GNN能够学习简单的化学规则,如价态,以及可能更复杂的化学现象,如官能团的电子或空间性质
- 在蛋白质-蛋白质相互作用(PPI)图中,边缘属性对应于一对蛋白质之间不同种类的相互作用。通过捕获这些属性在PPI图中的分布,GNN可以了解不同的交互如何相互关联
3.2 GRAPH-LEVEL PRE-TRAINING
- 目标:生成高质量的节点和图表示,因而可以在下游任务中迁移

- 图级预训练有两个选项
- 预测整个图的领域特定属性(例如,监督标签supervised labels)
- 预测图结构,例如:图形编辑距离(Bai等人,2019年)、图形结构相似性(Navarin等人,2018年)
- 使用第一个选项。图级多任务监督预训练,共同预测一组不同的监督图标签
- 在图表示之上应用线性分类器来联合预测图属性,其中每个属性对应于一个二进制分类任务
3.3 OVERVIEW: PRE-TRAININGGNNS AND FINE-TUNING FOR DOWNSTREAM TASKS
- 首先执行节点级自监督预训练
- 然后执行图形级多任务监督预训练
- 当GNN预训练完成时,为下游任务微调GNN。具体来说,在图级表示的顶部添加随机初始化的线性分类器,以预测下游图标签
二、DGI DEEP GRAPH INFOMAX
- 以无监督方式学习图结构中节点表示的通用方法
- 方法:最大化局部表示和相应高级图形摘要的互信息
1 INTRODUCTION
- 将神经网络推广到图神经网络是当前机器学习的主要挑战之一,但
- 最成功的方法是监督学习-->很多时候不可行,没有那没多标注的数据
- 从大规模图中发现新颖或有趣的结构是可取的
- 因此,图无监督学习至关重要
- 现行常用无监督算法是随机游走,问题
- 过度强调邻近信息而牺牲了结构信息
- 性能高度依赖于超参数选择
- 不清楚随机游走是否真的提供了有用信号:这些编码器实施了一种感应偏差,即相邻节点具有相似的表示
- 提出方法:用互信息替代随机游走
- DIM训练编码器模型,以最大化输入的高级“全局”表示和“局部”部分(如图像的面片)之间的互信息
- 这鼓励编码器携带存在于所有位置的信息类型(因此具有全局相关性)
2 RELATED WORK
Contrastive methods
- 对比学习是无监督学习的重要方法
- 使用打分函数,训练编码器增加“真实”输入(也称为正面示例)的分数,减少“虚假”输入(也称为负面示例)的分数
- DGI是对比的,目标是基于对局部-全局对和负采样对进行分类
Sampling strategies
- 对比方法的一个核心细节:如何对正样本和负样本进行采样
- 正样本:短随机游走出现的节点(语言建模角度,将节点视为单词,随机游走视为句子)
- 负样本:随机取样
- curriculum-based negative sampling scheme (with progressively “closer” negative examples)
- 引入对手来选择负样本
Predictive coding
- contrastive predictive coding(CPC)是另一种基于互信息最大化的深度表征方法
3 DGI METHODOLOGY
3.1 GRAPH-BASED UNSUPERVISED LEARNING
- 目标,学习一个编码器,将节点特征编码为局部特征h
- 此时h为局部特征,而不是节点特征
3.2 LOCAL-GLOBAL MUTUAL INFORMATION MAXIMIZATION
- 训练编码器的方法是互信息最大化:寻求节点表示,该表示捕获整个图的全局信息内容,由摘要向量表示

- 实现负采样

- 对于单个图,corruption function:
- 负采样程序的选择,将会决定,希望被捕获的特定类型的结构信息
- 优化目标:类似Deep InfoMax:
- 使用噪声对比型目标,在关节样本(正样本)和边缘产物(反样本)之间使用标准的二元交叉熵(BCE)损失

- 由于所有导出的局部表示都被驱动以保留与全局图摘要的互信息,这允许在局部级别上发现和保留相似性,例如,具有相似结构角色的遥远节点(已知对于许多节点分类任务来说,这是一个强预测器)
- 是 Hjelm et al. (2018)说法的反向版本:对于节点分类,我们要做的是让patches(局部节点)在整个图上进行连接,而不是让summary(摘要)保留所有的这些相似性


