深度学习课后作业4
题目列表
习题4-2 试设计一个前馈神经网络来解决XOR问题,要求该前馈神经网络具有两个隐藏神经元和一个输出神经元,并使用ReLU作为激活函数。
习题4-3 试举例说明“死亡ReLU问题”,并提出解决办法。
习题4-7 为什么神经网络模型的结构化风险函数中不对偏置b进行正则化。
习题4-8 为什么用反向传播算法进行参数学习时要采用随机参数初始化的方法而不是直接令W=0,b=0?
习题4-9 梯度消失问题是否可以通过增加学习率来缓解?
习题4-2 试设计一个前馈神经网络来解决XOR问题,要求该前馈神经网络具有两个隐藏神经元和一个输出神经元,并使用ReLU作为激活函数。
XOR问题描述:异或是对两个运算元的一种逻辑分析类型,当两两数值相同时为否,而数值不同时为真。
这里附上异或问题真值表

XOR输入为2个神经元,输出为一个神经元,此题要求隐藏神经元为2个,故只要两层全连接层即可,前馈神经网络设计:
数据集:输入为两位二进制,输出为一个二进制表示的数
网络模型:用pytorch搭建两层全连接层神经网络
训练:使用ReLU作为激活函数,损失函数,反向传播,参数更新
求权重和偏置
进行测试
代码:
import torch
import torch.nn as nn
import torch.optim as optim
# 异或门模块由两个全连接层构成
class XORModule(nn.Module):
def __init__(self):
super(XORModule, self).__init__()
self.fc1 = nn.Linear(2, 2)
self.fc2 = nn.Linear(2, 1)
self.relu = nn.ReLU()
def forward(self, x):
x = x.view(-1, 2)
x = self.relu((self.fc1(x)))
x = self.fc2(x)
return x
# 输入和输出数据,异或输入四种情况
input_x = torch.Tensor([[0, 0], [0, 1], [1, 0], [1, 1]])
input_x1 = input_x.float()
real_y = torch.Tensor([[0], [1], [1], [0]])
real_y1 = real_y.float()
# 设置损失函数和参数优化函数
net = XORModule()
loss_function = nn.MSELoss(reduction='mean') # 用交叉熵损失函数会出现维度错误
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # 用Adam优化参数选不好会出现计算值超出0-1的范围
# 进行训练
for epoch in range(10000):
out_y = net(input_x1)
# 计算损失函数
loss = loss_function(out_y, real_y1)
# 对梯度清零,避免造成累加
optimizer.zero_grad()
loss.backward() # 反向传播
optimizer.step() # 参数更新
# 打印计算的权值和偏置
print('w1 = ', net.fc1.weight.detach().numpy())
print('b1 = ', net.fc1.bias.detach().numpy())
print('w2 = ', net.fc2.weight.detach().numpy())
print('b2 = ', net.fc2.bias.detach().numpy())
input_test = input_x1
out_test = net(input_test)
print('input_x', input_test.detach().numpy())
print('out_y', out_test.detach().numpy())运行结果
w1 = [[ 0.51856667 0.00224139]
[-0.37243554 0.33996654]]
b1 = [ 0.3107024 -0.35686994]
w2 = [[ 8.9924451e-06 -3.4036016e-01]]
b2 = [0.49999413]
input_x [[0. 0.]
[0. 1.]
[1. 0.]
[1. 1.]]
out_y [[0.49999693]
[0.49999693]
[0.5000016 ]
[0.5000016 ]]
习题4-3 试举例说明“死亡ReLU问题”,并提出解决办法。
ReLU激活函数可以一定程度上改善梯度消失问题,但是ReLU函数在某些情况下容易出现死亡 ReLU问题,使得网络难以训练。这是由于当x<0时,ReLU函数的输出恒为0。在训练过程中,如果参数在一次不恰当的更新后,使得隐藏层神经元的输入全部为负数,某个ReLU神经元在所有训练数据上都不能被激活(即输出为0),那么这个神经元自身参数的梯度永远都会是0,在以后的训练过程中永远都不能被激活。而一种简单有效的优化方式就是将激活函数更换为Leaky ReLU、ELU等ReLU的变种。
举个例子:
首先为什么ReLU会导致死亡节点呢?

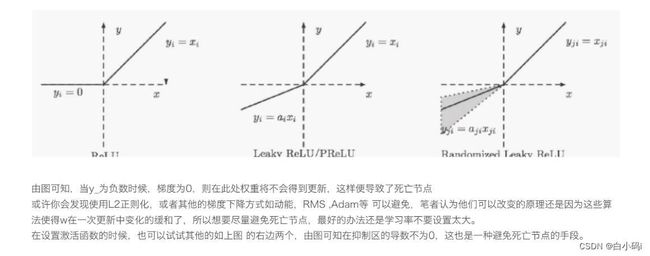
再比如,以一个二分类问题为例,同时采用交叉熵作为Loss Function:

当遇到负数值时, 会变得非常小,导致W变小,若学习率lr设置的非常大,那么W会变得非常小,以至于输出为负数,激活函数无法被激活,从而无法进行后续参数的更新,造成死亡节点,死亡问题。
会变得非常小,导致W变小,若学习率lr设置的非常大,那么W会变得非常小,以至于输出为负数,激活函数无法被激活,从而无法进行后续参数的更新,造成死亡节点,死亡问题。
解决办法便是可以选择其他的激活函数。
习题4-7 为什么神经网络模型的结构化风险函数中不对偏置b进行正则化。
首先模型公式为![]()
这里的W对于函数影响是比较大的,这个偏置 b 对于函数来说只是进行一个向左或向右的平移,并且 b 对输入的改变是不敏感的,无论输入变大还是变小, b 对结果的贡献只是一个偏置,因此其对过拟合没有帮助。
而对参数进行正则化的目的是为了防止过拟合,过拟合一般表现为模型对于输入的微小改变产生了输出的较大差异,这主要是由于有些参数w过大的关系,通过对||w||进行惩罚,可以缓解这种问题。
并且查阅后发现,对前置b进行正则化容易造成欠拟合。
习题4-8 为什么用反向传播算法进行参数学习时要采用随机参数初始化的方法而不是直接令W=0,b=0?
反向传播就是要将神经网络的输出误差,一级一级地传播到输入。在计算过程中,计算每一个w 对总的损失函数的影响,即损失函数对每个w的偏导。根据w的误差的影响,再乘以步长,就可以更新整个神经网络的权重。当一次反向传播完成之后,网络的参数模型就可以得到更新。更新一轮之后,接着输入下一个样本,算出误差后又可以更新一轮,再输入一个样本,又来更新一轮,通过不断地输入新的样本迭代地更新模型参数,就可以缩小计算值与真实值之间的误差,最终完成神经网络的训练。
假设将所有的参数都初始化为0,即W=0,b=0(或者相同的值),那么神经网络中的每个单元都会输出相同的激活值,同样也会有相同的误差值,这就会导致代价函数对各个参数的偏导数也相同,最终使用优化算法在增新参数后,所有的参数仍然相等,这样相当于隐层只有1个神经元,造成参数对称问题。
习题4-9 梯度消失问题是否可以通过增加学习率来缓解?
梯度消失问题是在早期的BP网络中比较常见的问题。这种问题的发生会让训练很难进行下去,看到的现象就是训练不再收敛——Loss过早地不再下降,而精确度也过早地不再提高
梯度消失问题是由于激活函数为类似于sigmoid与tanh,其值太大或太小时导数都趋于0;并且在深层神经网络中,误差反向传播时,传播到前几层时梯度信息也会很小。问题是可否通过增大学习率来增大梯度,以至于梯度信息可以在更新时变大。
答案是不行的,增大学习率带来的缺陷会比梯度消失问题更加严重,学习率变大时,很容易使得参数跳过最优值点,然后梯度方向改变,导致参数优化时无法收敛。
具体造成梯度消失问题的原因以及解决方法可以参考https://blog.csdn.net/weixin_45848575/article/details/125461641
参考:
课程魏老师csdn主页:(https://blog.csdn.net/qq_38975453?type=blog)