- DGI的问题:在一定条件下,其目标等价于最大化输入节点特征和高层节点嵌入之间的MI(来自论文:When does self-supervision help graph convolutional networks?)
- 为了实现InfoMax目标,DGI需要一个内射读出函数来生成全局图嵌入,其中内射属性限制太多,无法实现
- 对于DGI中使用的平均池读出函数,不能保证图嵌入能够从节点提取有用信息,因为它不足以保留节点级嵌入的显著特征
- 此外,DGI建议使用特征打乱来生成损坏的图形视图。尽管如此,该方案在生成负节点样本时在粗粒度级别考虑损坏节点特征
- 当特征矩阵稀疏时,仅执行特征洗牌打乱以为受损图中的节点生成不同的邻域(即上下文),从而导致对比目标的学习困难
三、GraphSAGE大型图的归纳表示学习 Inductive Representation Learning on Large Graphs
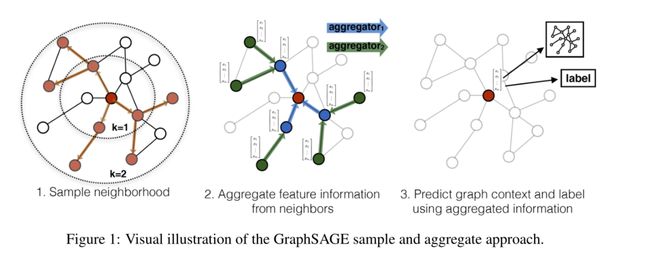
- 以前方法的问题:要求所有所有的节点在嵌入的过程是可见的---->不能为没有看过的(unseen)节点生成嵌入
- 解决方式:通过采样和聚合节点的局部领域中的特征来生成嵌入,不同于传统的矩阵分解方法
1 Introduction
- 节点嵌入方法:
- 利用降维技术将节点图邻域的高维信息提取为密集的向量嵌入
- 节点嵌入可以被馈送到下游机器学习系统,并帮助执行诸如节点分类、聚类和链接预测之类的任务
- 现在方法的问题
- 集中在单个固定的图中,使用基于矩阵分解的方法嵌入节点,不能够快速地为没有见过或全新的(子)图快速生成嵌入,是直推式的
- 可以经过修改,在归纳式的设置中操作,但是计算昂贵,需要额外几轮梯度下降
- 归纳式嵌入问题比直推式困难很多
- 生成没见过的节点讲新观察到的子图“对齐”到已优化好的图中去:需要学会节点的领域属性,即揭示节点在图中的局部角色,也揭示其全局位置
- 解决
- 思路:使用卷积运算学习图结构,但以往的GCN只用作了固定图的直推式学习
- 本模型将GCN扩展到归纳无监督学习的任务中,并提出了可训练聚集函数的框架
- 具体方法
- 利用节点特征来实现聚合函数,而不是矩阵分解
- 学习每个节点邻域的拓扑结构以及节点特征在邻域的情况
- 通过聚合函数学习邻域的节点特征,而不是为每个节点训练单独的嵌入向量
- 每个聚合函数聚合给定节点不同跳数、搜索深度的信息
- 可以无监督、有监督训练
- 利用节点特征来实现聚合函数,而不是矩阵分解
2 Related work
- 基于矩阵分解的嵌入方法
- 图的有监督学习
- 图卷积网络
3 Proposed method: GraphSAGE
- 核心思想:如何从本地邻居聚合信息,如度或者文本属性
3.1 Embedding generation (i.e., forward propagation) algorithm
- 假定模型已经经过训练并且参数是固定的



- 每次迭代或搜索深度时,节点从它们的本地邻居那里收集信息,并且随着这个过程的迭代,节点逐渐从图的更远的范围获得越来越多的信息
- 与魏斯费勒-雷曼同构检验的关系(Weisfeiler-Lehman Isomorphism Test):GraphSAGE是它的连续近似,前者为其提供了理论基础

- 为了minibatch,否则每一批量的空间和时间复杂度是不可预计的
3.2 Learning the parameters of GraphSAGE
- 无监督,基于图的损失函数(鼓励相邻节点有相似表示、不相干节点高度不同),使用随机梯度下降法

3.3 Aggregator Architectures
- 不同于多维点阵,图结构没有先后顺序,因此聚合函数必须是对称的,即对不同顺序的输入产生相同的结果
Mean aggregator
- 几乎等同于GCN中的传播规则
LSTM aggregator
- 有更好的表现力
- 但不是内在对称的(顺序输入)---->将LSTM应用于节点邻居的随机排列,我们使其适应于在无序集合上操作
Pooling aggregator
- 每个邻居的向量通过完全连接的神经网络独立馈送;在这种变换之后,应用元素层面的的最大池化操作来聚合邻居集合上的信息

四、INFOGRAPH: UNSUPERVISED ANDSEMI-SUPERVISED GRAPH-LEVEL REPRESENTATION LEARNING VIA MUTUAL INFORMATION MAXIMIZATION
问题:传统的图核的方法,在获得固定长度的图表征方面有效,但是由于是手工设计的,泛化能力较差
方法:
- InfoGraph最大化图级表示和不同尺度子结构(节点,边,三角)表示之间的互信息
- InfoGraph*最大化InfoGraph学习的无监督图表示与现有监督方法学习的表示之间的互信息。监督编码器从未标记的数据中学习,同时保留当前监督任务所偏好的潜在语义空间
1 introduction
- 图提供了有关较大部分中各个单元之间耦合的明确信息,以及用于为节点和连接节点的边指定属性的定义良好的框架
- 由于很多时候标签少(例如,在化学领域,标签通常是通过昂贵的密度泛函理论(DFT)计算产生的),半监督学习被提出来
- 提出能够学习整个图(相对于节点)的无监督表示的方法是处理未标记或部分标记图的重要步骤
- 图核方法的问题
- 没有提出许多机器学习算法在其上操作的显式图嵌入
- 图核的手工特征导致高维、稀疏或非光滑表示,从而导致泛化性能差,特别是在大型数据集上
- InfoGraph做法(无监督):最大化整个图的表示和不同粒度的子结构表示之间的互信息
- 从deep infomax而来
- Deep Infomax,最大化输入数据和学习表示之间的互信息量
- InfoGraph*:学生教师框架,与mean-teacher框架相似
- 最大化两个模型的中间表示之间的互信息,以便学生模型向教师模型学习
- 学生模型使用有监督的目标函数对标记数据进行训练
- 教师模型使用InfoGraph对未标记数据进行训练
2 related work
- 信息最大化图神经网络(IGNN):利用边状态和变换参数之间的互信息最大化,来实现对各种有监督的分子性质预测任务的预测
- Graph Kernels
- 节点分类任务

- Contrastive methods
- 无监督学习方法:训练编码器在捕获感兴趣的统计相关性的表示和不捕获感兴趣的统计依赖的表示之间进行对比
- Semi-supervised Learning
- Mean(教师的预测是使用之前训练步骤中的参数的指数移动平均值来做出的) Teacher增加了一个损失项,它鼓励原始网络的输出与教师的输出之间的距离变小
- InfoGraph*没有明确鼓励学生模型的输出与教师模型的输出相似,而是通过最大化两个模型学习的中间表示之间的互信息,使学生模型能够向教师模型学习
3 methodology
3.1 PROBLEMDEFINITION

- 半监督图预测任务
3.2 INFOGRAPH






- 使用一批中所有图实例的全局和局部表示的所有可能组合生成负样本

- 与deeo infomax的不同
- DGI随机抽样来获得负样本,因为他们主要关注于学习图上的节点嵌入。然而,对比方法需要大量负样本,因此,infograph尝试学习给定许多图形实例的图形嵌入时,使用批量生成负样本。
- 图卷积编码器的选择也是至关重要的。infograph使用GIN ,而DGI使用GCN 。GIN为图形级应用提供了更好的归纳偏差
3.3 SEMI-SUPERVISED INFOGRAPH
- 简单想法是将监督损失与作为正则化项的无监督目标函数相结合

- 这背后的直觉是,模型将受益于从大量未标记数据中学习良好的表示,同时学习预测相应的监督标签
- 问题:有监督任务和无监督任务可能倾向于不同的信息或不同的语义空间
- 解决:两种编码器模型:标记数据上的编码器(监督编码器)和未标记数据上的编码器(无监督编码器)
- 为了将学习到的表示从无监督编码器传输到有监督编码器,鼓励两个编码器学习到的表示在所有表示级别上具有高互信息(损失项8)

-

- 这个模式可以称为学生老师架构
- 实际上,为了减少等式8的第三项引入的计算开销,在每次训练更新时,在随机选择编码器层强制执行互信息最大化,而不是在编码器的所有层上强制执行互信息最大化
-

五、GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training
问题:现有的GNN多是基于特定任务的,往往不能迁移
提出:基于最近NLP和CV中的预训练方法,提出了 Graph Contrastive Coding (GCC),获取跨多个网络的通用网络拓扑属性
- 预训练任务:网络内和网络间的子图实例识别,并利用对比学习使图形神经网络能够学习内在的和可转移的结构表示
1 introduction
- 假设:具有代表性的图结构模式是通用的,并且可以跨网络进行转换
- 不同网络背后的普遍结构特征
- 万维网、社交网络和生物网络具有无标度特性,即它们的所有度分布都遵循幂律
- 许多实图满足致密化和收缩定律
- 跨网络的其他常见模式包括小世界、母题分布、社区组织和核心-外围结构
- 问题
- 我们能从网络中学习普遍的,可转移的,有代表性的图嵌入吗?
- 如何设计预训练任务,以便能够捕获和进一步传输网络中和跨网络的通用结构模式-->子图实例判别
- 如何设计学习跨图结构表征的结构:从输入图中抽取实例,将它们视为自己的一个不同类,并学习对这些实例进行编码和区分
- 有哪些实例-->对于每个顶点,我们从其多跳ego网络中抽取子图作为实例
- 鉴别规则是什么-->区分从某个顶点采样的子图和从其他顶点采样的子图
- 如何对实例进行编码-->使用图形神经网络(特别是GIN模型[59])作为图形编码器,将底层结构模式映射到潜在表示

2 related work
2.1 vertex similarity
- 三种类型
- 邻居相似性:紧密连接的顶点应视为相似
- 结构相似性:不假设节点相连,而是:具有相似局部结构的顶点应视为相似。两种方法:基于领域知识和基于谱图理论
- GCC采用对比学习和图形神经网络从数据中学习结构相似性
- 属性相似性:利用附加属性作为边信息或监督信号来学习表示,这些表示进一步用于度量顶点相似性
2.2 Contrastive Learning
- 对比学习是从数据中获取相似性的自然选择,NLP中有Word2vec
2.3 Graph Pre-Training
- Skip-gram based model
- LINE[47]、DeepWalk[39]、node2vec[14]和metapath2vec[11]
- 大多用的邻居相似性假设
- 表示与用于训练模型的图形相关联,并且不能处理样本外问题(out-of-sample question)
- Pre-training graph neural networks
- Hu et al. [19]的模型:预训练任务是恢复masked分子图中的原子类型和化学键类型
- Hu et al. [20]:定义了几种图学习任务来预训练一个GCN
- 区别
- GCC用于一般的未标记图,特别是社交和信息网络
- GCC不涉及明确的特征化和预定义的图形学习任务
3 graph contrastive coding(GCC)

3.1 The GNN Pre-Training Problem
- 其基本假设是,在不同的图形中存在共同的和可转移的结构模式,如母题(motifs),这在网络科学文献中是显而易见的
- 使用函数f将顶点映射到一个低维特征向量,具有两个性质:
- 结构相似性,将相似本地网络拓扑结构的节点映射到接近的向量空间
- 可迁移性,它与训练前看不到的顶点和图形兼容
- 重点是在没有节点属性和节点标签的情况下进行结构表示学习,这与图形神经网络研究中常见的问题设置不同
3.2 GCC Pre-Training
- 给定一组图,目标:预训练一个通用图神经网络编码器,以捕获这些图背后的结构模式

- Q1:如何在图中定义子图实例?
- 由于预训练任务只关注结构,没有使用节点的特征/属性,使用单个节点不可行
- 用子图作为对比实例,将单个节点和它的本地结构包含其中



- 将同一个r-ego网络扩充为两个相似实例,作为相似实例对的数据扩充方法(图采样,graph sampling)
- random walks with restart (RWR):带重启的随机游走,游走概率为边权重,回退概率0.8


- 目的:保留底层结构模式并隐藏确切的顶点索引,1)避免学习子图实例判别的简单解决方案,即简单地检查两个子图的顶点索引是否匹配,2)有助于在不同的图之间传递学习模型,因为这样的模型与特定的顶点集无关
- 将同一个r-ego网络扩充为两个相似实例,作为相似实例对的数据扩充方法(图采样,graph sampling)

- 任何GNN都可以使用,并且GCC不对GNN的选择敏感
- 使用Graph Isomorphism Network (GIN)
- 专注于结构表示预训练,而大多数GNN模型需要顶点特征/属性作为输入。为了弥补这一差距,利用每个采样子图的图结构来初始化顶点特征
- Definition 3.2 Generalized positional embedding(广义位置嵌入):其归一化图的上特征向量

- 借鉴NLP的位置嵌入,序列模型中的位置嵌入可以看作是路径图的拉普拉斯特征向量
- 还添加了顶点度数的one-hot编码[59]和ego顶点的二进制指示符[42]作为顶点特征
- 对输出的向量使用L2正则化
- 由于K个词典太大了,计算的限制,通常设计和采用经济的策略来有效地构建和维护词典,如端到端(E2E)和动量对比(MoCo)[17]
- E2E对小批量实例进行采样,并将同一个mini-batch的作为字典,主要缺点:字典大小受批量大小的限制



- 字典中的键表示由平滑变化的键编码器编码


3.3 GCC fine-tuning
- 下游任务
- 图级:输入图形本身可以由GCC进行编码以实现表示
- 节点级:对其r-ego网络(或由其r-ego网络扩充而来的子图)进行编码
- 然后提供给下游任务以预测特定于任务的输出

- GCC as a local algorithm(局部算法):只涉及输入(大规模)网络的局部探索,因为使用了随机游走方法
六、多视图对比学习 Contrastive multi-view representation learning on graphs
主要内容:通过对比图的结构视图来学习节点级和图级表示的自监督方法
结果:将视图数增加到两个以上或对比多尺度编码并不能提高性能,对比一阶邻居的编码和图扩散可以获得最佳性能
1 introduction
- 多视图视觉表征学习中的数据增强的合成用于生成同一图像的多个视图以进行对比学习,在图像分类基准方面取得了超过监督基线的最新成果--->将其迁移到图中来
- 与视觉对比学习的不同
- 增加视图的数量,即对两个以上视图的增强不会提高性能,通过对比来自一阶邻域的编码和一般的图形扩散,可以实现最佳性能
- 与对比图与图或多尺度编码相比,跨视图对比节点和图形编码在这两个任务上都能获得更好的结果
- 与分层图池方法(如可微池(DiffPool))相比,简单的图读出层(readout)在这两个任务上实现了更好的性能
- 应用正则化(early-stop除外)或规范化层对性能有负面影响
2 related work
2.1 unsupervised representation learning on graphs
- random work:使用随机游走方法将图扁平化为序列,然后使用语言模型学习特征
- 过分强调邻近信息而忽略结构信息
- 限制在了直推式的设置(GraphSAGE???),不可使用节点特征
- Graph kernels:将图分解为子结构,并使用核函数来度量它们之间的图相似性
- 需要设计子结构之间的相似性度量这一非平凡的任务
- Graph autoencoders (GAE):训练编码器,通过预测一阶邻域,将图结构中节点的拓扑贴近度施加在潜在空间上
- GAE过分强调邻近信息
- 受非结构化预测的影响
- Contrastive methods:通过对比包含相关依赖项的分布和不包含相关依赖项的分布中的样本,测量潜在空间中的损失
- 是目前的SOTA方法
2.2 Graph Diffusion Networks 图扩散网络
- 图扩散网络(GDN)协调了空间消息传递和广义图扩散
- 扩散作为去噪过滤器允许消息通过高阶邻域
- 早期融合模型和晚期融合模型
- 早期融合模型使用图扩散确定邻域。图扩散卷积(GDC)将图卷积中的邻接矩阵替换为稀疏扩散矩阵
- 后期融合模型将节点特征投影到潜在空间中,然后基于扩散传播学习的表示
2.3 Learning by Mutual Information Maximization
- 不能仅归因于MI的特性,编码器和MI估计器的选择对性能有显著影响
3 method

- 通过最大化一个视图的节点表示和另一个视图的图表示之间的MI来学习节点和图表示,反之亦然,与节点和图分类任务上的对比全局或多尺度编码相比,该方法获得了更好的结果
- 组成部分
- 扩充机制,将样本图转换为同一图的相关视图。只对边进行扩充。然后对其进行采样
- 图编码器:一个视图一个,其后接一个MLP
- 鉴别器:它将一个视图中的节点表示与另一个视图中的图形表示进行对比,并对它们之间的一致性进行评分
3.1 Augmentations 扩充机制
- 两种扩充机制
- 特征空间扩充(对初始节点进行操作,但是很多benchmark不含有初始节点特征,因此难以实现):屏蔽或添加高斯噪声
- 图形结构进行结构空间扩展和损坏:添加或删除连通性、子采样或使用最短距离或扩散矩阵生成全局视图
- 经验上的最优解:将邻接矩阵转换为扩散矩阵,并将这两个矩阵视为同一图结构的两个全等视图
- 原因:邻接矩阵和扩散矩阵分别提供了图形结构的局部和全局视图,因此从这两个视图中学习到的表示之间的最大一致性允许模型同时编码丰富的局部和全局信息(?)
- 扩散方法:

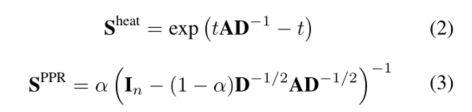
3.2 Encoders
- 节点表示
- 图级表示
- 两种表示都可以用于下游任务

3.3 Training
- 使用deep InfoMax进行




七、GraphCL Graph Contrastive Learning with Augmentations
内容: GraphCL,一个图对比学习的预训练框架
数据扩充时采用均匀分布有时候并不一定合理:
Graph Contrastive Learning with Adaptive Augmentation, CASIA, 2020arxiv
1 introduction
- 预训练的重要性
- 以前的浅模型可以防止过拟合,但现在数据集越来越大
- 就算是使用浅的模型,预训练可以更好地初始化参数:pre-training could initialize parameters in a “better" attraction basin around a local minimum associatedwith better generalization
- 一个简单方案是重建邻域信息(GAE,GraphSAGE),不总是有效
- 过分强调了临近性
- 损伤结构信息
- 对比学习:通过最大化不同增强视图下的特征一致性来学习表示,利用特定于数据或任务的增强来注入所需的特征不变性
- 证明了GraphCL实际上实现了互信息最大化
2 Related Work
- GNNs:(1)为节点级表示,(2)为图级表示
- Graph data augmentation:尚处在探索阶段,数据扩充仍需要额外成本
- Pre-training GNNs:较少。预训练GNN较难迁移,大量领域知识需要预训练和下游任务共同获得
- Contrastive learning:在适当的变换下使表示相互一致。
- 试图重建顶点邻接信息的传统方法可被视为一种“局部对比”,同时过度强调邻近信息而牺牲结构信息
- 因而提倡在局部和全局表征之间进行对比学习,以更好地捕获结构信息
3 Methodology
3.1 Data Augmentation for Graphs
- 数据扩充:在不影响语义标签的情况下,通过应用一定的转换来创建新颖且现实合理的数据

- 因为GNN的数据不像CV,来自于不同的领域,所以不同的数据扩充方法可能适应不同的图

- Node dropping:随机丢弃一部分顶点,基本先验知识是,丢失部分顶点不会影响G的语义
- Edge perturbation:随机添加或删除一定比例的边。假定:语义对边连通模式变动具有一定的鲁棒性
- Attribute masking:模型使用其上下文信息恢复masked顶点属性。基本假设:缺少部分顶点属性对模型预测影响不大
- Subgraph:使用随机游走生成子图,它假设语义可以在其(部分)局部结构中得到很大的保留。
- 默认的扩充(拖放、扰动、掩蔽和子图)比率设置为0.2

3.2 Graph Contrastive Learning

3.2 Graph Contrastive Learning
- 通过潜在空间中的对比损失最大化同一图形的两个增强视图之间的一致性来执行预训练
- 四个组成部分
- 图数据扩充:不同领域的扩充方法不同,生成两个子图作为正例正例(positive pair)
- 基于GNN编码器:提取图级表征,GNN模型任选
- 投射头(Projection head):MLP将增强表示映射到另一个潜在空间,计算对比损失
- 图数据扩充:不同领域的扩充方法不同,生成两个子图作为正例正例(positive pair)
对比损失函数:归一化的温度标度交叉熵损失(NT-Xent),最后的损失是通过小批量中的所有正(?)对计算的

- 负对不是随机生成的,而是同一个mini-batch中的其他−1个扩充图

- 讨论:GraphCL可以视为互信息最大化的一种形式,损失函数可以重写为

- 本质上最大化了互信息的下界
结论

八、GPT-GNN: Generative Pre-Training of Graph Neural Networks
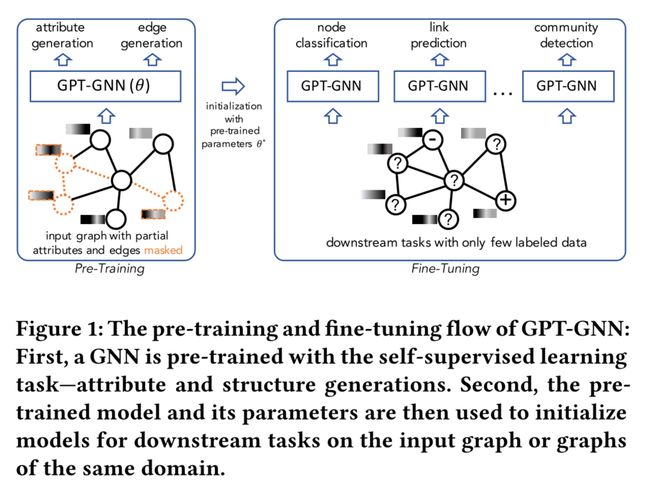
内容:有标签数据十分困难,一个有效的解决方法是先在无标签任务中进行预训练,然后使用少量标签进行微调。提出了通过生成性预训练(属性生成和边生成)初始化GNNs的框架:GPT-GNN
- 可以同时建模图的结构与属性
- 可以通过子采样处理大规模图
1 introduction
- 预训练目标:使GNN能够捕获输入图的结构和语义属性,以便通过对同一域中的图进行一些微调步骤,它可以轻松地推广到任何下游任务
- 方法:为了基于图重建预训练GNN,一个简单的选择是直接采用神经图生成技术
- 挑战
- 图生成技术大多只关注生成没有属性的图结构,而没有捕获节点属性和图结构之间的底层模式,图结构是GNNs中卷积聚合的核心
- 图生成技术被设计用于处理迄今为止的小型图形,限制了它们在大型图形上预训练的潜力
2 preliminaries and related work
- 预训练的目标是允许模型(通常是神经网络)使用预训练的权重初始化其参数。该模型可以利用预训练和下游任务之间的共性--->从这个角度来说,预训练可以看成是一种初始化权重的方法
2.1 Preliminaries of Graph Neural Networks

- s,t分别代表源节点和目标节点
2.2 Pre-Training for Graphs
- 两类
- 网络/图嵌入:直接参数化节点嵌入向量
- 通过保留一些相似性度量对其进行优化,eg. 网络接近度或来自随机游走的统计数据。
- 问题:嵌入不能用于初始化其他模型,以便在执行其他任务时进行微调
- 迁移学习设置:是预先训练一个通用的GNN,可以处理不同的任务
- 网络/图嵌入:直接参数化节点嵌入向量
- 变分图自动编码器[16]GraphSAGE[12]Graph Infomax[37]这些方法显示出比纯监督学习设置更好的性能,但是可以通过强制附近的节点具有类似的嵌入来实现学习任务,但是忽略了图的丰富语义和高阶结构
- 提取图形级表示:InfoGraph[29]在节点和图形级别预训练GNN的不同策略[14]
- GPT-GNN
- 置换生成目标对GNN进行预训练,引导模型学习输入图形更复杂的语义和结构
- 在单个(大规模)图形上预训练GNN,并执行节点级传输
2.3 Pre-Training for Vision and Language
- CV:先在大规模监督数据集上预训练模型,然后在下游任务上微调预训练模型[10]或直接提取表示为特征[5];一些自监督任务[2,13,35]也被用于预训练视觉模型
- NLP:通过利用文本语料库上的共现统计来学习(浅层)单词嵌入[22,25]。最近,在语境化单词嵌入方面取得了重大进展,如BERT[4]、XLNET[41]和GPT[27]
3 Generative pre-traning of GNNs
3.1 The GNN Pre-Training Problem
- 预训练模型应该:1)捕获图形的内在结构和属性模式,2)从而使此图上的各种下游任务受益

3.2 The Generative Pre-Training Framework


- 大多数现有的图生成方法[18,43]都遵循自回归的方式来分解概率目标,即图中的节点按顺序排列,边是通过将每个新到达的节点连接到现有节点生成的
- 表示排列向量π以确定节点顺序, 代表排列π中第i个位置的节点id:

- 假设观察任何节点排列π的概率相等,并且在以下章节中说明一个排列的生成过程时,也省略了下标π
- 给定排列顺序,得到每次迭代生成一个节点的对数似然自回归:
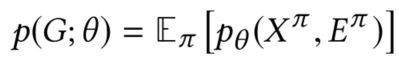

3.3 Factorizing Attributed Graph Generation
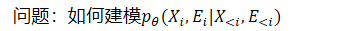


- 对于每个节点,其属性和连接之间的依赖关系被完全忽略,这很重要(属性图的核心性质,也是GNNs卷积聚合的基础)--->不可行
- 新方法:属性图生成过程的依赖感知因子分解机制,当估计一个新节点的属性时,我们会得到它的结构信息,反之亦然
- 此过程中,已观察到(或生成)部分边
- 两个耦合部分:1)给定观察到的边,生成节点属性,2)给定观察到的边和生成的节点属性,生成其余边

- 以学术图为例,如果希望生成一个论文节点,其标题被视为其属性,而该论文节点连接到其作者、发布地点和引用的论文
- 首先基于本文和一些作者之间观察到的一些边,生成它的标题
- 然后,基于观察到的边和生成的标题,我们预测其剩余作者、出版地点和参考文献
- 通过这种方式,该过程对论文属性(标题)和结构(观察到的边和剩余边)之间的交互进行建模,以完成生成任务,为学术图上的GNN预训练引入信息信号
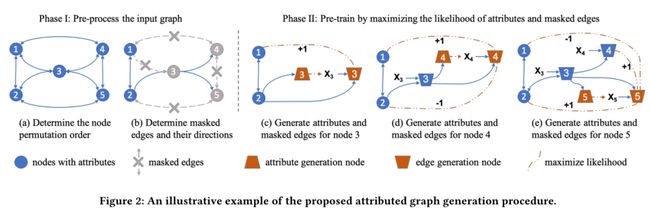
3.4 Efficient Attribute and Edge Generation
- 问题:如何通过优化属性和边缘生成任务有效地预训练GNN
- 为简化计算,希望只进行一次预测,同时计算节点属性和边,但边生成需要节点属性作为输入,这样可能会造成泄露--->将节点分为两类

- 边生成节点:保留它们的属性并将它们作为GNN的输入

- 边生成,假设每条边的生成都是独立于其他边

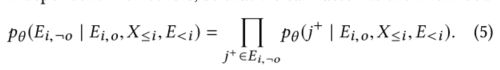


3.5 GPT-GNN for Heterogeneous & Large Graphs
- 异构图:可以直接应用于异构GNN的预训练。唯一的区别是,每种类型的节点和边缘都可能有自己的解码器,这是由异构GNN而不是预训练框架指定的。所有其他组件保持完全相同
- 大规模图:在太大而无法放入硬件的图上预先训练GNN,可对子图进行了抽样训练。建议分别使用Lades算法[45]及其异构版本HGSampling[15]从同质图和异构图中采样稠密子图。这两种方法从理论上保证了采样节点之间的高度互连,并最大限度地保留了结构信息
- 自适应队列
- 估算公式6中的对比损失,需要遍历输入图的所有节点
- 然而,我们只能访问子图中的采样节点来估计这种损失,使得(自)监控只关注本地信号
- 自适应队列将先前采样的子图中的节点表示存储为负样本。每次处理新的子图时,都会通过添加最新的节点表示和删除最旧的节点表示来逐步更新此队列
- 由于模型参数不会严格更新,因此存储在队列中的负样本是一致和准确的
- 自适应队列使我们能够使用更大的负样本池。此外,跨不同采样子图的节点可以为对比学习提供全局结构指导
九、When Does Self-Supervision Help Graph Convolutional Networks?
内容:图自监督学习,提出了三种新的GCN自监督学习任务,将多任务自我监控融入到图形对抗训练中
代码:https: //github.com/Shen-Lab/SS-GCNs
1 introduction
- 主要讨论直推式半监督节点分类
- 问题:主要讨论了转移半监督节点分类
- 贡献
- GCN是否能从分类性能的自我监督学习中获益?如果是,如何将其纳入GCN以最大化收益?
- 是;作为GCN训练中的一个正则化项,与作为预训或通过自训练的自监督相比,是有利的
- 前置任务的设计是否重要?GCN有哪些有用的自监督前置任务?
- 节点聚类、图划分、图完成(graph completion)。不同下游任务偏好不同的前置
- 自监督是否也会影响GCN的对抗性稳健性?如果是,如何设计前置任务?
- 将上述发现推广到对抗性训练环境中,表明自监督也提高了GCN在各种攻击下的健壮性,不需要更大的模型和额外的数据
- GCN是否能从分类性能的自我监督学习中获益?如果是,如何将其纳入GCN以最大化收益?
2 Related Work
- Graph-based semi-supervised learning:关键假设:与权重较大的边连接的结点更有可能具有相同的标注
- 方法:mincuts,Boltzmann machines,graph random walks ,GCNs
- Self-supervised learning:CNN中自监督主要分为两类
- 预训练和微调:首先用自监督的前置任务进行预训练,然后用标签监督的目标任务进行微调
- 多任务学习:与目标监督任务和(一个或多个)自监督任务的联合目标同时训练
- 自训练问题:“饱和”和退化,还限制了可以合并的自监督任务的类型
- Adversarial attack and defense on graphs:GCNs的广泛适用性和脆弱性提出了提高其健壮性的迫切需求,因而产生对抗性攻防算法
3 method
3.1 Graph Convolutional Networks

- 半监督学习:通过最小化标记节点的输出和真实标签之间的监督损失来学习GCNS中的模型参数


3.2 Three Schemes: Self-Supervision Meets GCNs

- 预训练和微调

- 使用得到的∗初始化(2)中的

- 预训练只提供了微小的提升

- 原因:
- 不通过任务之间的迁移
- 深GCN会导致过平滑
- 自训练:首先使用标签进行训练,然后将高可信度的预测出来的伪标签进行下一轮次的训练,循环往复

- 随着标签率的上升,表现的提升会逐渐饱和
- 多任务训练:将预训练任务和监督任务同时进行


- 预训练任务可以看作正则项
- 尽管GLR(图拉普拉斯变换)的有效性已在图形信号处理中得到证明,但正则化器仅在平滑先验之后手动设置,而不涉及数据
- 自监督任务作为正则化器,在人工先验的次要指导下从未标记的数据中学习
- 多任务学习是三者中最普遍的框架。在训练过程中充当数据驱动的正则化器,它不对自我监督的任务类型进行假设。也是表现最好的
3.3 GCN-Specific Self-Supervised Tasks
- 节点聚类

- 将簇索引作为自监督标签分配给所有节点
- 图划分:将图的节点划分为大致相等的子集,最小化不同子集中连接节点的边的数目

- 平衡约束
- 目标是最小化edgecut(即不同划分节点之间的边权重之和)
- 将分区索引指定为自监督标签
- 与基于节点特征的节点聚类不同,图划分提供了基于图拓扑的先验正则化
- 类似于图拉普拉斯正则化器(GLR),也采用了“连接提示相似性”
- GLR会将所有节点与其相邻节点进行局部平滑,图划分通过利用所有连接对连接密度较大的节点进行分组来考虑全局平滑性
- 图补全(graph completion):通过删除目标节点的特征来屏蔽,用GCN来恢复/预测之
- 优点:1)标签为节点特征,其获取是不耗费资源的。2)可以训练网络使用上下文来预测节点特征,提高表现力



3.4 Self-Supervision in Graph Adversarial Defense
- 研究三种预训练任务在增强抵抗各种对抗性攻击的鲁棒性方面可能发挥的作用
- 对抗性攻击:单节点直接规避攻击,训练模型参数在攻击时/后保持不变,为生成扰动特征与邻接矩阵的攻击者
- 对抗性防御
- 高效方法:通过对抗性训练,用对抗性示例扩充训练集
- 图上标签少,不可用--->未标记节点生成对抗性示例


- 针对图形数据的对抗性训练可以表述为对标记节点的监督学习和对未标记节点(被攻击和清除)的伪标记恢复
- 自监督的对抗性防御
- 根据公式(4),(6):
- 自监督提高了稳健性和不确定性估计,而不需要更大的模型或额外的数据
- 根据公式(4),(6):



4.3 result summary
- 在将自我监督纳入GCN的三种方案中
- 多任务学习起到了调节器的作用,并始终使GCN在具有适当自我监督任务的可推广标准绩效方面受益
- 预训练&微调将目标函数从自我监督切换到目标监督损失,这很容易“覆盖”浅层GCN并获得有限的性能增益
- 自我训练仅限于分配哪些伪标签以及使用哪些数据分配伪标签。它的性能增益在few-shot学习中更为明显,并且可以随着标记率的略微增加而减少
- 通过多任务学习
- 自监督任务提供了信息性的先验知识,这有助于GCN的生成目标的表现
- 节点聚类和图划分分别提供了节点特征和图结构的优先级
- 具有(联合)先验的图补全有助于GCN基于上下文的特征表示
- 自我监督任务是否有助于SOTA GCN的标准目标性能取决于数据集是否允许与任务相对应的高质量伪标签,以及自我监督优先级是否补充现有的体系结构优先级
- 对抗训练中的多任务自我监控提高了GCN对各种图攻击的鲁棒性
- 节点聚类和图划分提供了特征和连接的优先级,从而分别更好地抵御特征攻击和链接攻击
- 图补全,在特征和连接上都有(联合)扰动先验,对于最具破坏性的特征&链接攻击,可以持续增强鲁棒性,有时甚至大幅提高鲁棒性
十、GRACE Deep Graph Contrastive Representation Learning
提出:一种基于节点级对比目标的无监督图表示学习框架
- 通过损坏生成两个图形视图,并通过最大化这两个视图中节点表示的一致性来学习节点表示
- 结构级和属性级
代码:https://github.com/CRIPAC-DIG/GRACE
改进:GCA。本质上来说,对比学习希望模型能学习到在外界施加扰动的情况下不敏感的特征表达。但是在图中每个节点和每一条边的重要程度不同,我们在 data augmentation 时进行去边的操作时应该尽可能多的去除不重要的边,进而可以保留图中重要的边与节点的结构信息以及属性信息。GCA 依然遵循 GRACE 的数据增强策略,即采取拓扑结构层面的数据增强(去边)以及节点属性层面的数据增强(mask 节点特征)。我们希望在进行数据增强的操作时,对于每个边以及每个节点进行扰动的概率有所差别,且事件发生的概率应该偏向于不重要的边与节点特征
1 Introduction
- 以往的类似Deepwork的图嵌入过分强调了网络结构上定义的邻近信息
- 最近的图表征学习使用有监督方法,而标签难得。虽少数几个使用了无监督(矩阵重建),但还是过度依赖于预设的图接近矩阵
- DGI的问题:在一定条件下,其目标等价于最大化输入节点特征和高层节点嵌入之间的MI
- 为了实现InfoMax目标,DGI需要一个单射读出函数( injective readout functions )来生成全局图嵌入,其中单射属性限制太多,无法实现
- 对于DGI中使用的平均池读出函数,不能保证图嵌入能够从节点提取有用信息,因为它不足以保留节点级嵌入的显著特征
- 此外,DGI建议使用特征打乱来生成损坏的图形视图。尽管如此,该方案在生成负节点样本时在粗粒度级别考虑损坏节点特征
- 当特征矩阵稀疏时,仅执行特征洗牌打乱以为受损图中的节点生成不同的邻域(即上下文),从而导致对比目标的学习困难
- 提出简答有效的deep GRAphContrastive rEpresentation learning (GRACE)
- 主要关注节点级嵌入的对比,而不是将节点级嵌入与全局嵌入进行对比,没有对生成图嵌入的单射读出函数进行假设
- 使用随机损坏(拓扑和节点属性级别,即删除边和mask特征)生成两个相关的图视图
- 使用对比损失进行训练,使两个视图之间的一致性最大化
- 为不同视图中的节点提供不同的上下文,以促进对比对象的优化
- 主要关注节点级嵌入的对比,而不是将节点级嵌入与全局嵌入进行对比,没有对生成图嵌入的单射读出函数进行假设
2 Related Work
- 视觉表征的对比学习:最近的工作[26]表明,评估表示质量的下游性能可能强烈依赖于偏差,该偏差不仅在卷积结构中编码,而且在InfoMax目标的特定估计器中编码。
- 图表征学习
- 这些基于随机游走的方法
- 被证明相当于分解某些形式的图接近度(例如,相邻矩阵的变换)[4]
- 过度强调这些图接近度中编码的结构信息,并且还面临大规模数据集的严重缩放问题
- 已知这些方法在超参数调整不当时容易出错
- 无监督的GNN
- GraphSAGE,它也包含了类似DeepWalk的目标
- DGI结合了GNN和对比学习的力量,其重点是最大化全局图嵌入和局部节点嵌入之间的MI
- 很难满足图形读出函数的单射要求,因此图形嵌入可能会恶化
- 这些基于随机游走的方法
3 Deep Graph Contrastive Representation Learning
3.1 Preliminaries
3.2 Contrastive Learning of Node Representations
3.2.1 The Contrastive Learning Framework
- 通过直接最大化嵌入之间的节点级协议来学习嵌入
- 在每一次迭代中



- 每个正对的成对目标

- 没有显式地采样负样本,负样本来自两个源,视图间或视图内节点
- 将要最大化的总体目标定义为所有正对的平均值



3.2.2 Graph View Generation
- Removing edges (RE) 删除边:随机删除一些边
- Masking node features (MF)掩蔽节点特征:在节点特征中使用零随机mask部分维度



3.3 Theoretical Justification
- 与互信息的联系
- J是X和两个视图U,V之间MI的下界

- 证明方法,证明J是InfoNCE的下界,而InfoNCE是MI的下界
- 与直觉相反,最近的工作进一步提供了经验证据,证明优化更严格的MI界限可能不会导致视觉表征学习的更好下游性能[26],这突出了编码器设计的重要性
- J是X和两个视图U,V之间MI的下界
- 与triplet loss的联系

- 可以将等式(2)中的问题视为学习图卷积编码器,以鼓励正样本在嵌入空间中远离负样本

triplet loss:

- a:anchor,锚示例;p:positive,与 a 是同一类别的样本;n:negative,与 a 是不同类别的样本;margin 是一个大于 0 的常数。最终的优化目标是拉近 a 和 p 的距离,拉远 a 和 n 的距离
- triplet loss 损失函数 - 知乎